

Motivation
Imagine you’re an engineer working on a new product feature that is going to have a high impact on the end user, like the Dropbox Badge. You want to get quick validation on the functionality and utility of the feature. Each individual change you make might be relatively simple, like a tweak to the CSS changing the size of a font, or more substantial, like enabling the Badge on a new file type. You could set up user studies, but these are relatively expensive and slow, and are a statistically small sample size. Ideally, you write some code, add it to the codebase, have it tested automatically, and then release it immediately to some users so you can gather feedback and iterate.
Now imagine you’re the engineer responsible for maintaining the code platform. Every code change and every new version requires you or someone on your team to do a piece of work. You need to make sure that any random commit doesn’t break the development environment for everyone, that the machines that compile code are up and running, and that mysterious bugs are found and routed to the correct engineer to fix before a new version is released to the world. For the Dropbox Desktop Client, this also means keeping up lightning-fast sync rates, making sure core workflows (like sign-in) still function, and minimizing crashes. Ideally, you want to minimize manual operations work, and you want product quality to be high.
This can create conflict. The product engineer wants to release as quickly as possible, with ambitious new ideas. The platform engineer doesn’t want to stay until 10pm everyday to make that happen, or to have to constantly say no to the product engineer because changes are too risky to product quality. How do we keep these two types of people in harmony?
At Dropbox, the Desktop Client development and deployment schedule previously took 8 weeks per major release, with more than 3 full time engineers required to orchestrate everything. The experience was unpredictable for engineers, because there were frequent rollbacks and delays, and it took a lot of time to figure out and fix the source of new bugs and test failures. It would take up to 3 days before a product engineer’s code reached an internal user and 10-18 weeks before it was fully released.
With improvements in our process and systems, we are now operating on a 2-week cadence. Most of the release process is handled by a Technical Project Manager with two engineers who assist part-time, and debugging work is quickly routed to the responsible team. Code is sent to internal users within one business day, and to everyone within 2-4 weeks. The rest of this post (and the next post in this series) talks about how we achieved this remarkable improvement.
The previous model

In 2015, the Dropbox Desktop Client targeted a cadence of releasing a new major version every 8 weeks. It took 10-18 weeks from when code was added to the main branch of the codebase until the feature was deployed to 100% of Desktop Client users. To quote from old documentation, the "long cycle time is to ensure that we are not putting insecure or very broken code on our users' machines, because auto-update is a slow and imperfect process.” Here is a summary of that process:
Integrating new code
The Release Engineering team, responsible for the infrastructure on which test suites and build scripts ran, had at least one and up to three full-time people dedicated to operations work to keep the machines that allowed engineers to commit new code running.
Making builds
Compiling a new version of Dropbox was the responsibility of a specific engineer, who was the “Primary On-Call” for the Desktop Client team. Their day looked like this:
- Arrive to work. Choose a commit on which to make a new build.
- Do some manual tasks to incorporate new translations and tag the commit as the new official version. Push to the build machines, which would make new official Dropbox binaries.
- Troubleshoot the build machines and retry the build-making process if anything went wrong.
- Download and do some basic testing on those binaries.
- Adjust internal configuration parameters to serve the new build to the appropriate group.
- Send out any communications to announce the new build. This meant writing up an internal email with the commit log, and if the build was going to be posted to Dropbox Forums, a forum post.
- Spend the rest of the day filing, investigating, and triaging any bug reports that came in. If there was a sufficiently big issue, set the configuration back to a known good build. Do steps 1 - 4 again to make a new build with the desired fix.
Troubleshooting issues
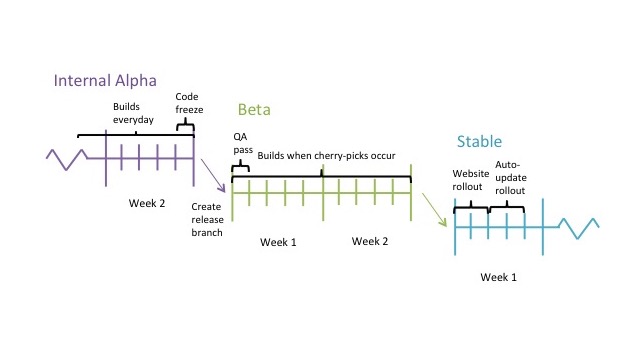
Another engineer, the Sync On-Call, would specifically be in charge of possible sync-related issues. The Sync On-Call and Primary On-Call together would do an initial investigation to either solve the problem or assign it to a person who would. There were three versions of Dropbox being served at any given point of time: the “office” build, which was just for internal users; “forums” build, which external users could beta-test; and “stable”, the version currently given to the world. Keeping track of all three was assumed to take up both On-Calls’ entire weeks, but was more difficult for newer engineers without as much context. Issues could easily take several days until their root causes were uncovered and fixed, so each major version of Dropbox spent weeks in each stage.
