

When someone uses Dropbox Dash to search or ask a question, it follows a retrieval-augmented generation (RAG) pattern. This means our AI first retrieves relevant company information and then uses that information to generate responses. To produce those answers, it relies on enterprise search to retrieve company-specific context and then uses that context to ground the response. Rather than responding solely from general knowledge, Dash incorporates information that already exists within an organization.
When a user submits a query, Dash first interprets the underlying information need and determines how to retrieve relevant content. Search returns a set of candidate documents, and a large language model (LLM) analyzes the most relevant results to generate an answer. Because there are millions (and, in very large enterprises, billions) of documents in the enterprise search index, Dash can pass along only a small subset of the retrieved documents to the LLM. This makes the quality of search ranking—and the labeled relevance data used to train it—critical to the quality of the final answer.
Search results in Dash are ordered by a relevance model that assigns a score to each document based on how well it matches the query. Like most modern ranking systems, this model is trained rather than hand-tuned. It learns from examples of queries paired with documents, annotated with human relevance judgments that define what high-quality search results look like. These judgments are labeled examples in which people evaluate how well a document answers a given query.
In this story, we explain how we train Dash's search ranking models with a mix of human and LLM-assisted labeling—starting with a small amount of internal, human-labeled data, and then amplifying those efforts with LLMs to produce relevance labels at scale.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Dash search relevance models
Dash’s ranking model is trained using machine learning techniques such as XGBoost rather than manually tuned rules. It learns from labeled examples of query–document pairs, where each document is evaluated based on how well it satisfies a given query. Over time, the model adjusts how it weighs different signals to reduce ranking mistakes (for example, cases where less useful documents are placed ahead of more useful ones). This framing leads directly to a core challenge: generating enough high-quality relevance labels to train the model effectively.
Where relevance labels come from
Training a relevance model requires examples that show what “good” and “bad” search results look like. In practice, those relevance labels can be created in several ways. One approach infers relevance from user behavior, such as clicks or skipped results. Another relies on humans manually assigning relevance scores to query and document pairs. And a third approach uses LLMs to generate relevance judgments directly.
This story focuses on the latter two approaches: direct human labeling and LLM-based evaluation. Signals from user behavior can still be helpful, but on their own they tend to be incomplete, influenced by existing rankings, and unevenly distributed. In practice, they work best as a supplement to labeled data rather than a replacement for it.
For the purposes of this article, relevance is treated as a graded score on a 1–5 scale. A score of 5 means the result closely matches what the user is trying to find, while a score of 1 means it isn’t useful enough to show. Importantly, relevance isn’t a fixed property of a document; it depends on the specific query, the user’s context, and the moment the search is made.
Human labeling
Historically, search engine providers relied on teams of human judges, typically third-party vendors, to label large datasets for model training. This approach had clear advantages. Human judges could systematically evaluate full result sets for each query, ensuring comprehensive and consistent relevance coverage in a way that user feedback—which is often sparse and biased—cannot.
However, the drawbacks are substantial. Human labeling is expensive and difficult to scale. Judges can be inconsistent and require ongoing training. In practice, it is also nearly impossible for humans to directly evaluate sensitive or proprietary customer data. Human evaluators also require training, which is made more difficult by the diversity of types of content that need to be rated (for example, comparing a Slack message to a Jira ticket or a Salesforce contact record can require very different contextual understanding and judgment).
LLM evaluation
LLMs provide an alternative mechanism for producing relevance judgments at scale. Compared to human annotators, LLMs are significantly cheaper, more consistent, and capable of evaluating much larger candidate sets across languages. They can also analyze customer content within defined compliance boundaries.
At the same time, LLMs are not general intelligence systems. Their performance depends heavily on both the quality of the underlying model and the clarity and precision of the instructions provided. As a result, LLM-generated relevance judgments must be evaluated and calibrated carefully before they are used for training. In practice, using LLMs for relevance evaluation requires a structured process that combines automation with human oversight.
Combining LLM evaluation with human review
To scale relevance evaluation without sacrificing quality, Dash pairs automation with human judgment. Before deploying an LLM to generate relevance labels at scale, its performance is validated against a small, high-quality set of human-labeled examples. (Human review is conducted by Dropbox with limited, non-sensitive internal datasets; no customer data is reviewed by humans as part of this process.)
