

Dropbox is a big user of Python. It’s our most widely used language both for backend services and the desktop client app (we are also heavy users of Go, TypeScript, and Rust). At our scale—millions of lines of Python—the dynamic typing in Python made code needlessly hard to understand and started to seriously impact productivity. To mitigate this, we have been gradually migrating our code to static type checking using mypy, likely the most popular standalone type checker for Python. (Mypy is an open source project, and the core team is employed by Dropbox.)
Dropbox has been one of the first companies to adopt Python static type checking at this scale. These days thousands of projects use mypy, and things are quite battle tested. It has been a long journey for us to get to this point, and there were a bunch of false starts and failed experiments along the way. This post tells the story of Python static checking at Dropbox, from the humble beginnings as part of my academic research project, to the present day, when type checking and type hinting is a normal thing for numerous developers across the Python community. It is supported by a wide variety of tools such as IDEs and code analyzers.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Why type checking?
If you have only ever used dynamically typed Python, you might wonder about all the fuss about static typing and mypy. You may even enjoy Python because it has dynamic typing, and the whole thing may be a bit baffling. The key to static type checking is scale: the larger your project, the more you want (and eventually need) it.
Once your project is tens of thousands of lines of code, and several engineers work on it, our experience tells us that understanding code becomes the key to maintaining developer productivity. Without type annotations, basic reasoning such as figuring out the valid arguments to a function, or the possible return value types, becomes a hard problem. Here are typical questions that are often tricky to answer without type annotations:
- Can this function return
None? - What is this
itemsargument supposed to be? - What is the type of the
idattribute: is itint,str, or perhaps some custom type? - Does this argument need to be a list, or can I give a tuple or a set?
Looking at this fragment with type annotations, all of these questions are trivial to answer:
class Resource:
id: bytes
...
def read_metadata(self,
items: Sequence[str]) -> Dict[str, MetadataItem]:
...
read_metadatadoes not returnNone, since the return type is notOptional[…].- The
itemsargument is a sequence of strings. It can’t be an arbitrary iterable. - The
idattribute is a byte string.
In a perfect world, you could expect these to be documented in a docstring, but experience overwhelmingly says that this is often not the case. Even if there is documentation, you can’t rely on it being accurate. Even if there is a docstring, it’s often ambiguous or imprecise, leaving a lot of room for misunderstandings. This problem may become critical for large teams or codebases:
Although Python is really good at early and middle stages of a project, at a certain point successful projects and companies that use Python may face a critical decision: “should we rewrite everything in a statically typed language?”
A type checker like mypy solves this problem by providing a formal language for describing types, and by validating that the provided types match the implementation (and optionally that they exist). In essence, it provides verified documentation.
There are other benefits as well, and these are not trivial either:
- A type checker will find many subtle (and not so subtle) bugs. A typical example is forgetting to handle a
Nonevalue or some other special condition. - Refactoring is much easier, as the type checker will often tell exactly what code needs to be changed. We don’t need to hope for 100% test coverage, which is usually impractical anyway. We don’t need to study deep stack traces to understand what went wrong.
- Even in a large project, mypy can often perform a full type check in a fraction of a second. Running tests often takes tens of seconds, or minutes. Type checking provides quick feedback and allows us to iterate faster. We don’t need to write fragile, hard-to-maintain unit tests that mock and patch the world to get quick feedback.
- IDEs and editors such as PyCharm and Visual Studio Code take advantage of type annotations to provide code completion, to highlight errors, and to support better go to definition functionality—and these are just some of the helpful features types enable. For some programmers, this is the biggest and quickest win. This use case doesn’t require a separate type checker tool such as mypy, though mypy helps keep the annotations in sync with the code.
