

It’s probably happened to you at some point: You go to use a service for which you believe you’ve got a paid subscription, only to find that it’s been canceled for non-payment. That’s not only bad for you the customer: It causes negative feelings about the brand, it disrupts what should be a steady flow of revenue to the business, and a customer who finds themselves shut off might decide not to come back.
At Dropbox, we found that applying machine learning to our handling of customer payments has made us better at keeping subscribers happily humming along.
Payments at Dropbox
The Dropbox Payments Platform manages payment processing for millions of our customers. When a customer visits the Dropbox website and chooses to buy one of our products, we ask the customer to enter their payment information on the purchase form. After the customer submits the form, the system collects their payment information and securely sends this info, along with the amount we want to charge them, to one of our external partners who process that type of payment information.
This all takes place behind the scenes instantly when a customer starts a Dropbox subscription. Once they complete their payment and become a paid customer, they enter our payment lifecycle. All of this, from start to finish, is handled by our Payments Platform.
Subscription renewals and failures
Customers who have a Dropbox subscription pay for it on a regular cadence—usually monthly or yearly. At the time of a recurring payment, a customer’s credit card is charged automatically (if the customer has authorized us to charge it). If the charge is successful, the subscription is renewed without the customer needing to do anything.
However, if the attempt fails, the customer enters what we call renewal failure. When that happens, we have recovery procedures that attempt to keep the customer’s subscription from being disrupted.
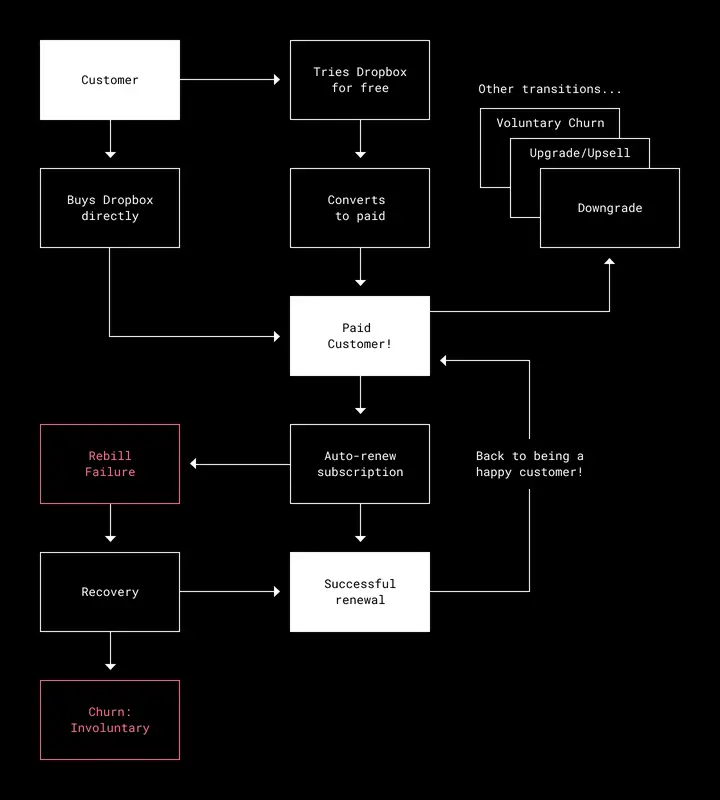
Figure 1. Involuntary Churn is when a credit card expires or is canceled, or has no funds, etc.
Historically, our Payments Platform has used a static set of about ten different methods to determine when to charge a customer whose subscription is in renewal failure. For example, we may charge a customer every four days until a payment succeeds, for a maximum of 28 days. If a customer’s payment still fails at the end of this window, their Dropbox account is downgraded to a free Basic account.
Of course, downgrades are a poor customer experience for active users and teams. And involuntary churn can be a lost opportunity for Dropbox.
