

At Dropbox, we view incident management as a central element of our reliability efforts. Though we also employ proactive techniques such as Chaos engineering, how we respond to incidents has a significant bearing on our users’ experience. Every minute counts for our users during a potential site outage or product issue.
The key components of our incident management process have been in place for several years, but we’ve also found constant opportunities to evolve in this area. The tweaks we’ve made over time include technological, organizational, and procedural improvements.
This post goes deeper into some of the lessons Dropbox has learned in incident management. You probably won’t find all of these in a textbook description of an incident command structure, and you shouldn’t view these improvements as a one-size-fits-all approach for every company. (Their usefulness will depend on your tech stack, org size, and other factors.) Instead, we hope this serves as a case study for how you can take a systematic view of your organization’s own incident response and evolve it to meet your users’ needs.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Background
The basic framework for managing incidents at Dropbox, which we call SEVs (as in SEVerity), is similar to the ones employed by many other SaaS companies. (For those who are less familiar with the topic, we recommend this series of tutorials by Dropbox alum Tammy Butow to get an overview.)
Availability SEVs, though by no means the only type of critical incident, are a useful slice to explore in more depth. No online service is immune to these incidents, and that includes Dropbox. Critical availability incidents are often the ones most disruptive to the largest number of users—just think about the last time your favorite website or SaaS app was down—so we find that these SEVs put the highest strain on the timeliness of our incident response. Success means shaving every possible minute from that response.
Not only do we closely measure the impact time for our availability SEVs, but there are real business consequences for this metric. Every minute of impact means more unhappy users, increased churn, decreased signups, and reputation damage from social media and press coverage of an outage. Beyond this, Dropbox commits to an uptime SLA in contracts with some of our customers, particularly in mission-critical industries. We define this based on the overall availability of the systems that serve our users, and officially cross from “up” to “down” when our availability degrades past a certain threshold. To stay within our SLA of 99.9% uptime, we must limit any down periods to roughly 43 minutes total per month. We set the bar even higher for ourselves internally, targeting 99.95% (21 minutes per month).
To safeguard these targets, we have invested in a variety of incident prevention techniques. These include Chaos engineering, risk assessments, and systems to validate production requirements, to name a few. However, no matter how much we probe and work to understand our systems, SEVs will still happen. That is where incident management comes in.
The SEV process
The SEV process at Dropbox dictates how our various incident-response roles work together to mitigate a SEV, and what steps we should take to learn from the incident.
Every SEV at Dropbox has several basic features:
- A SEV type, which categorizes the incident’s impact; well-known examples include Availability, Durability, Security, and Feature Degradation
- A SEV level from 0-3, to indicate criticality; 0 is the most critical
- An IMOC (Incident Manager On Call), who is responsible for spearheading a speedy mitigation, coordinating SEV respondents, and communicating the status of the incident
- A TLOC (Tech Lead On Call), who drives the investigation and makes technical decisions
SEVs with customer impact also include a BMOC (Business Manager On Call), who manages non-engineering functions to provide external updates where needed. Depending on the scenario, this might include status page updates, direct customer communication, and in rare cases, regulatory notifications.
Dropbox has built its own incident management tool, which we call DropSEV. Any Dropboxer can declare a SEV, which triggers the assignment of the roles above and creates a set of communication channels to handle the incident. These include a Slack channel for real-time collaboration, an email thread for broader updates, a Jira ticket to collect artifacts and data points, and a pre-populated postmortem document to be used for retrospection later. Employees can also subscribe to a specific Slack channel or email list to see the stream of new SEVs that are created. Here is a sample DropSEV entry to declare a minor availability incident for our mobile app.
