

In our previous blog posts on Dropbox's document scanner (Part 1, Part 2 and Part 3), we focused on the algorithms that powered the scanner and on the optimizations that made them speedy. However, speed is not the only thing that matters in a mobile environment: what about memory? Bounding both peak memory usage and memory spikes is important, since the operating system may terminate the app outright when under memory pressure. In this blog post, we will discuss some tweaks we made to lower the memory usage of our iOS document scanner.
Background
In the iOS SDK, the image container used ubiquitously is UIImage. It is a general container for images that cover pretty much all the common use cases. It has the following nice properties:
- It is immutable: immutability is a great property for a data container in general. In Apple’s own words,
- “… because image objects are immutable, you cannot change their properties after creation. Most image properties are set automatically using metadata in the accompanying image file or image data. The immutable nature of image objects also means that they are safe to create and use from any thread.”
- It is reference-counted: you can pass it around without deep-copying, thanks to Automatic Reference Counting.
- It handles image metadata, like display scale and orientation: this allows some operations to be trivially implemented. For instance, to rotate the image by 90 degrees, simply create a new UIImage pointing to the same data with a different orientation flag.
- It handles various pixel layout and primitives: it is possible that there is no bitmap backing a given UIImage at a given time—it could be a JPEG encoding, for instance. However, not all layouts are equally well-supported.
- It handles extra complexities like color space: the image could be sRGB, grayscale or palette-based, etc. A pixel is more than just an 8-bit number, and UIImage strives to fully specify the semantics.
However, one thing that UIImage does not let you do is to directly access the raw pixels (unless you have created one from raw pixels yourself and keep around an independent reference.) This makes sense because if a developer could directly access the raw pixels of an arbitrary UIImage, then immutability immediately goes out the window. You can get a copy of the pixels via CGDataProviderCopyData, which is a part of the public API. This isn’t bad when the image is small, but given that latest iPhones capture 12-megapixel images (= 48MB rasterized), even having one extra copy of the data hurts.
What makes this worse?
Image processing is often best expressed as a pipeline. For example, in our document scanner, the input image goes through resizing, document detection, rectification, enhancement and then compression, among other things. Consider the following toy example:
+(UIImage *)resize:(UIImage *)input;
+(UIImage *)rectify:(UIImage *)input;
+(UIImage *)enhance:(UIImage *)input;
+(UIImage *)doAllTheWork:(UIImage *)input
{
UIImage *intermediate0 = [MyModule resize:input];
UIImage *intermediate1 = [MyModule rectify:intermediate0];
UIImage *final_result = [MyModule enhance:intermediate1];
return final_result;
}@interface UIImageProvider
-(instancetype)initWithProvider:(UIImageProvider *)predecessor
-(void)doWork:^(UIImage *output)completionBlock
@end
@implementation /* ... some subclass that implements ImageProvider ... */
-(instancetype)initWithProvider:(UIImageProvider *)predecessor
{
if (self = [super init]) {
_predecessor = predecessor;
}
return self;
}
-(void)doWork:^(UIImage *output)completionBlock
{
// The work could be done asynchronously on a different thread.
[_predecessor doWork:^(UIImage* input) {
uint8_t *pixels = _someFuncThatGetsPixelsFromUIImageViaCopy(input);
// This could be cached if desired.
UIImage *output = _someCPPFuncThatDoesImageProcessing(pixels);
completionBlock(output);
}];
}
@end
@class ResizeImageProvider; // extends NSObject
@class RectifyImageProvider; // extends NSObject
@class EnhanceImageProvider; // extends NSObject
+(void)sampleApplicationCode:(id)inputProvider
{
resizer = [[ResizeImageProvider alloc] initWithProvider: inputProvider];
rectifier = [[RectifyImageProvider alloc] initWithProvider: resizer];
enhancer = [[EnhanceImageProvider alloc] initWithProvider: rectifier];
[enhancer doWork:^(UIImage *output) {
... // do something with output, e.g. display, upload or store.
