

Filling out forms is stressful and boring, so people avoid it. If getting people to fill out forms is critical to your job or your business, you know what a big problem this is. HelloWorks is a HelloSign product that’s solving this problem through automating the process of converting PDF forms into an intelligent, mobile-friendly format that boosts accuracy and completion rates. Data collection is critically important both to the organization requesting the information as well as the person filling out the form. The end-to-end reliability of this process is one of its most important requirements, and one we’ve spent an incredible amount of time and effort on.
Kernel panic!
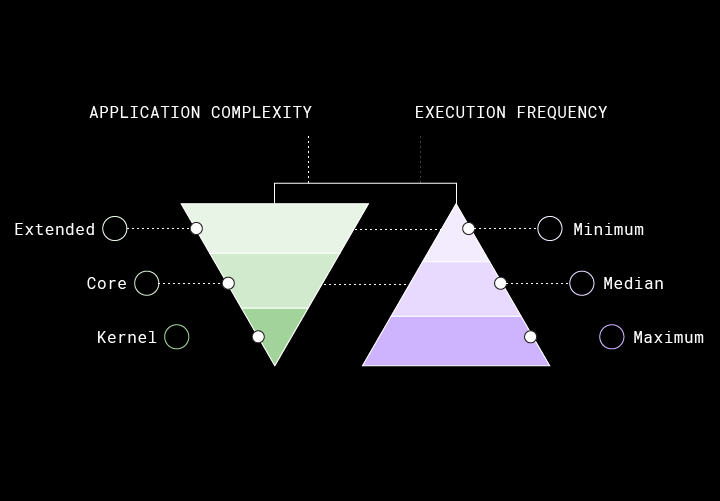
It’s the end of another chilly day as the setting sun turns the inhabitants of San Francisco into blind mice running through a maze. Meanwhile, another late night is slowly shifting to early morning, stuffed inside of a closet sized meeting room as we solve yet another gnarly technical challenge. Favoring speed over stability has led to increasing technical debt. After a couple months of dealing with the fallout, our engineering team took a step back to look holistically at why some unexpected behaviors were happening. We traced the overwhelming majority back to the application’s core. To fix this, we decided to bucket code into three tiers dubbed the error kernel, core features, and extended features.
An error kernel is the part of an application or system that should never fail. This is ideally as small as possible since the less surface area that it has, the less likely catastrophic failures will happen. When they do happen, the core system is small enough to reason about which greatly helps with triage and cauterizing of wounds.
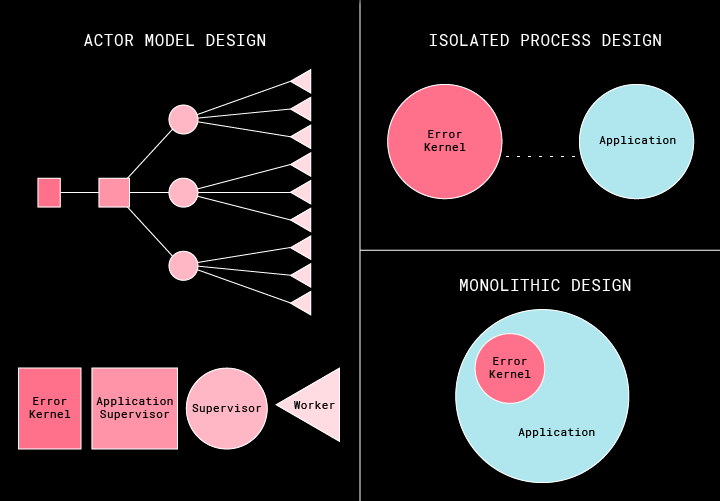
The book Reactive Design Patterns describes the principle of an error kernel as, “in a supervision hierarchy, keep important application state or functionality near the root while delegating risky operations towards the leaves.” What does that mean to the ordinary monolithic application designer? This concept originated in Erlang which is, humorously, an accidental real world implementation of the Actor Model. Having an actor framework would be helpful for most application developers, but the error kernel principle is still applicable without one. Using an error kernel helps you discover failure domains: the ways in which a method, module, service or function can fail in a system. In a monolithic application, it’s ideal to have a single core mechanism to handle all errors. This helps you understand what errors are recoverable, and which are critical because they contain the logic for what happens next. By tracing where failures occur in an application, the architecture becomes clear and reveals where weaknesses exist.
Another benefit of an error kernel is the prioritization of failures. The failures that occur inside of critical application infrastructure are the areas that need to be hardened and if possible isolated from the rest. This is what Joe Armstrong, one of Erlang’s original designers, meant by having an error kernel in general, not the specific actor model implementation of it. For example, HelloWorks has two independent error kernels for the two core services that we run. One is in our portal and the other is in the end-user application. Both involve the initialization and error handling of the services since without those nothing else is possible. The following illustration explains three valid architectural choices to designing an error kernel. In HelloWorks, we use the Actor Model design in our servers and the Monolithic one in our clients.
