

In this post, we introduce Alki, a new cost efficient petabyte-scale metadata store designed for storing cold, or infrequently accessed, metadata. We’ll discuss the motivations behind building it, its architecture, and various aspects of how we were able to rapidly prototype and then productionize the system with a small team.
Metadata Storage at Dropbox
At Dropbox, we store most of our product metadata in an in-house one-size-fits-all database called Edgestore. Over time, however, small misalignments in values between Edgestore and the various product use cases it powers became increasingly problematic. Its architectural limitations around data sharding and capacity expansion made storing certain types of metadata at scale infeasible.
Edgestore is built on top of MySQL with data stored on SSDs. In order to scale, data is distributed among a fixed set of MySQL databases, referred to as shards. An Edgestore cluster serves a subset of those shards and is comprised of a primary host and a number of secondary replica hosts.
Capacity expansion in Edgestore works by increasing the number of database clusters and redistributing the shards.
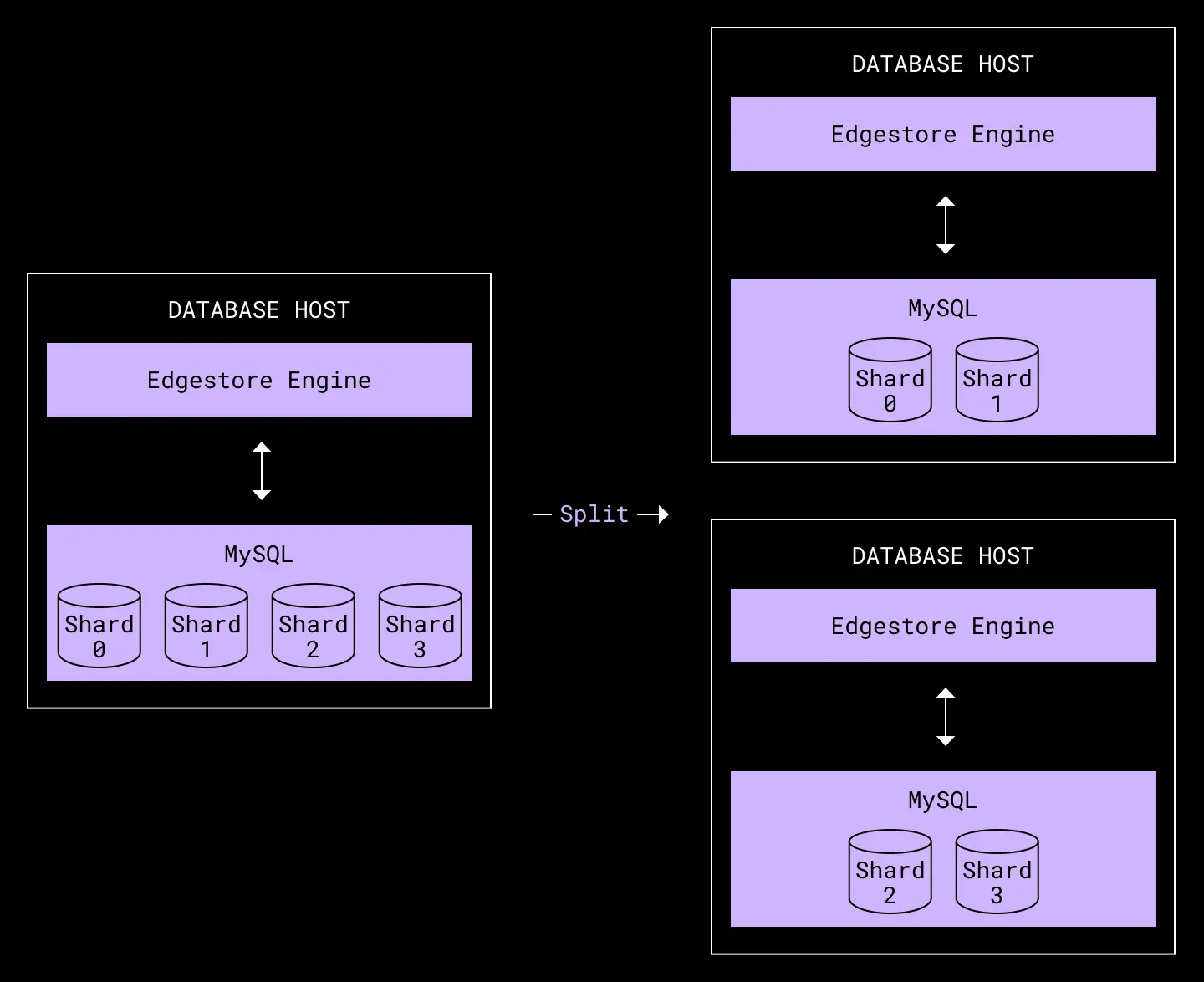
Capacity expansion in Edgestore via splits
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Assuming data is relatively evenly distributed among the hosts, when one cluster hits 80% disk space and needs to be split, most other clusters will also need to be split. This means that capacity expansion most often occurs by splitting the entire fleet, doubling the physical cost of Edgestore each time.
Capacity Crunch
Around fall of 2017, we split Edgestore from 256 clusters with 8 shards per cluster to 512 clusters with 4 shards per cluster. This increased Edgestore’s physical footprint from around 1500 database hosts to more than 3000 database hosts after accounting for local and geo-diverse replicas.
From our capacity projections at the time, we predicted the need to split yet again in under just 2 years. Increasing usage of Edgestore from various products, coupled with the growth of Dropbox itself, was causing the rate of splits to increase.
This was logistically problematic from a couple of perspectives. First, the financial cost for the exponentially larger and larger splits is a non-trivial amount of money to earmark. Second, buying and setting up so many machines at once is an all-hands-on-deck project for our hardware, datacenter, networking, and database teams and is hard to scale.
Architecturally, Edgestore would also only be able to perform 2 more splits, after which we would reach 1 shard per cluster with no more splits available. Our levers for capacity expansion were quickly closing and we were heading into a capacity crunch.
