

Edgestore is the metadata store that powers many internal and external Dropbox services and products. We first talked about Edgestore in late 2013 and needless to say, much has happened since.
In this post, we give a high-level overview of the motivation behind Edgestore, its architecture, salient features and how it’s being used at Dropbox. We’ll be doing a deep-dive on various aspects of Edgestore in subsequent posts.
A Brief History
Like so many startups, Dropbox started with vanilla MySQL databases for our metadata needs. As we rapidly added both users and features, we soon ended up with multiple, independent databases; some databases grew so large that we had to split them into multiple shards. And before long, unsurprisingly, we started hitting challenges of such an architecture, such as:
- Having to write SQL and interact with MySQL directly impacted developer productivity. In the same vein, schema evolution was brittle and error-prone.
- Managing so many independent MySQL hosts imposed a significant operational burden.
- Reactively (re)sharding individual databases as they hit capacity limits was cumbersome; conversely, setting up new database clusters for every use case added a lot of overhead.
- Lack of isolation meant bugs or slow queries would adversely impact performance across the board
In late 2012, we began building a system that would address these challenges. In addition, we wanted the following characteristics to meet future needs:
- Flexible enough to support a broad class of existing and future use cases
- Developer friendly APIs and easy schema evolution to accelerate product teams
- Table-stakes for critical infrastructure services: durability, high-availability and excellent performance.
At the time, no off-the-shelf solution met all our requirements. Given our in-house MySQL expertise and similar systems at other companies (notably, Facebook’s TAO), we decided to build our own system that would abstract away the database by providing higher-level abstractions and use MySQL (InnoDB) as the storage engine.
Edgestore started out as a simple client-side ORM wrapper, but has over time evolved into a sophisticated service with features like caching, geo-replication and multi-tenancy. Edgestore has been running in production at Dropbox for almost four years, on thousands of machines across multiple data centers, storing several trillion entries and servicing millions of queries per second with 5–9s of availability!
Architecture Overview
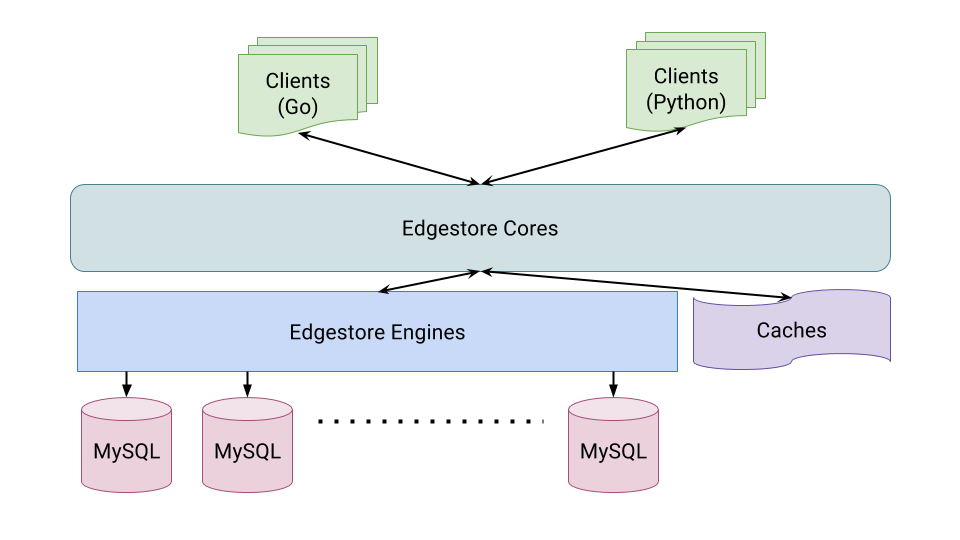
Users interact with Edgestore via language-specific SDKs that implement the Edgestore API. The API allows developers to easily describe (and evolve) their data model without worrying about how or where data gets stored. We currently provide SDKs for Go and Python.
Objects in Edgestore can be Entities or Associations, each of which can have user-defined attributes (roughly analogous to columns in a traditional database table). Associations describe how different Entities relate to each other: for instance, users/group membership might be described using a UserEntity , TeamEntity and a UserTeamAssoc .
The SDK provides Edgestore Clients that connect to any one of Edgestore Cores. Cores comprise a stateless layer responsible for routing (or forwarding) the request to the correct “shard” (or region).
Since our workload is read-heavy, Cores use a Caching Layer to speed lookups. The caches are also partitioned and replicated for high-availability. Edgestore provides strong-consistency by default, which requires invalidating caches on writes. If the workload can tolerate stale reads, clients can request eventual consistency.