Regular application development doesn't touch the error kernel much since it's intended to be small. Most of the action is in the next tier, core features. These are areas where the system can recover from issues but it will require significant effort. Things like data corruption and inconsistencies are painful but ultimately recoverable events in most scenarios. The core business logic of an application falls into this tier. Some might think that critical business logic should reside inside of the error kernel since without the business logic there is no value to the application, but the problem here is with application stability. If an application keeps falling down because of a critical business logic failure, this is an infrastructure and architecture problem. Infrastructure should remain stable and available regardless of the business logic, even when it’s wrong. In our two core services, building and running a workflow are two examples of critical business logic. Most other things fall into the last tier, extended features. These are the things that are irritating to a user when they go wrong but can be fixed with minimal risk.
Just adding layers to the pyramid that was described above is a semantic change but not really an architectural one. Bucketing features and development this way gives teams a common language to use across engineering, product, and design. This helps to specify the complexity of features and how fundamental they are to a system. Thinking about the application this way quickly answers questions such as whether or not a feature can be hacked together quickly or if it really needs to be thought about deeply, indicating how fast you can reasonably expect it to ship. In other words, things that only affect the extended features can be developed quickly and hacked together in a short period of time since they do not have a lasting impact on any other critical system components. Extending the core system to support a new type of launch mechanism is inherently riskier which means it needs to be tested at a higher level before being released into the wild.
The question then becomes, how do we rigorously test our error kernel and our core features so that we can reliably build new features and extend core mechanisms of the system reliably? Most systems don’t require formal verification which ties the application to its implementation strictly making changes costly to verify. A happy medium between flexibility and ease of use is property-based testing, which validates the behavior of systems. This approach allows for moving quickly to build the right thing while still being flexible with requirements. It also turns the mind-numbing task of writing tests into the intellectual challenge of automating the writing of tests. Mentally, there is a paradigm shift which turns programs into properties that hold true rather than a series of tests to pass. Writing properties allows for the possibility to both check and define the invariants of a program. What makes the method impressive is how it treats test failures. When a complex failure is discovered, the case is shrunk down to its simplest form, its principle, making it easier to understand.
At a high level, a property test will include a generator and a property. A generator is a description of data that will be the input of the module to be tested. A property is a generic outcome that is always true based on the generated inputs to the module being tested. Applying the same logic from math, the example is a simple demonstration of a property that is easy to reason about. Here’s an example closer to home. Every successfully saved object in a database is retrievable by a UUID. The following properties are:
- Only one object is retrieved on a successful save.
- The object remains unchanged after being saved on retrievals.
- Every object of type X can be saved.
- No database row exists when retrieving an object from a UUID that does not exist.
- UUID should not exist when there is a failure to save.
Generators are different than fuzzing because they define a problem-space. The generators do this by limiting the range of randomly generated values.
A brief guide on how to save the day
The superpower that property testing has is its ability to find bugs before users report them. In many cases, those bugs are non-trivial edge-cases, although it finds trivial ones too. A few really-easy-to-implement property tests that add relatively high value quickly can be done on code paths centered around regular expressions. Creating a generator that can build the expected string input can test a module so that the regex either does what is expected or catches all the failure that passes through validation. For example, when a regex is being applied as a filter to prevent invalid input into another function, it becomes a simple way to test both the validator doing its job and the function it’s passing its filtered input into. That was a mouthful, in other words:
fn send_email(msg, addr) ->
if valid_email_addr(addr) {
really_send_email(msg, addr)
}
end
property status_code(200) == send_email(msg, generated_valid_email_addr)In this case, assuming perfect network stability, two classes of errors are possible from the addr variable. The first is that the validator itself fails never sending any email. The second is that really_send_email is called but it fails due to a bad address that passed validation addr. Here, we're able to catch two potential classes of bugs with a single property test! It also makes unit tests in three locations redundant for the most part.
Modeling
The modeling pattern is building a property test that re-implements the same system that is being tested but in a way that makes the outcomes obvious. By eliminating optimizations and other unnecessary code like logging, the model system becomes easier to reason about. The nice thing about this approach is that once its built, there is a true equivalency test to base any future modifications to the production system on. This actually allows people to refactor the system without affecting the behavior of it in order to either extend or optimize it further!
Symmetric Properties
It’s not always feasible to create models and so there is another class called symmetric properties. These are highly useful for systems that translate data from one representation to another. Think about data serialization, marshaling, and encoder/decoder combinations. These always have the flavor of an identity proof which probably seems obvious to some. What makes property testing desirable here is the generated data is able to test the entire problem-space instead of a few examples that are known to be correct. This property can be summarized as:
fn encode(x) -> ...
fn decode(y) -> ...
property input == encode(decode(input))
property input2 == decode(encode(input2))Stateful Properties
So far, these tests have focused on stateless properties but all of these techniques equally apply to stateful properties. These tests are more advanced but worth the effort. Many systems have states that transition from one type to the next. Stateful properties make it possible to traverse the problem-space, or rather, all of the allowed state transitions. Using example-based scenarios can leave a lot of gaps because they're always testing the same scenarios without variation. Building a model to test these transitions helps engineers understand the complexity of a system and eliminate errors before testing is even complete. This makes stateful tests incredibly valuable because intermediary transitions in many systems can loop between transitions infinitely many times. By utilizing them, new state transitions will be traversed on each run with the potential to catch inconsistent behavior through the complex interactions of data manipulations between the different state transitions.