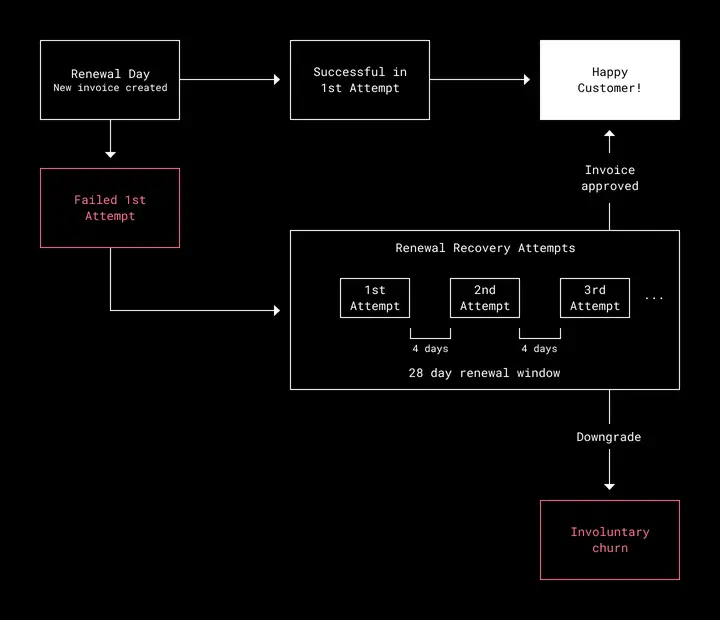
Fig 2. Renewal Attempts
Payment failures can happen for a number of reasons. Among them:
- insufficient funds
- expired credit card
- credit card disabled—perhaps reported lost or stolen
- transient processing failures
Some of these failures can be resolved on their own, while others require customer action for recovery.
Why machine learning for payments?
In the last couple of years, Dropbox ran A/B tests to see if shifting when we charge customers would have an impact on the success rates of those charges. These A/B tests relied heavily upon human intuition and domain knowledge to come up with a set of rules for when to charge a customer.
The Payments team had to manually segment users into populations based on their features—subscription type, geographic location, etc—then A/B test our ten or so different hardcoded rule sets to determine which performed the best for those features. The Payments team would then store the best billing policy option as the default for that population. Periodically they would retest to see if the best solutions for different users had changed.
On the upside, this approach proved that time of charge had an effect on charge success rates, which allowed Dropbox to keep more subscribers humming along without interruption. But over time a large number of these rules have decayed and hit a performance ceiling. Moreover, manually updating these rules is complex and time-consuming.
In a quest to reduce both involuntary churn and the amount of work required to maintain it, the Payments team partnered with the Applied Machine Learning team to experiment with using machine learning (ML) to optimize billing.
As a member of the ML team, I knew the challenge is similar to what machine learning experts call the multi-armed bandit problem—one has a fixed and limited set of resources to allocate among competing alternatives. With payments, we have to determine when to retry, how many times to retry, and whether we should even attempt a retry.
Applying machine learning over time, we identified multiple improvements that even a team of top Payments experts couldn’t have calculated:
- Removal of manual intervention and complex rule based logic
- e.g. “Retry every X days” or “Avoid Weekends”
- Global optimization of multiple parameters for specific customer segments
- Robustness to customer and market changes
- An overall increase in payment charge success rates and reduction of collection time
In short, applying ML to Payments has made both customers and us happier.
How we did it
We began by focusing on predicting when to try charges, i.e. identifying the best time to charge customers at the time of subscription renewal, and to retry charging their account during renewal failure.
We experimented with different customer segments, specifically starting with Individual customers and teams in North America. We built a gradient boosted ranking model trained with features including types of payment failures, Dropbox account usage patterns, and payment type characteristics. The model ranks the charge attempts by predicted likelihood of success for each charge window.
For example, we took an 8 day window and divided it into one-hour chunks, resulting in a total of 192 time chunks. We used our models to find the highest ranking time chunk to attempt the renewal. We also experimented with 6- and 4- day windows.
At first, we experimented with optimizing each charge attempt independently. We had a model that optimized when to charge a customer after the first payment failed. If the model’s recommended attempt also failed, we defaulted back to our rule-based logic for the rest of the renewal window. We ran an A/B test for this combination, using a random sampling of the US individual user segments. For targeting we used our internal feature gating service, Stormcrow. The model improved success rates, and we shipped it.
Our goal was always end-to-end optimization of renewal failure attempts. Starting with a single model helped validate that ML could be applied to solve this type of problem. However, we realized quickly that this design pattern of having a separate model per payment attempt only created a more complicated system. For example, if we retried 5 times before a payment succeeded, using this design we would end up with 5 models. This went against our secondary goal of using ML to reduce the complexity of the billing system.
