

How Dropbox re-wrote its core web serving stack for the next decade—sunsetting technical debt accrued over 13 years, and migrating high-traffic surfaces to a future-proofed platform ready for the company’s multi-product evolution.
~ ~ ~
In the Fall of 2021, Dropbox quietly launched an internal alpha version of our core web-based file browser. This internal alpha marked a critical milestone in Dropbox web architecture: our file browser was now a Single Page Application, or SPA.
On its own, this wouldn’t have been very remarkable. SPAs have been around in concept for almost two decades, and have been widely used on the web for at least half that time. In fact, to most people managing a website, SPA functionality is table stakes and barely worth writing a blog post about. That would have been true for us too if the web property wasn’t Dropbox.com—a very large surface spanning hundreds of back end services with deep and multi-layered feature sets owned by dozens of teams. We weren’t just launching a SPA, but a whole new platform to enable it. This platform would not only have to work correctly and outperform the existing stack, but—critically—do so without requiring a tough rewrite for teams who wanted to migrate.
Anyone who has worked with a system as large as ours—with all its attendant tech debt—knows that rewriting even limited segments can be a challenging endeavor. Our debut of the SPA architecture represented a complete rebuild of web foundations at Dropbox—an entirely new web framework, stack, and platform called Edison.
Developed over the last three years, Edison gives us the keys to unlock a host of performance and functional improvements. It enables sub-second developer iteration cycles and isomorphic rendering—meaning JavaScript that runs on both the client and server—and unlocks the unification of our web surface into a dynamic SPA. It is a full rewrite of our core web systems that sunsets some 13 years of technical debt. We built Edison to be our web serving stack for the next decade—a flexible platform fit for our highest-traffic surfaces and future products and features alike.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
What is the web to Dropbox?
“Things can change so fast on the internet” — Tim Berners-Lee
Dropbox launched its website in 2008, almost two decades after the web was invented. At launch, Dropbox was still just a desktop app, and the website a delivery mechanism and marketing surface. For much of the early years, the real action was in the app which ran on your computer and quietly kept your digital life in sync. Our engineering talent specialized in infrastructure—syncing, networking, chunking, and storage—rather than the web.
Over time, Dropbox built a web platform piece by piece, moving from a brochure site to an account manager and file viewer—and finally, to today’s platform, where we can provide advanced features like PDF editing and video collaboration. Many more users are able to benefit from these advanced features thanks to the reach and ubiquity of the web.
Today, the web is central to all Dropbox products—from enabling new file-based workflows to organizing cloud-only data—and increasingly where the battle for user utility will be fought. It’s critical to our future that we have a web platform which gives our product engineers the most reach and speed that it possibly can. As we move to meet the challenges of the future, Edison is just one example of how seriously Dropbox now takes the web, and the shifting internal and external culture around it.
The history of Dropbox on the web
Like any surface with a storied history, our web code has undergone a number of significant iterations over the years. Back in 2012, our web architecture was based on Pyxl, a Python-with-inline-HTML engine—familiar ground to folks who grew up writing PHP! We built much of our client front end in CoffeeScript, until that turned into a dead-end and pushed us to migrate to TypeScript. We used and then deprecated jQuery. We adopted React.
In short: much of our trajectory echoes the evolution of the web ecosystem itself over the last decade-and-a-half, and should be familiar to many who built web properties during that time.
More interesting is how the integration between our back end and front end evolved. In broad strokes, we moved in step with the wider web ecosystem—adopting open source technologies, server rendering, and interactive front ends. But over time we also built out custom infrastructure to solve our own set of business challenges. A critical piece of this was our custom webserver, and the optimizations built into it.
This (legacy) webserver is called DWS. (If you’re wondering what that acronym stands for, please take a guess; congratulations, you’re right!) DWS served us well for most of a decade, and allowed us to successfully iterate on our website during that time. But, inevitably, two things happened next: the web continued to evolve, and we wanted to demand more of DWS than it was designed to do.
As we moved to expand the capabilities of our web products, the limitations of DWS presented somewhat intractable issues for both our application feature set and developer productivity. There were two main classes of problems we were up against.
