

File names play a vital role in facilitating effective communication and organization among teams. Files with cryptic or nonsensical names can quickly lead to chaos—whereas a well-structured naming system can streamline workflows, improve collaboration, and ensure easy retrieval of information. Consistency in naming across different files and file types enables teams to find and share content more efficiently, saving time and reducing frustration.
To make it easier for our users to organize and find their files, Dropbox has an automated feature called naming conventions. With this feature, users can set rules around how files should be named, and files uploaded to a specific folder will automatically be renamed to match the preferred convention. For example, files could be renamed to include a keyword or date.
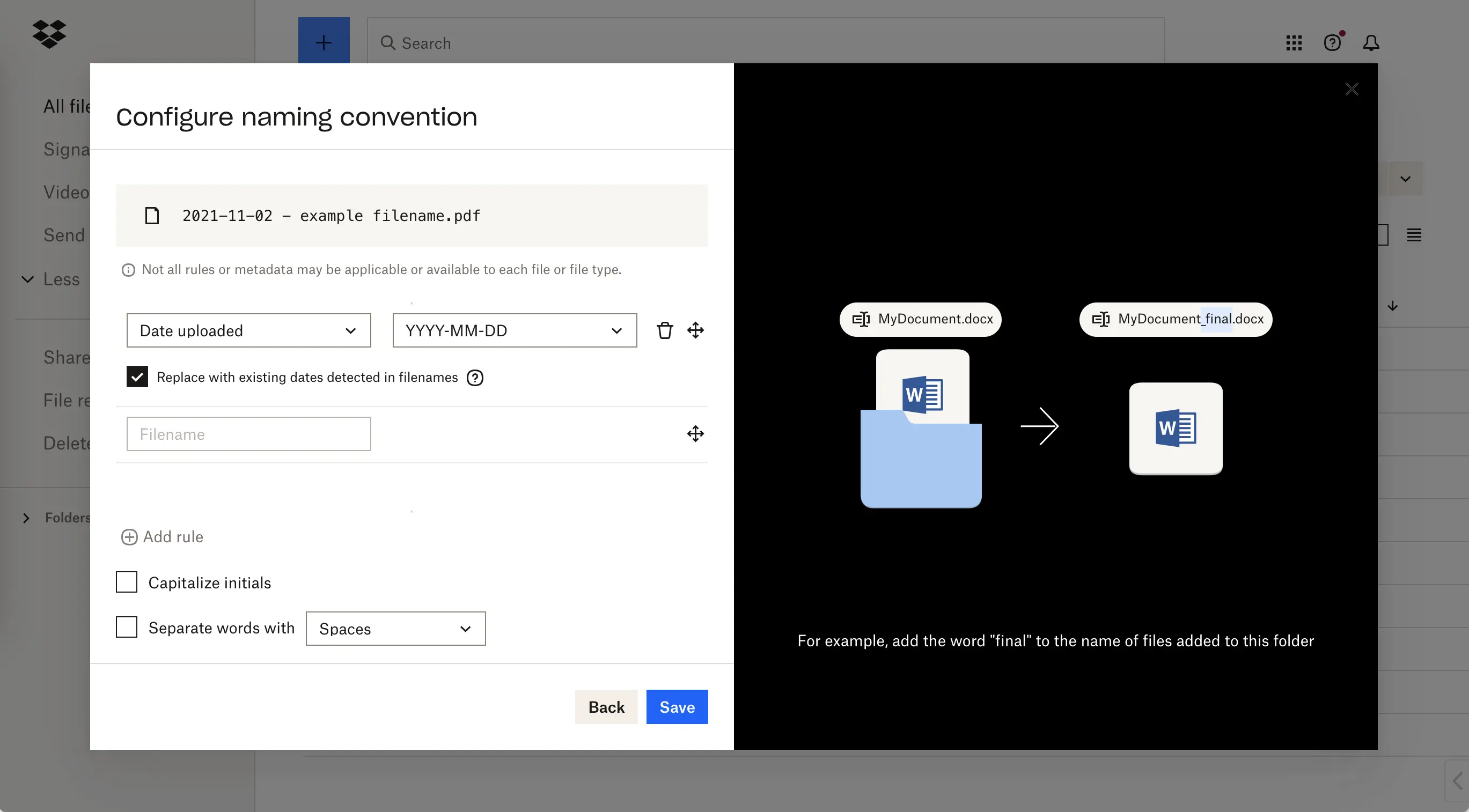
The user interface for naming conventions
Naming conventions can also detect whether a file name already contains a date, and use that date when renaming the file. However, identifying dates in existing file names can be challenging, particularly when the original naming conventions are inconsistent or ambiguous from one file to the next. For example:
- Different individuals or systems may use various date formats, such as MM/DD/YYYY, DD/MM/YYYY, or YYYY-MM-DD.