}];
}While ObjC blocks afford us flexibility, consider what happens in each of resize , rectify , enhance. In each method, before doing any useful work, we will have to read the pixels first, incurring a copy. As a result, we would end up doing a lot of memcpy operations. It seems silly to extract the pixels and then imprison them again in a UIImage each time.
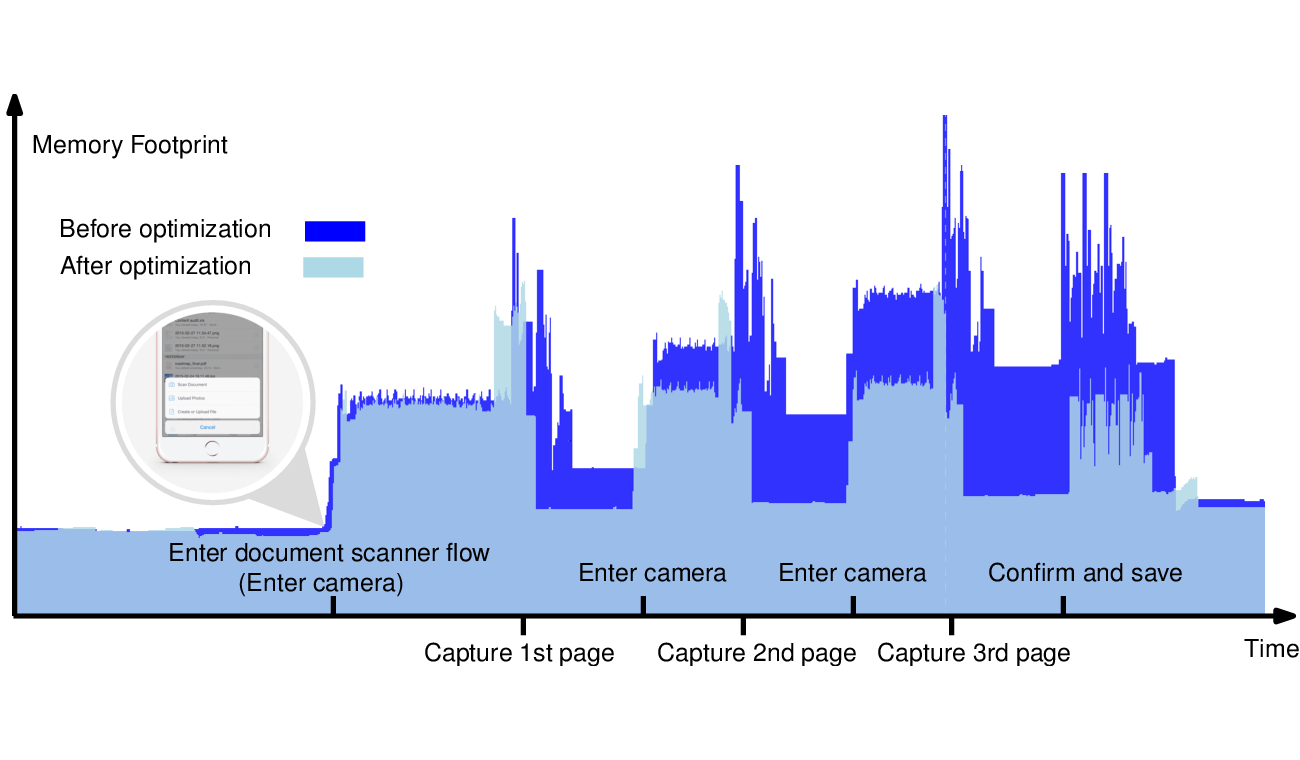
The teaser graph above shows a visualization created from Xcode's Instruments app, as the document scanner flow is used to acquire a 3-page document. It is easy to see that there's indeed a large spike in memory usage while the camera is actively running, and upon the user tapping the shutter button. We would often run into out-of-memory process deaths from these spikes, and this led to exploring an alternate design that could reduce both the spikes and the peak usage.