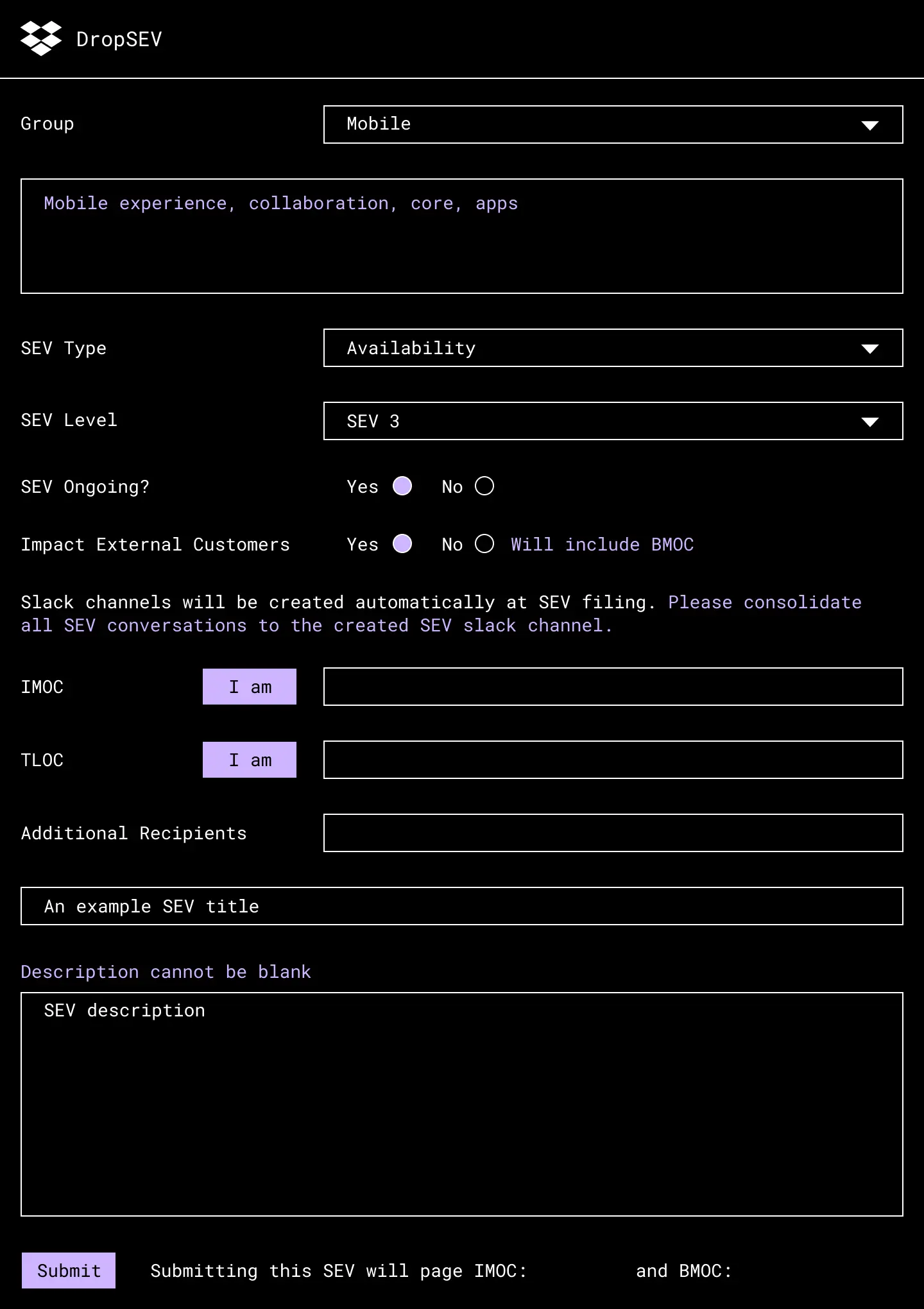
After a user creates an incident in DropSEV, the SEV process dictates the basic stages it will follow.
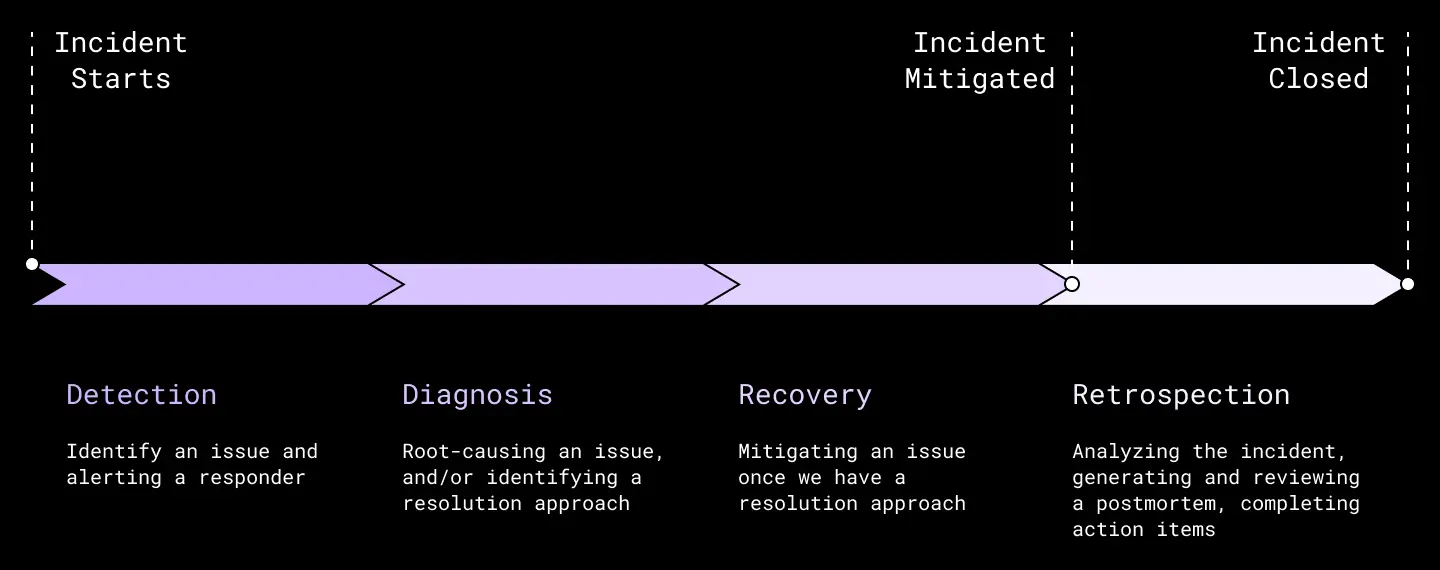
Though there is a lot of nuance around that latter stage of generating a valuable postmortem with effective action items—see “Postmortem Culture” in the Google SRE Workbook—this post will focus more on the period before a SEV is mitigated, while the user experience is still impacted. To simplify, we break this up into three overall phases:
- Detection: The time it takes to identify an issue and alert a responder
- Diagnosis: The time it takes for responders to root-cause an issue, and/or identify a resolution approach
- Recovery: The time it takes to mitigate an issue for users once we have a resolution approach
Remember our 21-minute max target for downtime in a month? That’s not a lot of time to detect, diagnose, and recover from a complex technical issue. We found that we had to optimize all three phases to make it happen.
