

Teams today create and share more types of content than ever before. Their work might span text, images, audio, and video, and that content is likely scattered across countless apps and tools. That can make it hard to find answers and insights fast—which is why we built Dropbox Dash. Its context-aware AI brings all your content and tools together, ensuring you always have everything you need to know to get work done. With Dash, you get an AI assistant and search engine that actually understands you and your team.
A key part of this understanding is Dash’s multimodal processing capabilities. This is what enables Dash’s intelligent features to work across content types—including photos and videos. To help us push these capabilities even further, we recently welcomed AI startup Mobius Labs to Dropbox. Their multimodal models, collectively named Aana, offer an ultra-efficient architecture for understanding rich media at Dropbox scale with significantly lower computational requirements than conventional architectures.
Aana does more than just make multimedia content searchable; it enables applications to analyze and interpret complex scenes, recognize objects and actions, and more accurately put content in the context of related work. That means teams—whether in creative, technology, media, or other fields—can get the answers they need to do their jobs more quickly, without manually digging through folders, timelines, or tools.
Here’s a closer look at how Aana works and why we’re excited to be bringing Mobius Labs’ Aana models into Dash.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
A multimodal engine built for scale
Audio, video, and images often hold valuable context—like design critiques, product demos, or client feedback—but they’re notoriously hard to search and organize. Understanding a one-hour video, for instance, means parsing scene changes, speaker shifts, on-screen text, objects, actions, and audio cues. Interpreting a collection of images poses similar challenges: recognizing who’s in them, what’s happening, and where and when it took place requires a nuanced grasp of visual detail. Think of the moment in Jurassic Park when the dinosaurs are revealed; all the essential information is communicated visually, but it’s the music, pacing, and brief dialogue that make it unforgettable.
Each of these modalities interacts intricately, often in different ways, with transcripts, shots, and other clues each following its own timeline and semantic boundaries. Extracting meaningful information from this rich but fragmented mix poses a significant challenge. It requires not only understanding each modality on its own—like what’s being said in the audio or shown in the video—but also understanding how those modalities relate to one another. In other words, systems need to capture how sound, visuals, and language combine to create meaning within a scene. Furthermore, doing that across exabytes of content quickly becomes cost-prohibitive without carefully designed systems.
This is where Aana comes in. It takes in files of all kinds—demo videos, audio interviews, photo libraries—and analyzes them together. Unlike systems that treat text, images, audio, and video as separate streams, Aana looks at how they relate to one another, revealing patterns and insights that emerge only when these modalities are combined.
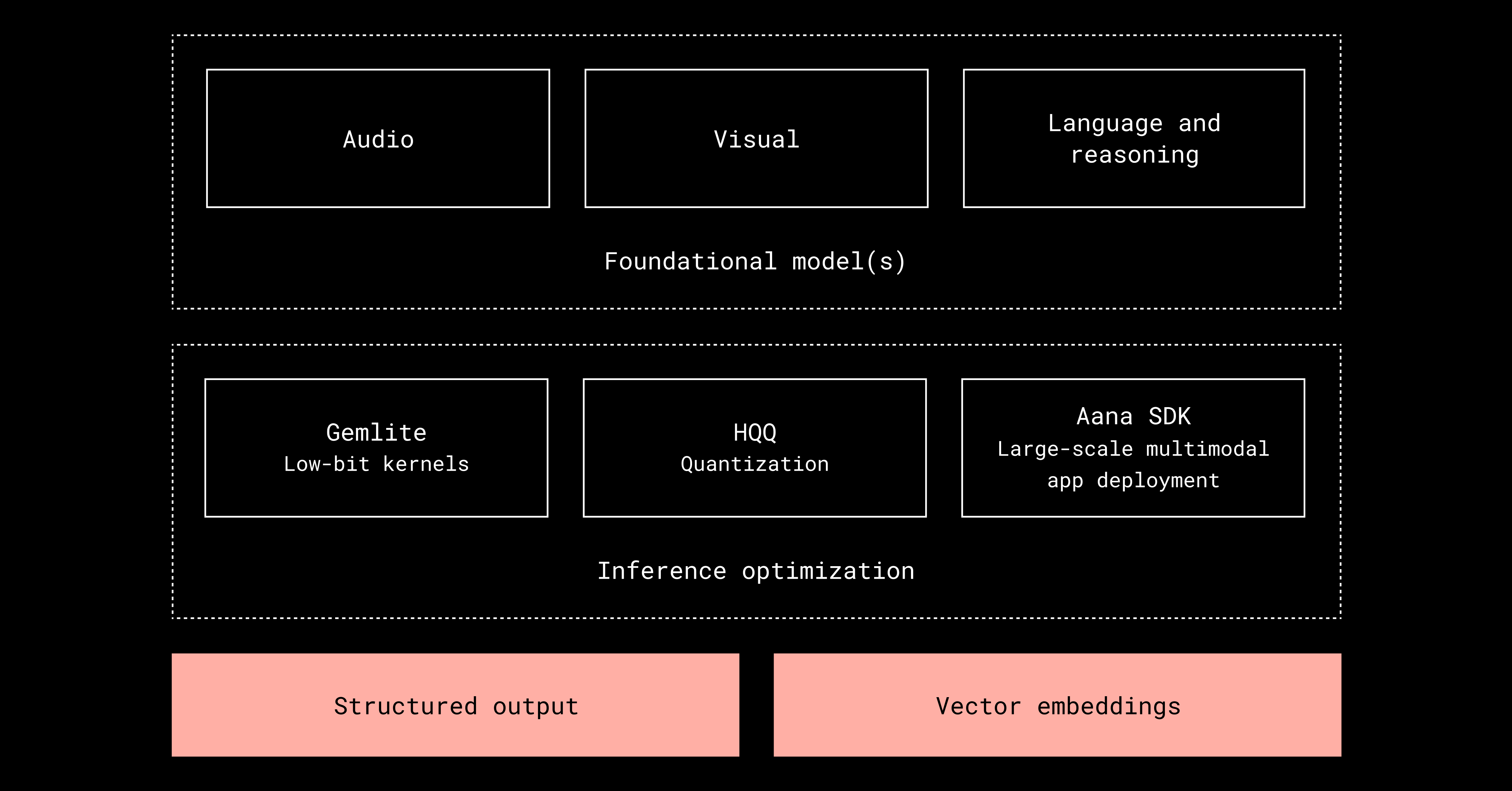
