

At Dropbox, we are proud to have recently hit one billion downloads on what is still our original Android app. Historically, we have been a relatively small team of about a dozen engineers. Recently, though, our org has grown to more than 60 mobile engineers. This growth led to an explosion of features (great!) as well as an explosion of execution time for our testing pipeline (not so great).
As the org grew, the time it took to run our automated suite of unit tests went from 30 to 75 minutes. What started as the effort of a handful of engineers had increased to 400 modules and 900,000 lines of code. Maintaining a high bar of quality with this much code requires a continuous investment in testing.
This year, we spun up a Mobile Foundation team and let them loose on our mobile testing infrastructure. We want to share how we scaled our CI pipeline, which is built on top of an in-house task runner called Changes to better serve the 3x growth of new engineers, new features and of course, new tests.
Using industry standard tools, some code borrowed from AndroidX, and lots of Kotlin, we reduced our CI runtime from an average of 75 minutes to 25 minutes. We did this by learning a lot about Gradle, offloading work to Firebase Test Lab, and rearchitecting our CI jobs to better allow parallelism.
Step 1: Recognize the problem
The growing team and codebase exposed some pain points in our development infrastructure. One of our biggest came from our testing pipeline which was run on every update to our diffs (i.e. pull requests). Our Android app has a suite of over 6,000 unit tests to ensure we can continually make improvements and update the app without any regressions.
We run some of these unit tests off-device (i.e. in a JVM) while others run on emulators. The long CI cycle was compounded by how we calculated code coverage. We want to make sure that coverage does not drop when writing new code. We were using a custom Python toolchain to validate the coverage level of each file in the codebase.
Unfortunately, the custom tooling suffered from occasional flakiness and a persistent lack of flexibility. The combination of this flakiness with long-running checks was extremely frustrating, and a significant productivity killer.
Save developers from developing bad habits
One of the wonderful things about Dropbox engineers is that they will go to great lengths to avoid frustration and wasted time. Unfortunately, when it came to our time-consuming CI, this trait led our engineers into development anti-patterns. Rather than many small diffs, folks were making a few large ones.
Engineers sometimes ended up writing less automated tests for new code, due to a fear of flakes causing delays for hours. This meant that we had a higher reliance on manual QA than we wanted. An example was engineers adding coverage exceptions of 0% early to files which then grew, untested, over time. These exceptions told our tooling to not validate test coverage on those files. Individually, these decisions were great for engineers who wanted to ship a small piece of code as quickly as possible. But they were less than great for the overall org, and for the long-term health of the codebase.
It’s important to recognize that the root cause of these issues was the bad developer experience of waiting for CI to finish running. It was halting their work unnecessarily too often. Investing in a better developer experience was well worth the time and focus they would get back. (At Dropbox, we believe focus is the new productivity.)
Our plan to reduce both CI flakiness and execution time revolved around a few goals:
- Test what is needed—no more no less
- Migrate to industry standard tools
- Parallelize Android unit tests that we run on device
Step 2: Examine the existing tech setup
The Dropbox Android app is built using Gradle and has about 400 modules stored in a Git monorepo. We have one module which is referred to as the monolith and has about 200,000 lines of code along with 2,200 unit tests. The remainder of the modules are very small by comparison, and mostly contain SDKs or new features.
Prior to our overhaul, we ran every test in the codebase on every pull request (PR) from an engineer. The process worked like this:
- When a developer sends a PR, a job in our CI infrastructure is created—a virtual machine begins executing various tasks.
- This virtual machine will set up the environment, use Gradle to build the app APK, assemble and run the unit tests, then launch an emulator and run the Android Tests.
- All our JVM tests , along with on-device unit tests produced coverage data. Once all tests are finished, custom scripts read and combine that execution data to produce an overall report for the project. When the report is generated, the job is complete and the PR is updated with the results.
Our existing setup had its fair share of custom tooling. For example, on CI we had previously made a decision to merge the source sets of our various modules into a single module/APK. This isn’t standard, but was done to make device tests execute more quickly. By creating a mega test module we only needed to compile one rather than dozens of test APKs.