Detection
The time it takes to identify an issue and alert a responder
A reliable and efficient monitoring system
When it comes to detecting issues at Dropbox, our monitoring systems are a key component. Over the years we’ve built and refined several systems that engineers rely on during an incident. First and foremost is Vortex, our sever-side metrics and alerting system. Vortex provides an ingestion latency on the order of seconds, a 10 second sampling rate, and a simple interface for services to define their own alerts.
These features are key to driving down the time-to-detection for issues in production. In a previous blog post we unboxed the technical design, which is also shown below.
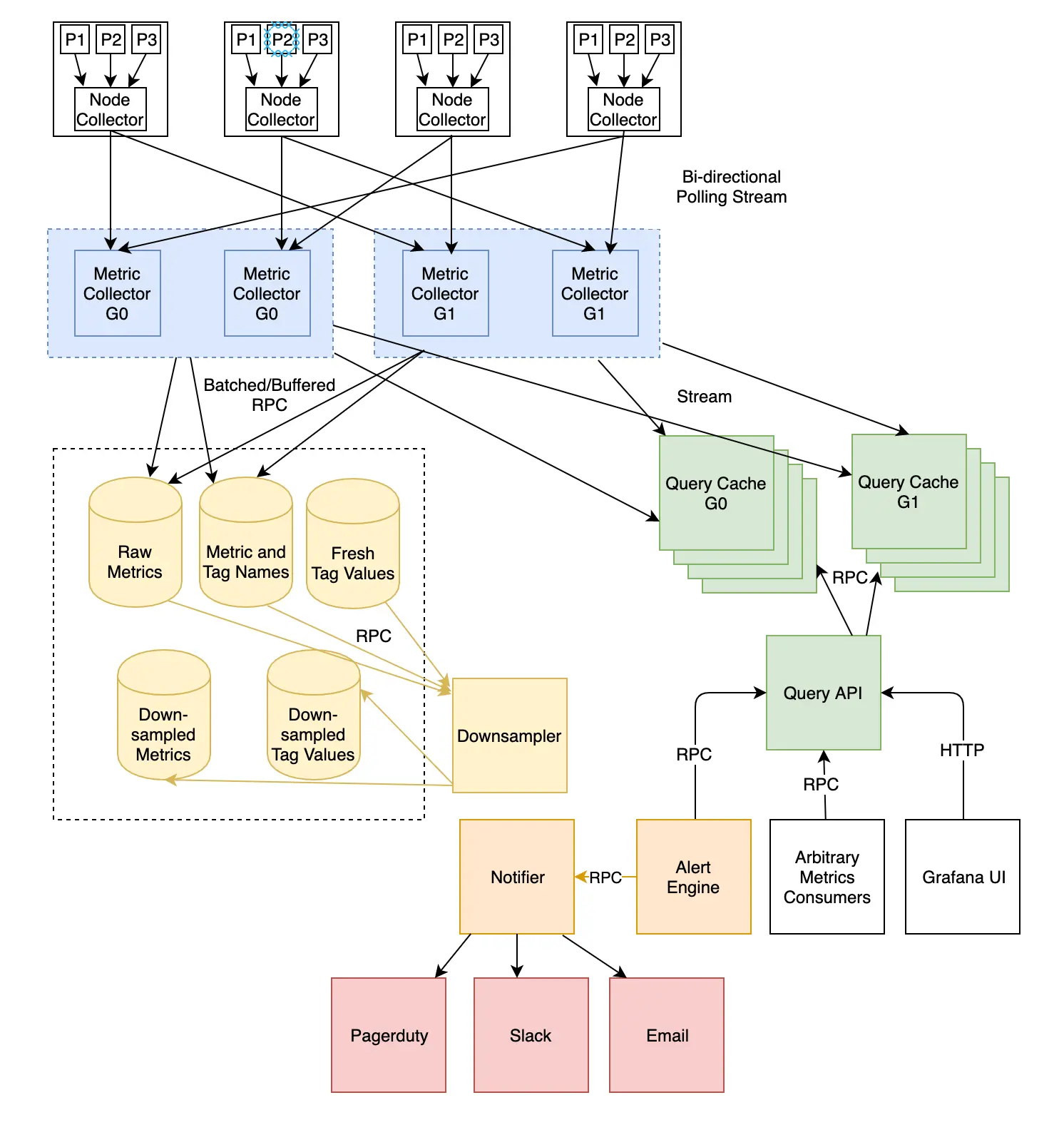
An overview of the Vortex architecture. Check out our detailed blog post for more on Vortex.