Prehistory of mypy
The story of mypy begins in Cambridge, UK, several years before I joined Dropbox. I was looking at somehow unifying statically typed and dynamic languages as part of my PhD research. Inspired by work such as Siek and Taha’s gradual typing and Typed Racket, I was trying to find ways to make it possible to use the same programming language for projects ranging from tiny scripts to multi-million line sprawling codebases, without compromising too much at any point in the continuum. An important part of this was the idea of gradual growth from an untyped prototype to a battle-tested, statically typed product. To a large extent, these ideas are now taken for granted, but it was an active research problem back in 2010.
My initial work on type checking didn’t target Python. Instead I used a home-grown, small language called Alore. Here is an example to give you an idea of what it looked like (the type annotations are optional):
def Fib(n as Int) as Int
if n <= 1
return n
else
return Fib(n - 1) + Fib(n - 2)
end
end
Using a simplified, custom language is a common research approach, not least since it makes it quick to perform experiments, and various concerns not essential for research can be conveniently ignored. Production-quality languages tend to be large and have complicated implementations, making experimentation slow. However, any results based on a non-mainstream language are a bit suspect, since practicality may have been sacrificed along the way.
My type checker for Alore looked pretty promising, but I wanted to validate it by running experiments with real-world code, which didn’t quite exist for Alore. Luckily, Alore was heavily inspired by Python. It was easy enough to modify the checker to target Python syntax and semantics, making it possible to try type checking open source Python code. I also wrote a source-to-source translator from Alore to Python, and used it to translate the type checker. Now I had a type checker, written in Python, that supported a Python subset! (Certain design decisions that made sense for Alore were a poor fit for Python, which is still visible in parts of the mypy codebase.)
Actually, the language wasn’t quite Python at that point: it was a Python variant, because of certain limitations of the Python 3 type annotation syntax. It looked like a mixture of Java and Python:
int fib(int n):
if n <= 1:
return n
else:
return fib(n - 1) + fib(n - 2)
One of my ideas at the time was to also use type annotations to improve performance, by compiling the Python variant to C, or perhaps JVM bytecode. I got as far as building a prototype compiler, but I gave up on that, since type checking seemed useful enough by itself.
I eventually presented my project at the PyCon 2013 conference in Santa Clara, and I chatted about it with Guido van Rossum, the BDFL of Python. He convinced me to drop the custom syntax and stick to straight Python 3 syntax. Python 3 supports function annotations, so the example could be written like this, as a valid Python program:
def fib(n: int) -> int:
if n <= 1:
return n
else:
return fib(n - 1) + fib(n - 2)
products = [] # type: List[str] # Eww
def fib(n):
# type: (int) -> int
if n <= 1:
return n
else:
return fib(n - 1) + fib(n - 2)
It turned out that these (and other) compromises didn’t really matter too much—the benefits of static typing made users quickly forget the not-quite-ideal syntax. Since type checked Python now had no special syntax, existing Python tools and workflows continued to work, which made adoption much easier.
Guido also convinced me to join Dropbox after finishing my PhD, and there begins the core of this story.
Making types official (PEP 484)
We did the first serious experiments with mypy at Dropbox during Hack Week 2014. Hack Week is a Dropbox institution—a week when you can work on anything you want! Some of the most famous Dropbox engineering projects can trace their history back to a Hack Week. Our take-away was that using mypy looked promising, though it wasn’t quite ready for wider adoption yet.
An idea was floated around that time to standardize the type hinting syntax in Python. As I mentioned above, starting from Python 3.0, it has been possible to write function type annotations in Python, but they were just arbitrary expressions, with no designated syntax or semantics. They are mostly ignored at runtime. After Hack Week, we started work on standardizing the semantics, and it eventually resulted in PEP 484 (co-written by Guido, Łukasz Langa, and myself). The motivation was twofold. First, we hoped that the entire Python ecosystem would embrace a common approach for type hinting (Python term for type annotations), instead of risking multiple, mutually incompatible approaches. Second, we wanted to openly discuss how to do type hinting with the wider Python community, in part to avoid being branded heretics. As a dynamic language that is famous for “duck typing”, there was certainly some initial suspicion about static typing in the community, but it eventually subsided when it became clear that it’s going to stay optional (and after people understood that it’s actually useful).