Rolling out
A third engineer, called the Release Manager, would keep track of all issues that needed to be quashed before a specific major version could be released to the general public, stewarding it over the entire 8 week release cycle. They often had a big feature going out into that release, and had a perk of assigning a codename. (Crowd favorite: “The Kraken”).
The Release Manager made sure all problems were resolved before rollout, and kept track of a complicated set of deadlines:
- Feature freeze: no new features added to the codebase.
- String freeze: no new user-facing strings, to allow time for translations.
- Code freeze: no non-critical code changes.
- Manual test pass: QA Engineers go through a spreadsheet of workflows to verify functionality.
- Rollout: Increasing segments of user receive the new build.
Any of these phases could turn an issue big enough to halt the release train, and after a fix often required going through various parts of the process again. This meant high process complexity, and a possibly large matrix of code combinations that needed to be tested. Engineers were cautioned only to make code changes that would improve the quality of the product after feature freeze (for example, fixing small bugs), but if you missed a release, you would have to wait a full 8 weeks longer until your code shipped to the world. This created pressure to scramble to hit a specific version, and furthermore, even a seemingly safe change could have unexpected side effects.
At this time, there were only about 30 engineers working on Desktop Client, meaning a tenth of the team was responsible for doing the often manual or organizational tasks necessary to keep the release trains running. We knew we wanted to speed up innovation on Desktop Client, but more engineers meant more changes per week, and more potential bugs that had to be tracked down per release. Further, the development environment required so much undocumented context that it was difficult for engineers working on other parts of the Dropbox to only work as a ‘part time’ Desktop Client engineer.
These existing tools and processes were unscalable. Something had to change.
Today
How did we do it?
- Reduce KTLO. “Keep The Lights On” is the Dropbox term for overhead required to maintain the current level of service. Often, it is work that requires precision but not intelligence, and therefore isn’t much fun for a human to do, is easy to mess up, and scales linearly with our product/code-change/release velocity.
- Automatically affirm quality. One engineer running code on a local machine is great - but Dropbox supports dozens of platforms, and users have infinitely inventive ways of poking and prodding the product. We try to catch as many edge cases as possible automatically ahead of time, and keep an (automatic) eye out in the field.
1. Improving Continuous Integration
When the project began in early 2016, Dropbox had Continuous Integration (CI) across the organization — engineers committed code to the same mainline branch in each codebase on a regular basis, and each commit kicked off a suite of test and builds. Generally speaking, as a software organization grows, CI and well-written test suites are the first line of defense for automatically maintaining product quality. They document and enforce what the expected behavior of code is, which prevents one engineer (who may not know or regularly interact with everyone who commits code) from unknowingly mucking up another’s work — or from regressing their own features, for that matter.
Our test and build coordinator is a Dropbox open source project called Changes, which has an interface for each suite that looks this:

Each bar represents a commit, in reverse chronological order. The result could be totally-passing (green) or have at least one test failure (red), with occasional system errors during the run (black). The time it took to run the job is represented by the height of the bar.
Engineers were expected to commit only code that would pass the full test suite by testing locally. If a build went red, the On-Call for that area of code would play “build cop”, tracking down the failures and resolving the issue. This involved identifying the breaking change, asking the author to fix it quickly, or backing out the commit themselves. This troubleshooting could take a significant amount of time, while the test suite remained red and engineers committing new code would get emails notifying them of test failures. Errored builds were sometimes the fault of new code, and sometimes due to external problems, adding another layer of complexity.Engineers quickly learned that if you got a failure email, it likely wasn’t due to your change. They no longer trusted the system, and weren’t incentivized to investigate every failure in detail, so multiple failures could pile up before the On-Call untangled them.
Untangling these build failures is KTLO work. To automate the job of ensuring that every single change passed the tests, Dropbox built a “Commit Queue” (CQ). Engineers submit new commits to the CQ, which run a suite of tests with the new commit incorporated into the codebase. If they passed, the CQ permanently adds the commit; if the tests failed, the commit is rejected and the author notified. The Commit Queue also ran tests on a greater set of environments than a single engineer could have on their laptop. An implementation of a commit queue had been running on the Server codebase since 2015, but using it for Desktop Client had two dependencies:
A. Unifying technology across codebases
The Server codebase had migrated to Git (from Mercurial) to reflect current trends in version control in 2014. Naturally, as they tackled similar issues and created new tools, those tools only explicitly supported Git. While we could have invested in improving the Server toolset to support Mercurial workflows, we ultimately decided instead to migrate the Desktop Client repo to Git. Not only would this enable us to leverage the work of our peer engineers, it also removed a point of daily friction faced by engineers committing code within both repos.