The 2018 redesign of this system was foundational for our reliability efforts. To understand why, think about that 21-minute internal target for monthly downtime. We needed to know that within tens of seconds of an incident beginning, Vortex would pick up these signals and alert the right responders via PagerDuty. If Vortex were unreliable or slow, our response would be hindered before it even began.
Your organization may not use a homegrown monitoring system like ours, but ask yourself: just how quickly will its signals trigger your incident response?
Optimizing metrics and alerts
Vortex is key in quickly alerting on issues, but it is useless without well-defined metrics to alert on. In a lot of ways this is a hard problem to solve generally, since there will always be use case-specific metrics that teams will need to add themselves.
We’ve tried to lessen the burden on service owners by providing a rich set of service, runtime, and host metrics that come for free. These metrics are baked into our RPC framework Courier, and our host-level infrastructure. In addition to a slew of standard metrics, Courier also provides distributed tracing and profiling to further aid in incident triage. Courier provides the same set of metrics in all languages we use at Dropbox (Go, Python, Rust, C++, Java).
Though these out-of-the-box metrics are invaluable, noisy alerts are also a common challenge, and often make it hard to know if a page is for a real problem. We provide several tools to help alleviate this. The most powerful is an alert dependency system with which service owners can tie their alerts to other alerts, and silence a page if the problem is in some common dependency. This allows teams to avoid getting paged for issues that are not actionable by them, and act on true issues more quickly.
Taking the human element out of filing incidents
Our teams receive a wide variety of alerts from PagerDuty about the health of their systems, but not all of these are “SEV-worthy.” Historically this meant that a Dropbox first responder receiving a page had to worry not only about fixing the issue, but whether it was worthy of filing a SEV and kicking off the formal incident management process.
This distinction could be confusing, especially for those who had less experience as an on-call for their team. To make the decision simpler, we revamped DropSEV (the incident management tool described earlier) to surface SEV definitions directly to users. For example, if you selected “Availability” as a SEV type in DropSEV, it would pop up a table like this one to map the degree of global availability impact to a SEV level.

This was a step forward, but we realized the “do I file a SEV?” decision was still slowing down our responders. Let’s say you were on-call for the frontend component of Magic Pocket, our in-house multi-exabyte storage system, which is responsible for handling Get and Put requests for data blocks. When you received a page, you’d have to ask yourself a series of questions:
- Is availability dipping?
- By how much?
- Is this having an upstream impact on global availability? (Where’s the dashboard for that again?)
- By how much? How does that line up with the SEV table?
That is not a smooth procedure, unless you are a highly trained on-call and you’ve seen your fair share of SEVs before. Even in the best case, in an outage it would cost us a couple minutes out of that critical 21-minute budget. A couple times SEVs weren’t even filed, meaning we missed out on involving the IMOC and BMOC while the technical team worked to restore availability.
So this summer, we began automatically filing all availability SEVs. A service owner will still receive their own system alerts, but DropSEV will detect SEV-worthy availability impact and automatically kick off the formal incident response process. Service owners no longer have to distract themselves with filing the SEV, and we have higher confidence that all incident response roles will be involved. And critically, we shave minutes off of the response for every availability SEV.
Where can you short-circuit human decision-making in your own incident response flow?
Diagnosis
The time it takes for responders to root-cause an issue, and/or identify a resolution approach
Common on-call standards
During the Diagnosis phase we often need to pull in additional responders to help beyond the initial recipients of an alert. We’ve built a “Page the on-call” button into our internal service directory, so a human can efficiently reach another team if needed. This is another way we’ve used PagerDuty for many years.
Our technical service directory includes a reference to each team’s on-call, and a button to quickly page them if needed in an emergency.
However, we found a critical variable which made it impossible to consistently keep our outages below 21 minutes: How is a team’s PagerDuty setup configured? Over time, well-intentioned teams at Dropbox made very different decisions on questions like these:
- How many layers does our escalation policy need?
- How much time should there be between each escalation? Across the entire escalation chain?
