

Dropbox originally used Amazon S3 and the Hadoop Distributed File System (HDFS) as the backbone of its data storage infrastructure. Although we migrated user file data to our internal block storage system Magic Pocket in 2015, Dropbox continued to use S3 and HDFS as a general-purpose store for other internal products and tools. Among these use cases were crash traces, build artifacts, test logs, and image caching.
Using these two legacy systems as generic blob storage caused many pain points—the worst of which was the cost inefficiency of using S3’s API. For instance, crash traces wrote many objects which were rarely accessed unless specifically needed for an investigation, generating a large PUT bill. Caches built against S3 burned pricey GET requests with each cache miss.
Looking at the bigger picture, S3 was simply an expensive default choice among many competitors—including our own Magic Pocket block store. What we really desired was the ability to expose a meta-store, transparently backed by different cloud providers’ storage offerings. As pricing plans, access patterns, and security requirements change over time and across use cases, having this extra layer would allow us to flexibly route traffic between options without migrations.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Another desirable side effect of routing all blob traffic through a single service was centralization. At the service layer, we could provide additional features like granular per-object encryption, usage and performance monitoring, retention policies, and dedicated support for on-call upkeep.
We built this service in 2020 and gave it the pedestrian name Object Store—but its impact has been anything but. Thanks to Object Store, we’ve been able to save millions of dollars in annual operating costs.
How Object Store works
Object Store doesn’t directly implement data storage. Instead, it acts as an abstraction over multiple storage backends, routing PUTs to the most cost-efficient store and GETs to the correct store. It is backed by a MySQL database to track object placements in these persistent stores.
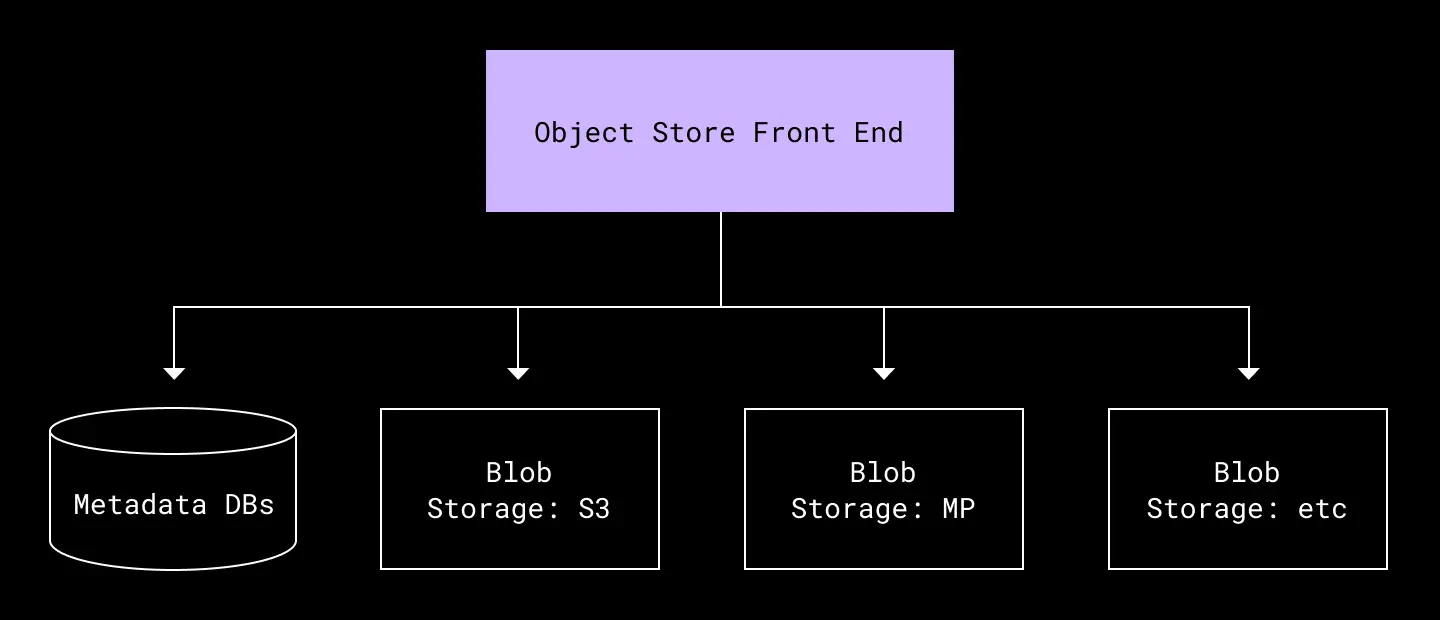
A simplified diagram of Object Store’s architecture
The API is equivalent to a simplified S3 API with PUT, GET, DELETE, and LIST. Access is segregated by pails, which are analogous to S3 buckets—containers for objects with shared configuration and ACLs.
