

When was the last time you were about to click a button on a website, only to have the page shift—causing you to click the wrong button instead? Or the last time you rage-quit a page that took too long to load?
These problems are only amplified in applications as rich and interactive as ours. The more front-end code is written to support more complex features, the more bytes are sent to the browser to be parsed and executed, and the worse performance can get.
At Dropbox, we understand how incredibly annoying such experiences can be. Over the past year, our web performance engineering team narrowed some of our performance problems down to an oft-overlooked culprit: the module bundler.
Miller’s Law states that the human brain can only hold so much information at any given time—which is partially why most modern codebases (including ours) are broken up into smaller modules. A module bundler takes the various components of an application—such as JavaScript and CSS—and amalgamates them into bundles, which are then downloaded by the browser when a page is loaded. Most commonly, this takes the form of a minified JavaScript file that contains most of the logic for a web app.
The first iteration of our module bundler was conceived way back in 2014—around the time that performance-first approaches to module bundling were becoming more popular (most notably by Webpack and Rollup in 2012 and 2015, respectively). For this reason, it was quite barebones relative to more modern options; our module bundler didn’t incorporate many performance optimizations and was onerous to work with, hampering our user experience and slowing down development velocity.
As it became clear our existing bundler was showing its age, we decided the best way to optimize performance going forward would be to replace it. That was also the perfect time to do so since we were in the middle of migrating our pages to Edison—our new web serving stack—which presented an opportunity to piggyback on an existing migration plan and also provided an architecture that made it simpler to integrate a modern bundler into our static asset pipeline.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Existing architecture
