

Introduction

With hundreds of billions of files, Dropbox has become one of the world's largest stores of private documents, and it’s still growing strong! As users add more and more files it becomes harder for them to stay organized. Eventually, search replaces browsing as the primary way users find their content. In other words, the more content our users store with us the more important it is for them to have a powerful search tool available. With this motivation in mind, we set out to deploy instant, full-text search for Dropbox.
Like any serious practitioners of large distributed systems our first order of business was clear: come up with a name for the project! We settled on Firefly. Today, Firefly powers search for all Dropbox for Business customers. These are the power users of Dropbox that collectively own tens of billions of documents.
This blog post is the first in a series that will touch upon the most important aspects of Firefly. We will start by covering its distinguishing characteristics and explain why these lead to a non-trivial distributed system. In subsequent blog posts, we will explain the high-level architecture of the system and dive into specific details of our implementation.
Goals
- Scale: The total number of documents that are represented in the search index (typically an inverted index used to efficiently perform search). From the perspective of a Search Engine, files of all types (docx, pdf, jpg, etc) are colloquially referred to as documents.
- Query latency: The time taken by the system to respond to a search.
- Indexing latency: The time taken by the system to update the search index to reflect changes, such as the addition or modification of a document.
Wait, why is this a hard problem?
At first glance, this might seem like a simple problem for Dropbox. Unlike a web search engine (such as Google), every search query only needs to cover the set of documents a user has access to. So why not just build and maintain a separate index for each Dropbox user with each stored in a separate file on disk? After all, one would rightly expect the distribution of Dropbox sizes across our user base to follow a Zipf distribution — a large fraction of users would have a small number of documents in their Dropbox. For these users, the corresponding search index would be relatively small and therefore easy to build and update as documents are added or modified.

There are two main drawbacks of this approach. Firstly, we expect some users to have a large number of documents in their Dropbox, making it non-trivial to update their corresponding index “instantly”. Secondly, this approach requires the system to maintain as many indices as there are users with each stored in a separate file. With over 300 million users, keeping track of so many indices in production would be an operational nightmare. We like to sweat the details here at Dropbox and would hate for even one of our customers to have problems searching because of an issue on our side. Having such a large number of index files would impair our ability to effectively and precisely monitor issues affecting a small fraction of our users.

Clearly we need a design that will create fewer search indices but now we have another problem: if we slice the complete search index into 1000 pieces each piece becomes pretty large (reflecting the Dropbox content for over 100 thousand users). How do we update such a large index “instantly”? To achieve this goal we need a system that supports incrementally updating the search index: a challenging task with billions of documents and millions of users.
How do you slice the search index?
In the discussion above we concluded that for the system to be both fast and operationally viable we needed a relatively small number of slices. In this section we take up a related question: what is a good way to slice the search index? In other words, how do we assign documents to a given slice? In distributed systems parlance the slices are commonly called shards and the deterministic function which maps a document to a shard is called a sharding function.
One additional dimension of complexity is that a Dropbox user may choose to share a folder with multiple other users. Files in a shared folder appear in each member’s Dropbox. So if we picked a sharding function based on user-id, a shared file would appear in the index multiple times, one for each user that has access to it. For efficiency, we wanted each user file to appear exactly once in the index.
As a result, we chose a sharding function based on “namespace”. A namespace is a widely used concept in our production systems. Internally, we represent a user’s Dropbox as a collection of namespaces. Each namespace consists of files and directories, along with a directory structure, and is mounted at a certain directory path within a user’s Dropbox. In the simplest case, a user’s Dropbox consists of just one namespace mounted at “/”, which is called the “Root” namespace.

