

When we first built Dash, it looked like most enterprise search systems: a traditional RAG pipeline that combined semantic and keyword search across indexed documents. It worked well for retrieving information and generating concise answers. But as teams began using Dash for more than just finding content—for example, asking it to interpret, summarize, and even act on what it found—we realized that retrieval alone wasn’t enough. The natural progression from “what is the status of the identity project” to “open the editor and write an executive summary of the projects that I own” required Dash to evolve from a search system into an agentic AI.
That shift introduced a new kind of engineering challenge: deciding what information and tools the model actually needs to see to reason and act effectively. This has been popularized as context engineering, the process of structuring, filtering, and delivering just the right context at the right time so the model can plan intelligently without getting overwhelmed. We started thinking about how these ideas applied inside Dash itself, including how the model planned, reasoned, and took action on a request. Instead of simply searching and summarizing results, it now plans what to do and carries out those steps.
At the same time, adding tools into Dash’s workflow created new tradeoffs around how context is managed. Precision in what you feed the model is critical in any RAG system, and the same lesson applies to agentic systems. Supplying the model with only the most relevant context, and not just more of it, consistently leads to better results. Below, we’ll walk through how we’ve been building better context into Dash.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Engineering context precision in Dash
As Dash gained new capabilities—like contextual search and assisted editing—we noticed something unexpected: more tools often meant slower, less accurate decision making. A “tool” here is any external function the model can call, such as search, look-up, or summarization. Each new capability expanded the model’s decision space, creating more choices and room for confusion. Even well-designed tools made the model spend more time deciding how to act instead of acting. The problem wasn’t broken tools; it was too many good ones. In human terms, Dash was facing analysis paralysis.
The Model Context Protocol (MCP), an open standard for defining and describing the tools a server provides, helps with this by outlining what each tool does and what inputs it takes. But as we experimented with MCP servers, we ran into limitations. Each tool we added came with its own description and parameters, which all have to fit inside the model’s context window (the space it uses to read and reason about information). In practice, these definitions also consume a significant number of tokens, a resource that directly impacts both cost and performance. Further, we noticed that the overall accuracy of Dash degraded for longer-running jobs. The tool calls were adding a lot of extra context. We were seeing similar patterns of what’s been popularized as context rot.