Problem 1: Pagelets
DWS was designed so that feature teams could iterate independently on the web. For example, one team might want to work on navigation while another worked on the sidebar. In particular, those teams would want to iterate and release without continuous cross-team coordination. DWS enabled this. DWS not only allowed engineers to develop independently, but also enabled their code to execute independently on both the back and front end. These properties ensured that one feature team could not hold up or slow down another.
To meet these requirements DWS settled on a pagelet architecture.
For those unfamiliar with the term, a pagelet is a subsection of a page, such as the navigation bar or the footer. In our case, one pagelet encompasses both the back end (data fetching, controller) as well as the front end (view) code.
Each pagelet has a controller in Python which retrieves the back end data it needs, specifies page metadata, and provides a JavaScript (JS) entry point with initialization data. Pagelets execute in parallel and stream the data they retrieve into the browser response, keeping the HTTP connection open for as long as needed until the streaming is complete. Under DWS, a collection of pagelets is defined as a route.
In the browser, each pagelet’s entry point module is executed as an individual React app, which initializes as soon as ready and renders into a specific HTML slot in the page’s appshell (the basic HTML which initializes the page and provides root elements to hold incoming content). As each pagelet completes, the page is assembled into its complete form.
Upsides to this architecture:
- Complex, multi-featured pages could be vertically sliced into manageable parts.
- There was clear separation and ownership of product code.
- Each team’s product could be rendered independent of other pagelets.
- It made early data retrieval possible. DWS issued parallel back end requests which streamed into the HTML, so that by the time the JS began executing, the data fetches it needed were already complete.1
Downsides to this architecture:
- Data fetch instructions were defined in the Python controller, but fetched data was consumed in the JS layer in the browser. These layers needed to be kept in sync manually, which was an obvious source of bugs. This also meant that it was hard to statically verify that a piece of data was actually still in use, making it easy to over-fetch data or forget to eliminate a data fetch as the front end changed.
- Writing functionality that crossed pagelet boundaries was nontrivial.
The difficulty of crossing pagelet boundaries was an especially serious limitation. It meant we couldn’t evolve our site into anything which you’d define as a holistic application, let alone a SPA. If you wanted your pagelet’s JS code to interact with another pagelet’s JS code, you’d need to meet with the owning team and agree to design a mutual JS messaging API (yikes!). This closed off a whole world of possibilities and feature sets.
Problem 2: Commingled layers
Any engineer who has designed a distributed system knows a few principles to building robust, composable, flexible interfaces. Separation of concerns. Loose coupling. The basic problem we faced as we tried to stretch our wings on the web was predictable: because DWS had evolved from a system of HTML-in-Python, it still retained a lot of hard-to-shift coupling between the server and the JS client.
What this meant was that if an engineer developing a feature for the web wanted to run their code—which might only be a few lines of JS and CSS—they also needed to run the whole webserver stack. The system wasn’t designed to be modular, and the JS application layer had many direct and indirect dependencies on server-rendered data. Executing JS without the webserver was rarely feasible, and even if some segments were, it wasn’t possible to build a universal way to do it.
Running a webserver is easy if you only have a handful of routes, and maybe a few thousand lines of code. Many projects will use webpack-dev-server and start their site up in, say, 10-20 seconds. However, our scale made this approach prohibitive. At Dropbox, it meant running ~100 back end services, all of which needed to be compiled and started up in the virtualized server environment we call devbox. This could take 20 minutes—and sometimes took twice that! An experienced front end engineer who joined the company might see their workflow change from “I can load the dev site on my laptop in 20 seconds” to “I need a provisioned dedicated remote server and 20-30 minutes.” Again, yikes!
We needed to get to a place where engineers could run their JS code quickly and easily—a place that didn’t require expensive builds of the back end and round-trips to a remote box. After all, it’s one thing to be able to run a single module without the webserver; there are systems that allow you to test some subset of your functionality (for example, Storybook). But these were patches on our problem, not full solutions. It’s no good if engineers need to work out how to run their code every time they need to test something. We needed a general solution.
Introducing Edison
Finding an an answer to our challenges with web client development at Dropbox wasn’t straightforward. Our first incremental rewrite began in 2016, before I joined Dropbox, and before the initial release of Next.js—the open-source project which Edison is frequently compared to. We had several false starts and backward steps as we iterated on incremental versus foundational changes.