- File names sometimes contain abbreviation or acronym-based date representations, such as Jan for January or FY2023 for the fiscal year 2023.
- In some cases, dates in file names are not separated by any identifier characters or separators, such as survey20230601.
At first, we tried a rule-based approach to date identification. However, we quickly learned that while these conventions may be familiar to the creator of the file, it was hard for a rule-based approach to automatically recognize them without prior knowledge. At Dropbox scale, we would need to consider a large range of date formats if a rule-based approach were used.
To overcome these challenges, we instead developed a machine learning model that can accurately identify dates in a file name so that files can be renamed more effectively. We began work on the model in early 2022, and released a new, ML-powered version of naming conventions for Dropbox users in August 2022.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Components of a date
In order to reformat or replace a date in a file name, the first step is identification. While human observers can promptly identify many common date formats, not all dates are so easily identified—and the process is even less straightforward for machines.
A comprehensive date is made of several components, such as year, month, and day. Recognition can occur either holistically, treating the date as a singular entity, or in a more segmented manner, isolating and identifying each individual component.
Treating the date as a single entity simplifies the problem and reduces the complexity of the machine learning model because we only need to identify one type of entity. However, there are downsides to this approach. The model’s ability to handle variations in data formats will be limited, and various date representations might be challenging for the model to handle accurately. The model also loses the ability to provide a detailed breakdown of the individual components within a date, which could be useful in downstream tasks or analysis.
Flexibility and granularity were critical for our use case since most of naming convention’s downstream tasks are interested in the individual components of dates. For example, this lets us manipulate the month separately from date.
With these considerations in mind, we formulated an ML-based solution to our problem using supervised learning for multi-class classification. Below is a high-level overview of how we get the outputs from inputs, which go through annotation, tokenization, encoding, and classification modules. We will explain each module in detail in the following sections.
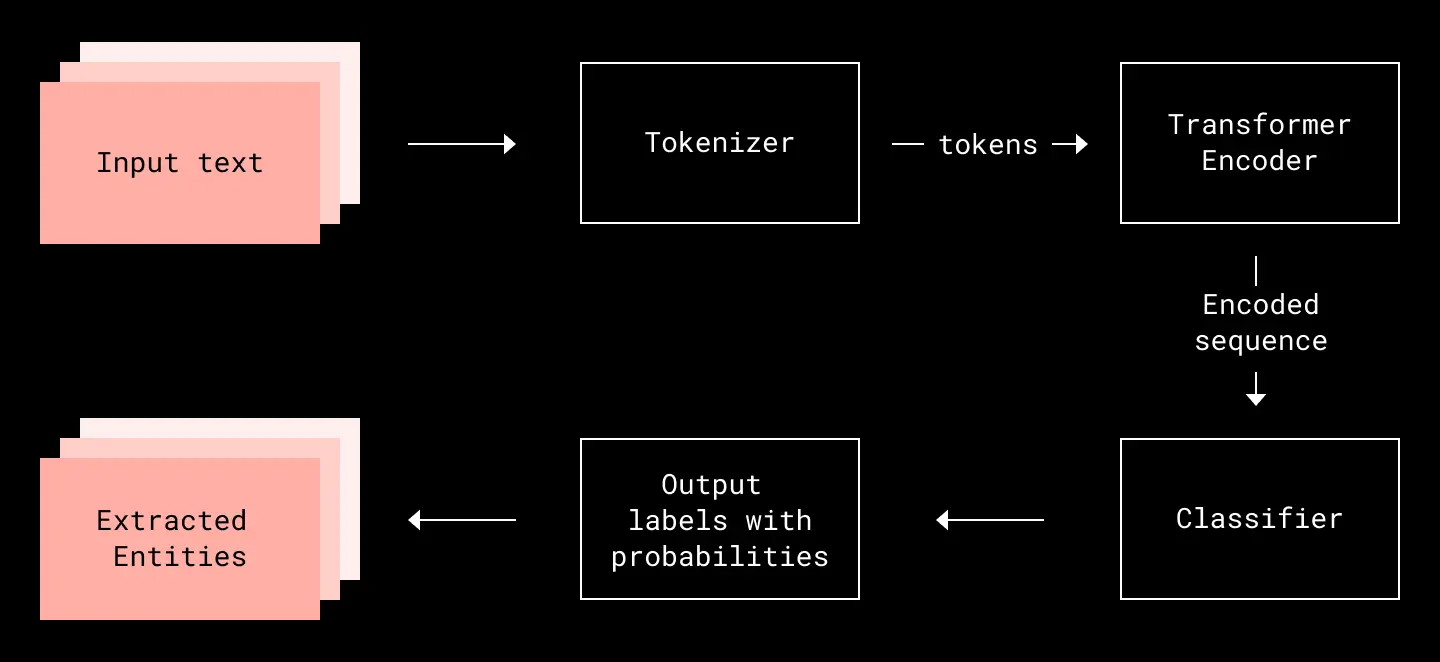
Overview of the workflow for extracting date components from a file name
Annotations
To train our model, we used file names sampled from Dropbox employees. To provide context and meaning to the training data, we then undertook a process of manual data annotation. This involved assigning labels to the file names to create high-quality training data. The labeling process entails associating the data with the desired output or target information—in this case, the identification of date components. Specifically, we marked the positions of dates in file names.