Options
We began to build a replacement metadata storage engine, called Panda, underneath Edgestore that would support incremental capacity expansion, allowing us to add just a handful of clusters at a time and dynamically move subsets of data to the new clusters, but we knew this would be a multi-engineer-year project to build, validate, and migrate.
In the meantime, we wanted to avoid the next round of splits, giving us roughly 2 years to solve Edgestore’s capacity crunch. We investigated and explored a number of options.
Among them was an option to optimize Edgestore’s existing data model, shaving off some bytes here and there on schema overhead. Perhaps we could variable-length encode some pieces of metadata, or remove others primarily used for debugging and etc. Many ideas like this were explored by the team, but we determined for most of the ideas that the risks would be too high and the maintainability of the system would be harmed in the long-run in return for not much capacity reduction.
Our database team also looked into switching the storage engine we use with MySQL 5.6 from InnoDB to Facebook’s MyRocks storage engine built on RocksDB, which has better compression. We also looked into trying to upgrade MySQL to 5.7 to enable usage of hole punching. One other option that was explored was running MySQL atop zfs for better compression as well. But testing and safely rolling out MySQL, kernel, and filesystem changes across a large fleet would be hard to validate safely. With plenty of unknowns, we didn’t want this to become a blocker.
Ultimately, the path we took became apparent when we started to closely examine the data stored in Edgestore.
Audit logs
We noticed that the largest dataset stored in Edgestore, was from audit logs for our customers. These logs power several features that give Dropbox Business account administrators visibility into how their Dropbox data is being used and shared. As an example, admins can search for events via the insights dashboards, subscribe to events via streams using the get_events API, or generate activity reports.
These log events are written and retained for many years, but outside of recently ingested events that are more frequently read randomly via the dashboard and get_events API, old events are rarely read and if read are usually done so in large batches of sequential objects. We refer to this as being hot, or frequently accessed, and cold, or infrequently accessed.
Edgestore, optimized for low latency and high throughput reads of single objects, was a poor fit for this use case due to those largely cold traffic patterns. This was reflected in the high cost of storage from the underlying SSDs whose performance benefits were mostly un-reaped. Moreover, audit logs had been hitting write throughput limitations with Edgestore due to large teams generating proportionally large volumes of events that created too much write contention against MySQL.
As such, we decided to work together with the team managing audit logs to look for a better solution to the audit log storage problem.
Challenge
The challenge when we set out to build Alki was to design, implement, and productionize a new optimized system with limited engineering resources in a short timeline. Beyond that, we wanted the system to be generic, benefiting many use cases besides audit logs, as well as to help reduce overall metadata storage costs at Dropbox.
Among the few off-the-shelf options we explored, we looked at running HBase or Cassandra on in-house machines equipped with spinning disks. Given a longer timeline or a larger team, it may have been possible to fit our use case onto these systems as is, but we ultimately ruled these out as we didn’t think we could gain the expertise and build the tooling to operate these at scale with high durability in the required amount of time.
One problem we ran into with many systems optimized for efficient storage of cold data was that they were unsuitable for high volumes of random reads and writes. While audit logs are eventually cold, they are ingested at high volume and frequently read randomly in the period right after ingestion which made those systems a poor fit for our use case.
Given this dichotomy, we decided to build a two-tier system with separate layers for hot storage and cold storage. Data when written would be stored in hot storage, allowing for efficient random writes and reads. Eventually the data would be transitioned to cold storage, allowing for low-cost storage and efficient sequential reads at the expense of random read performance.
Alki
This approach gave us the flexibility to combine systems optimized for opposing goals rather than trying to find a single system good at both. We based the structure of this new system on log-structured merge-tree (LSM tree) storage systems.
LSM tree
This type of storage system is fairly popular and its concepts are used in many modern day storage systems like Cassandra, HBase, and BigTable.
Writes
In a non-distributed LSM tree database implementation, when a write request comes in, the new record is inserted into an in-memory sorted table. Implementation of this memory table varies, for example, it could be represented as a red-black binary search tree to allow for inserts and searches in logarithmic time.
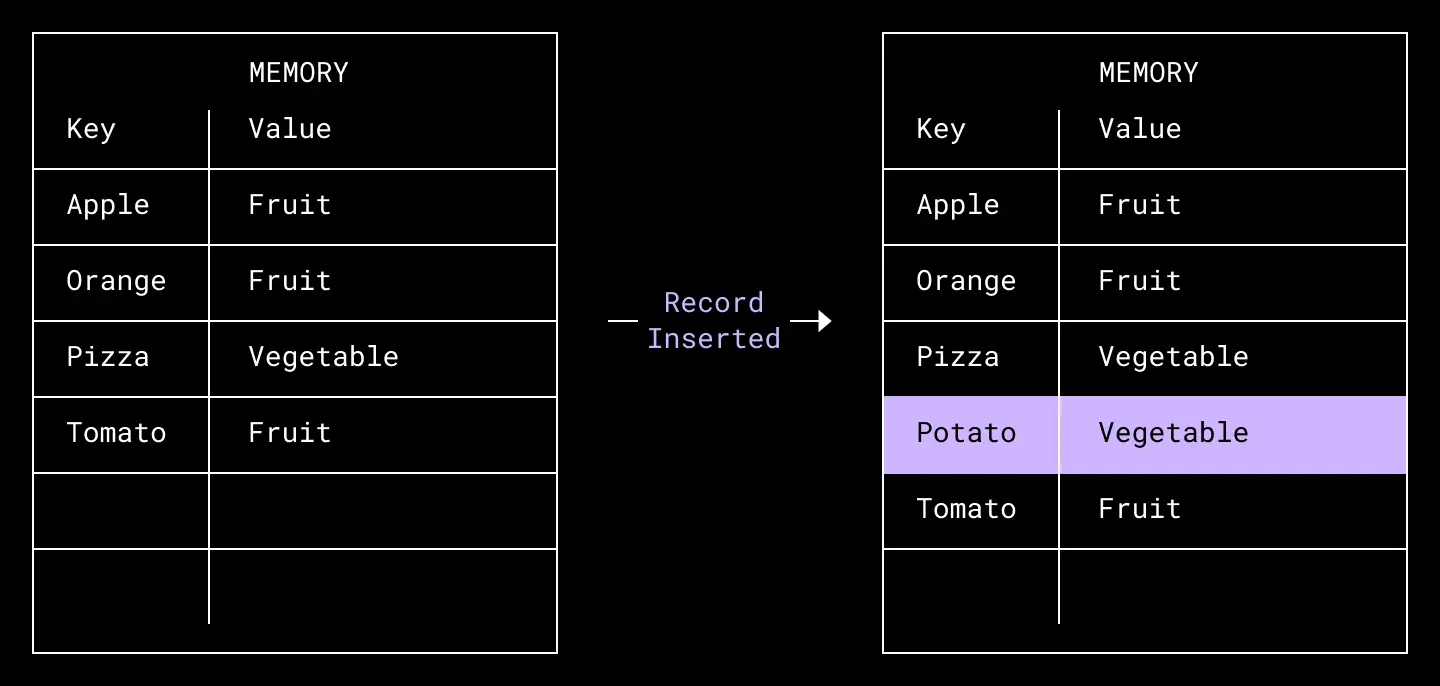
A key-value record [potato: vegetable] is inserted to our memory table in key order.