The eventually accepted type hinting syntax was quite similar to what mypy supported at the time. PEP 484 shipped with Python 3.5 in 2015, and Python was no longer (just) a dynamic language. I like to think of this as a big milestone for Python.
The migration begins
We set up a 3-person team at Dropbox to work on mypy in late 2015, which included Guido, Greg Price, and David Fisher. From there on, things started moving pretty rapidly. An immediate obstacle to growing mypy use was performance. As I implied above, an early goal was to compile the mypy implementation to C, but this idea was scrapped (for now). We were stuck with running on the CPython interpreter, which is not very fast for tools like mypy. (PyPy, an alternative Python implementation with a JIT compiler, also didn’t help.)
Luckily, there were algorithmic improvements to be had. The first big major speedup we implemented was incremental checking. The idea is simple: if all dependencies of a module are unchanged from the previous mypy run, we can use data cached from the previous run for the dependencies, and we only need to type check modified files and their dependencies. Mypy goes a bit further than that: if the external interface of a module hasn’t changed, mypy knows that other modules that import the module don’t need to be re-checked.
Incremental checking really helps when annotating existing code in bulk, as this typically involves numerous iterative mypy runs, as types are gradually inserted and refined. The initial mypy run would still be pretty slow, since many dependencies would need to be processed. To help with that, we implemented remote caching. If mypy detects that your local cache is likely to be out of date, mypy downloads a recent cache snapshot for the whole codebase from a centralized repository. It then performs an incremental build on top of the downloaded cache. This gave another nice performance bump.
This was a period of quick organic adoption at Dropbox. By the end of 2016, we were at about 420,000 lines of type-annotated Python. Many users were enthusiastic about type checking. The use of mypy was spreading quickly across teams at Dropbox.
Things were looking good, but there was still a lot of work to be done. We started running periodic internal user surveys to find pain points and to figure out what work to prioritize (a habit that continues to this day). Two requests were clearly at the top: more type checking coverage, and faster mypy runs. Clearly our performance and adoption growth work was not yet done. We doubled down on these tasks.
More performance!
Incremental builds made mypy faster, but it still wasn’t quite fast. Many incremental runs took about a minute. The cause is perhaps not surprising to anybody who has worked on a large Python codebase: cyclic imports. We had sets of hundreds of modules that each indirectly import each other. If any file in an import cycle got changed, mypy would have to process all the files in the cycle, and often also any modules that imported modules from this cycle. One of these cycles was the infamous “tangle” that has caused much grief at Dropbox. At one point it contained several hundred modules, and many tests and product features imported it, directly or indirectly.
We looked at breaking the tangled dependencies, but we didn’t have the resources to do that. There was just too much code we weren’t familiar with. We came up with an alternative approach—we were going to make mypy fast even in the presence of tangles. We achieved this through the mypy daemon. The daemon is a server process that does two interesting things. First, it keeps information about the whole codebase in memory, so that each mypy run doesn’t need to load cache data corresponding to thousands of import dependencies. Second, it tracks fine-grained dependencies between functions and other constructs. For example, if function foo calls function bar, there is a dependency from bar to foo. When a file gets changed, the daemon first processes just the changed file in isolation. It then looks for externally visible changes in that file, such as a changed function signature. The daemon uses the fine-grained dependencies to only recheck those functions that actually use the changed function. Usually this is a small number of functions.
Implementing all this was a challenge, since the original implementation was heavily geared towards processing things a file at a time. We had to deal with numerous edge cases around what needs to be reprocessed when various thing change, such as when a class gets a new base class. After a lot of painstaking work and sweating the details, we were able to get most incremental runs down to a few seconds, which felt like a great victory.
Even more performance!
Together with remote caching that I discussed above, mypy daemon pretty much solved the incremental use case, where an engineer iterates on changes to a small number of files. However, worst-case performance was still far from optimal. Doing a clean mypy build would take over 15 minutes, which was much slower than we were happy with. This was getting worse every week, as engineers kept writing new code and adding type annotations to existing code. Our users were still hungry for more performance, and we were happy to comply.
