

As we laid out in our blog post introducing DBXi, Dropbox is building features to help users stay focused on what matters. Searching through your content can be tedious, so we built content suggestions to make it easier to find the files you need, when you need them.
We’ve built this feature using modern machine learning (ML) techniques, but the process to get here started with a simple question: how do people find their files? What kinds of behavior patterns are most common? We hypothesized the following two categories would be most prevalent:
- Recent files: The files you need are often the ones you’ve been using most recently. These change over time, of course, but often the recent past is a good indicator of the near future. This can also include your files that have recent activity by others, not just by you. For example, a co-worker just wrote the first draft of a report, and shared it with you so you can edit it. Even if you haven’t opened it yet, the fact that it was recently shared with you is a strong cue that you might want to edit it now.
- Frequent files: Another category of your files are ones that you come back to again and again. This could include your personal to-do list, weekly meeting notes, or team directory. There’s some overlap with the previous category here—if you’re hard at work on a report due next week, you’ll probably open the report quite frequently and it will be among the most recent files you’ve accessed as well.
Heuristics
Starting with this basic understanding of the kinds of files users access, we built a system using a set of simple heuristics—manually-defined rules that try to capture the behaviors we described above. Here are the most successful:
- Recency: We can present your files to you in reverse-chronological order, i.e., most recent first. We already show this to users in dropbox.com today, and it’s a good baseline to improve upon.
- Frequency: Your most frequently used files over the last week are likely to be different from the ones over the last year. For simplicity, we started with a middle-ground between these options, e.g., one month. We count the number of accesses of each of your files in the last month and display the files with the highest counts.
- Frecency: The combination of the two options above is a heuristic called frecency. It looks for your files that have some recent activity, and/or were accessed frequently, ranking files that match both criteria higher. We decay the weight assigned to each access, based on how long ago it was. Accessing a file five times in the past week, for instance, makes it more likely you’ll use it again soon, compared to a file you accessed ten times a couple of months ago.
Deploying and improving heuristics
Starting with heuristics allows one to launch with a fairly simple implementation and start logging user reaction based on understandable behavior. In our case, we were able to use these simple heuristics to power the first version of content suggestions. That meant we could focus on all the other pieces needed to build this feature—the design, front-end code, back-end code, code to fetch a list of candidate files for each user, code to get the relevant metadata about access times for each file, etc.
Logging was critical for this initial version. Once we have a feature launched to some users (we often run initial experiments to a small % of users with our feature gating system Stormcrow), we can start seeing how often they find these suggestions helpful, and use that to help us determine what to do next. We can also compare different variants (e.g., the different heuristics) to see how they perform relative to each other.
In our case, we found a number of issues with the heuristics when we first tested them out with users. For example, sometimes a user might have only one file they’ve recently worked on, and nothing else for a long period before that. However, since we were always showing the top three suggestions, users would get confused why the recent file was shown together with their other completely unrelated files. We solved this by thresholding the heuristics: only showing files if their score was higher than a threshold value.
We can pick a threshold value by looking at a logged dataset of the suggestions shown, the score for each suggestion, and the ones users clicked on. By setting different threshold values offline, we can make a tradeoff between precision (what fraction of shown results were clicked) and recall (what fraction of clicked results were shown). In our case, we were interested in improving precision, to avoid false positives, and thus picked a fairly high threshold. Any files with heuristic scores below that value wouldn’t be suggested.
Another problem we found was that the suggestions sometimes included files that were accessed by programs installed on the user’s computer (such as virus scanners or temporary files) but not through the user’s direct actions. We created a filter to exclude such files in our suggestions. We also found other classes of user behavior we hadn’t included in our initial set of heuristics. In particular, some files were accessed in a periodic fashion which wasn’t captured by our heuristics. These could be documents like quarterly write-ups or monthly meeting documents.
At first, we were able to add additional logic to our heuristics to deal with these issues, but as the code started getting more complex, we decided we were ready to start building the first version of the ML model. Machine learning allows us to learn from users’ behavior patterns directly, so we don’t need to maintain an ever-growing list of rules.