However, memory is volatile and has smaller capacity relative to other storage mediums. It would not be scalable to store all data in in-memory tables.
Offloads
To limit the amount of data we keep in memory, we occasionally flush, or offload, the set of records out to disk, in a file, as a sorted list, or run, of records. For simplicity, we will refer to the data in the in-memory table as part of the in-memory run.
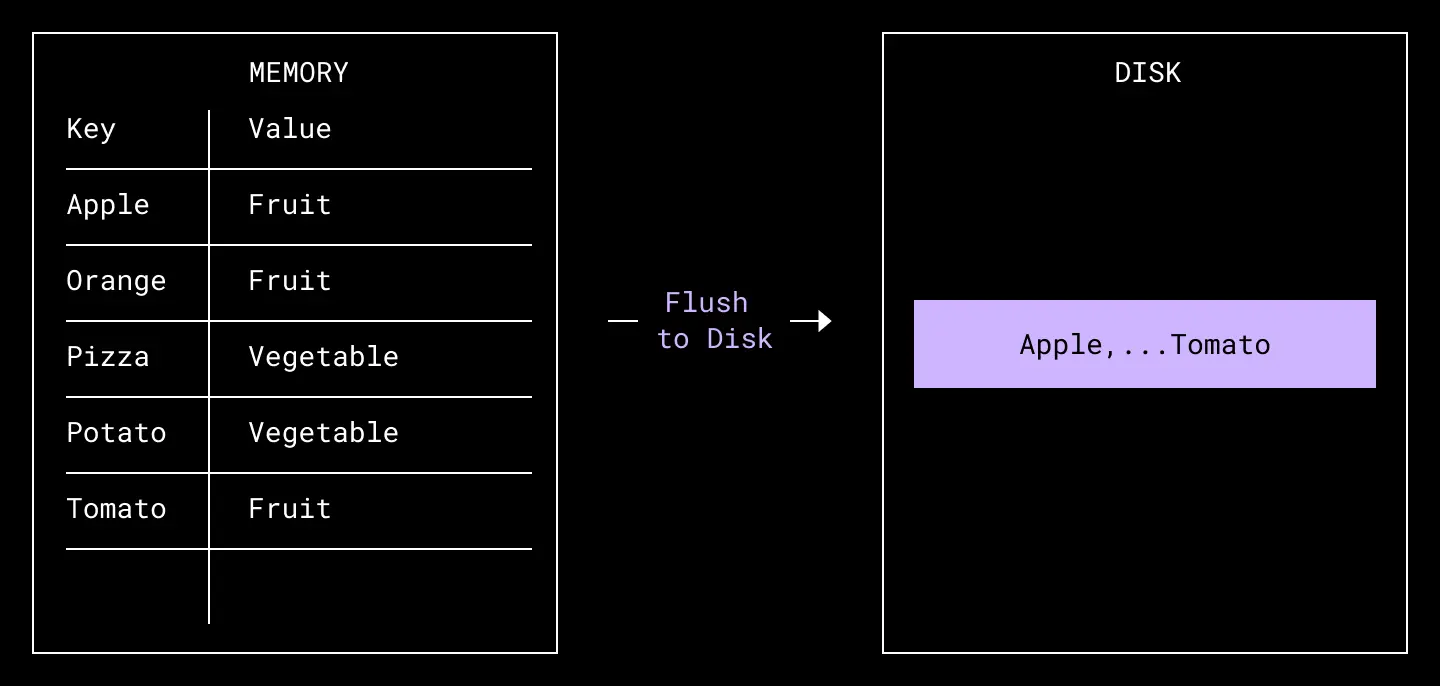
A run of in-memory records are flushed out to a file on disk, containing the same records in the same sort order.
Reads
This complicates the reads because records could be located in either the in-memory table or in any of the on-disk runs. Therefore we need to search in the in-memory table and in all on-disk runs and merge the results for each read request.