Reducing Memory Usage
We decided to roll our own image class—call it DBPixelBuffer—which is a thin wrapper around a block of memory, so that we could have read access of the pixels without incurring a copy each time. However, with great power comes great responsibility: doing so puts immutability at risk, so it is important to take proper care.
Rolling out our own image class had some added benefits. Recall from the previous blog post that we are leveraging the onboard GPU to accelerate image processing. This requires passing the data to the GPU in a format that it can understand (typically 32-bit RGBA buffers), so using our own container gives us more flexibility to minimize the number of times the buffer may have to be converted when using the GPU.
Also, while UIImage contains a flag for orientation and allows zero-cost rotation of images, computer vision algorithms often assume that the input buffer is upright, unless they have been trained on a dataset that is explicitly augmented with rotations. Hence it is generally a good idea to normalize the orientation when passing the image to computer vision algorithms. Since rotating images was a very common editing operation, and we decided to keep the orientation flag in DBPixelBuffer, so that we could lazily rotate the image.
One complication is that the iOS camera gives us a UIImage, which is internally backed by a JPEG encoding. Reading the pixels triggers JPEG decompression, which is done in a temporary buffer managed by iOS. Because this temporary buffer is not directly accessible, we would need to copy the content of the buffer to a buffer we control. In other words, we will have two copies of the image in memory simultaneously, if we want to convert the given UIImage to DBPixelBuffer. To avoid this, we decided to do JPEG decompression with libjpeg, rather than using Apple's SDK, so that we could dump the data directly into a buffer we control. As an added benefit, we could choose to decode the JPEG at a lower resolution, if only a thumbnail was needed.
Note that even in the best case, converting from UIImage to DBPixelBuffer involves at least one extra buffer. Sometimes we want to defer this as much as possible—for many of the image processing operations we perform, we do not need to be at full resolution. If the result is going to be small, e.g. screen size, then we could do just enough compute (and not more!) to make sure the result looks good at the intended resolution. Hence we designed our image processing pipeline to take a DBPixelBufferProvider as the input, which is a common protocol implemented by both UIImage and DBPixelBuffer, so that the determination of the processing resolution could be deferred.
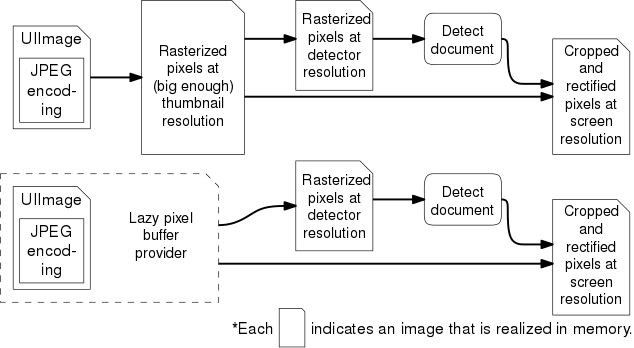
Why is this helpful? Previously we would create a thumbnail from the captured image right away, as shown in the top half of the above figure. However, because we didn't know a priori how big the detected document would be, the thumbnail had to be fairly large in order to ensure that the resulting crop was at least screen-sized. In the new implementation shown in the bottom half of the figure, we can avoid creating thumbnail up-front, and instead render the crop at screen resolution directly when needed.
Note that moving to a lazy provider introduces additional complexity: for one, it potentially introduces latency at the call site. We should also carefully consider whether and how to cache the resulting pixel buffers. Nonetheless, moving to a lazy provider allowed us to reduce memory footprint across all code paths at once, which was crucial in reducing the peak memory usage.
Summary
Transitioning from UIImage to our own image class with which we could precisely control when and how the pixels are transformed allowed us to reduce memory spikes from 60MB to 40MB, and peak memory usage by more than 50MB. (Check out the teaser graph above.) In this particular case, the complexity introduced by swapping out UIImage with our own was worth the reduction in resource utilization and increased stability.
Try out the Dropbox doc scanner today, and stay tuned for our next blog post.