- How should our on-calls receive PagerDuty notifications? Do they need push, SMS, or phone calls set up, or a combination?
After grappling with these inconsistencies in a few SEVs, we instituted a set of on-call checks which evaluated each team’s PagerDuty setup against common guidelines. We built an internal service that queries the PagerDuty API, runs our desired checking logic, and contacts teams about any violations.
We made the hard decision to enforce these checks strictly, with zero exceptions. This was a challenging shift to make, since teams had gotten used to some flexibility, but having consistent answers to the questions above unlocked much more predictability in our incident response. After the initial buildup it was easy to iteratively add additional checks, and we found ways to make our initial set more nuanced (e.g. different standards depending on the criticality of your team’s services). In turn, your own on-call guidelines should be a function of the business requirements for incident response in your own organization.
As of this post’s publication, PagerDuty has released an On-Call Readiness Report (for some of their plans) which allows you to run some similar checks within their platform. Though the coverage is not identical to what Dropbox built internally, it may be a good place to start if you want to quickly create some consistency.
Triage Dashboards
For our most critical services, such as the application that drives dropbox.com, we’ve built a series of triage dashboards that collect all the high-level metrics and provide a series of paths to narrow the focus of an investigation. For these critical systems, reducing the time it takes to triage is a top priority. These dashboards have reduced the effort needed to go from a general availability page, to finding the system at fault.
Out-of-the-box dashboards for common root causes
Though no two incidents or backend services are identical, we know that certain data points are valuable to our incident responders time and time again. To name a few:
- Client- and server-side error rates
- RPC latency
- Exception trends
- Queries per second (QPS)
- Outlier hosts (e.g. those with higher error rates)
- Top clients
To shrink diagnosis time, we want these metrics to be available to every team when they need them most, so they don’t waste valuable minutes looking for the data that will point them to a root cause. To that end, we built an out-of-the-box dashboard that covers all of the above, and more. The build-up effort for a new service owner at Dropbox is zero, other than bookmarking the page. (We also encourage service owners to build more nuanced dashboards for their team-specific metrics.)
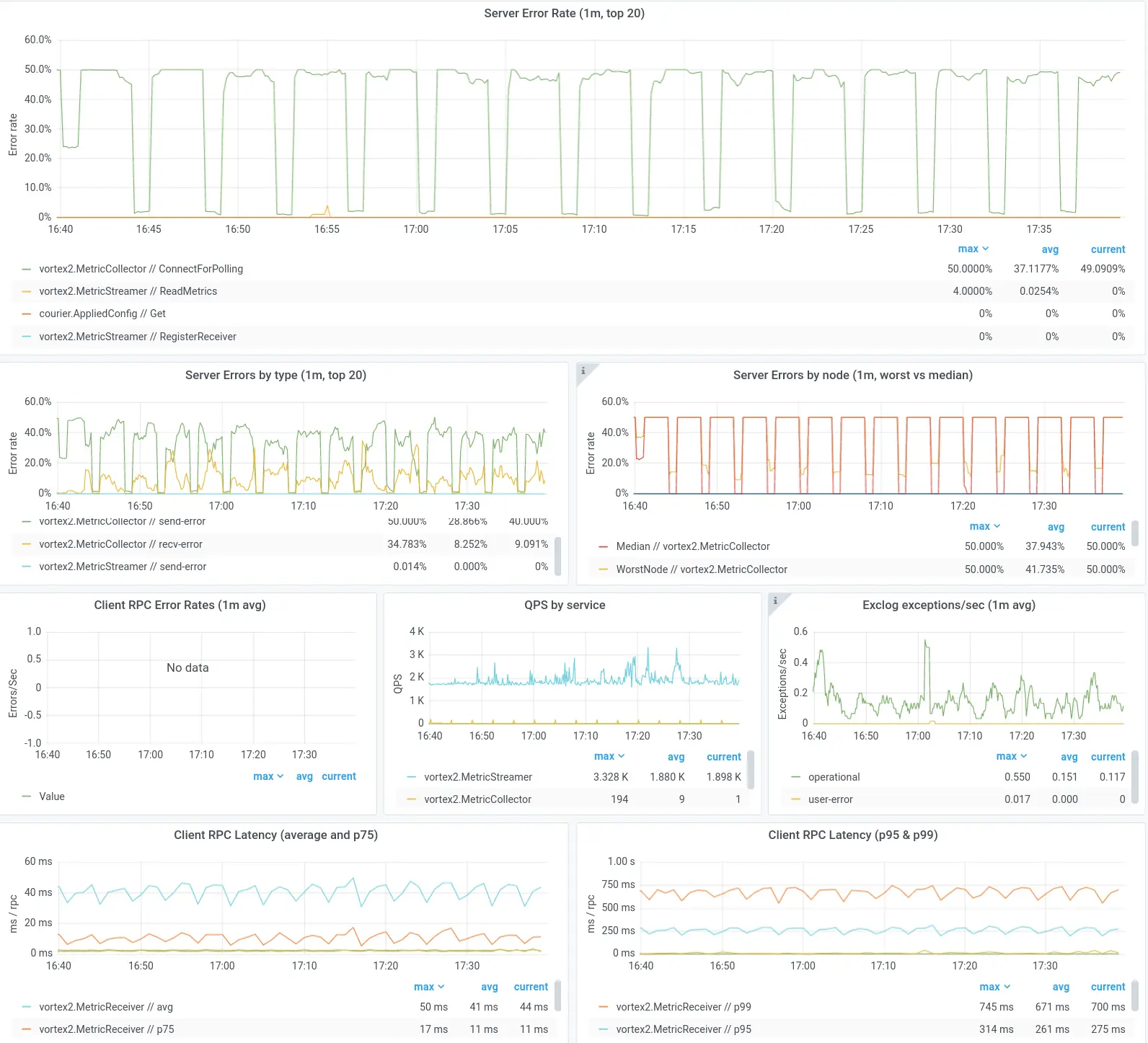
A segment of the Grafana-based Courier dashboard that service owners receive out-of-the-box.