Machine learning model v1
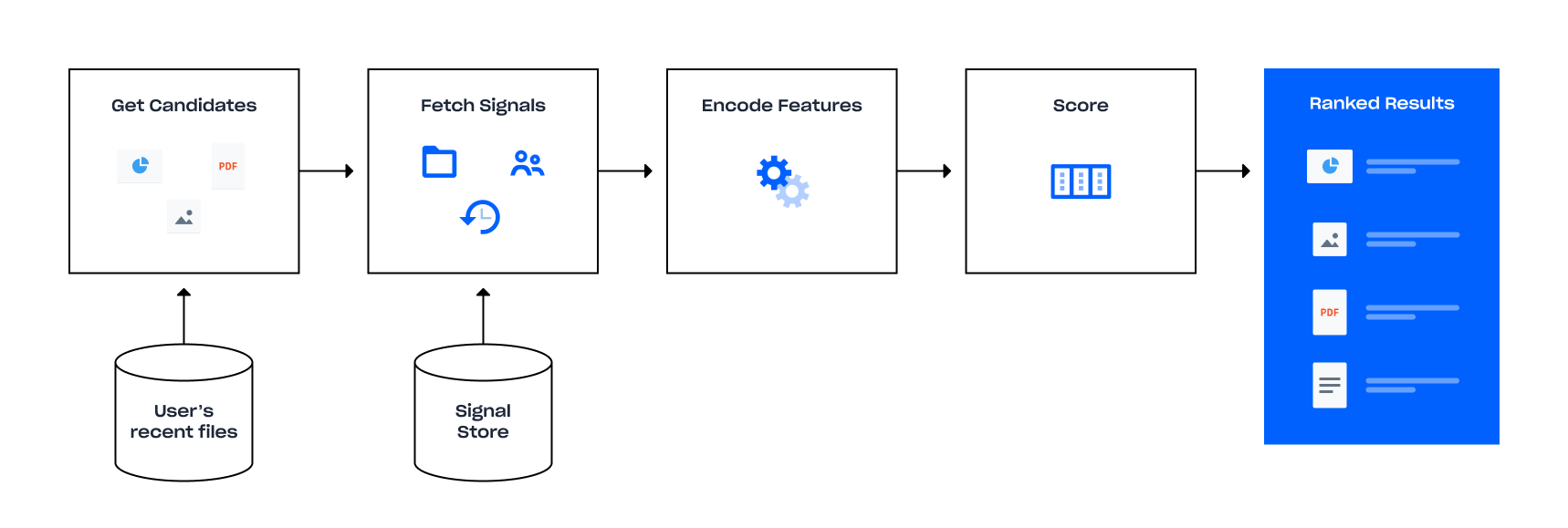
The steps are as follows:
- Get candidate files: For each user we need a set of candidate files to rank. Since Dropbox users could potentially have thousands or even millions of files, it would be very expensive to rank all of them—and not very useful either, since a lot of files are rarely accessed. Instead, we can limit to the most recent files that the user has interacted with, without a significant loss in accuracy.
- Fetch signals: For each candidate file, we need to fetch the raw signals we’re interested in related to that file. These include its history (of opens, edits, shares, etc.), which users have worked on the file, and other properties of the file such as its file type and size. We also include signals about the current user and “context” (e.g., current time and device type the user is on), so that the results become more personalized without having to train separate models for each user. The model is trained with activity from a huge number of users, which protects it from bias toward representing the actions (or revealing the behavior) of any given user. For the first version, we only used activity-based signals (such as access history), rather than content-based ones (such as keywords in documents). The advantage of this is that we can treat all files identically, rather than having to compute different kinds of signals depending on file type. In the future, we can add in content-based signals if needed.
- Encode feature vectors: Since most ML algorithms can only operate on extremely simple forms of inputs, such as a vector of floating-point numbers, we encode the raw signals into what is called a feature vector. There are standard ways of doing this for different kinds of input, which we adapted as necessary.
- Score: We’re finally ready to do the actual ranking. We pass the feature vector for each file to the ranking algorithm, get back a score per file, and sort by that score. The top-ranked results are then permission-checked again before being shown to the user.