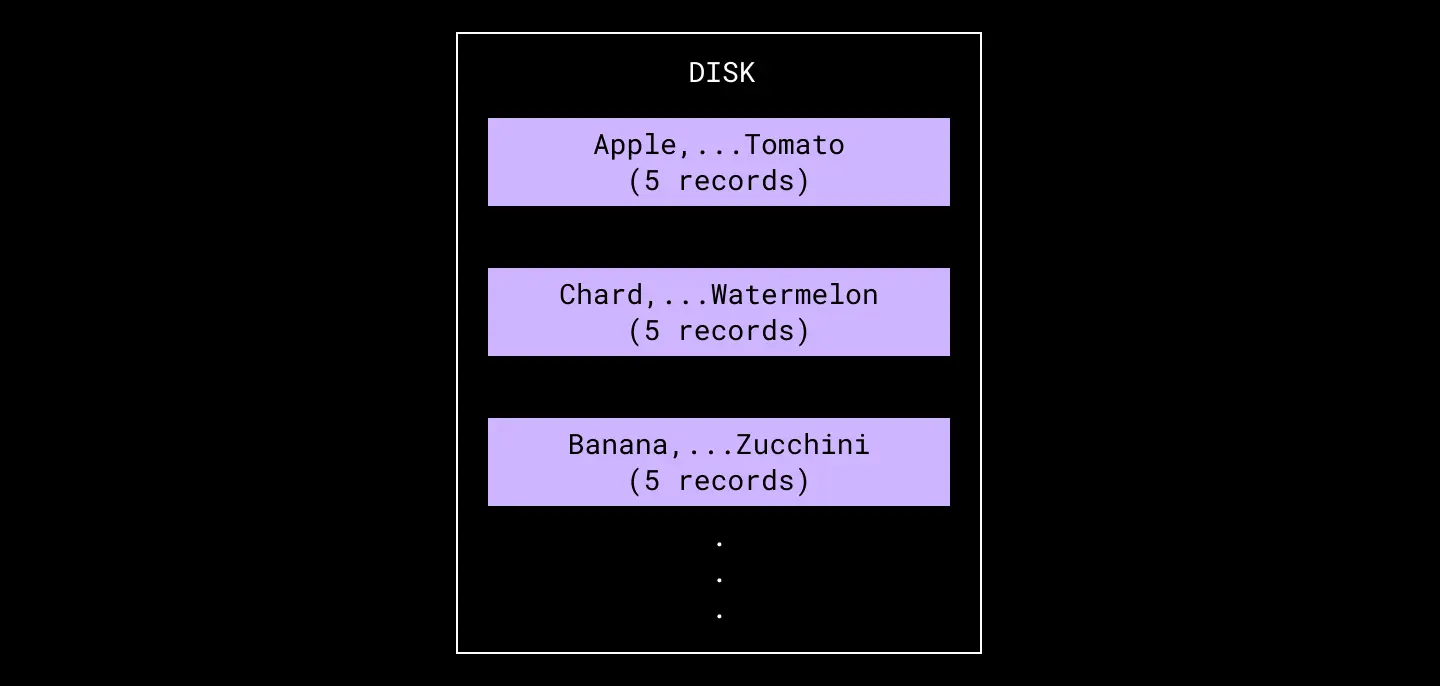
An example set of on-disk runs, representing data from multiple in-memory offloads.
As an example, in order to find the key Blackberry with the above set of on-disk runs, we would need to search for that key in the runs for <Apple,...Tomato> and <Banana,...Zucchini> and merge the results. We do not need to check the <Chard,...Watermelon> run because we know the key falls outside of the run’s range of keys.
If the key appears in no on-disk runs nor in the in-memory table, we know the record does not exist. If it appears in multiple places, we may choose to discard all of the old references in favor of the newest entry when merging results, depending on implementation.
Efficient lookups of a key in any single run, in-memory or on-disk, can be easily implemented because data in each run is sorted by key. On the other hand, as the number of runs increase, the number of runs to read from for each read request also increase. This is problematic over time due to the periodic flushing of the in-memory run. This negatively impacts read performance and throughput and wastes disk resources on the read amplification.
Compaction
In order to limit this read amplification, we periodically compact/merge sets of small sorted runs on disk to larger sorted runs. Since runs are all sorted, this compaction process can be done fairly efficiently, similar to the merge phase of a merge sort.
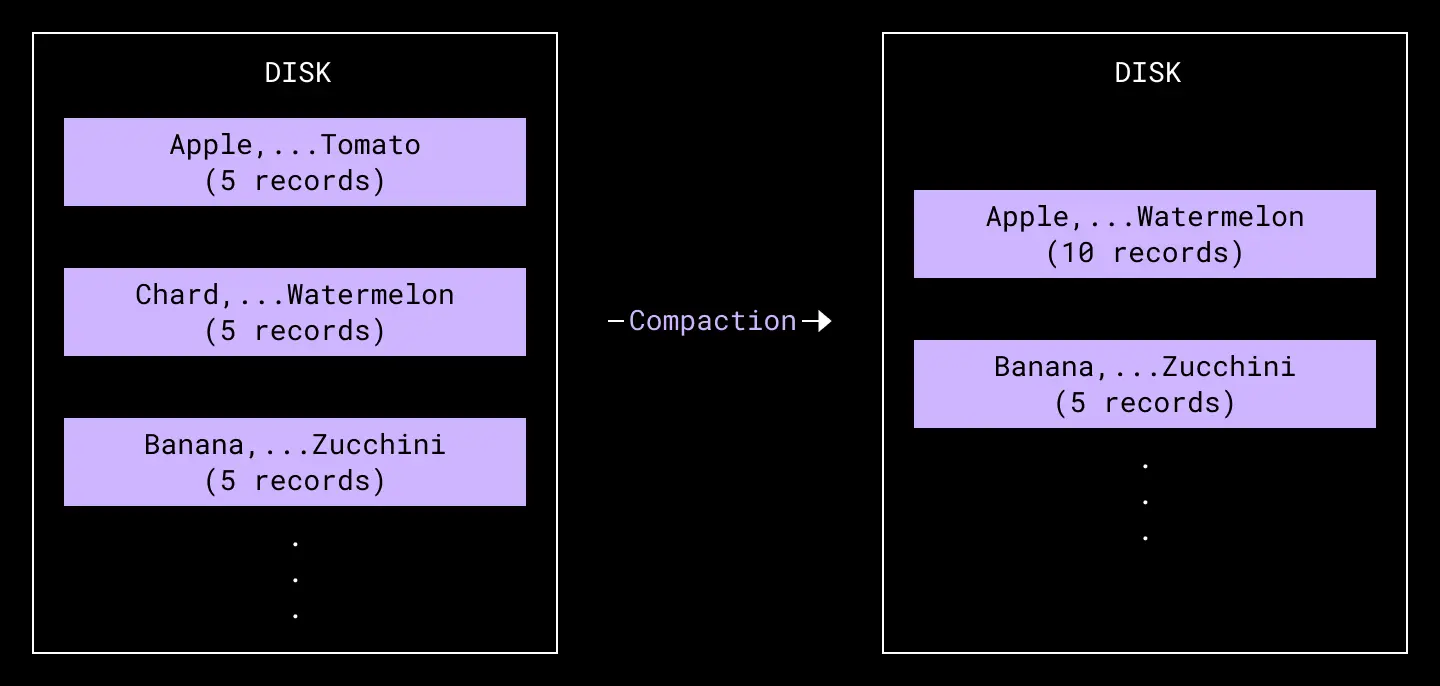
The [Apple, . . . Tomato] run and [Chard, . . . Watermelon] run are merged into the [Apple, . . . Watermelon] run.