The power of having a common platform like this is that you can easily iterate over time. Are we seeing a new pattern of root causes in our incidents? Great—we can add a panel to the common dashboard which surfaces that data. We’ve also invested in adding annotations in Grafana, which overlay key events (code pushes, DRTs, etc.) over the metrics to help engineers with correlation. Each of these iterations shrinks diagnosis time a little bit across the company.
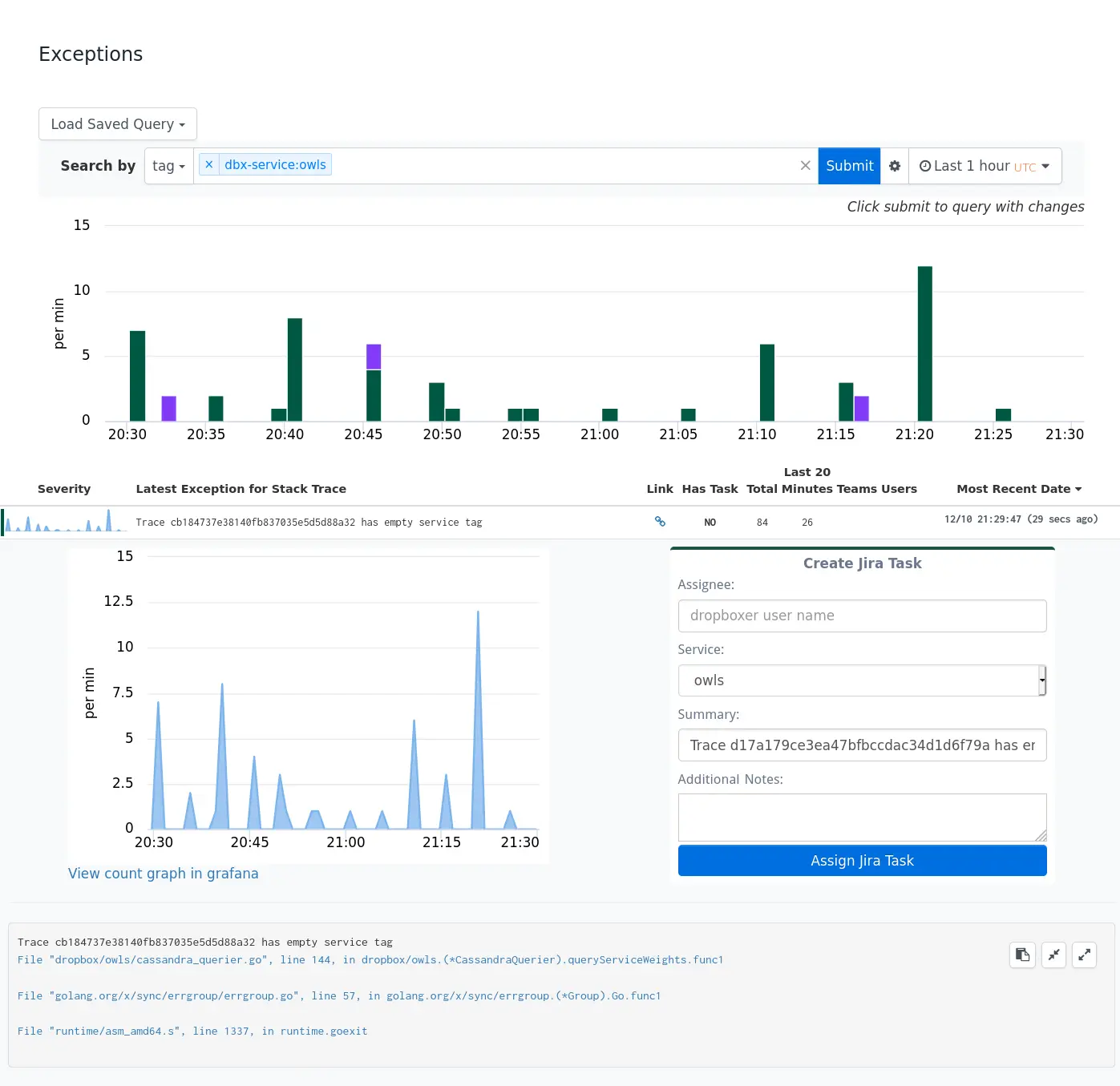
Exception Tracking
One of the highest-signal tools Dropbox has for diagnosing issues is our exception tracking infrastructure. It allows any service at Dropbox to emit stack traces to a central store and tag them with useful metadata. The frontend allows developers to easily see and explore exception trends within their services. This ability to dive into exception data and analyze trends is super useful when diagnosing problems in our larger python applications.