A small group of human evaluators labels a dataset that is orders of magnitude smaller than what would be required for full training. These labels are used to tune the LLM prompt and model parameters. Once performance meets quality thresholds, the LLM is deployed to generate hundreds of thousands—or even millions—of relevance labels used to train Dash’s relevance model. In this setup, the LLM acts as a force multiplier for human effort: humans teach the LLM, and the LLM generates large-scale training data in return.
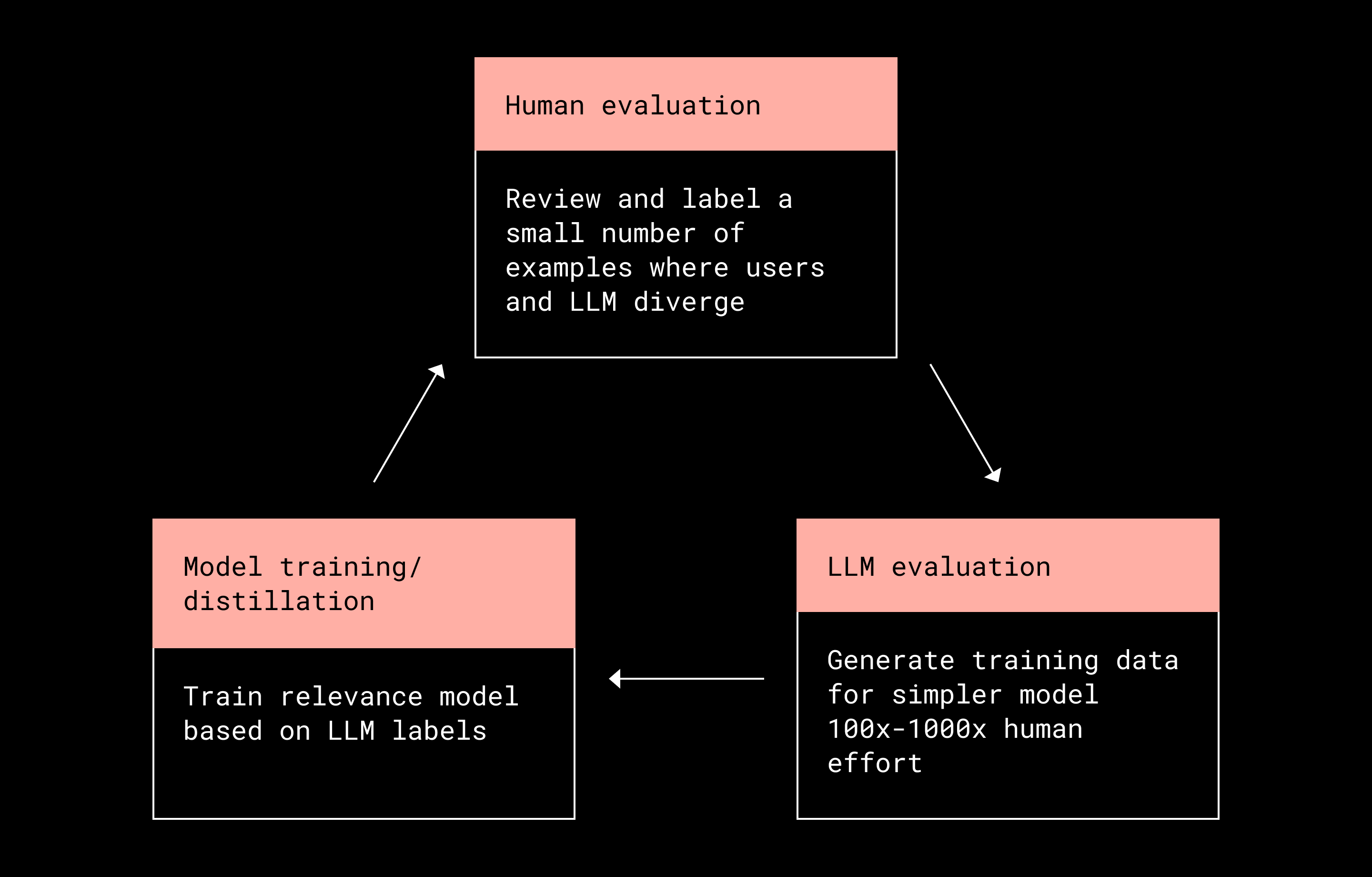
Human labeling effort is multiplied 100x to allow deeper and more representative training datasets
Using LLMs directly at query time to replace traditional ranking models is not currently feasible due to context window limitations and latency constraints. Instead, Dash uses LLMs offline to generate high-quality training data. In this role, the LLM functions as a teacher for smaller, more efficient relevance models that can operate at production scale.