In retrospect, the key functional requirements we had to nail with Edison were:
- The browser runtime is a single, unified JS application.
- The JS client can execute without the server.
The key non-functional requirements were:
- An easy migration. Rewriting all our code for a new system was a non-starter. Any particular team rewriting their code was a non-starter. We had nearly two million lines of TypeScript code, and around 100,000 lines of back end code handling pagelets. This was partly a technical problem, but also a political one, since expensive rewrites would have the potential to heavily delay or even render a new system DOA.
- Equal or better performance. The existing system had clear optimization lines that we had to match. We had to ensure that parallel products couldn’t impact each other, and that data fetches happened well in advance of the JS initialization. Again, this was both a technical and a political problem, because although limited performance regressions could hypothetically be the right technical outcome in some scenarios, they’d cause political pushback from impacted teams.
By 2020, we had a clear sense of the necessary outcome: a serverless client architecture, re-imagined from the ground-up, alongside a server which could do Node-based rendering. In other words, we needed an isomorphic JS application stack tightly integrated with our existing services and code architecture.
Structure
Edison consists of three major parts:
- Edison Server
- written in Go
- accepts direct web traffic via our Envoy proxy layer
- delegates server-side rendering (SSR2) to Streaming Reactserver
- performs data fetches via Courier, our gRPC framework
- handles ahead-of-time fetching and communicates with Edison Client in the browser
- Streaming Reactserver
- Go-wrapped Node service3 tasked specifically with performing React tree renders
- able to pass messages back to Edison Server asynchronously during render