PUT and GET
Object Store cuts costs by batching writes. On receiving a PUT(key, blob), the request servicing layer enqueues the blob in memory with other PUTs to the same pail. Upon queue timeout or reaching a certain aggregate request size, the queue’s requests are concatenated into a single batched blob and written to persistent storage—whether that be S3, Magic Pocket, or some other service in the future. Once this write completes, Object Store records the metadata in two MySQL tables:
- A batch row to record the batched blob’s key in the persistent store
- One or more object rows representing the original blobs submitted in each PUT request, which map object keys to start and end offsets in the batched blob, as well as the batch row itself
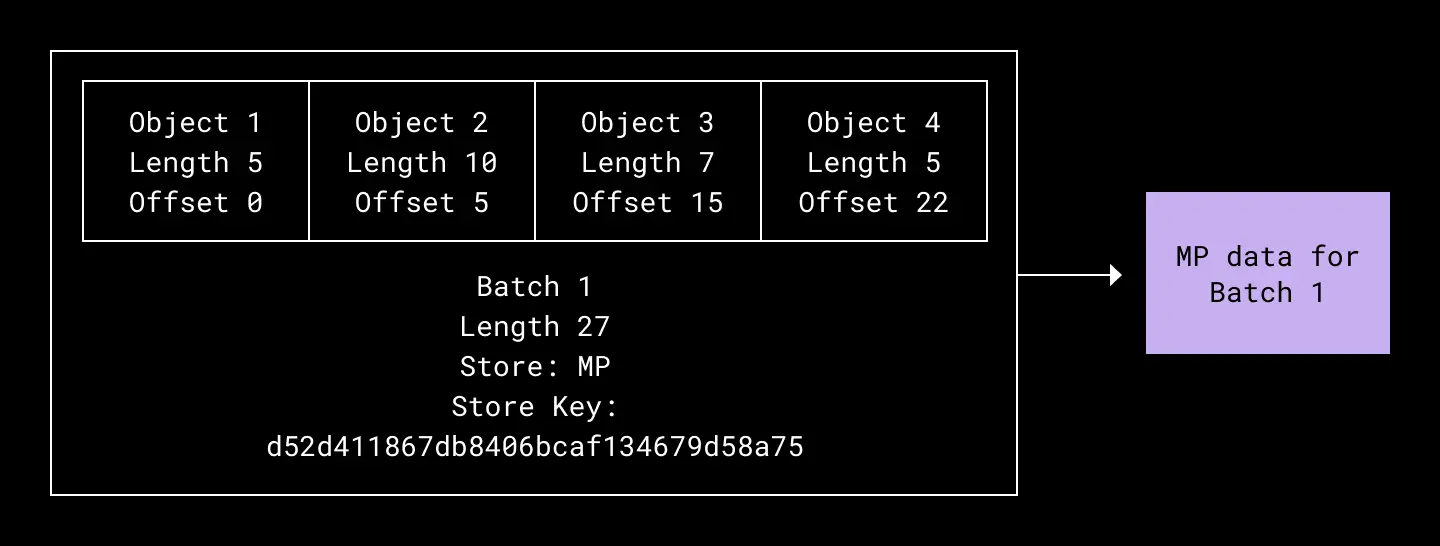
One batch contains many objects and corresponds to an underlying store blob. Objects are identified in the batch by length and offset
Each GET(key) involves a fetch and a slice. Object Store recovers the object and batch metadata from the key, then performs a ranged read on the batched blob in persistent storage using the object’s start and end offset as range delimiters.
This design solves our two biggest cost inefficiencies in accessing S3. A quick inspection of S3 pricing shows that users pay per gigabyte stored and per API request. By reducing the number of PUT requests for the same total volume of data, we save money. And when we use S3 as a cache, Object Store short-circuits S3 GETs during the nonexistent read case, cutting more API requests.