So we shifted our approach to have a single model that can predict when to charge a customer multiple times until the customer is able to successfully renew, or is downgraded after the maximum renewal window has passed as in Figure 2. If the first payment failed, we’d ask the model for the next best time to charge. If that failed, we’d again ask the model for the next best time, and so on for a maximum number of times. At that point, if none of the payments have succeeded, the customer is downgraded. But if any of the payments succeeded, the associated invoice was approved no matter how many payment attempts had been made.
This specific model is currently being A/B tested in production, using our Stormcrow system to randomly target Dropbox teams for testing. The results so far are positive.
Serving predictions
Once we had trained models, our next step was to make these models available during payments processing. We needed a way to serve the best time to charge predictions from our machine learning models to the Payments Platform, ensuring they would be used as part of the billing policy.
When we first began experimentation, we were using the Payments Platform to load and run the model. This design caused the Payments Platform to bloat significantly due to the added dependencies. Prediction latencies ran to around two minutes on average.
To streamline the process, we took advantage of the Predict Service built and managed by the ML Platform team, which manages the infrastructure to help quickly build, deploy and scale machine learning processes at Dropbox. Using Predict Service helped reduce latency for generating model predictions from several minutes to under 300ms for 99 percent of them. Migrating to Predict Service also provided a clean separation between the two systems, and the ability to scale easily.
With this plug-and-play machine learning system, the Payments Platform fetches all the signals relevant to a customer and makes a request to the model (served via Predict Service) to get the best time to charge the customer, eliminating all of our old hardcoded sub-optimal billing policies developed over 14 years of A/B testing.
The workflow for this system is designed as follows. White represents components of the Payments Platform. Purple represents components of the machine learning system.
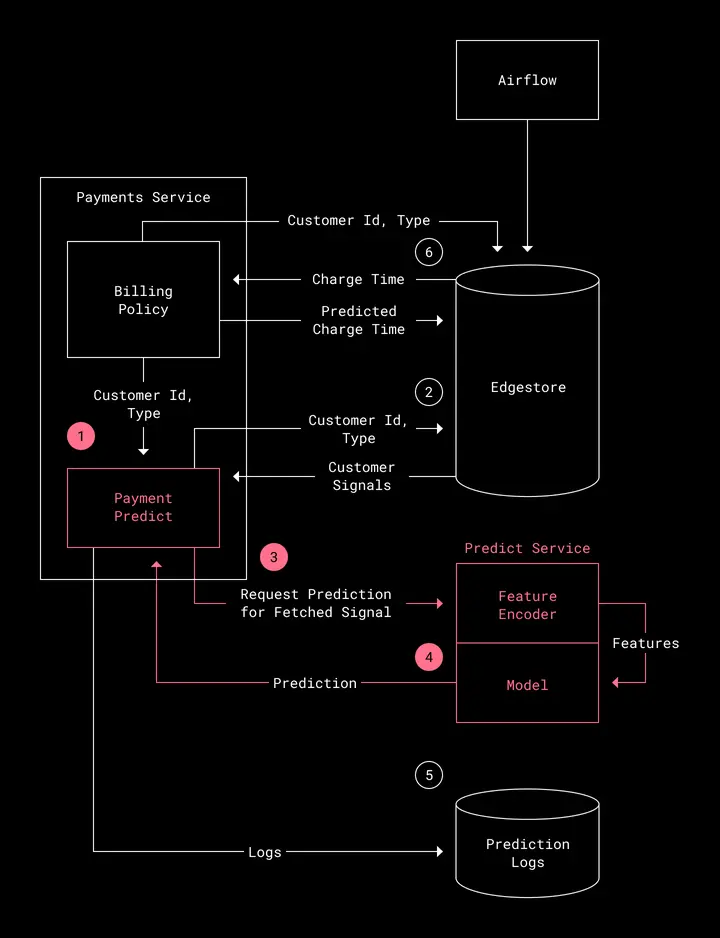
- Get prediction for next time to charge — When a payment attempt for a customer fails, the payments platform makes a request to the predict module to get the next best time to charge the customer. The request is made using the customer id and type.
- Retrieve customer signals. The predict module collects the most recent usage and payments signals for customers, as well as information about the previous failure. This data is stored in Edgestore (the primary metadata storage system at Dropbox) using a daily scheduled Airflow Job.
- Request prediction — The collected signals are sent to Predict Service via a GRPC call, which encodes the signals into a feature dataframe and then sends them to the model.
- Generate prediction — The model returns the best ranked time for when to charge the customer. This prediction is sent back to the predict module, which returns the results to the billing policy.