We decided to get back to one of the early ideas behind mypy—compiling Python to C. Experimenting with Cython (an existing Python to C compiler) didn’t give any visible speed-up, so we decided to revive the idea of writing our own compiler. Since the mypy codebase (which is written in Python) was already fully type annotated, it seemed worth trying to use these type annotations to speed things up. I implemented a quick proof-of-concept prototype that gave performance improvement of over 10x in various micro-benchmarks. The idea was to compile Python modules to CPython C extension modules, and to turn type annotations into runtime type checks (normally type annotations are ignored at runtime and only used by type checkers). We effectively were planning to migrate the mypy implementation from Python to a bona fide statically typed language, which just happens to look (and mostly behave) exactly like Python. (This sort of cross-language migration was becoming a habit—the mypy implementation was originally written in Alore, and later a custom Java/Python syntax hybrid.)
Targeting the CPython extension API was key to keeping the scope of the project manageable. We didn’t need to implement a VM or any libraries needed by mypy. Also, all of the Python ecosystem and tools (such as pytest) would still be available for us, and we could continue to use interpreted Python during development, allowing a very fast edit-test cycle without having to wait for compiles. This sounded like both having your cake and eating it, which we quite liked!
The compiler, which we called mypyc (since it uses mypy as the front end to perform type analysis), was very successful. Overall we achieved around 4x speedup for clean mypy runs with no caching. The core of the mypyc project took about 4 calendar months with a small team, which included Michael Sullivan, Ivan Levkivskyi, Hugh Han, and myself. This was much less work than what it would have taken to rewrite mypy in C++ or Go, for example, and much less disruptive. We also hope to make mypyc eventually available for Dropbox engineers for compiling and speeding up their code.
There was some interesting performance engineering involved in reaching this level of performance. The compiler can speed up many operations by using fast, low-level C constructs. For example, calling a compiled function gets translated into a C function call, which is a lot faster than an interpreted function call. Some operations, such as dictionary lookups, still fall back to general CPython C API calls, which are only marginally faster when compiled. We can get rid of the interpretation overhead, but that only gives a minor speed win for these operations.
We did some profiling to find the most common of these “slow operations”. Armed with this data, we tried to either tweak mypyc to generate faster C code for these operations, or to rewrite the relevant Python code using faster operations (and sometimes there was nothing we could easily do). The latter was often much easier than implementing the same transformation automatically in the compiler. Longer term we’d like to automate many of these transformations, but at this point we were focused on making mypy faster with minimal effort, and at times we cut a few corners.
Reaching 4 million lines
Another important challenge (and the second most popular request in mypy user surveys) was increasing type checking coverage at Dropbox. We tried several approaches to get there: from organic growth, to focused manual efforts of the mypy team, to static and dynamic automated type inference. In the end, it looks like there is no simple winning strategy here, but we were able to reach fast annotation growth in our codebases by combining many approaches.
As a result, our annotated line count in the biggest Python repository (for back-end code) grew to almost 4 million lines of statically typed code in about three years. Mypy now supports various kinds of coverage reports that makes it easy to track our progress. In particular, we report sources of type imprecision, such as using explicit, unchecked Any types in annotations, or importing 3rd party libraries that that don’t have type annotations. As part of our effort to improve type checking precision at Dropbox, we also contributed improved type definitions (a.k.a. stub files) for some popular open-source libraries to the centralized Python typeshed repository.
We implemented (and standardized in subsequent PEPs) new type system features that enable more precise types for certain idiomatic Python patterns. A notable example is TypedDict, which provides types for JSON-like dictionaries that have a fixed set of string keys, each with a distinct value type. We will continue to extend the type system, and improving support for the Python numeric stack is one of the likely next steps.