The MySQL and service clusters don’t run for free, but their cost is still a fraction of the API costs saved. In fact, by rerouting some writes from S3 to Magic Pocket, and making our remaining S3 requests more cost efficient, Object Store has helped us save millions of dollars each year.
The batched write model is not only useful for reducing our S3 costs, but is also necessary to shape stable traffic patterns to our internal blob store Magic Pocket, which was designed to run optimally with a homogenous 1-4 MB object size. By batching small PUTs we get closer to that optimal size, while also reducing the request rate to Magic Pocket servers.
Encryption
Encryption is handled by Object Store, regardless of the underlying storage destination. For every write, there are two levels of encryption that take place:
- Raw object blob data is padded and encrypted with the AES-256 cipher and a 256-bit block encryption key (BEK) before it is written to the underlying store. Each BEK is unique per object
- The BEK is encrypted (wrapped) by a versioned global key encryption key (KEK). This encrypted BEK is stored as part of object metadata in MySQL
Encrypting the BEK before storing it as metadata adds an additional layer of security. With this scheme, Object Store data can only be accessed with all three of the following: (1) the stored encrypted data (2) the encrypted BEK from metadata (3) the KEK.
The second advantage of encrypting the BEK is that it allows us to rotate encryption keys regularly. If we stored the raw BEK, key rotation would require reading and rewriting encrypted object data—a costly operation. With encrypted BEKs, key rotation can be done by decrypting the original BEKs, then encrypting them with a new KEK. This operates purely on metadata and is much cheaper—cheap enough that we regularly rotate KEKs as a matter of security hygiene.

Encrypted keys are stored as part of object metadata
DELETE
Batching adds complexity to the deletion path. Deletion typically means rendering an object inaccessible to reads. When storing personally-identifiable user information, Dropbox uses a stricter definition: not only must the object be unreadable from a client-facing API, but the data itself must be purged from Dropbox infrastructure and S3 within a certain deadline after the DELETE request. This means every object blob PUT into S3 or Magic Pocket must have a corresponding DELETE, negating the advantages of batched PUTs. It doesn’t matter how efficiently we cut down PUT volume if high DELETE volume becomes the dominating cost.
One possible solution is to also apply batching to DELETEs—which is what the first Object Store iteration did. Object Store marked the object metadata as deleted and failed any incoming reads. Simultaneously, we ran an asynchronous walker that picked out batched blobs whose objects were all deleted, and purged them from S3. This removed the overhead of multiple DELETEs and ensured DELETEs maintained cost parity with PUTs.
However, the objects in a blob weren’t guaranteed to all be deleted within the same time window. Therefore there was also a second asynchronous compaction walker that found batches containing one or more deleted objects nearing the purge deadline. These batched blobs could not wait for their remaining live objects to be deleted; everything had to go immediately. The batched blobs were compacted: broken down into live objects, merged into fresh new blobs, and rewritten both in metadata and to persistent storage.