This was a savings of roughly 15 minutes on every CI run. But as is often the case with custom tooling, it had tradeoffs. It led to a suboptimal experience for developers, where tests could succeed locally but then fail in CI. A common example: An engineer would forget to add a dependency to the app module when adding it to a library module.
Our handling of code coverage was another example of using custom infrastructure that involved tradeoffs. We used the industry standard tool Jacoco to measure code coverage, but had custom Python code for verifying coverage above a threshold. We wanted coverage reported on a per-file level, and allow for tests anywhere in the codebase to contribute to coverage for a given file, which was in a custom toolchain
Calculating coverage this way had the advantage of increasing overall coverage in our codebase. However, it led to a number of edge cases in our code which occasionally resulted in flakes in our CI process. It also allowed engineers to write tests in one module to improve coverage in another, an anti-pattern for module encapsulation. As a result, reusing modules in a new app would result in a drop in coverage for the new app.
Step 3: Selectively scale the pipeline
Running all of the tests on every PR was a simple way to guarantee the safety of a given change to the codebase. The downside was it took lots of time. Logically, you don’t actually need to run every test for every change to get the full safety of automated tests. You only need to run tests for code that changed, or that could have been affected by the change.
To visualize this, consider the following example module diagram for an application.
If code changes in the :networking module, what tests should be run to ensure everything still works? Of course, you would need to execute the tests inside the :networking module. What is a little less intuitive, but absolutely vital, is that you would need to also run the tests in :featureA. This is because :featureA might expect the :networking module to behave a certain way. The changes could violate those expectations and break :featureA.
So, when one module directly depends on another (e.g. :featureA directly depends on :networking), you must run the dependent module’s tests whenever the base module changes.
Next, it’s important to realize modules that implicitly depend on :networking might also break from this change. Think a Markov Blanket.
The reasoning is the same as for explicit dependencies, but is worth elaborating. Consider the impact of changes to the :networking module on the :app module. As we established above, it is possible that the change in the :networking module will change the behavior of the :featureA module. If :app was relying on :featureA to behave a certain way, and the change in the :networking module changes the way :featureA behaves, :app could break. This is how a change in the :networking module could end up breaking the :app module.
Ideally the code is not so tightly coupled that this situation would happen frequently, but it’s important to recognize that this is always a possibility. When a base module changes, anything that depends on the module, explicitly or implicitly, could break. Thus, we need to run the tests for :networking, :featureA, and :app whenever the :networking module is changed.
Now that we understand what tests must be run when a base module changes, we can see clearly what tests do not need to be run. In the example, tests for the :utils and :featureB modules do not need to be run when the :networking module changes. Those modules are not dependent, either explicitly or implicitly, on the behavior of the :networking module. They don’t even know the :networking module exists.
The key to saving time when running tests in CI is to not run the :featureB and :utils tests when an engineer updates the :networking module. When you have 5 modules, as in the example, the savings are likely small. But when you have 400 modules, you can really save time by figuring out what tests are needed and only running those tests, especially for product engineers who rarely make changes in base or util modules. Smaller test cycles increases developer confidence by allowing iterative changes in the same time that 1 large change used to be tested for.
To realize those time savings, we needed to:
- Find a way to determine what modules needed to be tested from the file changes in an engineer’s diff
- Construct a graph of the dependencies between modules
- Identify, for a given change, which modules were affected. This is a non-trivial programming task, given the format of the input data and available APIs.
Initially we thought we would need to make drastic changes, such as changing CI systems or abandoning Gradle for Bazel, which would have been a multi-year effort. After spending months evaluating Bazel we came to the conclusion that we do not have the resources to abandon the plethora of tools and community support that Gradle has.
As always in these situations, it would have been nice if someone else had already solved this problem and could help us out. Fortunately, in the world of Android development, there is a robust open-source community. AndroidX is one of the most prominent examples of open source repositories to improve Android development. Late last year, we were lucky enough to grab a few minutes with Yigit Boyar, an engineer on the AndroidX team, who shared with us how his team solved this problem while still using the Gradle build system.