One way to perform this periodic compaction process would be to constantly compact every new on-disk run into a single global on-disk run. This approach would correlate the total number of on-disk runs at any point in time to the speed at which we could merge new runs into the global run relative to how often we flush runs from memory to disk. In practice, this approach would be quite inefficient as this would effectively cause compaction to have to re-write the entire global run each time, wasting disk resources on the write amplification.
If we instead pick a compaction scheme that logarithmically compacts sets of runs, e.g. every 2 small runs into 1 medium run, every 2 medium runs into 1 large run, and etc., we can logarithmically bound the number of runs we would need to ever read from for any read request.
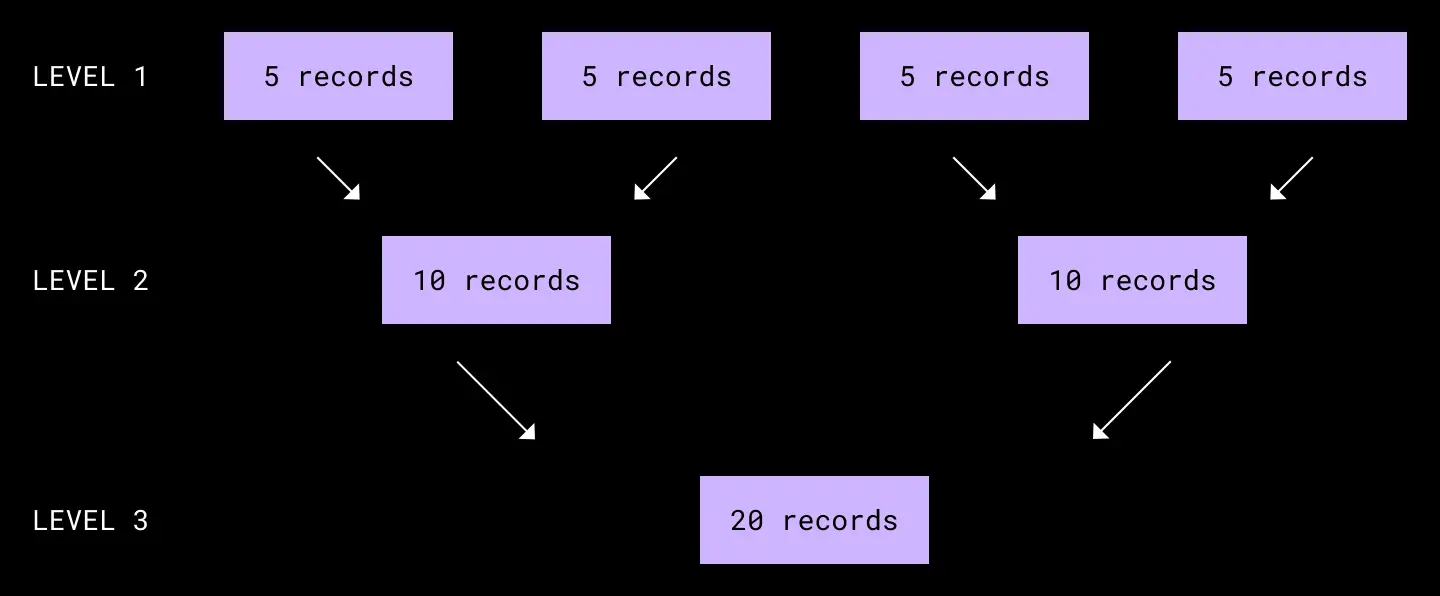
Logarithmic compaction results in O(logN) runs with O(logN) compactions.
This approach attempts to balance the write amplification of compacting too often with the read amplification of needing to read from too many runs.
Alki’s Architecture
The key trick of LSM trees is using multiple storage tiers to play to the strengths of different storage technologies. Specifically, you have a “hot” tier that's really good at high-throughput, fast, random access (which tends to make it correspondingly more expensive) and a “cold” tier where storage is really cheap, but where I/O throughput is lower and where reading/writing 10MB of data is about as expensive as 1KB (favoring infrequent access and big sequential access when you do any I/O at all). In non-distributed LSM trees, RAM makes a good “hot” tier, and disk a good “cold” tier.
For Alki, we found a couple of existing cloud storage technologies with a similar cost/performance tradeoff relationship to RAM/disk, and we used the same tricks used by LSM trees to play to each layer’s strengths while presenting a unified read/write API. We use a distributed key-value store, Amazon DynamoDB, as the hot store, and a distributed blob store, Amazon S3, as the cold store. We also use AWS Step Functions and an in-house batch processing system called Blackbird to orchestrate the control plane and run the offline ETL jobs.
By building Alki on top of powerful building blocks that exposed well-defined APIs and feature sets, we did not have to spend valuable time and resources to tackle and re-solve many of the hard distributed database problems.
Daily Lifecycle
At the beginning of each day, we dynamically create a table in the key-value store, representing a run of data in which to ingest writes. At the end of the day, this hot run is sealed and the data is offloaded to the cold store as a sorted cold run. Once offloaded, the table for the hot run is deleted. Periodically, we compact the cold runs in the cold store, merging them in order to reduce the total number of runs. Once compacted, the source cold runs are deleted.