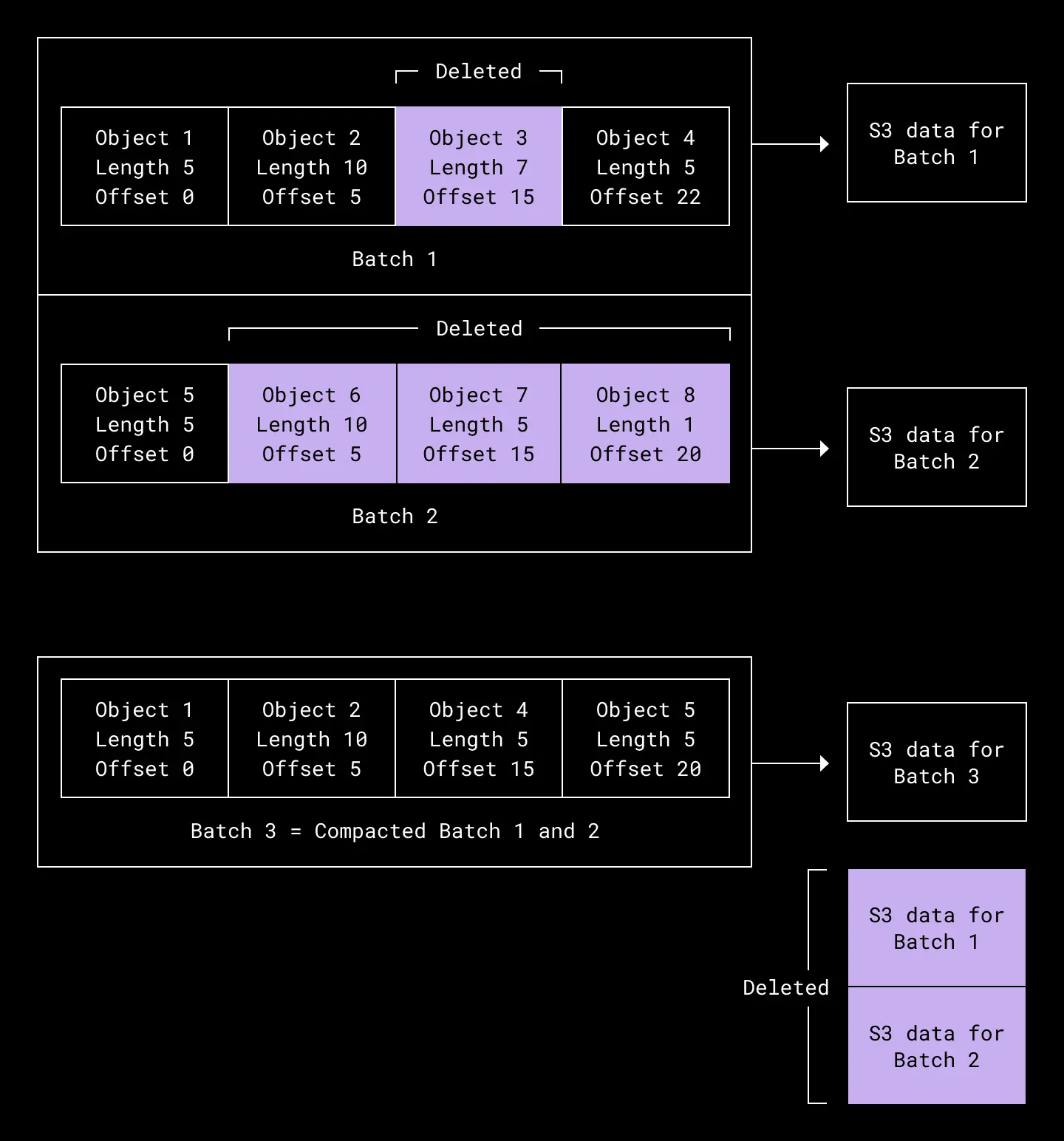
Batching meant our initial approach to object deletion involved compaction
Batched deletion with compaction worked but was difficult to maintain. Compaction bugs required forensics to reconstruct and undo. Batched deletions weren’t guaranteed and compaction itself generated PUTs, so costs weren’t optimal. Lastly, our deletion policy hinged on the compaction walker running regularly and quickly, which ate up maintenance effort.
As an alternative, per-object encryption let us simply implement deletions using the original naive approach of wiping the object metadata. Without the key, the object’s information is effectively wiped from persistent store…but without making an explicit data DELETE request. No deadline management, no compaction—instead, DELETEs occur synchronously with a MySQL operation. This technique, called crypto-shredding, provides instantaneous deletion for compliance purposes while asynchronous space reclamation works through at a slower cadence.