- Edison Client, our browser-based runtime
- main browser entry point
- interfaces with Edison Server to fulfill ahead-of-time data fetch guarantees
- handles data exchange directly with Courier services for late fetches
- implements a single React app for the whole page
Running serverless is a key part of Edison’s design. In principle, you could build Edison Client and our product code and have them served from a static CDN. There’s no reason for us to do that in production, but it’s an enabling feature (we’ll come back to this later).
But if we can run serverless, why have a server component at all? Edison Server is a critical part of our stack. It complements the client by acting as a runtime accelerator, and is responsible for meeting the performance targets set by DWS. Let’s dive into how that’s accomplished.
Application acceleration with Edison
Earlier I discussed pagelets and the optimizations we’ve gained by processing their data requirements in parallel, early in the request lifecycle. This is one of the key optimizations the server needs to perform. But how does it provide the speed boost?
Suppose we’re looking at a file preview, which is a sub-function of our file-browsing application. We want to bring up a page which has a file listing and an overlaid preview of a PDF. Here’s how a simplified version of that might look:
- The server naively responds to the initial request for /browse with the JS application entry point bundle for that page.
- Once it loads, the browse app requests the data for the user.
- Once it has that data, the browse app determines that it needs the preview JS app to proceed.
- Once that data loads, the page can complete rendering and the user can see the content.
Here’s that process represented on a timeline:
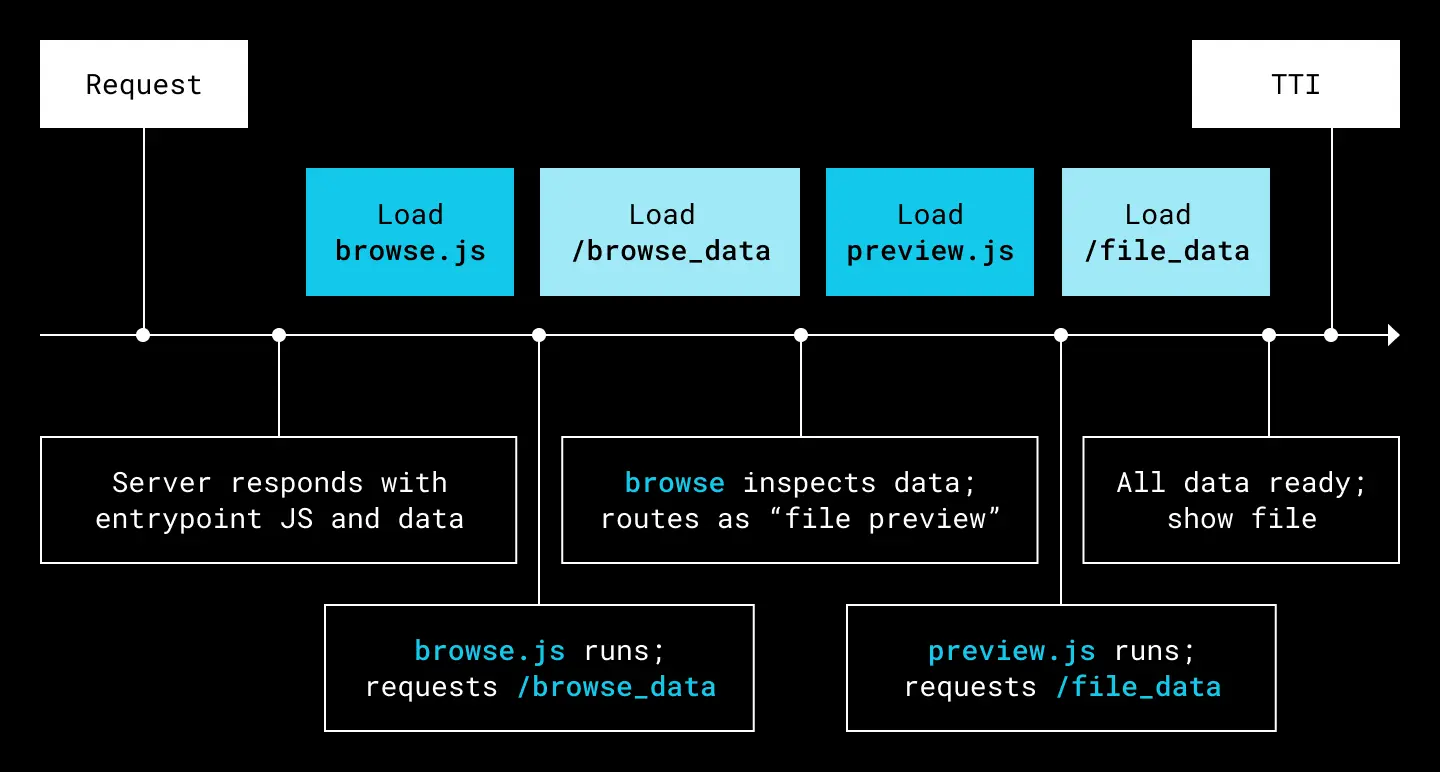
An example of a naive cascade for a pure-client JS application