We were doubly lucky. Not only did Yigit share his theoretical knowledge of this problem, he actually pointed us to the implementation used by the AndroidX team, which is open source! He got us to explore a part of AndroidX that we had never before thought to use before: the code that actually builds and tests AndroidX, particularly its novel approach to testing through an Affected Module Detector. If AndroidX can succeed using Gradle we were confident we can scale with it as well.
While this code was coupled to how AndroidX does revisions through gerrit, it nonetheless gave us a fantastic starting point for our own solution (Spoiler alert: We’ve open-sourced it.) We were able to migrate some helper classes to instead be dependent only on Git, and begin testing Git’s ability to determine what modules are changed when a given file is updated in our codebase. In our initial pass on JVM unit tests, we saw fantastic results from the Affected Module Detector. We used it to disable any JVM test task which didn’t need to run for a given change.
project.tasks.withType(Test::class.java) { task ->
task.onlyIf {
affectedModuleDetector.shouldInclude(task.project)
}
}
This was promising progress, and an aha moment of clarity that helped us pick up a general pattern of writing Gradle configuration code in Kotlin, which increases their testability.
However, this alone was not enough for a production-ready solution. A module with only disabled tasks still consumes a small amount of time to process—in our experience, about 500ms to 750ms. When multiplied by 400 modules, build profilers, and loggers, even a no-op run could take several minutes to bypass our unit tests.
Don’t exclude tasks, include dependencies instead
To prevent this unnecessary churning, we turned around our approach. Instead of excluding unnecessary tasks, we create a task which only includes necessary dependencies. Many Gradle tutorials later, we settled on the following, again all in Kotlin:
private fun registerRunAffectedUnitTests(rootProject: Project, affectedModuleDetector: AffectedModuleDetector) {
val paths = LinkedHashSet<String>()
rootProject.subprojects { subproject ->
val pathName = "${subproject.path}:testUnitTest"
if (affectedModuleDetector.shouldInclude(subproject) &&
subproject.tasks.findByPath(pathName) != null) {
paths.add(pathName)
}
}
rootProject.tasks.register("runAffectedUnitTests") { task ->
paths.forEach { path ->
task.dependsOn(path)
}
task.onlyIf { paths.isNotEmpty() }
}
}This gave us hope that we were on the right track and could soon try to apply this same algorithm to our on-device Android tests. We have released these tasks as part of our version of the affected module plugin.
Run Android Tests in the Cloud
Our previous implementation ran our Android tests on a series of emulators hosted in-house which were spun up using custom tooling written in Python. This had served us well, but it presented limitations in sharding the tests across multiple emulators, prevented us from testing on physical devices, and required upkeep on our part.
We evaluated a few options for hosting physical devices:
- Managed devices in house
- Google’s Firebase Test Lab
- Amazon’s Device Farm
We ultimately chose Google’s Firebase Test Lab because we wanted to be able to share knowledge with other companies our size, and because of the incredible availability of Firebase Test Lab support engineers on the Firebase community on Slack.
Using the same strategy as we had with unit tests, we rewrote our testing scripts to instead leverage Gradle and Android Plugin APIs by registering a task which only depends on modules which include Android tests. This task will call assembleAndroidTests and generate all of the appropriate Android Test APKs.
While this approach increases the number of APKs we generate, in turn increasing our overall build time, it achieves our goal of allowing us to test each module in isolation. Developers can now write more targeted tests and apply coverage in a more focused way. It also allows us to more safely use modules across multiple apps.
From there, we’ve incorporated Fladle into our Gradle scripts. This allows us to write a simple Domain Specific Language (DSL) and scale our individual Android Tests across multiple Firebase Test Lab Matrixes, sharding suites of tests where appropriate.
Reviewing our source code, most modules have fewer than 50 Android tests and run in under 30 seconds. However, our monolith still has hundreds of tests which take a few minutes to complete. Fortunately, Flank allows us to easily shard the tests and split them across multiple devices to run in parallel, reducing time drastically.