While our existing bundler was relatively build-time efficient, it resulted in massive bundle sizes and proved to be a burden for engineers to maintain. We relied on engineers to manually define which scripts to bundle with a package, and we simply shipped all packages involved in rendering a page with few optimizations. Over time, the problems with this approach became clear:
Problem #1: Multiple versions of bundled code
Until recently we used a custom web architecture called Dropbox Web Server (DWS). In short, each page consisted of multiple pagelets (i.e. subsections of pages), resulting in multiple JS entry points per page, with each servlet being served by its own controller on the backend. While this sped-up deployment in cases where a page was being worked on by multiple teams, it sometimes resulted in pagelets being on different backend code versions. This required DWS to support delivering separate versions of packaged code on the same page, which could potentially result in consistency issues (e.g. multiple instances of a singleton being loaded on the same page). Our migration to Edison would eliminate this pagelet architecture, giving us the flexibility to adopt a more industry-standard bundling scheme.
Problem #2: Manual code-splitting
Code splitting is the process of splitting a JavaScript bundle into smaller chunks, so that the browser only loads the parts of the codebase that are necessary for the current page. For example, assume a user visits dropbox.com/home, then dropbox.com/recents. Without code-splitting, the entire bundle.js is downloaded, which can significantly slow down the initial navigation to a page.
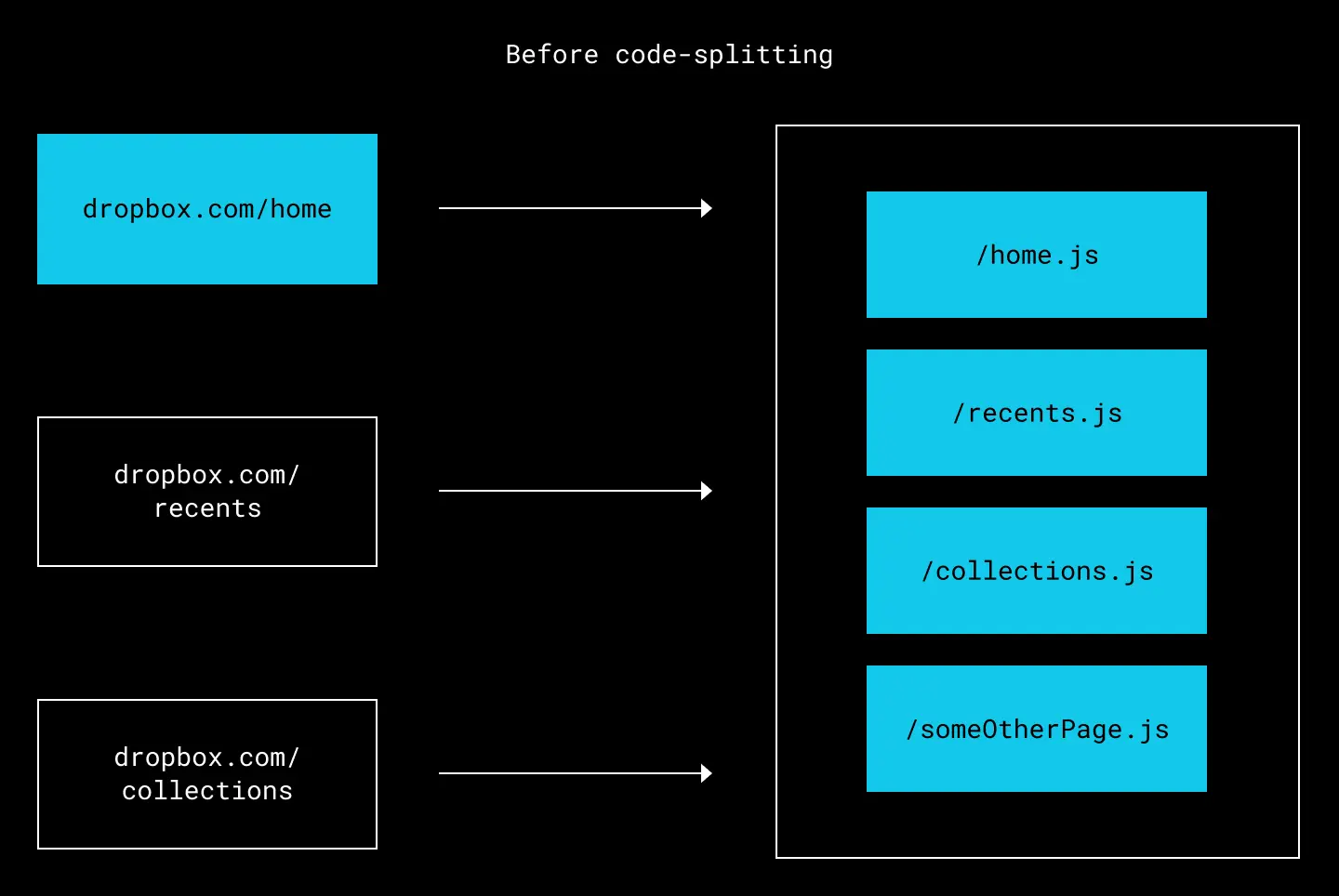
All code for all pages is served via a single file