Of course, this all has to happen very quickly for each user and their files, since the user is waiting for the page to load. We spent a fair amount of time optimizing different parts of the pipeline. Luckily, we could take advantage of the fact that these steps can be done independently for each candidate file, thus allowing us to parallelize the entire process. In addition, we already had a fast database for getting a list of recent files and their signals (steps 1 and 2). This turned out to be enough to meet our latency budget, without having to significantly optimize steps 3 and 4.
Training the model
Now that we know how the system will run in production, we need to figure out how to train the model. We initially framed the problem as binary classification: we want to determine whether a given file will be opened now (“positive”) or not (“negative”). We can use the predicted probability of this event as a score to rank results. For the training pipeline, the general guideline is to try to get your training scenario as close to the prediction scenario as possible. Thus, we settled upon the following steps, closely matching our prediction pipeline.
- Get candidate files: As the input to the entire system, getting this step right is crucial to the final accuracy, and despite its apparent simplicity, it was one of the most challenging, for a number of reasons.
- Where to get positive examples: Our logging gives us a list of historic file opens. However, which opens should we be counting as our positive examples? The data from the heuristic-powered version of this feature, or general Dropbox file open data? The former are much more “relevant” candidates because we know that the user opened those files in exactly the context we will be deploying this model to; however, models trained only on data from a single context can suffer from tunnel vision when used in a broader context. On the other hand, the more general file history is more representative of all kinds of user behavior, but might include more noise. We initially used the former method as the logs were much easier to process, but switched to a mix of both (with a heavy emphasis on the latter) once we had our training pipeline in place, because the results were much better.
- Where to get negative examples: In theory, every file in the user’s Dropbox that was not opened is a negative! However, remembering our guideline (“get your training scenario as close to your prediction scenario as possible”), we use the list of recent files, at the time of the positive file open, as the set of possible negatives, because this most closely resembles what will happen at prediction time. Since the list of negatives is going to be much larger than the set of positives—something that ML systems often don’t do well with—we subsample the negatives to only a small factor larger than the positives.
- Fetch signals: This is just like in the prediction scenario, except it requires access to historic data, because we need the signals as they would have appeared at the time of each training example. To facilitate this, we have a Spark cluster which can operate on historic data. For example, one of our signals is “recency rank," which is the rank of a file in the list of recently opened files, sorted by time of last access. For historic data, this means reconstructing what this list would have looked like at a given point in time, so that we can compute the correct rank.
- Encode features: Again, we keep this exactly as in production. In our iterative training process, we started with very simple encodings of the data, and made them more sophisticated over time as needed.
- Train: The major decision here was what ML algorithm to use. We started with an extremely simple choice: a linear Support Vector Machine (SVM). These have the advantage of being extremely fast to train, easy to understand, and come with many mature and optimized implementations.
The output of this process is a trained model, which is just a vector containing weight coefficients for each feature dimension (i.e., floats). Over the course of this project, we experimented with many different models: trained on different input data, with different sets of signals, encoded in various ways, and with different classifier training parameters.
Note that for this initial version, we trained a single global classifier over all users. With a linear classifier, this is powerful enough to capture generic behavior such as recency and frequency of file usage, but not the ability to adapt to each individual user’s preferences. Later in the post, we’ll describe the next major iteration of our ML system, which can do that better.
Metrics and iteration
Once we had a working training and prediction pipeline, we had to figure out how to get the best possible system shipped to users. What does “best” actually mean, though? At Dropbox, our ML efforts are product-driven: first and foremost we want to improve the product experience for our users, and any ML we build is in service of that. So when we talk about improving a system, ultimately we want to be able to measure the benefit to our users.
We start by defining the product metrics. In the case of content suggestions, the primary goal was engagement. We use several metrics to track this, so we decided to start simple: if our suggestions are helpful, we would expect users to click on them more. This is straightforward to measure, by counting the number of times people clicked on a suggestion divided by the number of times a user was shown suggestions. (This is also called the Click-Through Rate, or CTR.) To achieve statistical significance, we would show subsets of users the suggestions from different models over the course of a week or two and then compare the CTRs for the different variants. In theory, we could launch models every few weeks and slowly improve engagement over time.