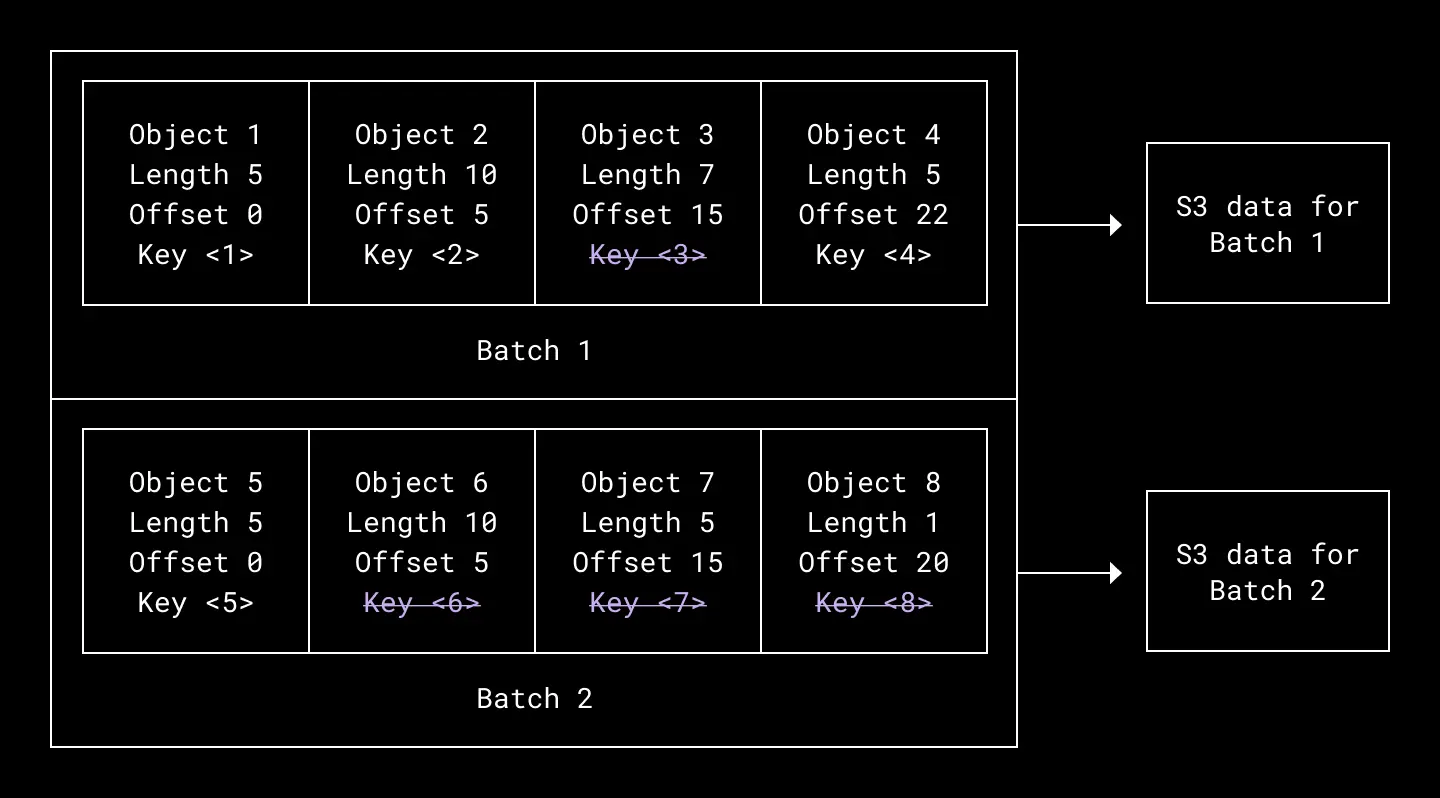
Eventually, we settled on a crypto-shredding approach to object deletion—no compaction needed
Chunking
We’ve described how Object Store batches small PUT requests and slices the corresponding GETs. What about slicing a single large PUT request and combining the corresponding GETs? Originally this wasn’t necessary, as fewer small PUTs meant lower AWS costs. Upon shifting our workload to Magic Pocket, though, we found that the 4MB size constraint made storing larger objects cost-ineffective and even infeasible. This led to a dark period where our routing code crudely operated as:
if object.length > 4 * MB:
store = STORE_S3
else:
store = STORE_MPTo squeeze out further performance from the Magic Pocket write path, we implemented object chunking. This breaks objects larger than 4MB into 4MB chunks and stores them in Magic Pocket separately. At read time, Object Store fetches the component chunks in parallel from Magic Pocket and reconstructs them into the original object. To avoid creating more metadata overhead to track the multiple Magic Pocket chunks, the system instead stores a base key and deterministically computes the Magic Pocket keys from that base at read and write time.