After code-splitting, however, only the chunks needed by the page are downloaded. This speeds up the initial navigation to dropbox.com/home, since less code is downloaded by the browser—and has several additional benefits too. Critical scripts are loaded first, after which non-critical scripts are loaded, parsed, and executed asynchronously. Shared pieces of code are also cached by the browser, further reducing the amount of JavaScript downloaded when moving between pages. All of the above can greatly reduce the load time of web apps.
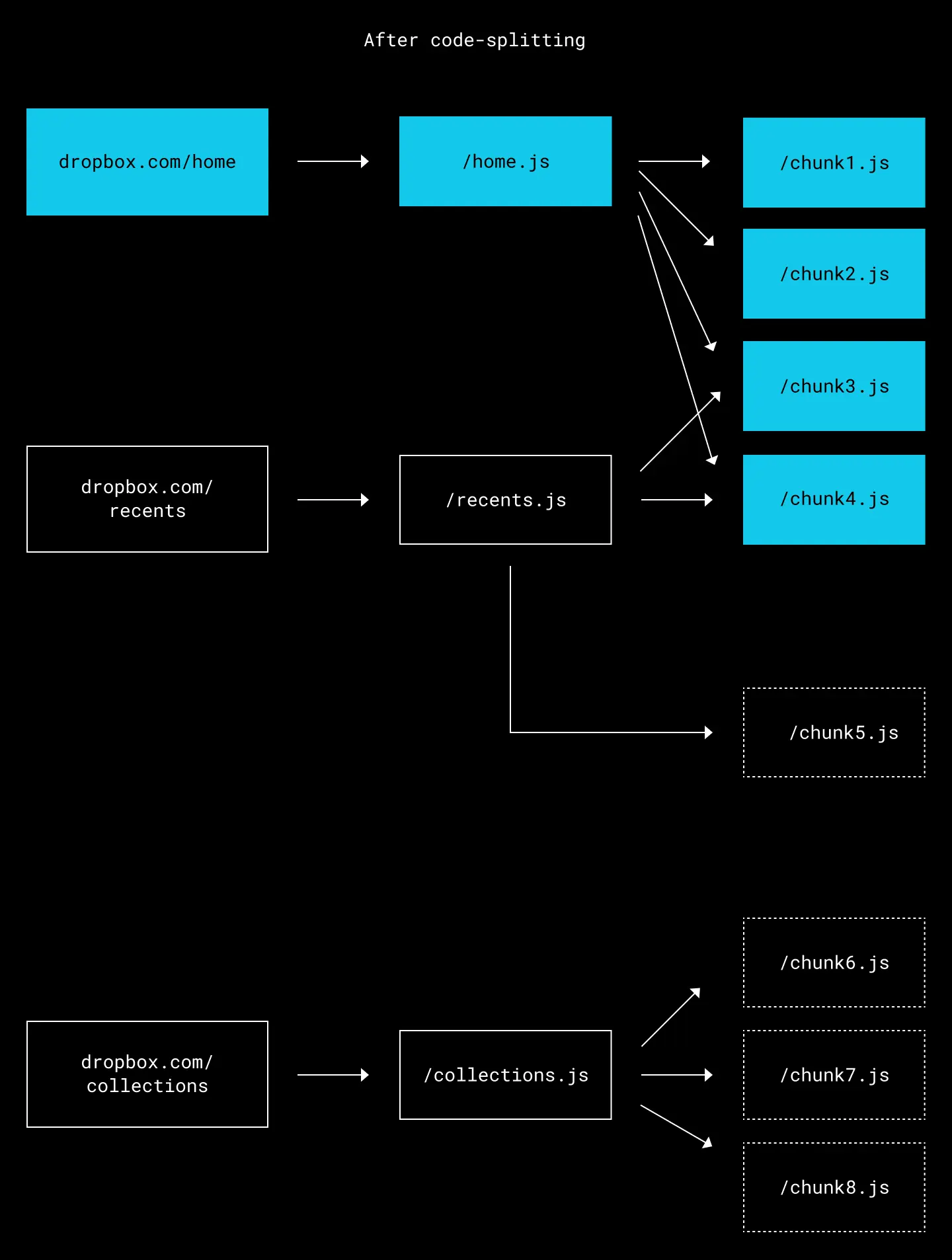
Only the new chunks that are needed for the page are downloaded
Since our existing bundler didn’t have any built-in code-splitting, engineers had to manually define packages. More specifically, our packaging map was a massive 6,000+ line dictionary that specified which modules were included in which package.
As you can imagine, this became incredibly complex to maintain over time. To avoid sub-optimal packaging, we enforced a rigorous set of tests—the packager tests—which became dreaded by engineers since they would often require a manual reshuffling of modules with each change.
This also resulted in a lot more code than what was needed by certain pages. For instance, assume we have the following package map:
{
"pkg-a": ["a", "b"],
"pkg-c": ["c", "d"],
}If a page depends on modules a, b, and c, the browser would only need to make two HTTP calls (i.e. to fetch pkg-a and pkg-b) instead of three separate calls, once per module. While this would reduce the HTTP call overhead, it would often result in having to load unnecessary modules—in this case, module d. Not only were we loading unnecessary code due to a lack of tree shaking, but we were also loading entire modules that weren’t necessary for a page, resulting in an overall slower user experience.
Problem #3: No tree shaking
Tree shaking is a bundle-optimization technique to reduce bundle sizes by eliminating unused code. Let’s assume your app imports a third-party library that contains several modules. Without tree shaking, much of the bundled code is unused.
