

Today the Apache Software Foundation announced Apache Superset as one of its official top-level projects. Apache Superset is a modern, open source data exploration and visualization platform already in use at Airbnb, American Express, Lyft, Nielsen, Rakuten Viki, Twitter, and Udemy among others.
I worked on Apache Superset at Airbnb in its early days. When I came to Dropbox in late 2018, I got to continue working on it as a side project. Eventually, the company decided it was important enough to our internal needs to put our full attention to incorporating Apache Superset as our data exploration platform. We’ve been using it in production since early 2020, expanding its use until it became our main data exploration tool.
Our choice of Apache Superset wasn’t cut and dry, though. I’ll explain what alternatives we looked at, and why we chose Superset. Of course I think it’s great, but for your own purposes it’s important to choose the tool that solves the most important real problems you have.
Problems we started with
As many companies of our size have done, we had built a number of internal tools to help engineers, analysts, and business stakeholders with their analytics needs. At one point we had more than 10 different data visualization solutions in order to:
- Monitoring and ensuring uptime
- Performing migrations as needed
- Piping data between systems
- Ensuring correct access controls
- Data governance
- Onboarding users into these systems
- Providing on-demand user support
In late 2019, we decided to consolidate our data exploration tooling and introduce a single solution. For our needs, it would need to be able to:
- Transform SQL queries into charts with minimal friction
- Enable quick data exploration for ad-hoc analysis, without needing to design a dataset first
- Allow users to create charts and dashboards that could be shared with others
- Encourage re-use of queries through customizable macros
- Consume data from our centralized data store (Hive and Presto clusters on top of S3 data)
Evaluating data exploration tools
Most of our dashboarding and data visualization needs could be classified into three buckets:
- Business analytics: exploration and investigation of past business performance to gain insights, identify trends, evaluate ideas and experiments, and size up opportunities.
- Operational analytics: investigation of our operational systems, especially software ones (software reliability, trends, debugging, etc).
- Automation of repetitive tasks: as a data-driven company, there was a lot of demand for report automation—monitoring system health, reviewing team metrics, measuring OKRs, etc.
To arrive at the right tool, we prioritized the following capabilities in descending order of importance:
- Security: Data visualization tools have access to sensitive data. We need first and foremost to ensure that data access can be governed and audited, and that we are following the best practices of the Dropbox security team.
- User friendliness: A shallow learning curve, good documentation, and good support were our top priority after security, so that insights from data can be generated quickly. A steep learning curve has historically been one of the major adoption blockers of any data visualization or dashboarding tool we’ve deployed.
- Maintainability: Minimize the maintenance cost of the system, which breaks down to two key factors:
- End users should have minimal overhead to maintain their charts and dashboards.
- The Data Platform team should be able to ensure continuous support of the tool and its development.
- Flexibility and extensibility: Seamless integration into the ecosystem of data infrastructure tools and adaptability to future needs is a plus, but not as important as user friendliness and maintainability for us.
While data processing and data visualization are critical to our business, they are neither our core competency, nor are they a competitive advantage themselves. Building best-in-class tools requires a lot of long-term investment and has proven to be a challenging task.
Our general philosophy is to buy a solution that satisfies our need whenever possible, or leverage an open source initiative. We will build a tool in-house only if neither of the first two options are possible.
With all this in mind, we created a list of properties we were looking for in a data exploration tool:
- Preference to buy a solution or leverage open source rather than build
- Minimize the number of solutions needed to cover our internal use cases
- Optimize for ease of iteration and dashboard creation
- Encourage the right behavior and ETL best practices in data quality
- Maintain a clear delineation between visualization and data processing
- Stay as close as possible to the source of truth
- Delegate computation to the database engine
- Minimize the number of intermediate layers or configurations needed to build a chart
Why we chose Superset
As our table below shows, no one option is the best at everything. They all have unique strengths. Periscope (recently renamed to Sisense) allows drag-and-drop interfaces and works with any git server. Mode’s implementation of topics and cross-topic searches is impressive. Redash has alerts today which Superset has only begun to develop, plus a user activity log not found in some other solutions. Metabase is also worth considering, but we ruled it out for Dropbox because it is written in Clojure, which is neither adopted internally within Dropbox engineering, nor supported by our current infrastructure.
For us, Superset offered abilities that mattered to our internal users, who want to get answers without writing SQL and for whom time and effort creating visualizations needs to be minimal. The ability to create reusable virtual table columns and metrics that are shared across teams is a big plus for them. Access control list granularity helped us meet the high security expectations we have at Dropbox, streamline data access and cross-team sharing, and minimize support and administration work. Superset’s API for creating charts powers a couple of internal tools and has saved engineering time when building custom visualizations. And in daily use for busy people, a progress bar is more helpful than you might realize.