In a scenario where we run all of our tests from all of our modules, we will start 26 matrices, with up to 3 shards in the monolith’s matrix. Each matrix runs tests for a maximum of 2 minutes. Including the time to upload APKs, allocate devices, run the tests, and process the results, this step takes 7 minutes (Firebase only charges for the 2 minutes of runtime).
Due to Flank and Firebase Test Lab’s abilities to scale with our modules and to shard tests within an individual module, we expect this time to remain fairly constant as we continue to scale our code base.
Always: Evaluate opportunity costs
In the process of overhauling our testing strategy to go from “every test on every diff” to “only the necessary tests,” we discovered a few issues with our code coverage infrastructure. Our custom coverage implementation was separate from our standard Gradle toolchain, and thus required increased maintenance. This maintenance wasn’t always prioritized. And we discovered that the infrastructure had silently broken.
We faced a decision: update and fix our code to maintain the custom solution, or go a different direction.
We ultimately decided to move away from our custom solution. While the technical aspects of migrating to a more industry standard coverage solution are interesting, we think it’s more valuable to cover the process we used to make this decision. So, let’s briefly detour to describe our general approach to these kinds of questions and then cover how the general concepts applied in this particular case.
At Dropbox, engineering choices are all about evaluating trade-offs in the context of our values and goals. We balance perceived benefits against perceived costs. But simply looking at whether the benefits outweigh the costs is not enough. For any project we work on, whether an internal infrastructure tool or new feature for our users, we are not simply looking to build things with positive net value. We want to build things with the greatest value at the lowest cost. We are looking for work that generates maximum leverage for our investment of resources.
Thus, the right decision involves understanding opportunity costs. We must compare a given option with the best alternative. We must answer, “if we didn’t work on this, what is the highest-leverage thing we would work on instead?”
In an ideal world, the answers to these questions would be obvious, and picking the high-leverage things to work on would be trivial. In reality, answering these questions is often challenging and can easily become very time consuming. But spending lots of time making decisions is itself a problem!
So, just as we use heuristics to come up with acceptable solutions to NP-complete problems in computer science, we often rely on heuristics to make engineering decisions. There are several such heuristics we could cover that apply in various contexts, but in the interest of brevity we will focus on a few here.
Pareto solutions
The first heuristic that we apply at Dropbox is to look for Pareto solutions, where we can get most of the benefits of a given solution with a small fraction of the effort. Pareto solutions are inherently high-leverage, and are almost always an element of our final decisions. For example, in a small codebase with a small number of engineers, running all tests against every pull request is a Pareto solution compared with developing a selective testing algorithm.
But Pareto is not the be-all-end-all. There are times where it makes sense to go beyond an 80/20 solution. In particular, it is often worthwhile to go well beyond an 80/20 solution when a decision relates to a core competency of your team or organization.
The origin of Dropbox is a good example: emailing files to yourself was an 80/20 solution for sharing data across devices. Of course, it proved worthwhile to push beyond that particular Pareto solution.
Leverage your core competencies
Just as Dropbox has core competencies as a company, teams inside the company have their own core competencies for the customers they support, internally or externally. Thus, in addition to Pareto, we always consider whether a given decision relates back to one of our core competencies.
Sometimes it’s not worth it
That’s a very high-level look at the process of engineering decision making at Dropbox: Does a given direction provide the highest leverage for our time and resources when evaluated against some common heuristics? How does it connect back to our code coverage decision?
In this case, we asked ourselves: does fixing and maintaining our custom coverage infrastructure represent an 80/20 solution for coverage, and is code coverage infrastructure within our team's core competencies?
While we decided that code coverage infrastructure was indeed a core area of ownership for our team, the custom solution was more trouble than it was worth. Our team decided that we are able to provide more value to Dropbox through other infrastructure investments.