Evaluating LLM relevance judgments
Improvement always starts with evaluation. Performance is measured, a change is made to the model or its instructions, and results are measured again to determine whether the system is moving in the right direction.
A chess engine operates under the same principle. As Garry Kasparov describes in Deep Thinking, reflecting on his historic match against IBM’s Deep Blue, the engine explores possible move sequences to a fixed depth and evaluates each resulting position. Poor evaluations prune entire branches of the search tree, while strong evaluations preserve promising lines of play. The overall strength of the system depends critically on the quality of the evaluation function.
Gradient-based optimization follows a similar pattern. Rather than enumerating the entire parameter space, machine learning algorithms compute a gradient and take incremental steps in the direction it indicates. Progress depends entirely on whether the evaluation signal accurately reflects improvement.
For an LLM acting as a relevance judge, evaluation follows the same logic. Dash compares LLM-generated relevance ratings with human judgments, rewarding exact matches on a 1–5 relevance scale and applying penalties for disagreement. Small differences incur small penalties, while large mismatches incur substantially larger ones. This behavior is captured using mean squared error (MSE), where the error ranges from 0 for exact agreement to 16 for the maximum possible disagreement.
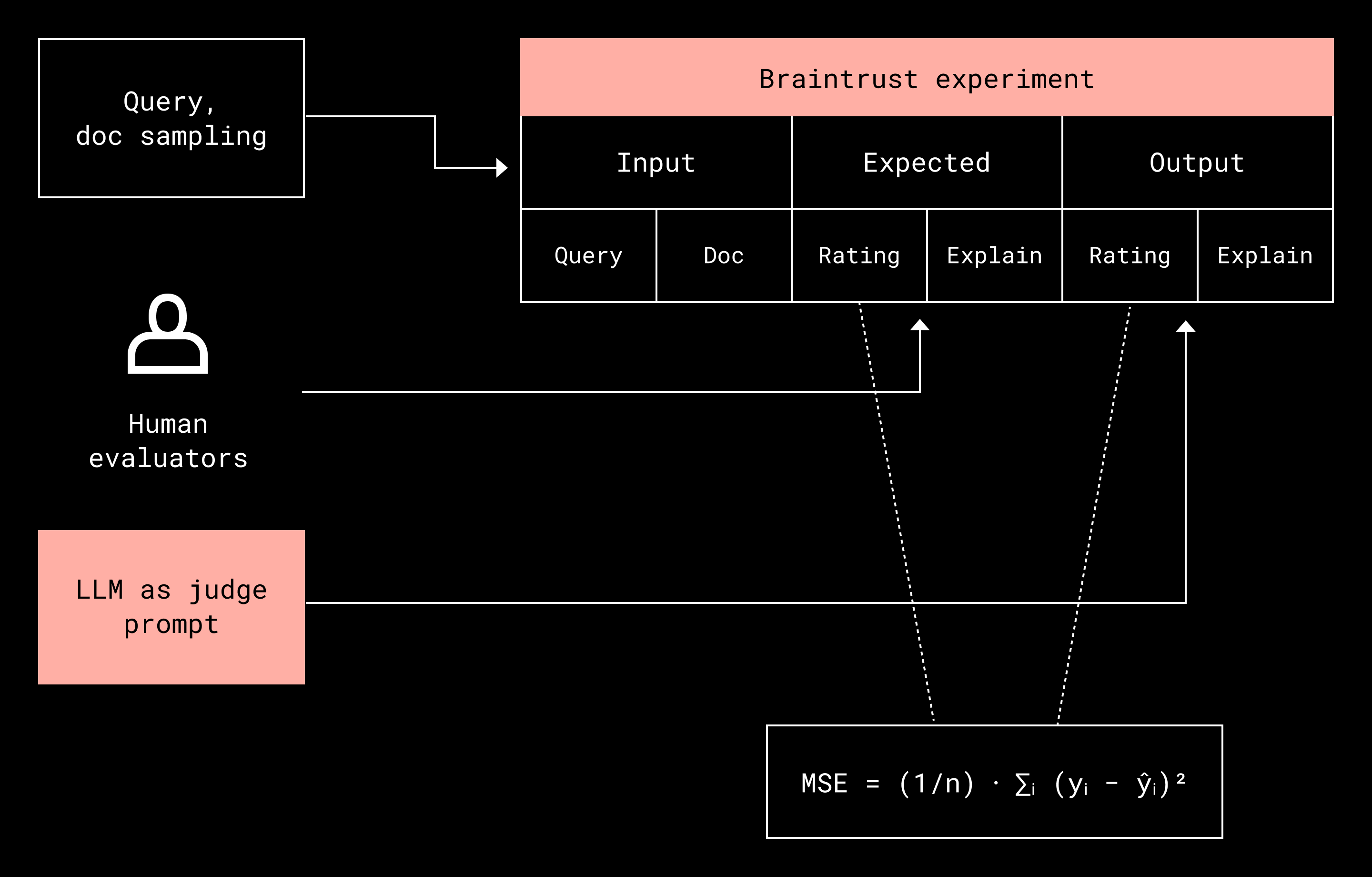