The Incident Manager’s role: clearing distractions
During an outage or other critical incident, a lot of stakeholders are invested in what is going on while the SEV team is diagnosing the issue.
- Customer-facing teams need to provide updates and an ETA for resolution.
- Service owners in the blast radius of the affected system are curious about the technical details.
- Senior leaders, who are accountable for reliability and business objectives, want to convey urgency.
- And senior engineering leaders in particular may want to roll up their sleeves and join the diagnosis efforts.
To make matters worse, the crosstalk in your incident Slack channels may have grown in 2020 as responders began working from home and could not collaborate in-person.
At Dropbox, we’ve seen all of the above unfold during our incidents. However, we’ve sometimes struggled with a key element of the IMOC’s role: to shield the SEV team from these distractions. Thanks to the training they received, IMOCs generally knew the SEV process, associated terminology and tooling, and the expectations for postmortems and incident reviews. But they did not always know how to drive a war room and optimize the efficiency of our SEV response. We heard feedback from our engineers that IMOCs were not providing them the front-line support they needed, and distractions were slowing them down from diagnosing issues.
We realized that we had not made those aspects of the IMOC role explicit, and the tribal knowledge of “what makes a good IMOC” had faded over time. A first step was updating our training to emphasize setting urgency, clearing distractions, and consolidating communication in one place. We are now working on game-like SEV scenarios where new IMOCs can actually practice these concepts before their first shift. Finally, we plan to increase the cadence of tabletop exercises involving a broader set of IMOCs, so the group can regularly evaluate its overall readiness.
In addition, we established a Backup Response Team of senior IMOCs and TLOCs that could be pulled in for our most severe incidents. We gave them a clear playbook to assess the state of the incident and determine with the existing IMOC/TLOC if they should be transferred ownership. Giving these senior players an explicit, well-known role when necessary made them a valuable support structure, not a set of extra voices in Slack.
The key lesson: pay attention to the delta between how your incident response process looks on paper, and how it works in practice.
Recovery
The time it takes to mitigate an issue for users once we have a resolution approach
Envision mitigation scenarios
At first, it may seem challenging to find a silver bullet for the Recovery stage. How do you optimize this part when every incident calls for a different mitigation strategy? This requires a lot of insight into how your systems behave, and the steps your incident responders would have to take in worst-case (but feasible) scenarios.
As Dropbox pursued a 99.9% uptime SLA, we began running quarterly reliability risk assessments. This was a bottoms-up brainstorming process across our Infrastructure teams and others whose systems were likely to be involved in SEVs. Knowing we needed to optimize recovery times, we prompted the teams to focus on a simple question: “Which incident scenarios for your systems would take more than 20 minutes to mitigate?”
This surfaced a variety of theoretical incidents, with varying degrees of likelihood. If any of these occurred, we were unlikely to stay within our downtime target. As we rolled up the risk assessment outputs to Infrastructure leadership, we aligned on which ones were worth investing in, and several teams set out to eliminate these scenarios. For a few examples:
- Push time for our monolithic backend service was > 20 minutes. The owners of the service optimized the deployment pipeline below 20 minutes, and began running regular DRTs to ensure that push time never degraded.
- Promoting standby database replicas could take > 20 minutes, if we lost enough primary replicas during a single-rack failure. Our metadata team improved the rack diversity of our database systems, and shored up the tooling that handles database promotions.
- Changes to experiments and feature gates were hard to identify, and core teams could not roll back these changes in an emergency, making it likely it would take > 20 minutes to resolve an experimentation-related issue. So our experimentation team improved visibility for changes, ensured all experiments and feature gates had a clear owner, and provided rollback capabilities and a playbook to our central on-calls.
By addressing these and other scenarios, we saw the number of lengthy availability incidents sharply decrease. We continue to use the “20-minute rule” as a measuring stick for new scenarios we uncover, and arguably should tighten this threshold over time.