The concept of a namespace makes it easy to support the notion of shared folders. Each shared folder in Dropbox is represented by a separate namespace. It is mounted at a certain directory path within the “Root” namespace for all users with whom the folder has been shared.
Dropbox manages billions of namespaces. We use a standard hash function as our sharding function to divide them into a relatively small set of shards. By pseudo-randomly distributing namespaces across shards, we expect the shards to be roughly similar in terms of properties such as number of documents, average document size, etc.
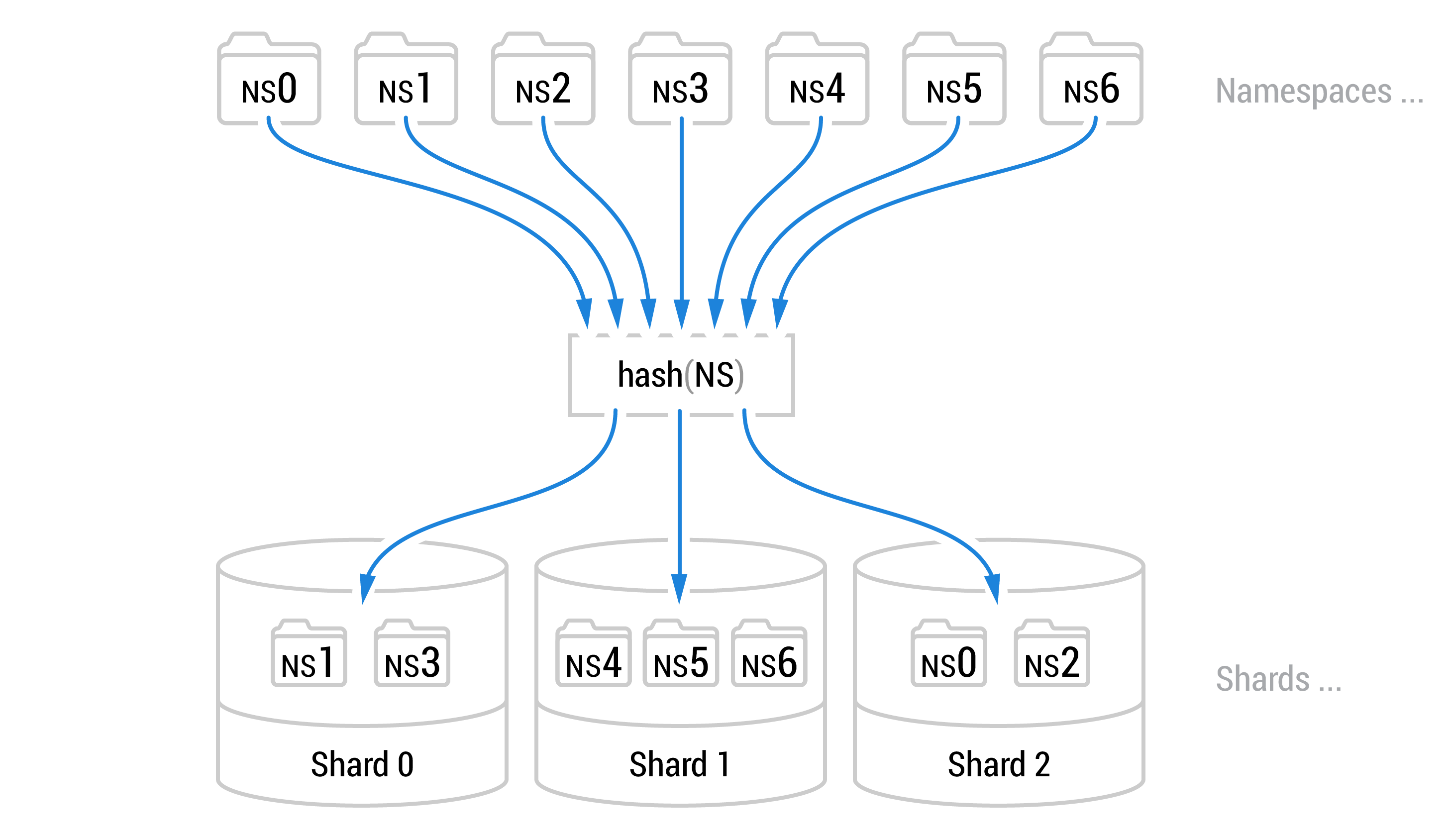
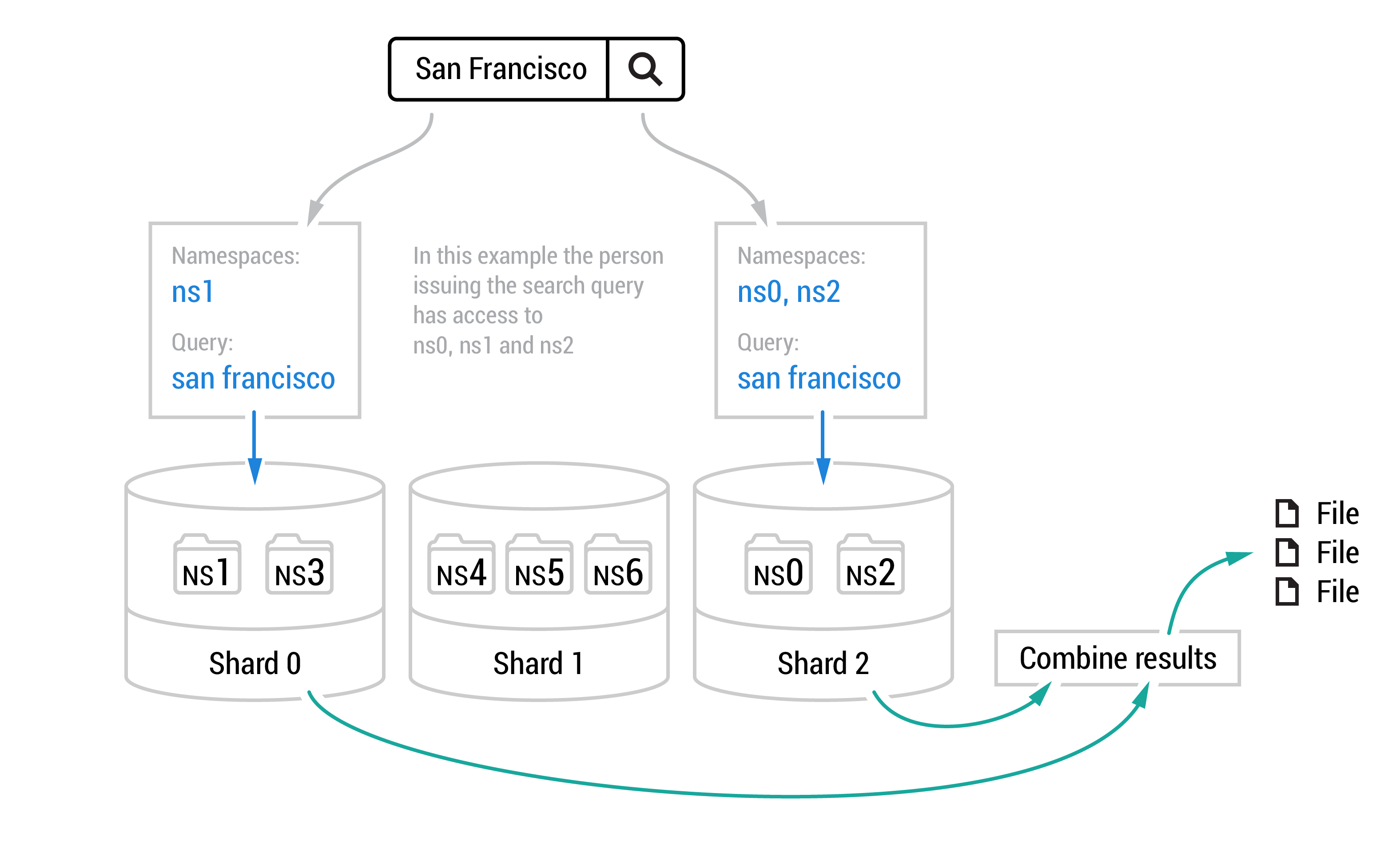
Conceptually, the search index contains the mapping: {token => list of document IDs}. If a user with access to namespace with ID ns1 issues the query “san francisco”, we tokenize it into tokens: "san" and "francisco", and process it by intersecting the corresponding list of document IDs. We would then discard all document IDs that do not belong to namespace ns1.
This is still inefficient, as a shard typically contains a large number of namespaces (in the millions), while a user typically has access to a handful of namespaces. To make the query processing even faster, we prefix each token in the search index with the ID of its namespace: {namespace-id:token => list of document IDs}. This corresponding list of documents contains only those that contain the token and are also present in the namespace. This allows us to focus our processing on the subset of the search index that is relevant to the set of namespaces that belong to the user. For example, if a user with access to the namespace with id ns1 issues the query “san francisco”, we process it by intersecting the list of document IDs for tokens: "ns1:san" and "ns1:francisco".
Leveraging open-source solutions