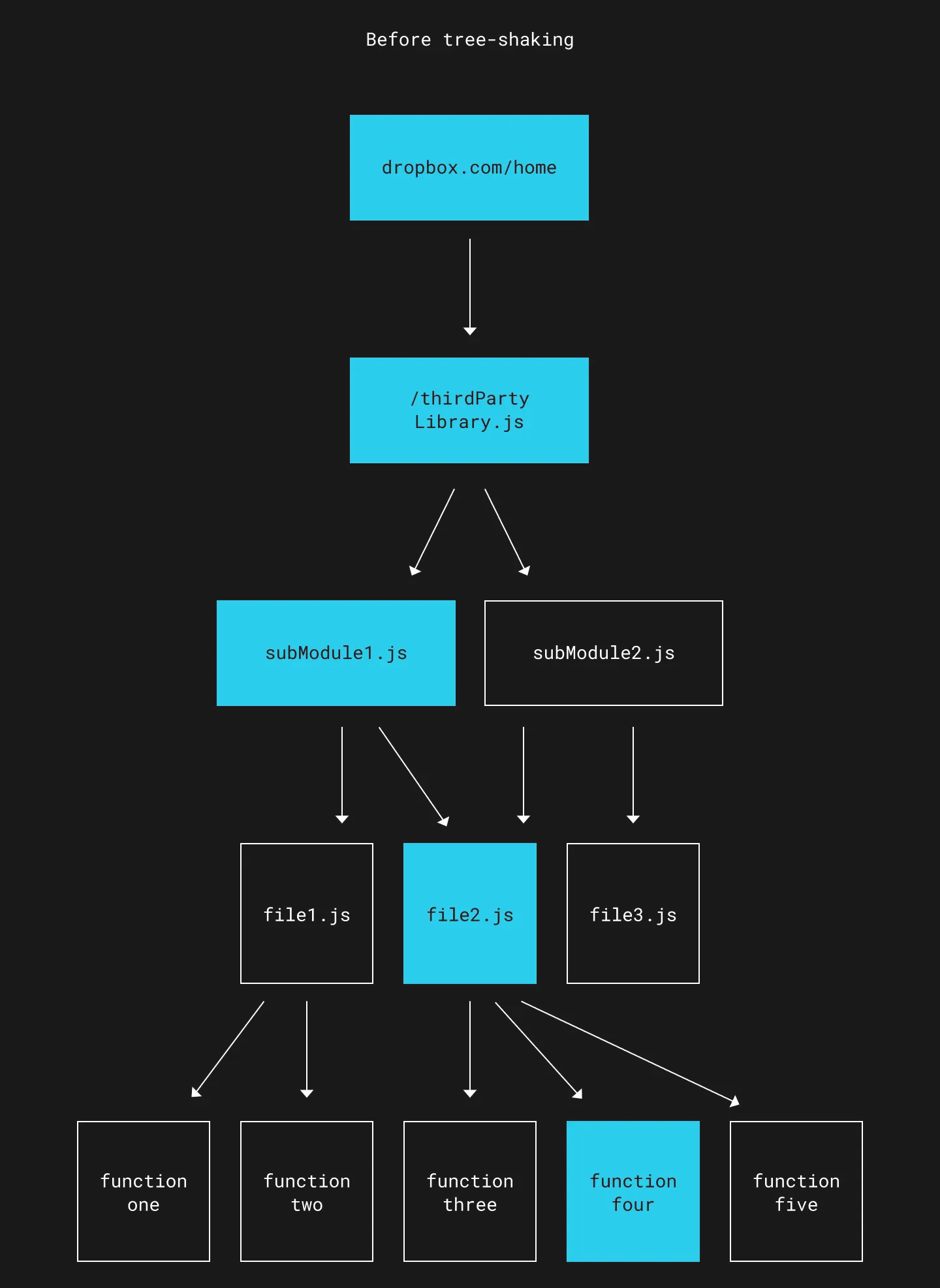
All code is bundled, regardless of whether or not it’s used
With tree shaking, the static structure of the code is analyzed and any code that is not directly referenced by other code is removed. This results in a final bundle that is much leaner.
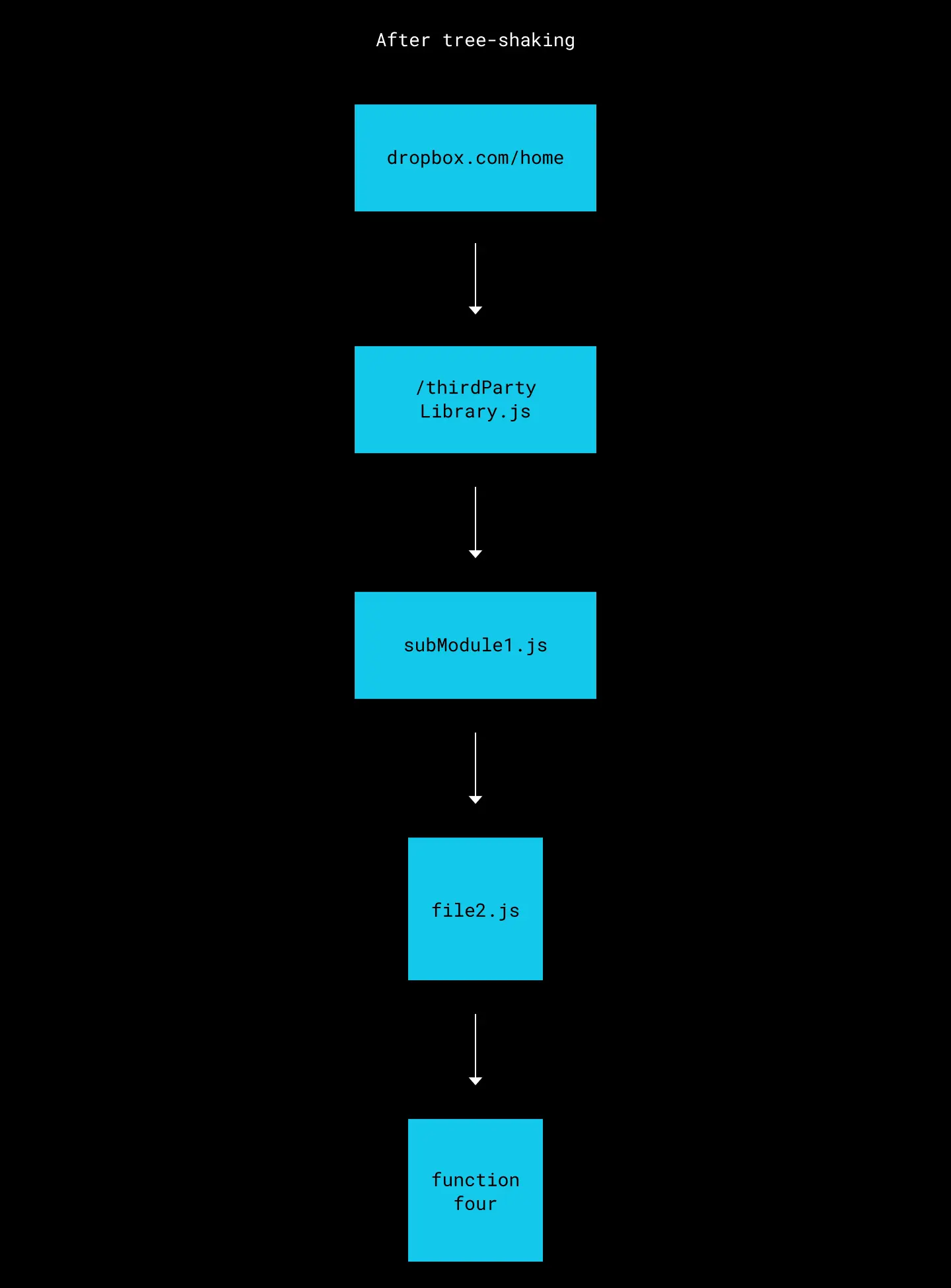
Only used code is bundled
Since our existing bundler was barebones, there wasn’t any tree shaking functionality either. The resulting packages would often contain large swaths of unused code, especially from third-party libraries, which translated to unnecessarily longer wait times for page loads. Also, since we used Protobuf definitions for efficient data transfer from the front-end to the back-end, instrumenting certain observability metrics would often end up introducing several additional megabytes of unused code!
Why Rollup
Although we considered many solutions over the years, we realized that our primary requirement was having certain features like automatic code-splitting, tree shaking, and, optionally, some plugins for further optimizing the bundling pipeline. Rollup was the most mature at the time and most flexible to incorporate into our existing build pipeline, which is mainly why we settled on it.
Another reason: less engineering overhead. Since we were already using Rollup for bundling our NPM modules (albeit without many of its useful features), expanding our adoption of Rollup would require less engineering overhead than integrating an entirely foreign tool in our build process. Additionally, this meant that we had more engineering expertise with Rollup’s quirks in our codebase versus that of other bundlers, reducing the the likelihood of so-called unknown unknowns. Also, replicating Rollup’s features within our existing module bundler would require significantly more engineering time than if we just integrated Rollup more deeply in our build process.
Rollup rollout
We knew that rolling out a module bundler safely and gradually would be no easy feat, especially since we’d need to reliably support two module bundlers (and consequently, two different sets of generated bundles) at the same time. Our primary concerns included ensuring stable and bug-free bundled code, the increased load on our build systems and CI, and how we would incentivize teams to opt-in to using Rollup bundles for the pages they owned.
With reliability and scalability in mind, we divided the rollout process to four stages:
- The developer preview stage allowed engineers to opt-in to Rollup bundles in their dev environment. This allowed us to effectively crowdsource QA testing by having developers surface any unexpected application behavior introduced by Rollup bundles early on, giving us plenty of time to address bugs and scope changes.