In short, we chose Apache Superset because it was the best match to our specific internal needs. We were ready to invest engineering effort to close the gaps wherever needed.
We also enjoyed contributing the following features back to the Superset project:
- Alert improvements
- Schema permissions model
- Slack integration
- Presto and Hive support in CI
- And more!
As part of our decision-making process, we created this table which lists the key properties of the leading contenders. We’re happy to share it to help you make your own decisions.
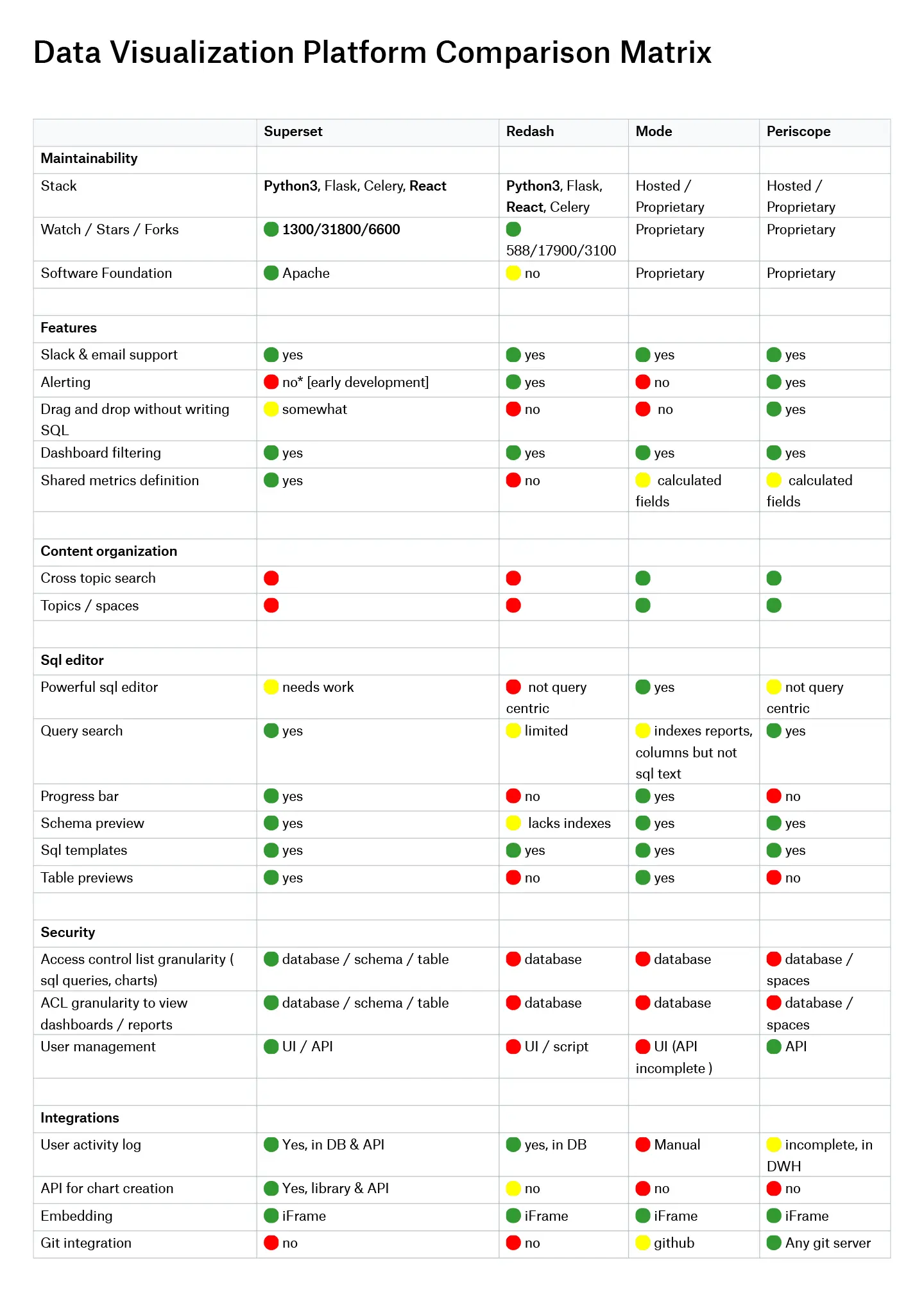
View or download the full-size comparison matrix here.