This actually hints at a greater trend within Dropbox. The Dropbox EPD (Engineering, Product, and Design) organization had transitioned into explicit “Product” and “Product Platform” groups at the very beginning of 2016, rather than “Desktop”, “Web”, “Android”, etc. teams that did a combination of product and platform work. One benefit was obvious: it allowed us to specifically invest in platform goals like performance and ease of development, and free up product initiatives to be cross-platform. An additional side-benefit is that it put engineers with similar considerations across different codebases closer together organizationally, so that they could cross-pollinate and leverage the same set of tools.
B. Reducing baseline flakiness
Blocking developers from landing broken commits is great, but how do you know for certain a test failure is actually a real product bug, and not just noise? More trickily, what do you do about transient “flaky” failures that only occur infrequently when the test is run?
There are two possible categories of reasons why a build would fail when the underlying code hadn’t regressed functionality: infrastructure flakiness (unreliability in the systems or code that run test jobs) and test flakiness (tests that fail some of the time, often non-deterministically). We had to hammer out a significant amount of both, or engineers would spend all their time waiting for their code to be merged. Or, they might retry preemptively, increase load on the infrastructure, and potentially cause cascading failures.
- Test Flakiness
Say you have a test that fails, non-deterministically, around 10% of the time, maybe due to a race condition. If you run it once in Commit Queue, most likely it will get through without a problem, and then fail every 10 builds or so there after. This will cause red builds in the post-commit runs, and occasionally block unrelated changes in Commit Queue. Both of these lead to a really bad developer experience, especially as flaky tests pile up and one test here or there fails, unrelated to your changeset, on every single run.
Sometimes the flakiness is a badly written test, with a timeout that is too short and therefore triggers when the code being tested is doing just fine. Sometimes the flakiness is caused by state left over from a previous test that interferes with the current one, like a database entry. At Dropbox, tests are run in random order, so the same failure can show up as problems across the test suite. Sometimes the feature being tested is flaky, i.e., a window is supposed to open after a button click, but only does so some of the time. Categorizing these intermittent failure types is challenging for a human, let alone an automated tool.
How do we identify flakiness? For one, we can re-run a test multiple times. The limiting factor is the total wait time for the test job, or if the the tests are sharded across multiple machines to reduce duration, the compute infrastructure costs of running the test suite. We configured Commit Queue to run a new or edited test many times as it is being committed, and reject a change if any of them fail. That should alert the authoring engineer that something needs to be fixed. From there, this engineer has the most context to figure out whether the product or the test (or both) is at fault. Once a test has passed Commit Queue, we run it up to three times post-commit and on unrelated changes, and count any success as “green”.
However, because Commit Queue allows intermittent failures once a test is admitted to the general pool, we have to identify tests that recently started flaking and alert the corresponding engineer. For this, we have an additional tool called Quarantine Keeper that removes tests from the main pool if they fail too often, and files a bug against the engineer tagged as the owner of the test to fix and re-add to circulation. The overall goal is to try and keep signal to noise high; very unpredictable random one-off failures should not be alarming, but consistent occasional failures should be eliminated.
- Infrastructure flakiness
Ironing out the build infrastructure flakiness meant systematically cataloging and fixing the types of failures — making sure that timeouts are set to appropriate intervals, adding retries where necessary, etc. The most impactful change we made was implementing a full-job retry to every job. If the network flaked momentarily in the beginning of the build, there was no reason to fail right off the bat — anything that failed for infrastructural reasons before 30 minutes were over was retried up to a total of 3 times, and it had a big impact on the greenness of our builds.
Meanwhile, we had to get serious about running a distributed system, including measuring and anticipating the computational requirements to run the test and compilation jobs. The Dropbox Desktop Client is officially supported on over a dozen operating system versions, spread across Windows, Mac, and Linux. A lot of developer pain previously came from having to run tests across all these platforms by hand, so a coupled goal for all of this was increasing the number of OSes we had CQ coverage on. However, the more configurations we ran automatically, the more surface area for flakiness to manifest itself on any given commit, gradually eroding trust in the CI even as we worked to reduce many sources of flakiness since the beginning of the project. Further, we had to be careful because if we enabled more jobs types than we could support, we could easily push the machines that ran the jobs past their limits and cause across-the-board failures.
One set of particularly interesting scaling-pains incidents occurred when rsync and git clone commands would mysteriously hang on Windows and Linux (but not Mac OS X) — and seemed to do so at a higher rate when more code was being committed. It turned out that the problem stemmed from the fact that our Windows and Linux Virtual Machines (VMs) shared the same network-attached storage device, while Mac OS X used different hardware. As we began supporting more test types, we were maxing out the disk I/O capacity of this machine, so rsync calls that simply copied files from one VM to the next would do both ends of the transfer on the same machine, overloading it, and fail! Thankfully we were able to fix it by removing some test types out of Commit Queue until we were able to upgrade our machine.