When chains of requirements execute linearly like this, they can rapidly add up to unacceptable delays in serving an experience to a user. This cascade is also greatly simplified; an actual production application can have hundreds of modules which may interact in many different ways.
This is where server acceleration shines. Since Edison Server can pre-analyze the whole application tree, it can anticipate many of these requests:
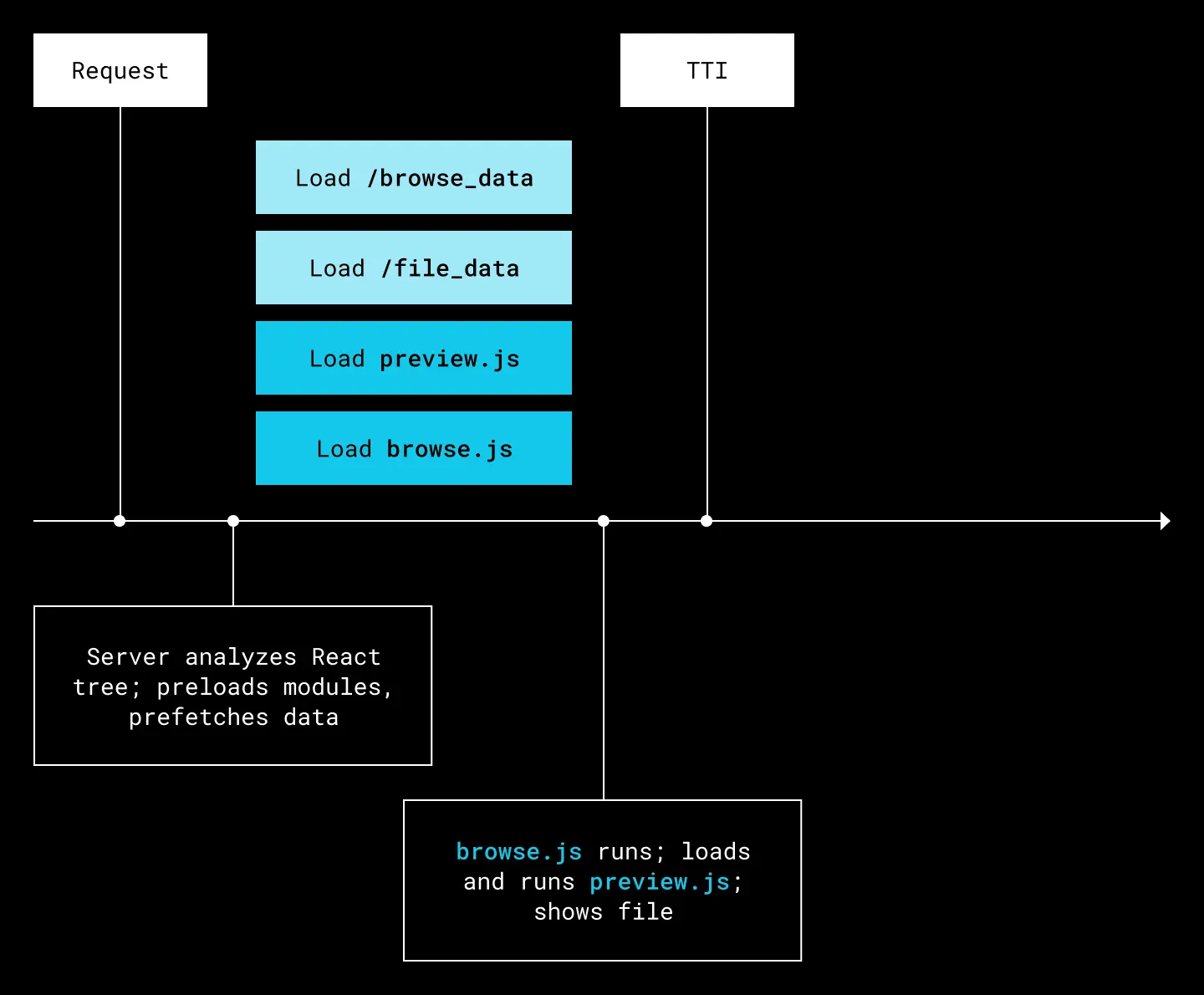
The same sequence, with modules and data preloaded
This kind of acceleration via application analysis is possible because of the cross-service communication between Edison Server and Streaming Reactserver during the server-side render of the React tree. When a request comes in, the following sequence results:
- Edison resolves the route to a JS entry point module, packages up all the data required to render that entry point, and sends it to Streaming Reactserver.
- Streaming Reactserver then begins a server-side render4. During the render, the code path encounters data fetch calls (specifically, calls to Edison.prefetch).
- As those calls are encountered, Streaming Reactserver sends an asynchronous message to Edison Server, which immediately kicks off the data fetch while the React render continues.
- When that data fetch completes, Edison Server can stream the results into the response HTML, regardless of whether the React render is complete or not, so that the data needed is ready before the application requires it.
This is how we unlock the same performance wins as Edison’s predecessor DWS. Even better, we end up with an architecture where data fetch requests are co-located with the code that needs them, and all the application logic now lives in a single layer of the system.
Migrating to Edison
Prior to Edison, we undertook a phased set of steps to gradually migrate the web page APIs away from Python and Pyxl towards JS. This provided manageable steps for stakeholders, allowing them to upgrade incrementally with benefits along the way.