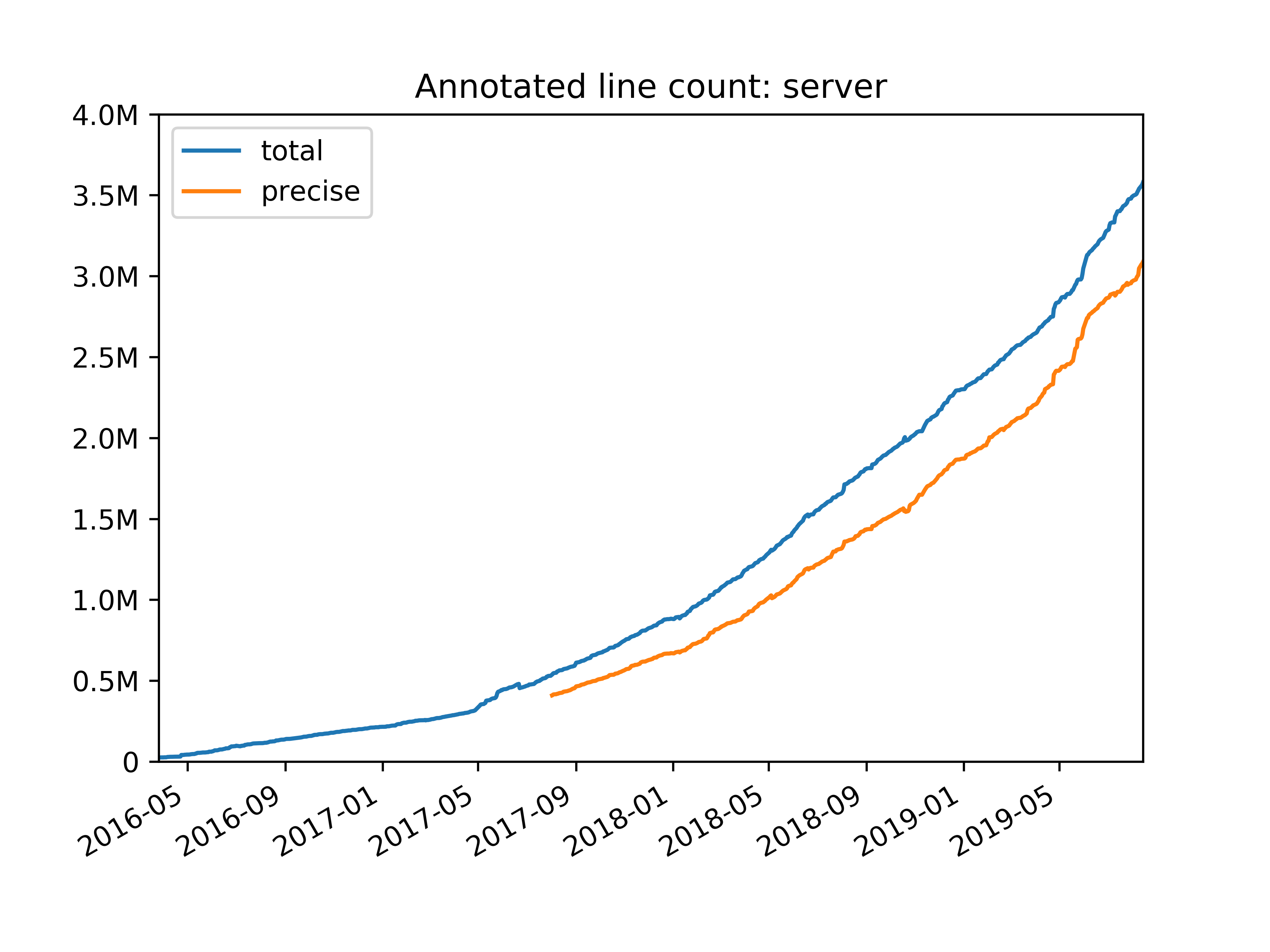
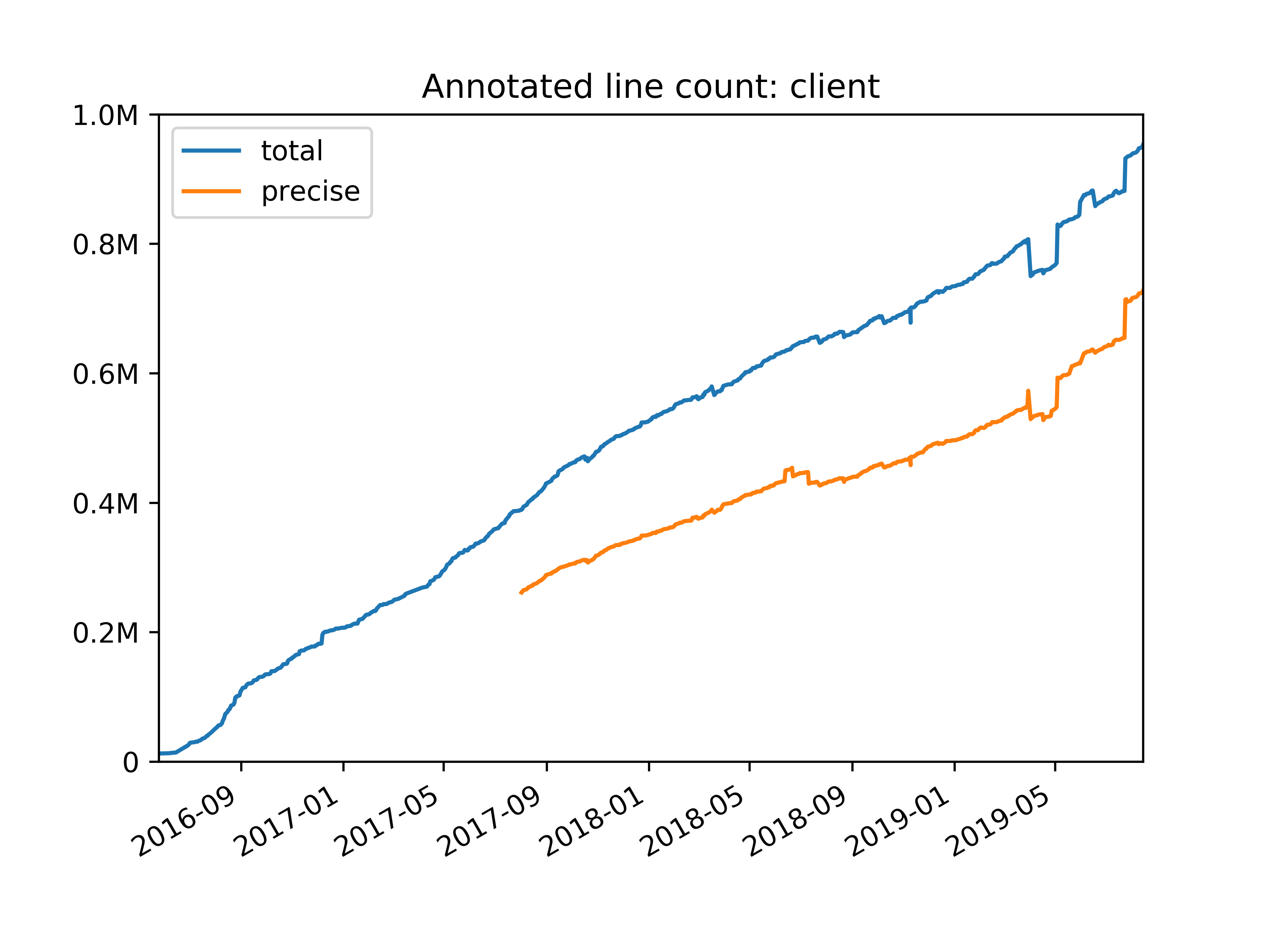
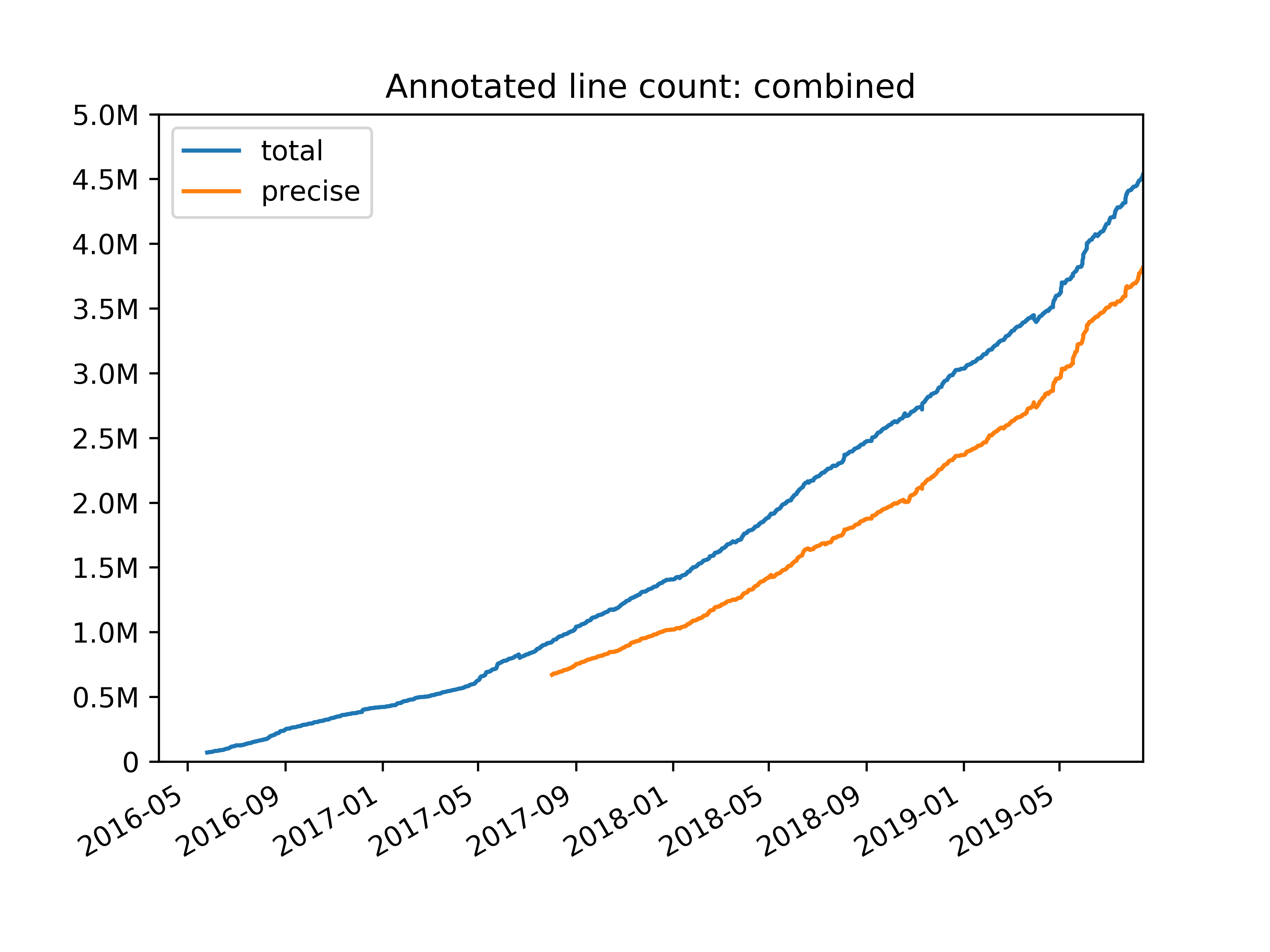
Here are highlights of the things we’ve done to increase annotation coverage at Dropbox:
Strictness. We gradually increased strictness requirements for new code. We started with advice from linters asking to write annotations in files that already had some. We now require type annotations in new Python files and most existing files.