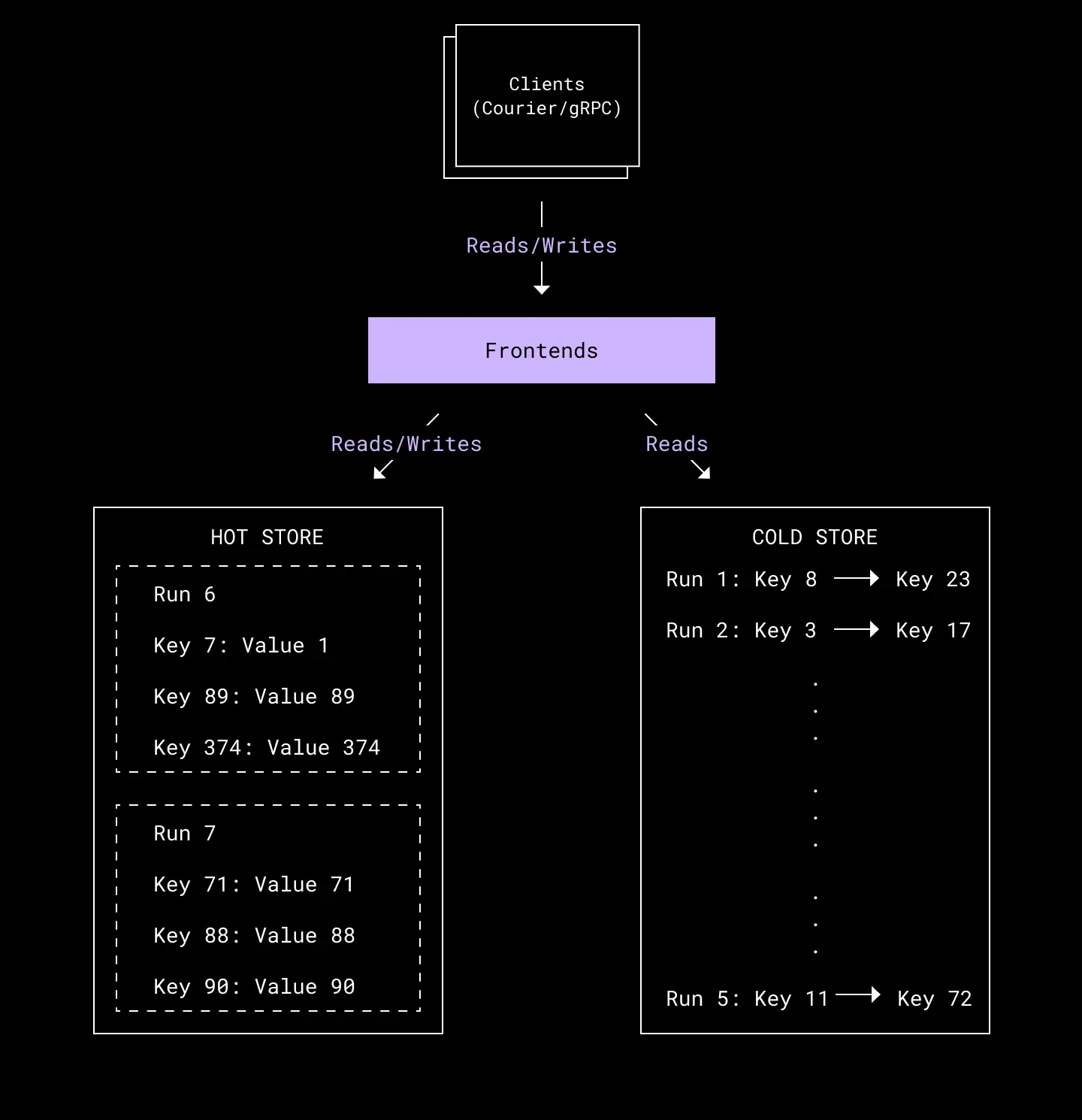
Alki's architecture
Cold Store Format
In some LSM-tree based stores, offloaded data is stored using a variant of a special indexed file format that provides a mapping from keys to data pointers, pointing to the actual data stored elsewhere in the file. A similar implementation over a blob store might require multiple blob reads per lookup and markedly worse latencies, so we instead store this index as an internal metadata table in the key-value hot store.
The indexing metadata itself could be very large depending on the ratio of the size of the keys versus the size of the values. In order to reduce the storage costs of storing this in the key-value store, we batch many records into a single S3 blob and only store a sparse mapping of 1 key for every blob, corresponding to the key of the first value in the blob. The blob that potentially contains any given key is found by searching for the last entry in the ordered index table with a first key smaller than or equal to the given key. Using a sparse index further optimizes for storage cost at the expense of potentially needing to read blobs that do not contain the key at all.
AWS Services
We chose to build Alki on top of AWS services for a few reasons.
The main one is the relatively low maintenance cost of using fully managed systems which allowed us to rapidly prototype and build Alki. AWS gave us a great deal of access to their support engineers, who taught us many tips and tricks (and idiomatic usage patterns) to get the most out of the AWS services we were building on top of.
DynamoDB and S3 are also horizontally scalable both in storage and throughput which allowed us to handle the scale of our audit logs and more from day one. This came in handy during the migration as we were able to easily scale up the systems to handle more than 100x steady state traffic and it continues to provide us benefits as we onboard other large use cases.
However, the specific hot and cold stores are implementation details of Alki, and any of the backend systems could be easily swapped out, allowing us to take advantage of unique properties of other storage systems.
Data Plane vs Control Plane
Another benefit of using these managed systems as building blocks is that it allows the entire data plane on our end to be stateless, merely translating incoming requests into reads and writes against the underlying hot and cold store. This greatly reduces our maintenance cost to operate Alki.