Edison was meant to be a seamless extension of that trend. By launch, teams that were up to date on our old stack had the following:
- a Python pagelet executor to handle data loads and provide initialization data
- a set of JS application code to accept that data and render the product
Migrating to Edison meant teams had only to make manageable adjustments:
- a data servicer (could be Python, Go, or any other Dropbox-supported language) to handle data loads and provide initialization data back over gRPC
- a set of JS application code which implemented Edison.prefetch to call out to the servicer
In most cases, this work amounted to a refactor of a single Python file, repackaged with the Servicer API instead of the Pagelet API, and a new JS entry point module to wrap the JS logic and make the prefetches. Critically, this was a change that teams could undertake:
- incrementally, with the Edison version gated to internal traffic only
- without code duplication, since both back end and front end core code could be shared
- with strong expectations that feature parity would be available to them out of the gate
Asking teams to handle multiple incremental refactors took time and capital, but was critical. By the time Edison was ready for launch, the migration effort for major web services had been dramatically reduced. These refactors got us to a place where even major pages could be run simultaneously on DWS and Edison with the same JS code, making gradual rollouts easy to achieve.
Solved problems
To summarize:
- Edison successfully broke up our commingled application layers by moving all the product code into the TypeScript layer.
- We preserved our ability to do acceleration with early data fetches by relying on asynchronous gRPC calls initiated during the server-side React render.
- We collapsed two sources of truth for data fetches into one, making maintenance easier and the code more readable for product engineers.
- We retained the ability for separate product modules—what we previously called pagelets in DWS—to own their back end data providers, and to execute their JS code as soon as those providers returned the initialization data they needed.
- Application engineers could now trivially write functionality which crossed the old pagelet boundaries, since the application is now a single, coherent React tree.
- Routes that had been refactored into pure React could run simultaneously on DWS and Edison, and migrated incrementally for safety.
What’s left?
The last piece is developer productivity. Remember that, with DWS, engineers needed to run the whole stack (100+ services) to execute any JS. At this stage in Edison’s rollout, that was still the case. So let’s talk about what Edison enabled us to do next, and how we’re solving the next set of problems while building for the future.
Building on Edison
Shifting engineers to an Edison-based surface let us do two things. First, we could immediately work on a single, coherent React tree—bringing us back to the start of this journey, where I talked about moving the first parts of the Dropbox.com web surface to a SPA architecture. Second, splitting the layers between client and server properly now meant the client no longer needed to be served from the webserver. This allowed us to streamline much of our developers’ workflow.
The rapid rise of the SPA
Single Page Applications aren’t an immediate panacea or necessarily a final endpoint of our architecture. For many sites—especially mostly-static sites—a thinner client could solve the same pain points. But for a site like ours, where actions such as file uploads, moves, and manipulation are center to its functionality, Dropbox on the web needs to function, in essence, as a full, graphical file manager. Being able to decouple user actions and page state from navigation around the surface is essential.
Some specific examples of how a SPA architecture benefits our web surface are:
- It enables intuitive navigation around the file tree, allowing us to do something like drag a file into the sidebar. Those were entirely separate React apps before!
- We can provide visual transitions between surfaces which used to be entirely separate, such as folder navigations. These give users a better sense of what’s changing and reduce cognitive overhead.
- We can deliver better performance by powering page navigations with a single API call, instead of a full page load with all its attendant costs.
As this part of our product continues to mature, I am sure the SPA will be a topic worthy of its own story. Rather than dig deeper on it now, let’s talk about client-server splitting and our developer productivity enhancement, which we call Edison Localmode.
Edison Localmode
Since the client no longer needs the webserver to function, we now have the ability to do things like:
- bundle our sources and deploy to a CDN, eliminating infrastructure
- deploy an app to Electron—a unified, cross-platform code pipeline
- serve the whole web client from our engineers’ laptops, enabling rapid iteration
All of these are awesome abilities—but for the purposes of this post, it‘s the third we care about the most, since it solves our problem with developer productivity!
The basic goal of Edison Localmode is simple: web client developers should not need to run anything but the web client. We should be able to decouple them from the webserver. In the new Edison world, engineers who are creating and iterating on JS and CSS code should no longer need to repeatedly touch the webserver—or any back end services for that matter. They should be working on a pure client codebase which utilizes APIs to interface with the remainder of the Dropbox world.
Edison Localmode fulfills this promise. Edison Localmode is an opt-in system which enables serving of all static assets (JS and CSS) directly from an engineer’s development laptop. An engineer loads a page as normal (from a Dropbox webserver, whether that be a dev server they’ve spun up, or our staging environment), boots a lightweight local Node-based asset server, and opts into Localmode. From then until they opt out, all static assets will be served from their local laptop.