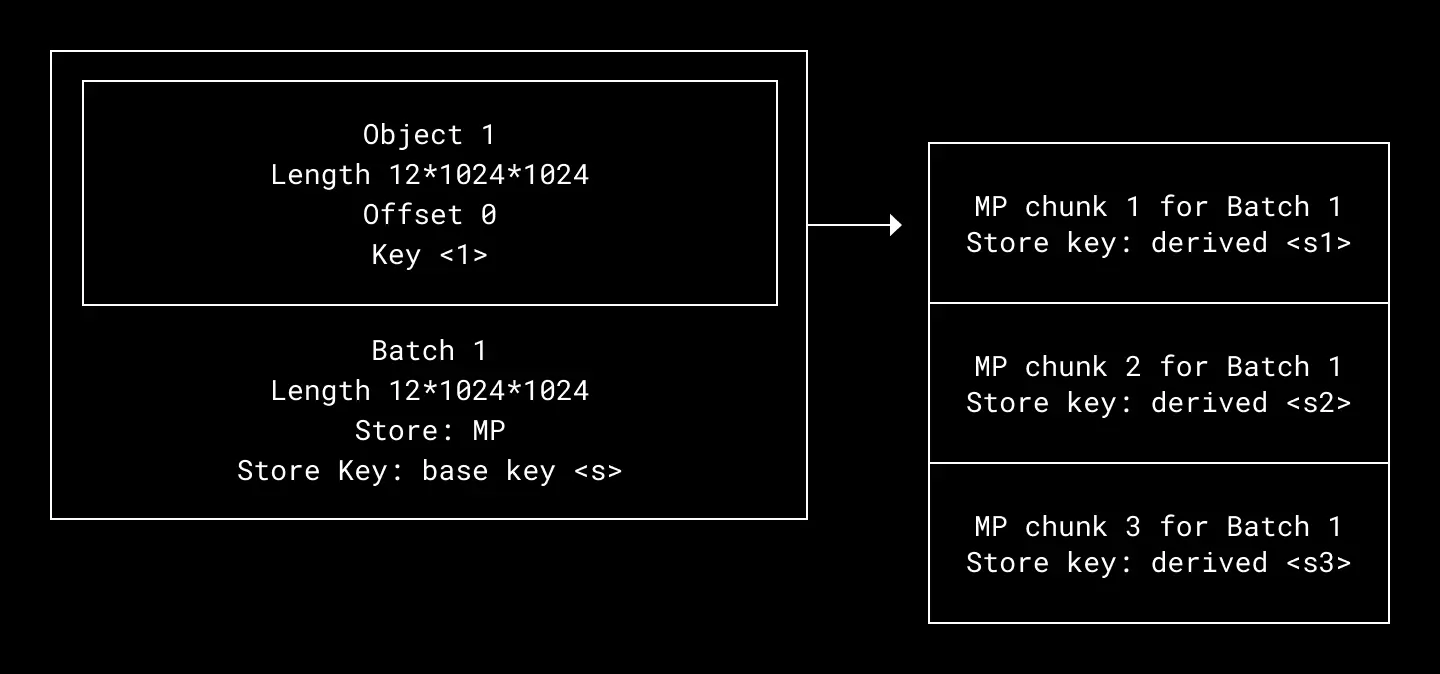
Chunking objects means not only can we store many objects in one blob—we can also store one object across many blobs. Magic Pocket keys are derived deterministically from a single database key
This last optimization, completed recently at the end of 2021, elevated Object Store to a general purpose system that accepts data of any size and repackages it into optimally-sized chunks for backend storage. With this powerful chunking support we deprecated the majority of our HDFS usage at Dropbox, saving us millions of dollars in annual operating costs.
What’s next for Object Store
Object Store is an important strategic pivot for Dropbox’s data storage infrastructure. It gives us a standardized interface under which we can transparently shuffle data between various cloud providers depending on pricing models and compliance requirements, while also providing optimizations and features of its own. We originally designed the system explicitly for non-file data—raw Magic Pocket is the primary store for user file blocks—but after seeing how useful it’s been, we’re planning to migrate subsets of user file data to Object Store. Future directions include:
- Lambda functions support for object writes and modifications
- Using Object Store as a backend for storage systems like Cassandra or RocksDB. This will allow us to run these systems on diskless compute hosts while using Object Store as an exabyte scale remote disk
- Using Object Store as a backend for third-party systems that allow pluggable object storage, like Apache Pinot and Loki
From this tour of Dropbox’s internal systems, it should be clear that we enjoy getting to work on interesting technical problems. If building innovative products, experiences, and infrastructure excites you too, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