You can adopt a similar methodology in your own organization or team. Write down the potential incidents that will take the longest to handle, stack-rank them by likelihood, and improve the ones at the top of the list. Then, test how the scenario would actually play out with DRTs or “wheel of misfortune” exercises for your incident responders. Did the improvements reduce recovery time to a level that’s acceptable for your business?
Holding the line at 99.9
With a tight SLA we don’t have a lot of time to react when things go wrong, but our tech stack is constantly changing underneath us. Where will the next risk pop up, and where do we focus our investments?
In addition to the process changes mentioned above, to help hold the line we’ve built up authoritative data sources in two areas:
- A single source of truth for our SLA, and what incidents have affected it
- A dashboard tracking the relative impact of services in the critical path
Having a single source of truth for our SLA makes it straightforward to plan around. This ensures there is no confusion across the organization for how each team’s contributions, such as internal SLAs, bubble up to our customer guarantees.

Tracing is used to determine what is in the critical path
We also track the impact of services in the critical path using distributed tracing. The tracing infrastructure is used to calculate a weight for each service. This weight is an approximation of how important a given service is to Dropbox as a whole. When a service’s weight exceeds a threshold, additional requirements are enforced to ensure rigor in its operations.
These weights (and the automation around them) serve two purposes. The first is to act as another data point in our risk assessment process; knowing the relative importance of services lets us better understand how risks in different systems compare. The second is to ensure we aren’t caught by surprise when a service is added to the critical path. With a system the size of Dropbox it’s hard to keep track of every new service, so tracking the critical path automatically ensures we catch everything.
Estimating user impact
“How painful is this SEV for our customers?” Addressing this question won’t speed up recovery, but it will allow us to communicate proactively to users through the BMOC and Be Worthy of Trust, which is our first company value. Again, every minute counts for our users during an incident.
This question has proven particularly tricky for availability SEVs at Dropbox. You may have noticed above, our availability SEV level definitions start with a somewhat naive assumption that lower availability is more severe. This definition provided some simplicity as the company scaled up, but it has failed us in the long run. We’ve encountered SEVs with a steep availability hit but almost no customer impact; we’ve encountered minor availability hits that barely qualified as SEVs but rendered dropbox.com completely useless. The latter case was what kept us up at night, because we ran the risk of under-serving and under-communicating to our users.
As a tactical fix we zeroed in on our website, which has lower traffic than our desktop and mobile apps (meaning web-specific availability issues may stand out less in the numbers). We worked with teams across engineering to identify ~20 web routes which corresponded to key webpages and components. We started monitoring availability for these individual routes, adding these metrics to our dashboards, alerts, and SEV criteria. We trained IMOCs and BMOCs on how to interpret this data, map an availability dip to specific impact, and communicate to customers—and we practiced with a tabletop exercise. As a result, in subsequent incidents impacting our website, we quickly got a sense whether key user workflows were affected, and used this information to engage with customers.
We believe we still have work to do in this area. We’re exploring a variety of other ways we can pivot from measuring 9s to measuring customer experience, and we are excited by the technical challenges these will entail:
- Can we classify all of our routes, across platforms, into criticality-based buckets which we flag to the response team?
- How do we use direct signals of customer impact (such as traffic to help and status pages, customer ticket inflow, and social media reaction) to rapidly trigger an engineering response?
- At our scale, how do we efficiently estimate the number of unique users affected by an availability incident in real-time? How do we get more precise data on the populations affected—regions, SKUs, etc.—after the incident?
- Where will we benefit most from client-side instrumentation, to measure customer experience end-to-end?
Continuous improvement
Dropbox is not perfect at incident management—no one is. We started with a SEV process that worked great for where Dropbox was, but as our organization, systems, and user base grew, we had to constantly evolve. The lessons we outlined in this post didn’t come for free; it often took a bad SEV or two for us to realize where our incident response was lacking.
That’s why it’s so critical to learn from your gaps in each incident review. You can’t fully prevent a critical incident from happening, but you can prevent the same contributing factor from coming back to bite you again.
At Dropbox, this starts with a blameless culture in our incident reviews. If a responder makes a mistake during an incident, we don’t blame them. We ask what guardrails our tools were missing against human error, what training we failed to give the responder to prepare them for this situation, and whether automation could take the responder out of the loop in the first place. This culture allows all parties to feel comfortable confronting the hard lessons a SEV teaches us.
Just as we don’t lay blame on individuals for our SEVs, no single person can take credit for the improvements we’ve made to Dropbox’s incident management. It truly has taken an organization-wide effort over the last several years to incorporate these lessons. But to name a few, we’d like to thank current and past members of the Reliability Frameworks, Telemetry, Metadata, Application Services, and Experimentation teams for the topics covered in this blog post.
If you’re interested in helping us take incident management at Dropbox to the next level, we are hiring for Site Reliability Engineers. With Dropbox’s announcement that we are becoming a Virtual First company, location is flexible for these positions long-term.