We used Doccano, an open source annotation tool, to conduct annotations on the sampled file names. Dropbox employees reviewed each data instance to determine the date elements, such as year, month, and day. Annotation is an iterative process—especially in complex cases where naming conventions can be subjective or context-dependent—so iterative refinement was necessary to ensure a high-quality dataset.
To enable the trained machine learning model to effectively generalize to unseen data, we also needed to make sure the training data set had sufficient coverage of various date formats. Otherwise, the model could struggle to accurately identify dates in real-world scenarios. Because it would be difficult to cover enough cases through human annotations alone, we built a tool to generate synthesized data.
Once a missed format was identified, we annotated a few samples and used the tool to generate a large set of synthesized data with the same format. For instance, the date format MM_DD_YYYY was not captured in our training data, which meant the model was not able to predict any date components from file names containing this format. We used the tool to synthesize file names containing this date format, and integrated the synthesized file names with the original human annotated training data to reduce overfitting risks.
Overall, we have a few thousand training samples. The trade-off between the cost of annotation and the size of training data was a critical consideration. This is one of the reasons why we leveraged transfer learning. With transfer learning, we can still get good performance by fine-tuning a smaller, annotated data set like ours, making it a more cost-effective approach.
Tokenization
It’s important to note that file names might encompass words or phrases beyond just dates. Our learning objective is also to understand the context of a file name—specifically, the words surrounding the dates. This is where tokenization comes into play. With tokenization, we divide file names into segments. These could be words, characters, or phrases, based on the chosen tokenization algorithm. By analyzing each token separately, the model can capture the structure and patterns within file names more effectively.
Depending on the granularity level of the task, there are different tokenization algorithms to choose from. For example:
- Word tokenization is simple and intuitive, but it generates a large vocabulary, and it does not handle out of vocabulary (OOV) problems well if we limit the size of the vocabulary.
- Character tokenization is very simple and would greatly reduce memory usage and computational time complexity, but it makes it much harder for the model to learn meaningful input representations and is often accompanied by a loss of performance.
- Subword tokenization divides words into subword units using techniques like Byte-Pair Encoding (BPE), Unigram Language Model, or WordPiece. It captures subword-level information, which is a good balance for our problem because we want a fine granularity for the dates part (e.g. at digital level), and word or subword level granularity for other parts. It allows the model to have a reasonable vocabulary size while being able to learn meaningful context-independent representations.