Document sampling for LLM evaluation
At scale, not all evaluation data is equally informative. To improve LLM accuracy efficiently, Dash focuses evaluation effort on the cases most likely to surface errors. Training samples are biased toward situations where mistakes are more likely, since these offer the greatest opportunity for learning. Dash identifies such cases by analyzing discrepancies between user behavior and LLM-predicted relevance.
Examples include users clicking on documents the LLM rated as low relevance, or consistently skipping documents the LLM rated as highly relevant. These discrepancies are prioritized for human review and prompt refinement. (These processes are, again, limited to small internal datasets that do not include customer data.) The process is repeated iteratively until major sources of error are addressed or improvements plateau.
Evaluating relevance with additional context
Accurate relevance evaluation often depends on context that isn’t explicitly present in the query or document text. Without this context, even well-trained models can make systematic errors. In many cases, a query and a document alone are insufficient to make a reliable relevance judgment. Additional context about internal terminology, acronyms, or organizational knowledge may be required.
For example, within Dropbox, the term “diet sprite” refers to an internal performance management tool rather than a soft drink, a distinction that can be difficult for LLMs to infer without additional context. Acronyms present similar challenges, as they often have multiple meanings across organizations or even within the same company. Human evaluators typically resolve this ambiguity by running additional searches or consulting internal tools.
To automate this process, Dash provides LLMs with tools that allow them to research query context before assigning relevance labels. Once the LLM understands the user’s intent, it can apply consistent, context-aware relevance labeling across large candidate result sets, often going deeper than human evaluators would in practice.
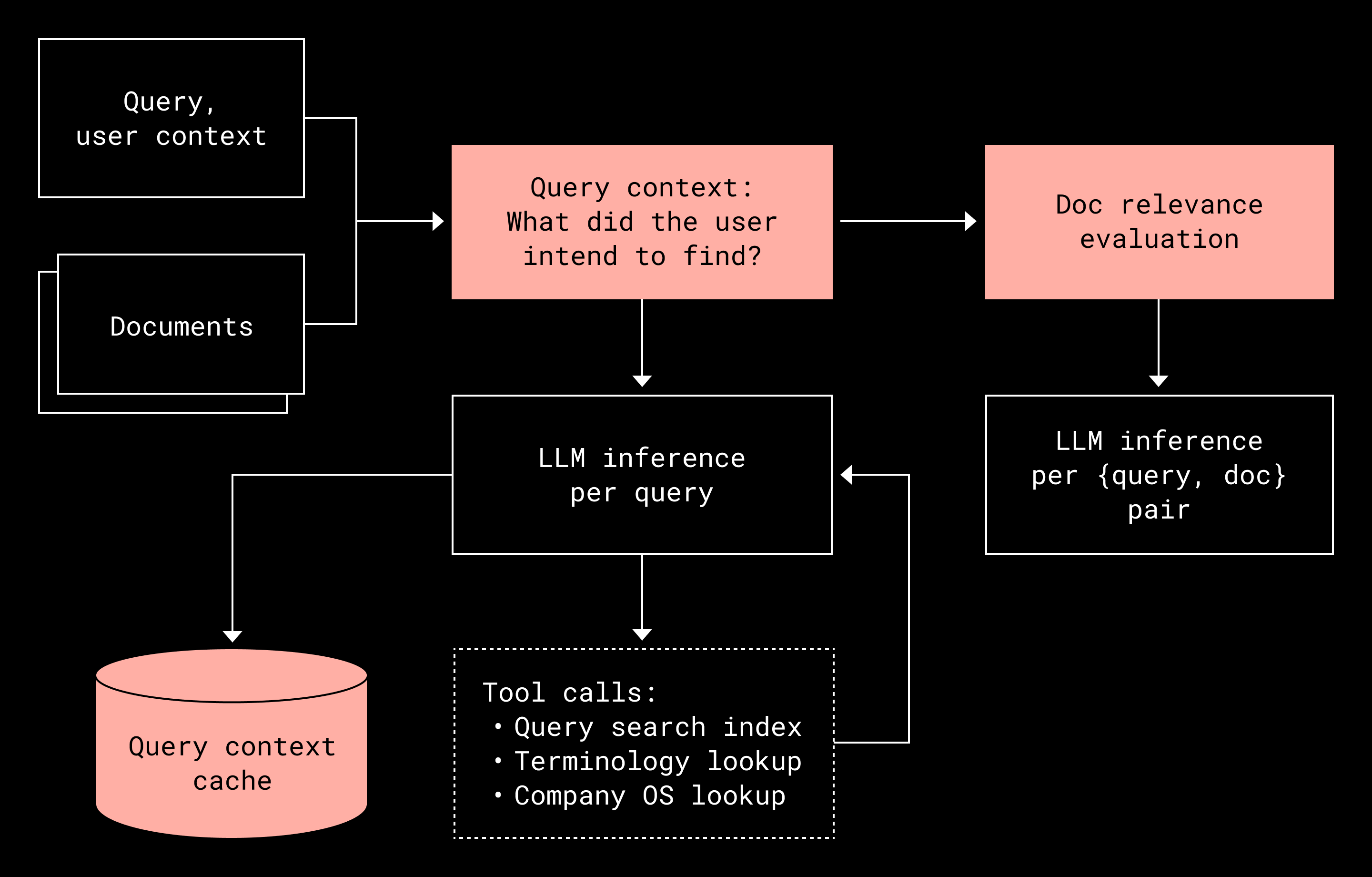
Prompt optimization
As evaluation scales, prompt quality starts to matter much more. Prompt optimization ends up looking a lot like how human guidelines are developed: You review cases where the model gets relevance wrong, adjust the instructions or add missing context, and then test again. This is harder than it sounds. Small prompt changes can cause unexpected regressions, and consistency becomes harder to maintain as prompts grow longer and more complex.
Meta-prompting frameworks such as DSPy can help manage this complexity. (DSPy is a library for programmatically optimizing LLM prompts against defined evaluation targets.) Given a clear objective and a small set of human-labeled examples, DSPy can automatically refine prompts to better match human judgments. This makes it possible to reuse the same optimization approach across different evaluation tasks and model configurations, rather than treating each case as a one-off.