This led us to rethink context. Building effective, agentic AI isn’t just about adding more; it’s about helping the model focus on what matters most. In Dash, that means curating context so the model can make faster, better decisions through three core strategies:
- Limit the number of tool definitions in the context
- Filter context to only what’s relevant
- Introduce specialized agents for tasks that demand deeper reasoning
Our principle is simple: better context leads to better outcomes. It’s about giving the model the right information, at the right time, in the right form.
Limit the number of tool definitions in the context
Our first insight was that giving the model too many options for calling tools led to worse results. Dash connects to many of the apps our customers use to get work done, and each of those apps provides its own retrieval tools, such as search, find by ID, or find by name.
Although we have the Dash Search index—our server-based search index that stores and manages documents and messages for fast and reliable retrieval—we did experiment with using other tools for retrieval. For example, Dash might need to consult Confluence for documentation, Google Docs for meeting notes, and Jira for project status to service one request. In our experiments with those other retrieval tools, we found that the model often had to call all of them, but it also didn’t do so reliably.
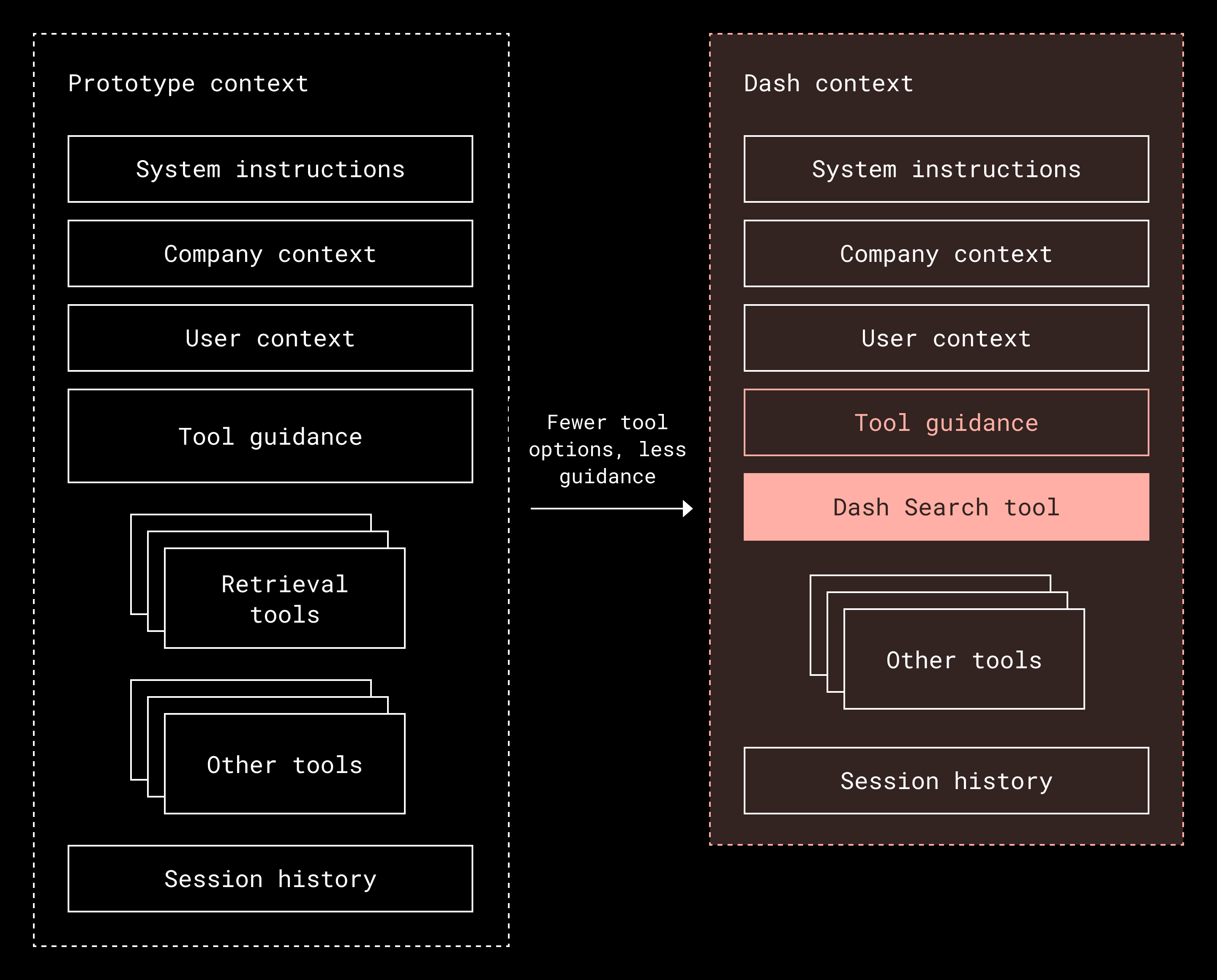
We solved this by replacing all of those retrieval options with a single, purpose-built tool backed by the Dash universal search index. Instead of expecting the model to understand and choose between dozens of APIs, we created one interface that handles retrieval across all services. The key idea is simple: Giving the model one consistent way to retrieve information makes its reasoning clearer, its plans more efficient, and its context use more focused.
These learnings also influenced our design of the Dash MCP server, which brings Dash’s retrieval to MCP-compatible apps like Claude, Cursor, and Goose with just one tool. It connects to the systems people already use and securely searches inside their apps. By keeping descriptions lean, more of the context window stays focused on the user’s request.
Filter context to only what’s relevant
Our next insight was that not everything retrieved from multiple APIs is actually useful for the task at hand. When we tried pulling data from several tools at once, we still needed a way to rank and filter the results so that only the most relevant information reached the model.
We built the Dash index to combine data from multiple sources into one unified index, then layered a knowledge graph on top to connect people, activity, and content across those sources. (A knowledge graph maps relationships between these sources so the system can understand how different pieces of information are connected.) These relationships help rank results based on what matters most for each query and each user. As a result, the model only sees content our platform has already determined to be relevant, which makes every piece of context meaningful. Building the index and graph in advance means Dash can focus on retrieval at runtime instead of rebuilding context, which makes the whole process faster and more efficient.