Under the hood, Aana combines open-source, fine-tuned foundation models for speech, vision, and language—continuously evaluated and updated as new releases emerge. For audio, it uses inference-optimized Whisper-like models developed with open-source collaborators, such as the faster-whisper-large-v3-turbo model. Its vision and language systems rely on transformer-based and mixture-of-experts (MoE) architectures engineered for fast, cost-effective inference on off-the-shelf GPUs. The team works closely with the open-source community to benchmark and integrate the latest advances, improving performance and efficiency over time. The entire system is built to strike an optimal balance, delivering high-quality multimodal understanding while keeping compute demands low.
With this foundation in place, Aana can do more than just recognize what’s happening in a scene—it can understand how that scene evolves. Aana follows how objects move, actions unfold, and layouts change over time. It can even connect insights across modalities, like pinpointing the exact moment in a video when someone walks to a whiteboard to explain a diagram. All of this information is distilled into a shared vector space, enabling fast, multimodal search. The result is a system that understands context. You can ask for “the part where the presenter explains the API flow” instead of scrubbing through timestamps or relying on basic metadata.
Behind this capability is an efficiency-focused architecture. Aana employs advanced inference optimizations that make large-scale multimodal understanding feasible. Its HQQ system enables low-bit (8-bit and 4-bit) inference for dramatically lower compute and memory costs, while Gemlite accelerates core AI operations like matrix multiplications and attention layers with custom GPU kernels.
These optimizations are orchestrated by the Aana SDK, which handles batching, model coordination, and efficient GPU utilization. The SDK also serves as a flexible framework for building and deploying multimodal applications, allowing multiple AI models to collaborate seamlessly while maintaining performance and scalability. Teams can configure, compose, and deploy different model setups and processing pipelines into production, making it easy to experiment, optimize, and scale new multimodal workflows with minimal overhead.
Together, these optimizations mean Aana can analyze exabytes of information with just a fraction of the compute footprint of traditional architectures. For teams working with large volumes of rich media, that opens the door to entirely new possibilities—from surfacing a specific visual motif across a company’s creative archive to summarizing years of client meetings into concise, searchable highlights.
What comes next
Dropbox has long been trusted by innovators and creative professionals who bring ideas to life, from musicians and filmmakers to designers, engineers, and marketers. As teams work across more formats and tools, their creative process depends on understanding content in context. That’s what multimodal tools like Dash make possible: When AI understands your work—wherever that work happens, and whatever format it’s in—you can spend less time managing your content and more time actually creating it.
We’re excited to welcome Mobius Labs’ team of multimodal experts to Dropbox. Bringing Aana’s capabilities into Dash won’t just help us make visual and audio content more searchable; it’ll provide foundational support for agentic workflows that can analyze and interpret multimedia data, surface insights automatically, and even take action on behalf of teams. For marketing, creative, and technical organizations alike, this means turning large collections of media into connected, searchable knowledge that helps teams find answers, generate ideas, and move work forward.
To learn more about Dash visit dropbox.com/dash.
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit jobs.dropbox.com to see our open roles.