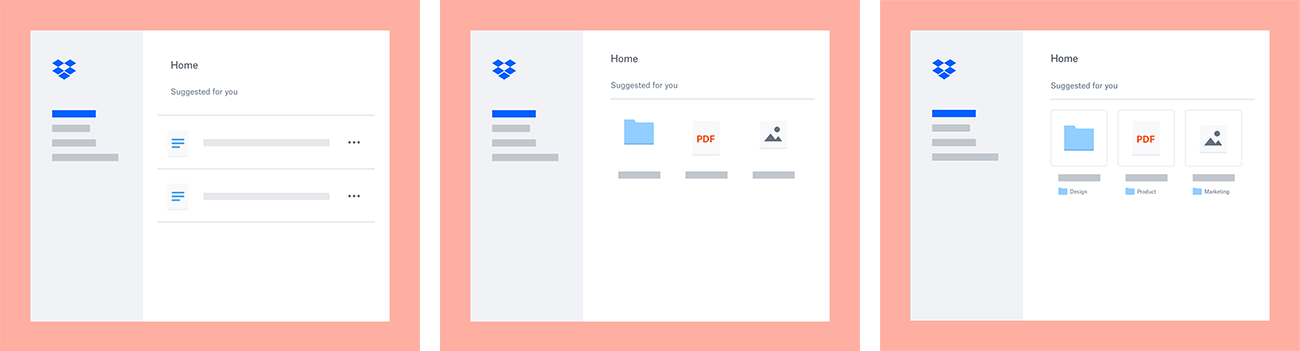
In practice, we ran into a few major issues (and some minor ones). First was how to attribute increases (or drops) in the CTR due to changes in the product design vs. changes in the ML model. A large body of research and industry case-studies have shown that even seemingly small changes in the user experience (UX) can cause big changes in user behavior (hence the prevalence of A/B testing). So, while one team of engineers was focusing on improving the ML model, another team of engineers, designers, and product managers was focusing on improving the design of the feature. Some high-level examples of this design iteration are shown below:
Given that we might change both the UX and the ML model for a new version, how would we know which change affected the CTR (and by how much)? In fact, the problem was even more complicated to address than we initially thought. Early on, we discovered that in a fair number of cases, we were suggesting the right files to the user, but they weren’t clicking them from the suggestions section; instead, they would navigate to the file some other way and open them from there. While there are many possible reasons for this—greater familiarity with existing ways of accessing files, lack of critical contextual information (such as parent folder names, which we added as part of our design iteration), etc.—the end result was that we couldn’t rely on the CTR numbers as our sole measure of model accuracy. We needed to find a proxy metric that would more directly capture the accuracy of our model, and be as independent of UX as possible.
There was another compelling reason to switch to a proxy metric: iteration speed. A couple weeks to run an A/B test doesn’t sound very long, but that’s just the time needed for each experiment to run fully. After that, we had to analyze results, come up with a list of proposed improvements, implement them, and finally train the new model. All of this meant that it could take well over a month to release a new version. To make serious progress, we would need to cut this time down dramatically, ideally something that we could measure “offline”—without releasing to users.
Hit ratios
Our training process let us measure various quantities on held out sets of training data, such as precision and recall (as described earlier), or accuracy of the classifier, but we didn’t find a strong correlation between these metrics and the CTR when we actually launched a model to users. Instead, we came up with a “hit ratio” metric that satisfied all our criteria. For any given suggestion, we checked if the user accessed that file in the subsequent hour, no matter how they arrived at the file. If so, we counted it as a “hit”. We could then compute both a per-suggestion “hit ratio” (percent of suggestions that were hits) and a per-session hit ratio (percent of sessions where at least one suggestion was a hit). We could measure this both online and offline (by looking at historical logs of user behavior).