- Log prediction results — The predict module also logs the model’s prediction, along with other relevant information that can be used for troubleshooting and analysis.
- Schedule next charge — Once the payments service receives the best time to charge, it then uses it to schedule the next payment attempt, and stores that in Edgestore.
ML Operations
Our task wasn’t done upon rollout. We applied DevOps best practices to our data collection and prediction systems: We automated our data collection jobs to run daily, and put monitoring in place to notify us of any failures or delays in the jobs running.
For our models and model-serving infrastructure we defined a set of business- and model-specific metrics that we track, and set up alerting in case any metrics go below an acceptable threshold. These are the main metrics and measures we use to ensure that everything is running as expected:
Business Metrics
- Invoice Approval Rate: This is the primary metric that we want to improve. Every time a user’s Dropbox subscription renews, all the payments for that specific renewal are tracked as part of a single invoice. This metric tells us whether the renewal for the user was successful or not.
- Attempt Success Rate: This metric helps us track the success rates for each individual payment attempt made on behalf of the user. There might be one payment attempt made, or two, four, or more. This metric, along with the Invoice Approval Rate, helps us track how quickly we are able to renew a customer.
Model internal monitoring
This is a set of measures internal to the training process and tooling being used. These help us determine how well the model is tuned based on the input data, as well as helping to identify any issues with the model while it’s running in production. We measure the following online model metrics to help with diagnostics:
- Coverage: the percentage of customers that have recommendations from the model compared to the fixed 4 day interval.
- Number of predictions made by the model: the number of recommendations that the model made successfully without any errors
- Prediction Latency: how long it took the model to make each recommendation
Infrastructure monitoring
Along with all the monitoring and alerting in place for Payments Platform and Predict Service, we also track the following to track how well our infrastructure is performing:
- Freshness and delays in feature data pipelines
- Availability and latency of Predict Service
- Availability of EdgeStore
We use Grafana dashboards and Vortex for monitoring our model, and infrastructure metrics. For business metrics we use Superset. All these live metrics, and dashboards help us proactively track the expected behavior of the model, enabling us to take appropriate action when it deviates.
The responsibility of monitoring these metrics is split between the Payments engineering team and the Applied Machine Learning team. We have troubleshooting guides to help on-call engineers to debug any issues with clear escalation paths. Since ML was new to the Payments engineering team, we spent time explaining how the systems worked, and how to interpret the model’s results. This has helped the two teams successfully collaborate on the project and ensure that everything runs smoothly.
Next steps
Our experimentation has validated that the ML-based system outperforms our rule-based approach. Moreover, without manual and extensive investment, the rule-based system’s performance will decay over time, whereas the ML system stays sharp through retraining. We can further improve the models by adding more relevant features, and experimenting with different model architectures.
Our model targeting individual customers is currently deployed in production. Our model for optimizing the entire renewal cycle is currently running in A/B testing. We’re looking towards expanding our model optimizations from North America to all customers across the globe. There are also more complex model types that we can experiment with—including reinforcement learning—now that we have the data and production pipelines built. As we improve our models, we’ll focus on further improvements to our renewal success rates that will keep customers happy as well.
We're hiring!
The Applied Machine Learning team and ML Platform team at Dropbox use Machine Learning (ML) to drive outsized business and user value by leveraging a high-fidelity understanding of users, content, and context. We work closely with other product and engineering teams to deliver innovative solutions and features. It’s exciting to find opportunities within Dropbox to improve our processes and customer experiences by applying ML to new fields. We plan to continue to use the lessons from this project and apply them to other areas.
The Payments team at Dropbox enables monetization of new and existing products via a flexible payments and collections system and a smooth user experience. We leverage Machine Learning(ML) to optimize our billing and routing systems. We are also actively experimenting with ML based strategies for targeted payments and billing communications. In addition to directly impacting revenue these ML based approaches improve the productivity of the team and maintainability of our systems.
See open positions at Dropbox here!
Thanks to:
The Payments Engineering, Product, Revenue Analytics, and ML Platform teams for their continued partnership. In particular: Pratik Agrawal, Kirill Sapchuk, Cameron (Cam) Moten, Bryan Fong, Randy Lee, Yi Zhong, Anar Alimov, Aleksandr Livshits, Lakshmi Kumar T, Evgeny Skarbovsky and Ian Baker.