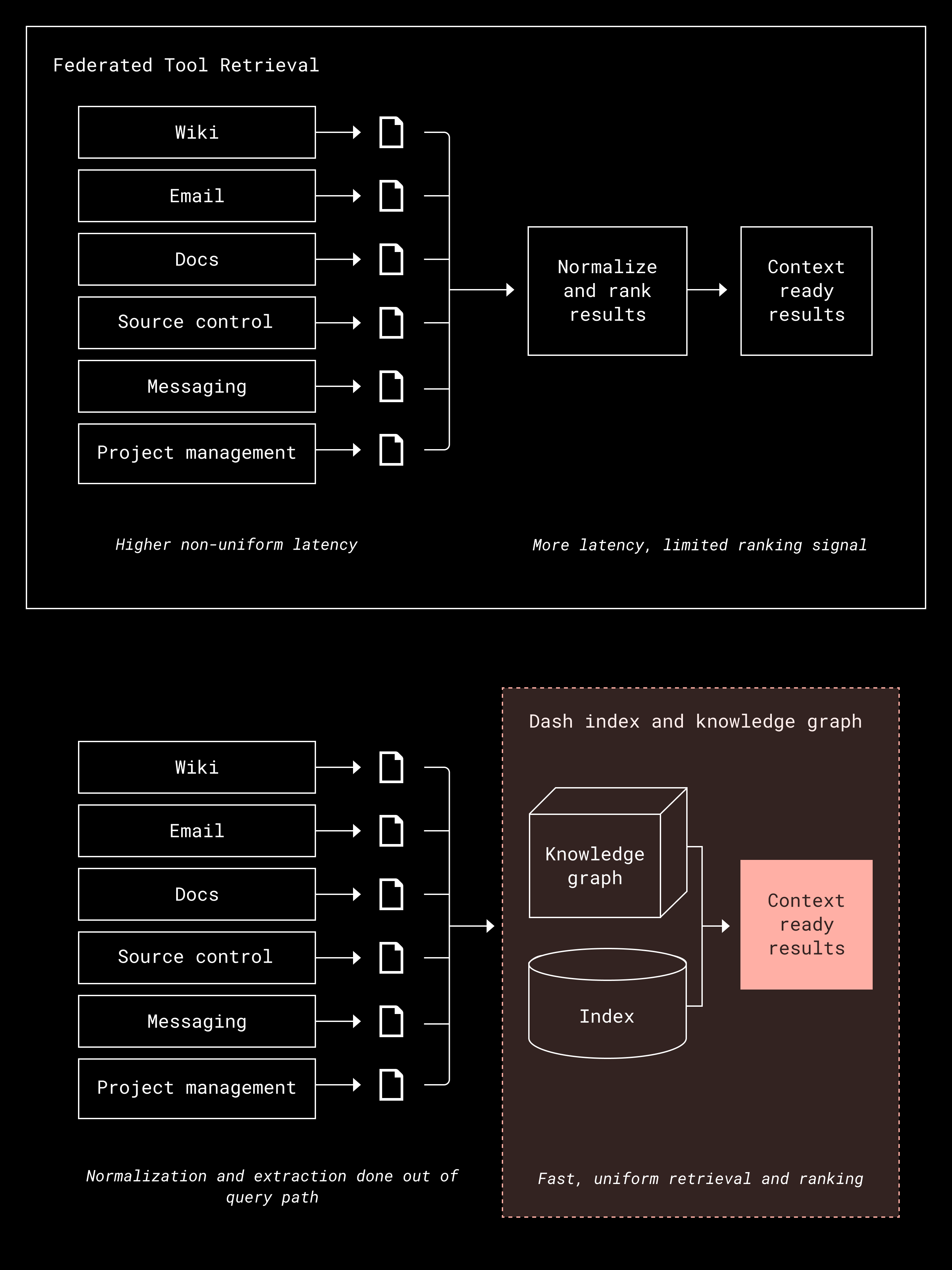
The key lesson is that everything retrieved shapes the model’s reasoning, so relevance is critical to guiding it efficiently. Sending only what’s essential improves both performance and the quality of the entire agentic flow.
Introduce specialized agents for complex tasks
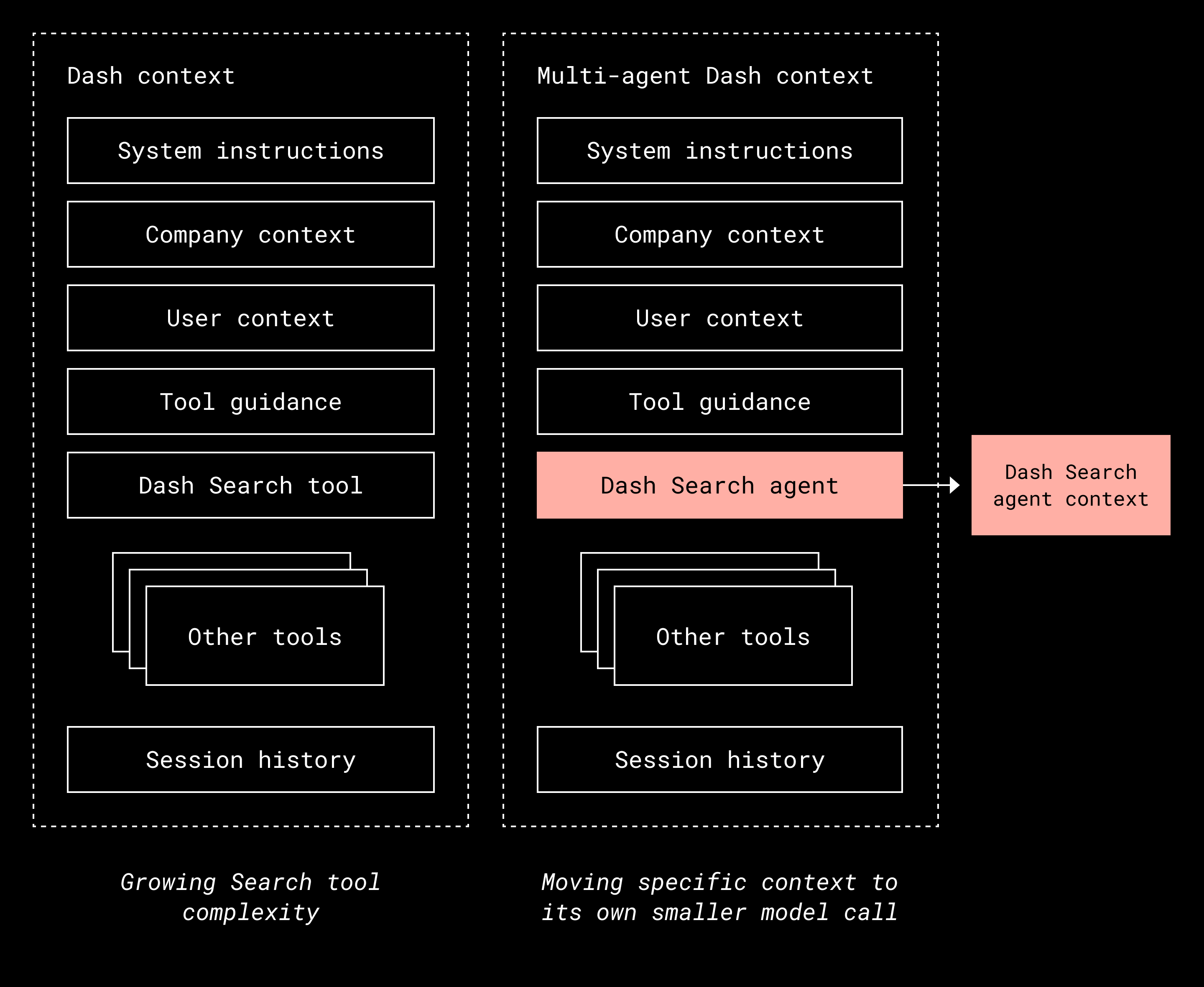
Our third discovery was that some tools are so complex that the model needs extra context and examples to use them effectively. We saw this firsthand as we continued to expand the Dash Search tool. Query construction turned out to be a difficult task on its own. It involves understanding user intent, mapping that intent to index fields, rewriting queries for better semantic matching, and handling edge cases such as typos, synonyms, and implicit context.
As the search tool grew more capable, the model needed more instruction to use it correctly. Those details started to take up a significant portion of the context window, leaving less room for reasoning about the overall task. In other words, the model was spending more of its attention on how to search than on what to do with the results.
We solved this by moving search into its own agent. The main planning agent decides when a search is needed and delegates the actual query construction to a specialized agent with its own prompt. This separation allows the main agent to stay focused on planning and execution while the search agent handles the specifics of retrieval. The key lesson is that when a tool demands too much explanation or context to be used effectively, it’s often better to turn it into a dedicated agent with a focused prompt.
Looking forward