For writes (or on a cache-miss), Cores send the request to the Engine where data is “mastered”, as determined by our partitioning scheme. Engines abstract away the Storage layer from Cores, so our design is not MySQL specific. Engines translate Edgestore APIs to MySQL commands and track resource consumption by traffic-source. This forms the foundation of isolation and multi-tenancy in Edgestore.
For brevity, we’re glossing over many technical details here. Please check back for our follow-up posts where we’ll deep-dive into the special topics listed under “Coming Up” below!
Use Cases
Edgestore’s flexible data model enables some of the most critical and well-known use cases in our product, demonstrating the diversity of workloads it’s capable of supporting. From graph-like representations, key-value stores and queues, Edgestore is a veritable swiss army knife of data models for our product engineers to leverage. Here are a few examples.
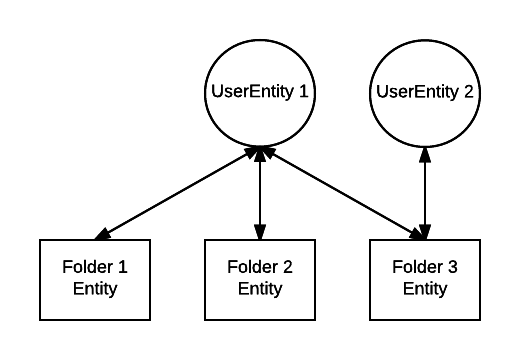
The core aspects of sharing and collaboration are all modeled using Edgestore’s graph-like data model. Users and Folders are represented as Edgestore entities. Bi-directional associations make it easy to query all folders a given user has access to, as well as all users that have access to a given shared folder. Removing a user from a shared folder requires removing just a single association.
Email Campaigns
Given its continued dominance, it should be no surprise that email remains one of the most powerful ways for Dropbox to connect with our user base. To make it easy for any team in Dropbox to set up an email campaign, we have built an internal email management system that leverages Edgestore’s ability to function as a queue. Every email message that is stored and sent through our email service maintains an Assoc with the current status of the message (is the message pending, is it scheduled to go out, was it sent and returned with an error) and a timestamp that is used to order the messages. A periodic job is used to scan the timestamps and status to see which messages require sending; they are sent and removed from the queue (or re-enqueued, as needed). This system stores all of its metadata in Edgestore and relies on Edgestore’s strong consistency guarantees to provide exactly–once delivery semantics.
Trust and Security
At Dropbox, being worthy of our users’ trust is a core company value. In a previous blog post, we covered our support for Universal 2nd Factor (U2F) security keys as an additional method for two-step verification to provide stronger authentication protection to our users. Our implementation of U2F leverages Edgestore to store critical metadata like the hardware token and the public key associated with each token, as well as other relevant information in the association between a User entity and a Host entity.
Coming Up
To recap, Edgestore is a strongly consistent, read-optimized, horizontally scalable, geo-distributed metadata store that powers many internal and external Dropbox services and products. At some point as a company evolves, the need arises for a flexible, generic metadata store. Rather than continue bolting more features and tooling to our MySQL infrastructure, we built Edgestore to abstract away the database altogether.
We are excited to share our learnings with the community! This is the first of a series of blog posts about Edgestore. Over the next few months, we plan to cover more technical details on some of the more interesting aspects of Edgestore. Some examples:
- Data Model and Schema Evolution: We’ll describe how Edgestore users express their data model and how Edgestore represents that on-disk, as well as how users evolve the data model over time.
- Consistent Caches: Many Edgestore workloads require strong consistency, which in turn requires that in-memory caches are always consistent with on-disk state. Doing this in a performant way without sacrificing availability posed some interesting challenges for us.
- Event Stream: We found many applications interested in acting upon metadata in Edgestore as it gets written/updated. To enable this, we’ve built an event stream abstraction.
- Cross Data-Center Routing and Replication: To support geo-replication in Edgestore, we had to build a custom replication pipeline (one of the consumers of the aforementioned event stream) as well as a request routing and forwarding layer.
- Multi-Tenancy: Edgestore is used by dozens of products and services, both internal and external. We share a single Edgestore deployment for all workloads, necessitating good attribution and isolation across workloads.
- Operations and Tooling: Edgestore is mission-critical, complex service with high availability requirements. We hope to share more about how we manage different parts of our infrastructure.
This is a tentative list — if there are specific areas you’d like to see covered, please leave a comment!
Thanks to: Alex Degtiar, Adil Hafeez, Bogdan Munteanu, Chris Roberson, Daniel Tahara, Kerry Xing, Maxim Bublis, Mehant Baid, Michelle Chesley, Mihnea Giurgea, Rajat Goel, Renjish Abraham, Samir Goel, Tom Manville and Zviad Metreveli