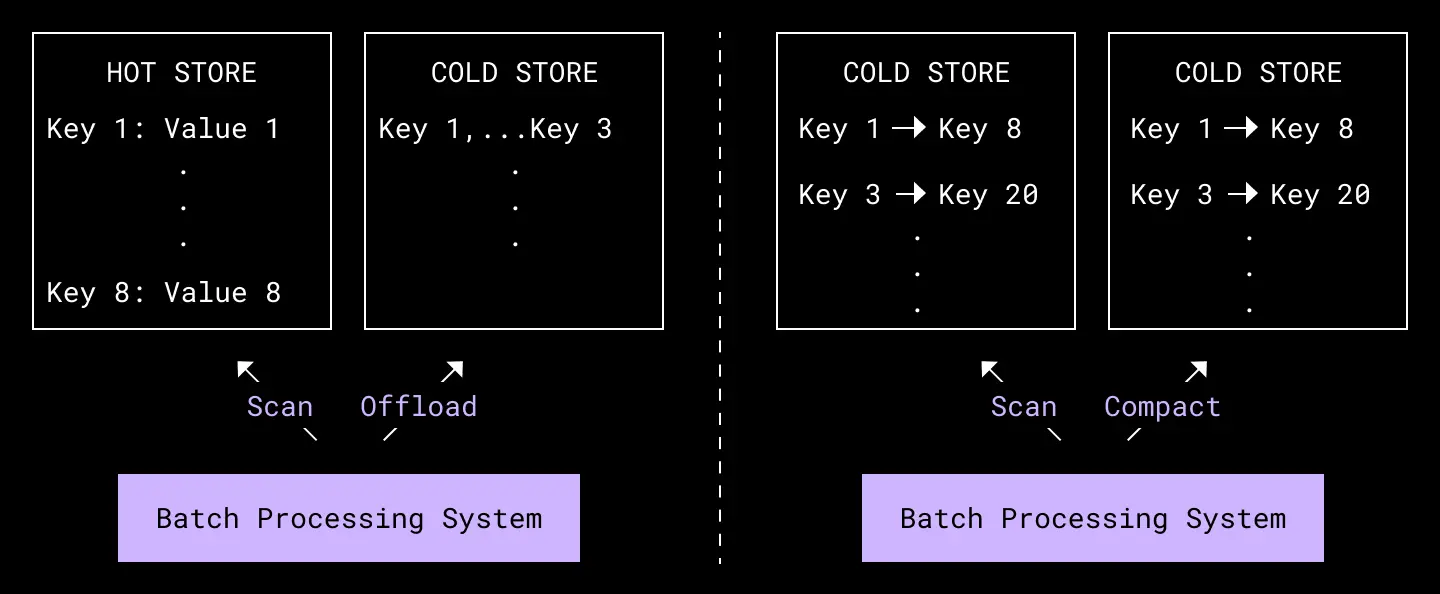
Periodic offload and compaction performed by our offline batch processing system.
In the offline path, we use Blackbird (our batch execution system) together with StepFunctions to periodically perform the offload and compaction processes. Using a hot store that is horizontally scalable also removes the need to offload data with strict deadlines, since any downtime of the batch processing layer only results in extra storage cost, but not in unavailability or data loss. Likewise, an extended downtime of the compaction process only results in slightly degraded read latencies.
Verification and Immutability
For both offload and compaction verification, before committing and marking the new runs visible, we verify the correctness of the transitions by running a series of checks comparing the pre- and post- data. We validate that keys of the new run are sorted, counts of records match up, and that the hash of the (key, value) pairs match.
For the hashing function, we use an order-independent hashing function built on arithmetic over several large prime modulos (a shout-out to our former teammate Robert Escriva, who conceived of the idea and open sourced an implementation). This allows us to compute the hash for a run efficiently by modulo summing the hashes from concurrently computed hashes of different chunks of the run. For compaction, it also allows us to compute the expected hash of the compacted run by simply modulo summing the hashes of the individual runs to be compacted.
Verification of large scale batch operations to transform data is often a hard problem but is made easy in Alki by the immutability of data in a run once it is sealed.
Development and Migration
When designing and building large systems like this in a tight timeline, we found it helped to try to deliver incremental value as it helps to discover unknown unknowns as early as possible. This means that we split building Alki and the migration of audit log data from Edgestore into several phases with concrete deliverables that could help us re-prioritize and re-focus our efforts.
Phase 0: Benchmarking
Before settling on Amazon DynamoDB and S3, we developed and performed many artificial benchmarks against several hot and cold stores. This phase helped rule out several backends early on that would’ve caused significant pain down the line from performance and throughput limitations at scale. It also helped us develop good relationships early on with the DynamoDB and S3 solutions architects to learn how to operate those systems at scale.
Phase 1: Double Writes
We began by implementing a basic write path into the hot store that allowed us to start ingesting data in Alki. We immediately integrated this into the existing live write path of audit logs by writing to Edgestore first and attempting to write to Alki after. At this phase, we did not have the offload from hot to cold implemented, so we simply dropped the ingested data after some period of time to avoid incurring high cost due to the pile-up of data in expensive hot storage. Since we didn’t have confidence in Alki’s reliability yet, we didn’t count Alki write failures against our external APIs’ success rates, but the early integration helped us begin to gauge the performance and availability of Alki and to start building operational expertise. In particular, it revealed early on several issues with handling bursty requests in our gRPC layer and with provisioning of AWS DynamoDB capacity that we were able to implement best practices to mitigate.
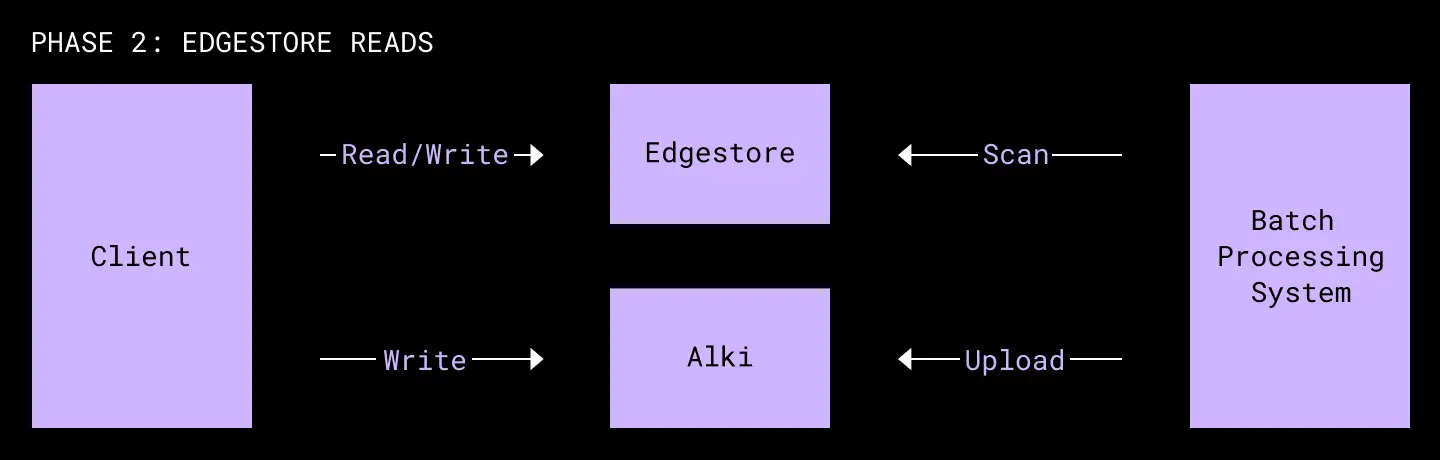
Phase 2: Double Reads w/ Edgestore as Source of Truth
Once we had a read path implemented, we began to perform shadow reads on the live path. This meant every request to read audit log data would, in the background, issue the same request to Alki and compare the results.