We chose the SentencePiece tokenizer, which is a subword tokenizer and based on the BPE and Unigram algorithms. SentencePiece provides different options based on the specific requirements of the tokenization process—which is useful for us, since dates are mostly made out of digits. By default, it treats digits as separate tokens, similar to characters or words.
Once file names are tokenized, we label the tokens based on the annotations conducted before tokenization. Inside-Outside-Beginning (IOB) tagging is a method used in natural language processing to annotate tokens in a sentence with labels to indicate their position within a sequence. In IOB tagging, each token is assigned one of the three labels: “I” (Inside), “O” (Outside), or “B” (Beginning). These labels are used to represent the position of the token relative to a particular entity or chunk.
For example, for file name hello 2022-04-01!, the IOB tag would be look like this:
["hello", "O"], (Not part of any entity)
[" ", "O"],
["2", "B-YEAR"], (Beginning of a Year entity)
["0", "I-YEAR"], (Inside of the Year entity)
["2", "I-YEAR"], (Inside of the Year entity)
["2", "I-YEAR"],
["-", "O"],
["0", "B-MONTH"], (Beginning of a Month entity)
["4", "I-MONTH"], (Inside of the Month entity)
["-", "O"],
["0", "B-DAY"], (Beginning of a Day entity)
["1", "I-DAY"], (Inside of the Day entity)
["!", "O"]
By using IOB tags, it becomes easier to identify and extract specific entities or chunks in a file name, as the labels indicate the position and boundaries of the entities within the sequence of tokens. These IOB tags are also the target labels we are going to predict with a multi-class classifier we will detail next.
Classification
Now that we’ve defined our IOB tags and linked each tag to a token generated through tokenization, we can move on to our ultimate objective: predicting IOB tags for a file name that hasn’t been encountered before. This prediction of IOB tags is instrumental in reconstructing the date components. To achieve this, a multiclass classifier was trained. For inputs, we use file names as sequences. The outputs are IOB tags.
Traditionally, a text-based data classification task could be solved with a bag of words (BOW) analysis, such as frequency based TF-IDF or word hashing. An obvious limitation of this type of approaches is it discards the word order and ignores the context, which is important for solving our problem. Instead, transformer-based approaches have shown remarkable performance on various NLP tasks. Self-attention enables the model to create rich, contextualized representations for each token in the input sequence, while transfer learning enables fine-tuning of specific classification tasks with smaller labeled datasets. They both yield improved performance.
In our classification task, the transformer-based model DistilRoberta is our backbone for predicting IOB tags. With a sufficiently extensive training corpus, DistilRoberta is able to achieve good performance on most of the NLP tasks. Moreover, it is well-balanced among models in terms of size, efficiency, and performance.
However, we still suffered performance issues at inference time. With high real-time latency of more than one second, we knew the resulting user experience would be poor. To make DistilRoberta faster at inference time, we applied several optimization techniques such as model pruning and model quantization. Model pruning removed unnecessary parameters or layers from the model, while model quantization converted the model to a lower precision format (e.g., from float32 to float16).
These optimization techniques helped us to bring our latency down to an acceptable level. Among the optimization strategies we implemented, model pruning exhibited the most influence on latency. DistilRoberta has six layers of encoders and 88 million parameters, which yield a model size of about 300 MB. With model pruning, we were able to remove the last two encoding layers without compromising performance, resulting in a latency reduction of more than 30%.
Results
In testing, our ML model saw a 40% increase in renamed files over our baseline rule-based model. Following the rollout of the ML model to users in August 2022, we also saw an increase in both the feature’s weekly active users and the number of renamed files. Notably, naming conventions were applied to more than one million files during the feature’s first few weeks of availability alone.
One challenge we observed in our user research was that some users were reluctant to perform the initial, manual configuration of naming convention rules for a folder. To address this, we started to automatically suggest potential naming conventions based on the naming conventions of existing files already in a folder. This approach enabled users to easily apply their existing conventions to new files added to the same folder, rather than having to define their unique conventions from scratch.
Finally, it’s worth noting that other elements such as names, locations, and organizational entities are also commonly found within these file names. At present, our model can only extract dates components—but in the future, we envision leveraging more sophisticated models, such as large language models, to identify more types of entities. This would enable an even more detailed and precise renaming experience.
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