In the end we migrated away from the old solution and towards the industry standard of using Jacoco’s verification task. The only custom configuration we have is locating coverage data from firebase and local tests. We moved the logic surrounding this to Kotlin, and created a data model for our coverage files:
fun forVerification(): JacocoProjectStructure {
val extras = addExtraExecutionFiles(module, getCoverageOutputProp(SourceTask.VERIFY))
module.logger.lifecycle("Extra execution File Tree $extras")
val executionFiles = getExecutionFiles(module) + extras
return JacocoProjectStructure(
getClassDirs(module),
getSourceDirs(module),
executionFiles
)
}Midpoint evaluation
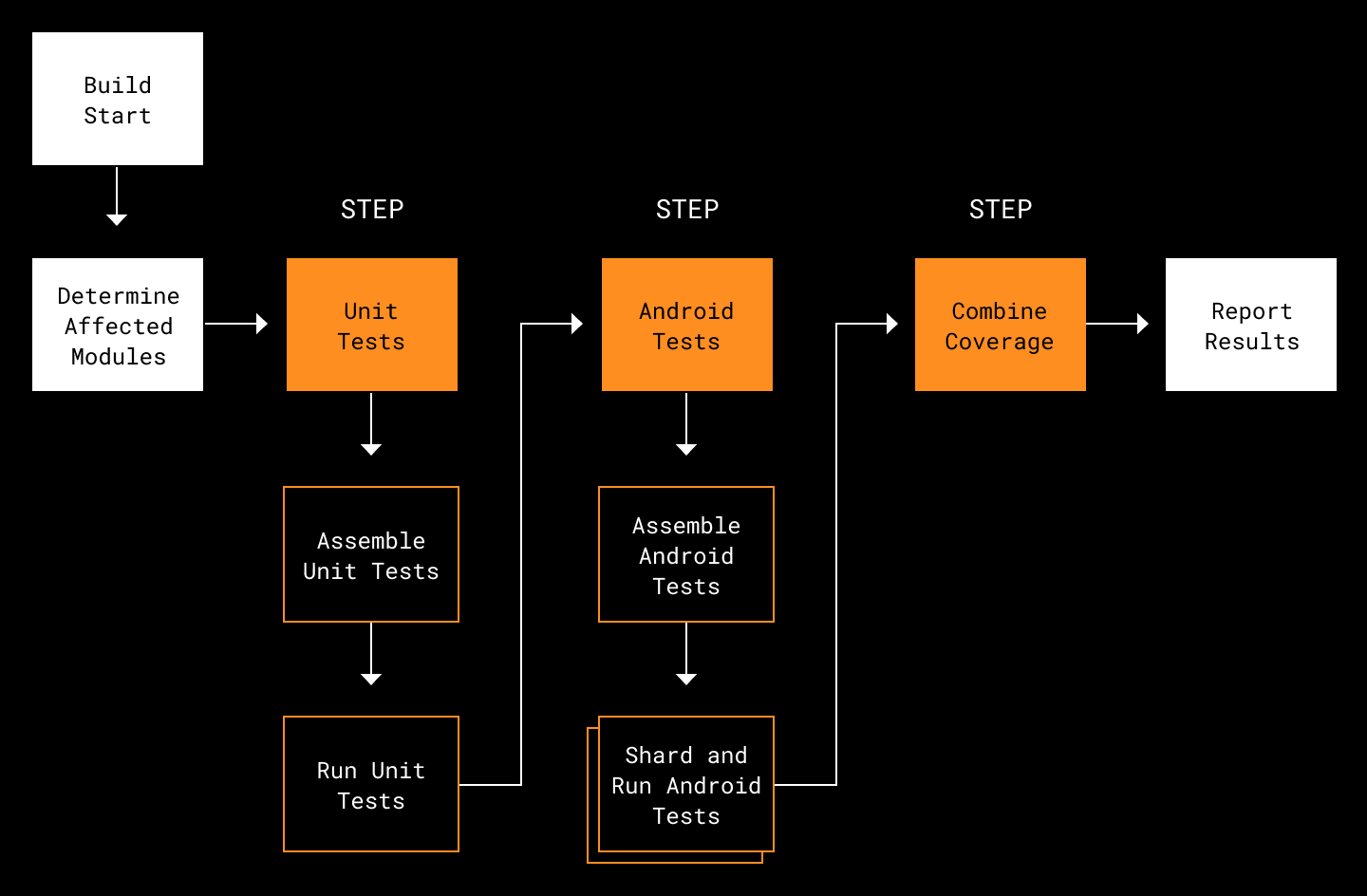
Once all the pieces were in place, we began to evaluate how we were doing in comparison to our existing method. After a few days of running as a shadow job, we found our average job run time was about 35 minutes. This included selectively building the source code, running unit tests, executing Android Test on Firebase Test Lab and calculating the code coverage.