Results
Six months after we bet on Superset, it’s clearly been a big success at Dropbox. Superset had quick and strong adoption across the organization, and is now the main data exploration tool for our data warehouse. It has helped a number of teams to improve their workflows—so much so that they agreed to be quoted:
It's been a game changer for us. It is much less friction than the previous flow, and it makes it easy to add new metrics. We'll be able to get much more visibility into how the various aspects of the sync engine are working, which will help us detect issues earlier and minimize their impact on our customers. —Core Sync Team
Superset is great, the speed of queries is astounding! It has been a big upgrade for the team over our legacy tools and the dashboards are much easier to build. —Product Analytics
Their praise is quantified by a chart of Superset’s Weekly Average Users at Dropbox following rollout:
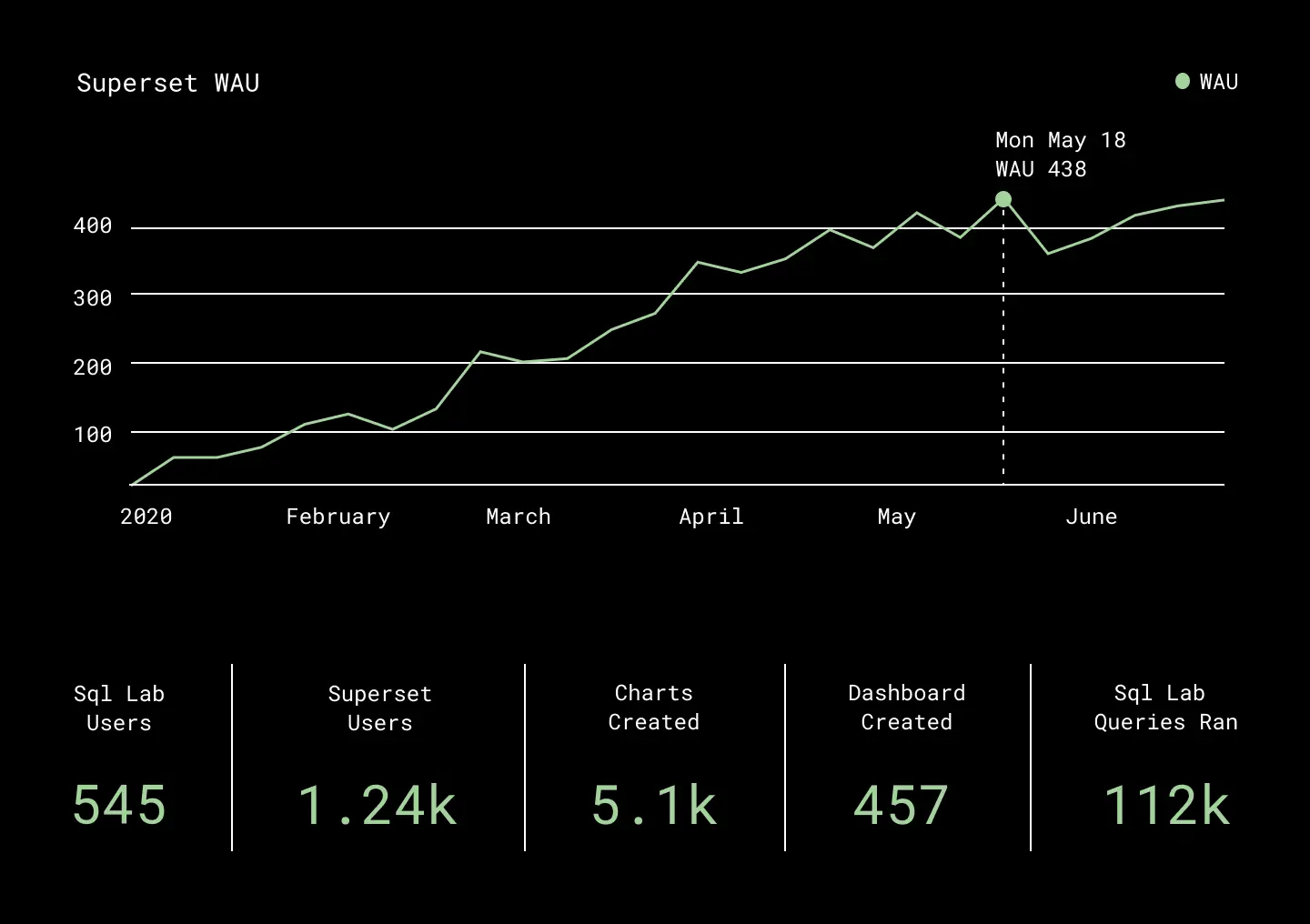
Superset Weekly Average Users trend following initial rollout (top), overall users and content created (bottom)
Choose the best solution for your own biggest problems
I’m proud of what we’ve built with Superset, but you should research and decide what your own priorities are before committing to a platform. In our case, user-friendliness was more important than flexibility and extensibility. Apache Superset stood out to us in ease of user adoption, yet was flexible enough to meet our needs.
We’re lucky to be living in a time where there are a number of great solutions on the market that can provide powerful data exploration capabilities to your organization. We hope this post helps you make your own best decision.