Coverage reporting. We send weekly email reports to teams highlighting their annotation coverage and suggesting the highest-value things to annotate.
Outreach. We gave talks about mypy and chatted with teams to help them get started.
Surveys. We run periodic user surveys to find the top pain points and we go to great lengths to address them (as far as inventing a new language to make mypy faster!).
Performance. We improved mypy performance through mypy daemon and mypyc (p75 got 44x faster!) to reduce friction in annotation workflows and to allow scaling the size of the type checked codebase.
Editor integrations. We provided integrations for running mypy for editors popular at Dropbox, including PyCharm, Vim, and VS Code. These make it much easier to iterate on annotations, which happens a lot when annotating legacy code.
Static analysis. We wrote a tool to infer signatures of functions using static analysis. It can only deal with sufficiently simple cases, but it helped us increase coverage without too much effort.
Third party library support. A lot of our code uses SQLAlchemy, which uses dynamic Python features that PEP 484 types can’t directly model. We made a PEP 561 stub file package and wrote a mypy plugin to better support it (it’s available as open source).
Challenges along the way
Getting to 4M lines wasn’t always easy and we had a few bumps and made some mistakes along the way. Here are some that will hopefully prevent a few others from making the same mistakes.
Missing files. We started with only a small number of files in the mypy build. Everything outside the build was not checked. Files were implicitly added to the build when the first annotations were added. If you imported anything from a module outside the build, you’d get values with the Any type, which are not checked at all. This resulted in a major loss of typing precision, especially early in the migration. This still worked surprisingly well, though it was a typical experience that adding a file to the build exposed issues in other parts of the codebase. In the worst case, two isolated islands of type checked code were being merged, and it turned out that the types weren't compatible between the two islands, necessitating numerous changes to annotations! In retrospect, we should have added basic library modules to the mypy build much earlier to make things smoother.
Annotating legacy code. When we started, we had over 4 million lines of existing Python code. It was clear that annotating all of that would be non-trivial. We implemented a tool called PyAnnotate that can collect types at runtime when running tests and insert type annotations based on these types—but it didn’t see much adoption. Collecting the types was slow, and generated types often required a lot of manual polish. We thought about running it automatically on every test build and/or collecting types from a small fraction of live network requests, but decided against it as either approach is too risky.
In the end, most of the code was manually annotated by code owners. We provide reports of highest-value modules and functions to annotate to streamline the process. A library module that is used in hundreds of places is important to annotate; a legacy service that is being replaced much less so. We are also experimenting with using static analysis to generate type annotations for legacy code.
Import cycles. Previously I mentioned that import cycles (the “tangle”) made it hard to make mypy fast. We also had to work hard to make mypy support all kinds of idioms arising from import cycles. We recently finished a major redesign project that finally fixes most import cycle issues. The issues actually stem from the very early days of Alore, the research language mypy originally targeted. Alore had syntax that made dealing with import cycles easy, and we inherited some limitations from the simple-minded implementation (that was just fine for Alore). Python makes dealing with import cycles not easy, mainly because statements can mean multiple things. An assignment might actually define a type alias, for example, and mypy can’t always detect that until most of an import cycle has been processed. Alore did not have this kind of ambiguity. Early design decisions can cause you pain still many years later!
To 5 million lines and beyond
It has been a long journey from the early prototypes to type checking 4 million lines in production. Along the way we’ve standardized type hinting in Python, and there is now a burgeoning ecosystem around Python type checking, with IDE and editor support for type hints, multiple type checkers with different tradeoffs, and library support.
Even though type checking is already taken for granted at Dropbox, I believe that we are still in early days of Python type checking in the community, and things will continue to grow and get better. If you aren’t using type checking in your large-scale Python project, now is a good time to get started—nobody who has made the jump I’ve talked to has regretted it. It really makes Python a much better language for large projects.
Are you interested in working on Developer Infrastructure at scale? We’re hiring!