Context engineering for agentic AI systems is still an emerging discipline. While the strategies we’ve outlined—retrieval consolidation, relevant context filtering, and specialized task agents—work well for our use cases, we’re continuing to learn and iterate. As we continue to build the best tools for knowledge workers, we’ve found that the Dash index is a powerful resource for managing relevant context and helps us use other tools more effectively.
The work we’ve shared here focuses on one piece of the puzzle: Learning how to trim context down to what really matters, both in tool selection and retrieval. But context is expensive in more ways than one. It affects cost, speed, and how much attention a model can give to the task at hand. We’ve found that leaner contexts don’t just save resources; they also make the model smarter.
Next, we’re turning these lessons toward other parts of Dash’s context, like user and company profiles, as well as long and short-term memory. We think there’s even more performance to unlock by refining these areas, especially as we experiment with smaller and faster models.
Although our discussion centered on retrieval-based tools, action-oriented tools exhibit many of the same limitations. MCP continues to serve as a robust protocol, but effective scaling depends on reducing tool proliferation, investing in specialized agents, and enabling the LLM to generate code-based tools when appropriate, an approach that parallels our consolidation of retrieval tools into the Dash retrieval system. We’ve covered how Dash uses code-based tools in a previous blog post, and we see that other companies are approaching this problem with a similar mindset.
Moving forward, our focus is on making context even more efficient so the model can spend its attention where it matters most.
Acknowledgments: Rene Schmidt, Josh Clemm, Marta Mendez, Nishchal Arya, Roland Hui, Noorain Noorani, Tony Xu
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit jobs.dropbox.com to see our open roles.