How to Ruin the Day
When I first started pursuing property testing, I bundled a bunch of properties together with a single generator. This was a terrible idea for a few reasons.
- It made the generator's code unnecessarily complicated
- When properties do fail their tests, it is very difficult to know what specifically generated the failure, making them more difficult to debug
- The tests will run slower since the generated inputs will be larger since there are more of them
- The tests might actually contain less diversity in the generated values by bundling properties and generators together
The reasons they seem like good ideas are the following:
- Bundling treats a single generator like a master generator, making it possible to use the same generator to test all properties on a given entity
- It's less route work which removes the ceremony and boiler plate that comes with it
- In some cases, tests may run faster but the more complicated generators become the more time it takes to generate inputs
- The speed-up comes from generated inputs that can be reused to test multiple properties
In the email example, if we also tested the msg variable, it would be harder to guess if the test failed due to an invalid addr or invalid msg. For this reason, isolating individual properties and generators make them easier to read, write, and diagnose failures.
msg = generate_msg()
addr = generate_addr()
# if this fails then who is responsible?
property status_code(200) == send_email(msg, addr)
# better to separate properties like this so failures are clear
property status_code(200) == send_email("valid message", addr)
property status_code(200) == send_email(msg, "asdf@qwerty.ai")
# targeted unit tests are clear and quick but writting many becomes burdensome
test status_code(200) == send_email("\"; drop table students;", "simple@email.com")
test status_code(200) == send_email("message", "a.b.c+1234@hack.io")In the code snippet above, the last point is that while unit tests can be quick and clear, if there are a lot of test cases then it would also require updating all the test cases when requirements change. For instance, if we pass back a 300 on the status code instead of a 200, then updating a large number of unit tests would be very annoying but updating a couple property tests that generate many test cases is far less daunting. Ultimately, this makes clear generator targets and clear properties very valuable.
How we use property testing
Property testing is a continuous and evolving process. Currently the forms in HelloWorks contain complicated logic within them that is not directly noticeable at first glance when building them. Both the building and publishing phases are currently undergoing some remarkable work but part of this stabilization process uses modeling as described above to remove inconsistencies and detect errors.
As we move away from a validation-based system and towards parsed-based language, we’re ensuring the stabilization of features that extend what can be built inside a form and how they're run. Since regressions in behavior are more visible, we can extend these features without sacrificing the customer experience. There are a few DSLs that get translated into protocols that other services speak. Those are the locations where we use symmetric properties. We’re continuing to work on our job executor to model stateful properties and this process is already yielding great results even though it’s still in its early stages.
The other place that we're actively working on is our PDF mapping logic. We already use some basic property tests there, but our next step is to make mappings as robust as possible so we catch issues before a customer publishes their forms rather than when their users fill out the documents. This is one of those places where property tests can still solve the problem but a different approach might be just as robust and much quicker to implement.
So far, property-based testing has had a lasting impact on our approach to building reliable software. Using them has brought to light many issues, both with our services and others. A few notable ones:
- It has caught issues with database adapters when there was a need to swap them out
- Unintentional changes to existing behaviors were found when adding new features to our form editor
- Five separate inconsistencies were found with our JSON Schema that were remedied just by building the tests (not even running them)
- Catching issues storing specific types of strings at the database level
One ongoing battle is trying to figure out ways to quickly on-board people to using property testing. There is a steep learning curve and it’s hard to know where this approach adds value without any intuition on why it might be effective. Overall, property testing has been a high net-positive. Even if no one else on the team understands how to write property tests, when they fail it is clear why. They provide true equivalency testing to the team which is a gift that keeps on giving. It's been about eight months since the more complicated tests first shipped and there hasn't been a need to modify or correct them for six! Unit tests seem to come and go pretty quickly as they tend to focus a lot more on implementation details, even when the best effort is to test behavior. The initial cost of property tests are high but diminish as the team becomes more familiar with them, allowing engineers to build more interesting things quickly and stably.
Conclusion
Building a mental model for the tiered application structure and pairing that with property based testing has produced the side effect where multiple humans are no longer crammed into a makeshift closet sized war-room. Since application tiers account for a system’s sub-component priority, the areas to get hardened through property testing are clear. Because we have clear boundaries, each sub-component gradually becomes more isolated from external dependencies making their behaviors easier to test. Now when I come to work, I don’t feel like I’m fighting a battle in the dark that can’t be won. Instead, I leave the office before the sunlight disappears for the day!!
Acknowledgements
I’d like to say thank you to Garret Smith, Nick Ball, Benny Kao, Sheryl Chui, Santhana Parthasarathy. I’d also like to thank the rest of the HelloWorks and HelloSign teams for supporting me along the way. Fred Hebert has been an inspiration and influence in my development as the abundance of material that I learned directly from belong to him. Also, I wouldn’t even have bothered writing if it weren’t for the love and support of my wife and daughter. Thank you to Fanny Luor for making the graphics look great. Lastly, here’s to you!
Thank you!
If you enjoy, we’re hiring!