At first, because we had not yet made Alki durable and were regularly dropping data, this would show a high rate of missing records. Once we implemented the offline processes and reads of cold data, we were able to immediately verify that offload and reads worked by seeing the rate of missing records plummet to a low rate of reads of old records never ingested into Alki.
Beyond allowing us to see immediate validation that our offload implementation worked, this early verification also allowed us to start building tooling around investigating the causes of mismatched reads, which became indispensable for tracking down bugs in the ingestion and read path.
Once all of the functionality to read, write, and migrate data into Alki had been battle tested, we wiped Alki’s data one last time and begin to durably write audit logs into Alki. At this point, reads were still using Edgestore as a source of truth. In the background, we began to migrate data from Edgestore directly into Alki’s cold store using a batch upload API that we built.
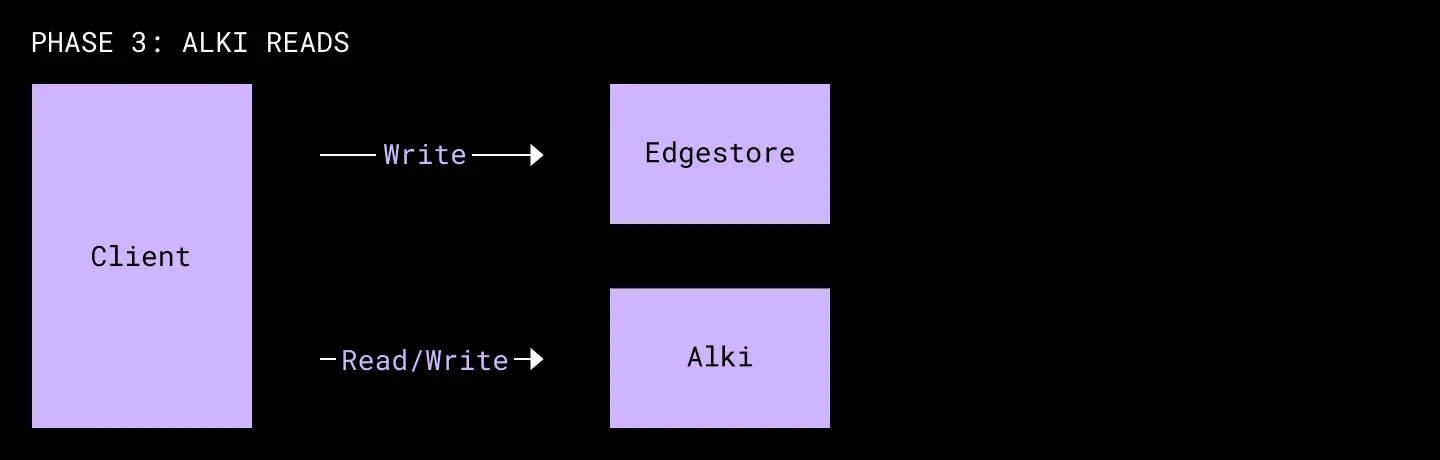
Phase 3: Double Reads w/ Alki as Source of Truth
After we verified the migration was complete, we let the shadow read verification run for a few more weeks to build more confidence. We then switched the source of truth for reads and writes over to Alki. We remained in this double read/double write phase for another few weeks to ensure we could rollback to using Edgestore if needed. Though the rollback was never needed, the continuation of validating reads revealed that Alki actually ingested data more reliably than Edgestore. In particular, Alki was able to handle ingestion spikes more gracefully and we often saw Alki reads return more complete data than Edgestore.
Phase 4: Alki Only
Once we were confident Alki was working as expected, we turned off audit log writes to Edgestore and began deleting the now-migrated data from Edgestore.
Conclusion
Today, Alki serves roughly 350 TB worth of user data (pre-replication and not counting indexes), at about 1/6 the cost of Edgestore per GB per year. This was made possible by leveraging the inexpensive storage costs of cold blob storage.
We’re in the process of onboarding a couple of other cold metadata use cases at Dropbox. In particular, there are many similar logging use-cases where the retention is long but the data is rarely read after some initial ingestion period that are prime for migration to our optimized cold metadata system.
Looking forward, we’re also planning to build a system to automatically detect and migrate cold metadata from Edgestore and the in-development Panda key-value store into Alki.
Many thanks to past and present contributors, design reviewers, and mentors: Anuradha Agarwal, James Cowling, William Ehlhardt, Alex Grach, Stas Ilinskiy, Alexey Ivanov, Anirudh Jayakumar, Gevorg Karapetyan, Olga Kechina, Zack Kirsch, Preslav Le, Jonathan Lee, Cheng Li, Monica Pardeshi, Olek Senyuk, Lakshmi Kumar T, Lawrence Xing, Sunny Zhang
We’re Hiring!
Do you enjoy building databases and storage infrastructure at scale? Dropbox has petabytes of metadata, exabytes of data, and serves millions of requests per second. The Persistent Systems team at Dropbox is hiring both SWEs and SREs to work on building the next generation of reliable, highly scalable, and durable storage systems.