This metric proved invaluable not just for iterating on the ML faster, but also for diagnosing UX issues. For example, when we first moved from displaying content suggestions as a list of files to a set of thumbnails, we expected CTR to increase. Not only were we showing the files in less vertical space, we were also showing thumbnails to make it easier for users to identify the files. However, CTR actually dropped. We tried a few different design iterations and used our hit ratio metric to verify that the quality of the suggestions was not to blame. We discovered a number of issues that we rectified, such as the missing folder names mentioned earlier.
Now that we had both a product metric and a proxy metric that measured the accuracy of the model, we could make rapid progress on improving both the UX and ML aspects of our system. However, not all our improvements came solely from looking at those metrics. If you think of metrics as “broad but shallow” measures of our performance, it is also helpful to look at “deep but narrow” measures as a complementary source of information. In this case, that meant looking in some detail at the suggestions for a very small subset of data—those belonging to our own team members.
With extensive internal testing, we uncovered a number of other issues, including many that affected the very beginning of the pipeline: what data we used. Here are a few interesting examples:
- Short clicks: We found that our training data included instances where users would open a file in a folder, and then scroll through other files in that folder using the left and right arrow keys. All of these would end up getting counted as positive training samples, even though this kind of behavior isn’t applicable on the home page, where we only show a few images at a time. We thus devised a simple method of labeling these “short clicks” and filtered them out from our training data.
- Very recent file activity: A commonly used Dropbox feature is automatically saving screenshots to Dropbox. Users coming to the home page would expect to see these right away, but our feature pipeline wasn’t quite responsive enough to pick these up. By tuning the latency of various components, we were able to include these in the results as well.
- Newly created folders: In a similar vein, users expect to see newly created folders show up on the home page, since these are often created specifically to move files into. In this case, we had to temporarily use a heuristic to detect such folders and merge them into the suggestions, since the kind of signals we have for folders is much more limited (and different from files).
Machine learning model v2
Armed with this newly gleaned knowledge of where our current system wasn’t doing as well, we set out to make significant improvements throughout the training pipeline. We filtered out short clicks from our training data, as well as certain other classes of files that were getting spuriously suggested to users. We started integrating other kinds of signals into the training process that could help move our hit ratio metric. We reworked our feature encoding step to more efficiently pull out the relevant information from our raw signals.
Another big area of ML investment at Dropbox proved to be quite important for improving the content suggestions: learning embeddings for common types of entities. Embeddings are a way to represent a discrete sets of objects—say each Dropbox user or file—as a compact vector of floating point numbers. These can be treated as vectors in a high-dimensional space, where commonly used distance measures such as cosine or Euclidean distance capture the semantic similarity of the objects. For example, we would expect the embeddings for users with similar behavior, or files with similar activity patterns, to be “close” in the embedding space. These embeddings can be learned from the various signals we have at Dropbox, and then applied as inputs to any ML system. For content suggestions, these embeddings provide a noticeable boost in accuracy.
Finally, we upgraded our classifier to a neural network. Our network is currently not very deep, but just by being able to operate non-linearly on combinations of input features, it has a huge advantage over linear classifiers. For example, if some users tend to open PDF files on their phones in the morning, and PowerPoint files on desktop in the afternoon, that would be quite hard to capture with a linear model (without extensive feature combinations or augmentations), but can be easily picked up by neural nets.
We also changed how we framed our training problem slightly. Instead of binary classification, we switched to a Learning-To-Rank (LTR) formulation. This class of methods is better suited to our problem scenario. Rather than optimizing for whether a file will be clicked or not, completely independent of other predictions, LTR optimizes for ranking clicked files higher than not-clicked files. This has the effect of redistributing output scores in a way that improves the final results.
With all of these improvements, we were able to significantly boost our hit ratio and improve overall CTR. We have also laid the groundwork for additional improvements in the future.
Acknowledgements
This project was a highly collaborative cross-team effort between the product, infrastructure, and machine learning teams. While there are too many people to list here individually, we’d like to give special credit to Ian Baker for building large parts of the system (as well as improving virtually every other piece in the pipeline), and to Ermo Wei for leading much of the ML iteration effort.
All of our teams are currently hiring, so if these kind of problems sound exciting to you, we’d love to have you join us!