Before we embarked on building Firefly, we considered whether we should leverage an off-the-shelf open-source search engine ( SolrCloud, ElasticSearch, etc). We evaluated many of these solutions and decided to build our own for two main reasons. Firstly, none of these solutions is currently deployed at a scale comparable to ours. And secondly, a system built from scratch gives us control over design aspects that have significant impact on the machine footprint, performance, and operational overhead. Also, search is a foundational feature for many of our products, current and planned. Instead of setting up and maintaining a separate search system for each of these, over time we intend to extend Firefly into a “search service”. This will allow us to quickly enable search over new corpora.
Having said that, we do leverage a number of open-source components in the implementation of Firefly (e.g., LevelDB, HDFS, HBase, RabbitMQ, Apache Tika). We will go into the details of our use of these in subsequent blog posts.
Summary
Today, Firefly has been in production for several months and powers search for all Dropbox for Business users. We have designed it to be a horizontally scalable system. It is able to comfortably meet the goals for serving and indexing latency that we set for ourselves.
In this post, we discussed the key requirements for Firefly and the motivations behind them. We also explained why meeting these requirements was not easy and described our sharding strategy in some detail.
In subsequent posts, we will cover the overall design of Firefly and detail the components that enable it to be a scalable, robust and instant search system. We will describe how Firefly scales horizontally to support growth as well as gracefully handle different types of failures.
There is always more to be done to support Dropbox’s growth and optimize the performance of our systems — if these type of problems are your cup of tea, join us!
Firefly was built by a very small team — Firefly infrastructure was built by the two of us with help from Adam Faulkner (our intern, who recently joined us full-time!). If you are interested in working in a small team and making a large impact come talk to us.
Contributors: Abhishek Agrawal, Adam Faulkner, Franck Chastagnol, Lilian Weng, Mike Lyons, Rasmus Andersson, Samir Goel