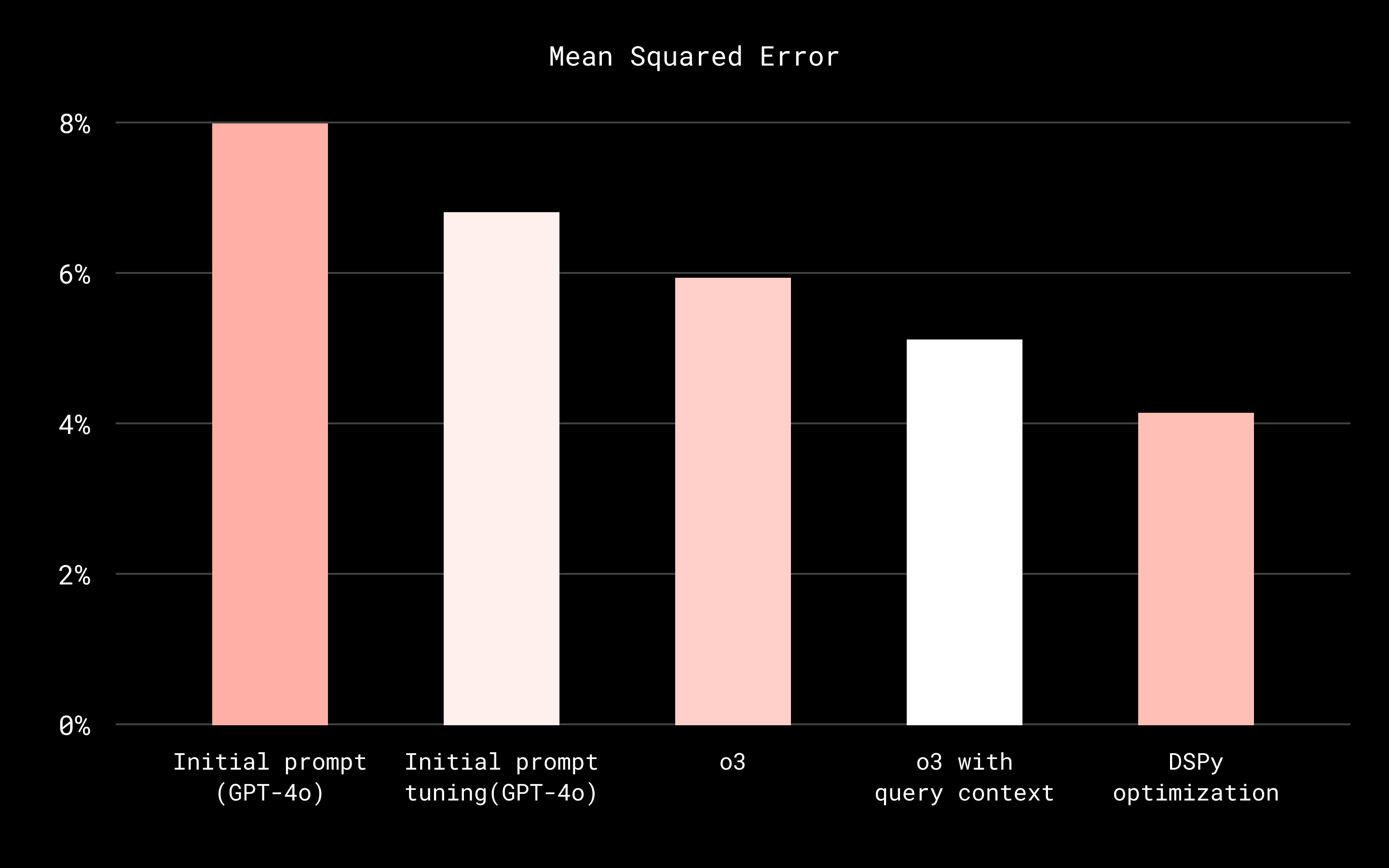
The chart below shows how the mean squared error (MSE) for the LLM-based relevance evaluator improved over time, driven by prompt refinement, the use of a reasoning-optimized model, incorporation of query context, and automated optimization with DSPy.
Conclusion
The relevance labeling approach described here is not limited to document search or tied to a specific model or evaluation framework. What matters is the underlying pattern: starting with a small amount of high-quality human judgment, using that judgment to calibrate LLM-based evaluation, and then scaling relevance labeling in a way that remains measurable, auditable, and correctable over time.
Because LLM-generated labels are grounded in human-reviewed reference data, they can be continuously monitored, stress-tested, and re-calibrated as models, prompts, and product requirements change. This grounding establishes a stable evaluation baseline that makes regressions detectable and improvements measurable, even as the surrounding system evolves.
As Dash expands to support additional content types—such as images, videos, messages, and chat—the evaluation problem becomes more complex. Each domain encodes relevance differently, and surface-level similarity is often insufficient. Human-calibrated LLM evaluation provides a shared mechanism for adapting relevance judgments across modalities without rebuilding labeling pipelines or redefining evaluation criteria from scratch.
Even as models improve, human grounding remains a structural requirement. Prompts drift, models change, and product expectations shift. A persistent, human-reviewed reference set anchors evaluation over time, allowing LLMs to scale judgment without eroding correctness. In short, LLMs make it possible to apply human judgment consistently and at scale, rather than replacing it.
Acknowledgments: Eric Wang, Hans Sayyadi, Josh Clemm, Mingming Liu, Andrew Yates, Marta Mendez, Jun Sun, Jay Frank, Angela Li
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit jobs.dropbox.com to see our open roles.