This was a marked improvement over our existing job’s average time of 75 minutes. However, when we entered a scenario where someone changed one of the core modules, it would trigger most or all modules to be rebuilt, spiking our selective job’s run time to over 90 minutes.
Profiling our pipeline revealed that the main culprits were generating the additional module’s APKs and interacting with Firebase Test Lab. Generating the additional APKs added 10 minutes. And while Firebase Test Lab was able to shard the tests, the overall provisioning of devices and collecting results added four to five minutes overhead to our existing approach.
We wouldn’t be able to circumvent generating the APKs if we wanted to measure coverage on a per module basis. And Firebase Test Lab provided benefits around physical devices and sharding that we didn’t want to implement ourselves. This led us to evaluate how we were running the job, and if we could shard the number of modules which needed to be run.
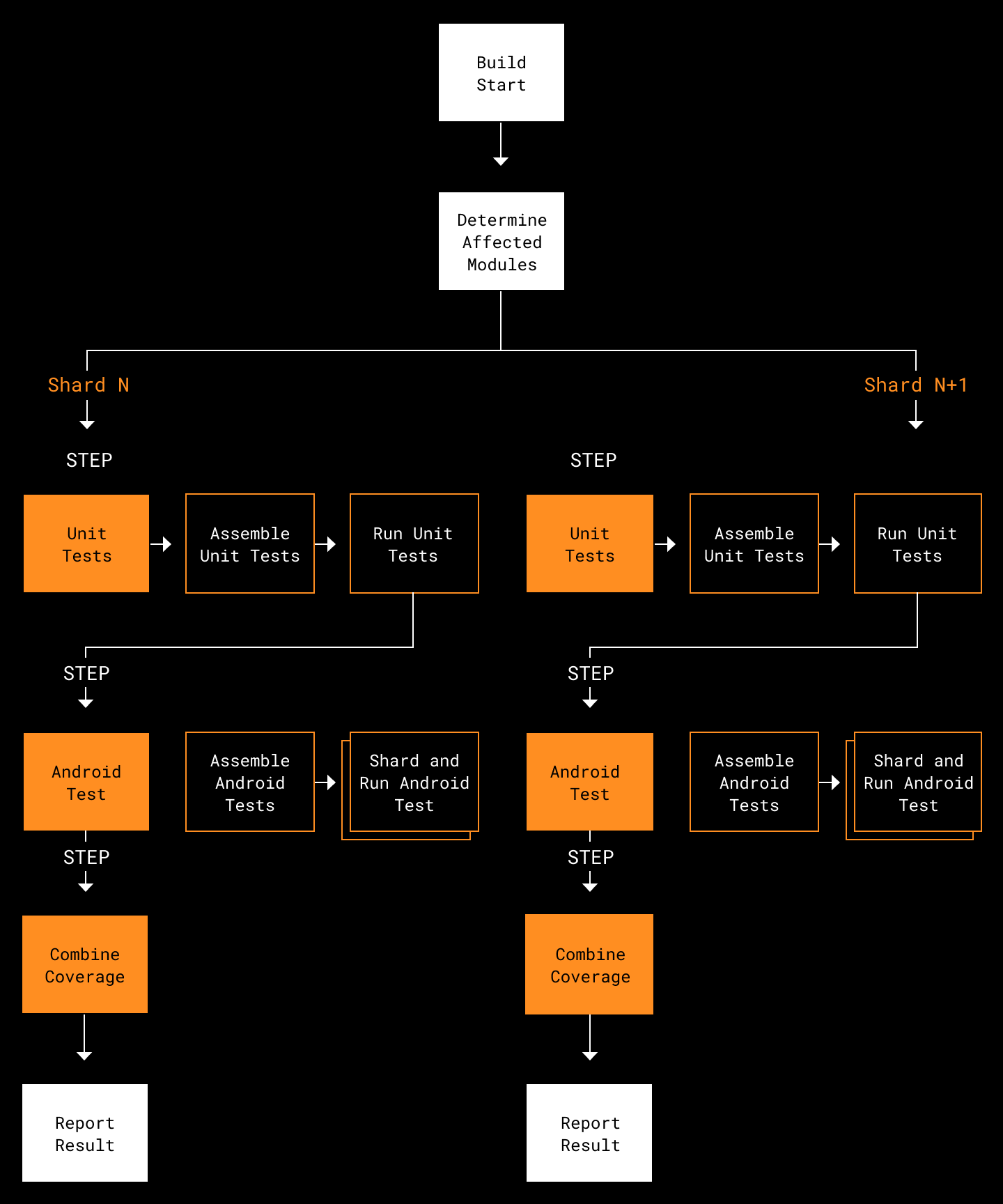
Shard modules whenever possible
Just as Firebase Test Lab sharded each of the module’s tests across multiple devices, we wondered if we could shard the assembly of the unit tests across multiple nodes in our CI environment.
Initially, we wanted to start our job, split the unit tests to one node, split the Android tests to another node, then finally collect all the results and run coverage over the results. We began to explore this option, but ran into limitations with Changes sharing artifacts across nodes—in particular, collecting artifacts. The nodes were on different VMs without a clear way to share results.
Pausing that investigation, we considered what was supported in Changes. We had the ability to provide a list of IDs to our task runner Changes, which would start an appropriate number of nodes each with a subset of ids passed in to run. This functionality is usually used to pass a list of test names to run per shard.