- The Dropboxer preview stage involved serving Rollup bundles to all internal Dropbox employees, which allowed us to gather early performance data and further gather feedback on any application behavioral changes.
- The general availability stage involved gradually rolling out to all Dropbox users, both internal and external. This only happened once our Rollup packaging was thoroughly tested and deemed stable enough for users.
- The maintenance stage involved addressing any tech debt left over in the project and iterating on our use of Rollup to further optimize performance and the developer experience. We realized that projects of such a massive scale will inevitably end up accumulating some tech debt, and we should proactively plan to address it at some stage instead of sweeping it under the rug.
To support each of these stages, we used a mix of cookie-based gating and our in-house feature-gating system. Historically, most rollouts at Dropbox are exclusively done using our in-house feature gating system; however, we decided to allow cookie-based gating to quickly toggle between Rollup and legacy packages, which sped up debugging. Nested within each of these rollout stages were gradual rollouts, which involved ramping up from 1%, 10%, 25%, 50%, to 100%. This gave us the flexibility to collect early performance and stability results—and to seamlessly roll-back any breaking changes if they occurred—while minimizing impact to both internal and external users.
Because of the large number of pages we had to migrate, we not only needed a strategy to switch pages over to Rollup safely, but also to incentivize page owners to switch in the first place. Since our web stack was about to undergo a major renovation with Edison, we realized that piggybacking on Edison’s rollout could solve both our problems. If Rollup was an Edison-only feature, developer teams would have greater incentive to migrate to both Rollup and Edison, and we could tightly couple our migration strategy with Edison’s too.
Edison was also expected to have its own performance and development velocity improvements. We figured that coupling Edison and Rollup together would have a transformational synergy strongly felt throughout the company.
Challenges and roadblocks
While we did expect to run into some unexpected challenges, we realized that daisy-chaining one build system (Rollup) with another (our existing Bazel-based infrastructure) proved to be more challenging than anticipated.
Firstly, running two different module bundlers at the same time proved to be more resource-intensive than we estimated. Rollup’s tree-shaking algorithm, while quite mature, still had to load all modules into memory and generate the abstract syntax trees needed to analyze relationships and shake code out. Also, our integration of Rollup into Bazel limited us in being able to cache intermediary build results, requiring our CI to rebuild and re-minify all Rollup chunks on each build. This caused our CI builds to time-out due to memory exhaustion, and delayed the rollout significantly.
We also found several bugs with Rollup’s tree-shaking algorithm which resulted in overly aggressive tree shaking. Thankfully, this only resulted in minor bugs that were caught and fixed during the developer preview phase without ever impacting our users. Additionally, we found that our legacy bundler was serving some code from third-party libraries that was incompatible with JavaScript’s strict mode. Serving this same code via the new bundler with strict mode enabled resulted in fail-hard runtime errors in the browser. This required us to conduct a one-time audit of our entire codebase and patch code that was incompatible with strict mode.
Finally, during the Dropboxer preview phase, we found that our A/B telemetry metrics between Rollup and the legacy bundler weren’t showing as much of a TTVC improvement as we expected. We eventually narrowed this down to Rollup producing a lot more chunks than what our legacy packager produced. Although we initially hypothesized that HTTP2’s multiplexing would negate any performance degradations from a greater number of chunks, we found that too many chunks would result in the browser spending significantly more time in discovering all the modules needed for the page. Increasing the number of chunks also resulted in lower compression efficiency, since compression algorithms such as Zlib use a sliding-window approach to compression, which results in greater compression efficiency for one large file vs. many smaller files.
Results
After rolling out Rollup to all Dropbox users, we found that this project reduced our JavaScript bundle sizes by 33%, our total JavaScript script count by 15%, and yielded modest TTVC improvements. We also significantly improved front end development velocity through automatic code-splitting, which eliminated the need for developers to manually shuffle around bundle definitions with each change. Lastly and perhaps most importantly, we brought our bundling infrastructure into modernity and slashed years of tech debt accumulated since 2014, reducing our maintenance burden going forward.
In addition to having a highly impactful rollout, the Rollup project revealed several bottlenecks in our existing architecture—for example, several render-blocking RPCs, excessive function calls to third-party libraries, and inefficiencies in how the browser loads our module dependency graph. Given Rollup’s rich plugin ecosystem, addressing such bottlenecks has never been easier in our codebase.
Overall, adopting Rollup fully as our module bundler has not only resulted in immediate performance and productivity gains, but will also unlock significant performance improvements down the road.
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