The engineer is then free of the need to touch the server. As they continue to iterate, the lightweight local server will watch the filesystem and re-transpile5 code on the fly, patching it directly into the running page so that modifications are applied instantly to the working surface.
Let’s recap, because it’s deceptively easy to state, but quite transformative.
Before:
- An engineer modifies and saves a source file.
- They manually issue a command to reload devbox, which syncs changed files, rebuilds, and restarts services.
- Once complete (15-30 seconds), the engineer switches back to the browser and hits refresh.
- If their code runs deep in a flow—like the third stage of an interactive form—the engineer needs to manually reconstruct that state each and every time they refresh.
- Once the page is reloaded, the engineer checks to see if their code is working correctly.
- Repeat as needed to complete the feature.
After:
- An engineer modifies and saves a source file.
- The code is transpiled and running in the page, with all states intact and requiring no manual intervention, before they’ve even had the time to switch back to the browser.
For an engineer who might have previously reloaded their devbox every few minutes, the raw time savings can add up considerably. If you’re reloading your code every 15 minutes, and looking at the conservative side of devbox reload speeds, you’re potentially saving one minute every hour. At six hours a day, that scales up to around four working days per year you’re no longer wasting.
Less quantifiably, whenever an engineer is delayed for 30 seconds, they will inevitably try to check messages on Slack while they wait, get bumped out of flow, and lose more time. Having instant feedback allows engineers to remain in flow more continuously, and increase the speed of their changes.
These are big wins for developer productivity and overall satisfaction. Front end development on devbox was a notoriously frustrating experience; with the release of Edison Localmode, work that used to be a chore can now return to its natural state of being satisfying and quick!
The future
Edison is the culmination of many things for Dropbox.
As the web gained prominence, our workforce diversified; we grew from mostly back end engineers to include a strong cohort of full-stack web engineers. Edison would have never been possible without this culture shift.
Developing Edison also led to a better understanding of the constraints of our own systems. DWS made many implicit assumptions that Edison illuminated, allowing them to be better understood and isolated. Getting to this point required incremental adjustments to our APIs and any code that used them. This increased our understanding of what future alignment of our systems with open source should look like, and what it would take to get there. Alignment with open-source is something we continue to work towards, and is a de facto good; it reduces our reliance on bespoke tools and can further increase developer productivity.
In the meantime, Edison is a huge accelerator for our product development. Tasks and features which would have been inaccessible or lengthy projects under DWS are now easy, and development work which was riven with interruptions and delays has become smooth and continuous. Edison lets us think much more freely about what our web products ought to be and envision a Dropbox.com closer to the cutting edge.
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.
~ ~ ~
Footnotes
- The early, parallelized, data fetching functionality in DWS was a critical performance optimization for Dropbox, and it arrived well before JS server-side rendering was an option for us. At that time a naïve architecture might need front end code to handle its own data fetching, which would add hundreds of milliseconds of delay into the time-to-interactive window. Pagelets had their problems, but parallelizing early data loads and having a client runtime which could manage the data was definitely not one of them.
- Server-side rendering means a system where the server provides a full HTML rendering of the page’s content as part of the initial response. This allows the browser to render the page before the JS application loads and executes (a performance benefit); it also makes it easier for bots and SEO crawlers to understand the page, since they don’t need to execute a large JS application just to read the text. Our file-manipulation application doesn’t do this, because the use case offers limited benefits (the pages are not accessible except to the authenticated user, and the HTML is of limited use without the JS interactivity). Other parts of Dropbox Web, like CMS-based public pages and Dropbox Paper, use SSR.
- Edison Server and its wrapping layer around Node are written in Go. Go makes the jobs Edison Server needs to do easy. It has good support for concurrency, making our highly parallelized processes intuitive to reason about; it’s highly performant; and it is tightly integrated into the Dropbox service ecosystem.
- Streaming Reactserver’s back end renders can be used as an acceleration mechanism or to provide server-rendered HTML. We don’t always use server HTML, but it’s important for some specific pages—especially those which depend on good search engine visibility.
- Transpilation is the process of getting source code (written in TypeScript and CSS Modules) into a form which we send to the browser. It’s a series of transformations to the code which previously needed to happen on an engineer’s devbox; now, it can happen locally, too.