We, however, did not shard the individual tests as that would not be possible when running tests on an external device cloud. Instead we shared at the granularity of each module which contained unit tests and or Android tests. This would also alleviate the need to collect results from each of the nodes as they could all run coverage on their specific modules and report success or failure.
This strategy allowed us to do shard testing of our 400 modules on up to 10 VMs. On average, 20 modules are touched per diff which means each VM only needs to test 2 modules.
Providing information to Changes to shard proved fairly straightforward. Once we left an artifact with the modules to run, we could retrieve the subset of modules in the shard, provide that to the Affected Module Detector, and indicate that a given module should be included if it had source files changed or if it was passed in.
The sharding approach put us into a position where the average run time is 25 minutes, with a maximum run time of 35 minutes. Most runs require about 30 minutes of compute time, whereas the worst case requires 3 hours. While the worst case is higher, we feel this is acceptable. It’s rare for a developer to trigger this case. Overall, our revisions help get feedback to the developer as quickly as possible.
We also expect these times to decrease as we decompose monolithic modules into smaller feature modules. This is significantly better than our starting point of 75 minutes:
Takeaways—and source code
Three months after we set out to improve our CI pipeline, we’re fairly satisfied with the results. Most importantly, we have a scalable solution for testing. It will allow us to allocate more VMs for JVM testing or more Firebase devices for on-device testing as our module counts double and beyond.
The biggest takeaways for us were:
- Invest in Build/CI architecture as much as in production code.
- Don’t reinvent the wheel. Delegate the hard parts to Firebase, Flank, and Jacoco.
- When you’re feeling blue, sprinkle some Kotlin on it.
Get our AffectedModuleDetector on GitHub
It’s not enough to just talk about it: We’ve open sourced our affected module detector as a standalone Gradle plugin. We’ll add additional hooks to it in coming months.
We love community contributions. And if this sounds like work you want to get paid to do, we’re hiring!


