

Knowledge workers routinely lose valuable time trying to find that thing—the right images, videos, documents, or audio files—across their dozens of apps and essential work tools. When we started building Dropbox Dash, our universal search and knowledge management product, we knew it had to do more than just speed up search. It also needed to scale beyond text. Because often, the challenge isn’t just finding a file—it’s finding what’s inside that file. And that gets tricky when things aren’t labeled clearly, your team’s folder structure breaks down, or you just can’t remember where you saved what you need.
Searching for multimedia content poses unique challenges. Images, for example, often come with cryptic names like IMG_6798 by default, and teams can quickly accumulate thousands of these unlabeled assets. Unlike documents, which usually contain metadata or readable content to help with discovery, media files frequently lack that context and require manual review. On top of that, they demand heavier compute resources and smarter ranking systems to deliver relevant results at speed.
Supporting fast, accurate media search in Dash wasn’t a matter of layering features on top—it required fundamental changes across our infrastructure. We had to rethink how we indexed and ranked non-text files, how we rendered visual previews, and how we hydrated and surfaced metadata. We also had to reevaluate traditional document-search assumptions about relevance, latency, and even UI presentation.
Our multimedia retrieval features were built to solve these exact problems, allowing users to find images, video, and audio just as easily as they find documents. What follows is a behind-the-scenes look at the engineering that made this possible: what we built, what we learned, and how we delivered a system that makes media as searchable as text.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Challenges in supporting multimedia search
Supporting search for multimedia—images, video, and audio—introduces a distinct set of technical hurdles. These files require significantly more processing power, have fewer textual cues for ranking, and often lack meaningful metadata. Delivering fast, relevant results means handling large file sizes efficiently, identifying new relevance signals, and optimizing how results are rendered for user review.
That’s why our universal search solution had to support seamless browsing, filtering, and previewing of media—right inside Dash. Scaling search for this content meant facing higher storage and compute costs, tighter latency requirements, and adapting systems originally built for text-based retrieval. To understand what makes media search tricky, let’s break down some key considerations.
Storage cost
Media files are significantly larger than typical documents. On average, image files are about 3X larger, and video files are roughly 13X larger than non-media files in our system. These size differences directly increase storage demands and costs.
Compute cost
Multimedia files, such as images and videos, require more intensive processing to extract features both due to their larger size and the complexity of the features. Unlike text documents, we also generate previews of different resolutions for the images and videos, thereby significantly increasing the compute demands in our system.
Relevance
Dash operates a multi-phase retrieval and ranking scheme, which was previously trained and optimized for textual content. Retrieving and ranking multimedia content requires having indexed any new multimedia-specific signals, formulating a query plan that leverages these signals, and handling any corner cases to avoid poorly ranked results.
Responsiveness
Serving multimedia content introduces new latency challenges that are not present with text-based documents. We need previews for the multimedia search results to be meaningful, and we need them in multiple resolutions, including high-res formats, for a rich product experience. The larger resolutions add to the storage and compute costs.
Only a small fraction of the indexed files are actually viewed during search interactions. As a result, precomputing previews at multiple resolutions for all media files would be wasteful and unnecessary. To balance responsiveness with resource efficiency, we generate previews on demand during the read path rather than upfront. This minimizes upfront compute and storage costs but introduces new latency concerns during user interactions, since we want to generate previews quickly to have a snappy user experience.
With these challenges in mind, we designed a solution that integrates scalable infrastructure, smarter content understanding, and a preview system optimized for speed and accuracy.
Building a multimedia search solution
To deliver a responsive and scalable experience in Dash, we had to rebuild key parts of our infrastructure to support search that’s as smart and seamless for photos and videos as it is for documents. This work spans multiple layers of the stack, and it wasn’t pulled off successfully without trial and error.
We began by indexing lightweight metadata—pulled from media blobs (the raw files like images, videos, or audio)—to keep compute costs low. We extended our relevance models to handle location-aware queries and fuzzy file naming, and we optimized our preview generation pipeline to balance latency with cost. Along the way, we made frontend and backend updates to ensure media renders quickly and consistently across devices. The result is a robust multimedia search experience powered by smart metadata, just-in-time previews, and a UI that helps users find the right visual asset fast. Let’s get into how we tackled it.
Indexing media files by metadata
To keep the compute costs low, we begin by indexing media files using available metadata, which is significantly cheaper to process than analyzing the full contents of media like images or videos. For example, we extract features such as file path, title, and EXIF. These metadata provide a lightweight foundation that enables basic search functionality with minimal processing overhead.
As our capabilities evolve, we plan to build on this metadata-first approach by selectively incorporating deeper content analysis—such as semantic embedding and/or OCR—striking a balance between accuracy and cost.
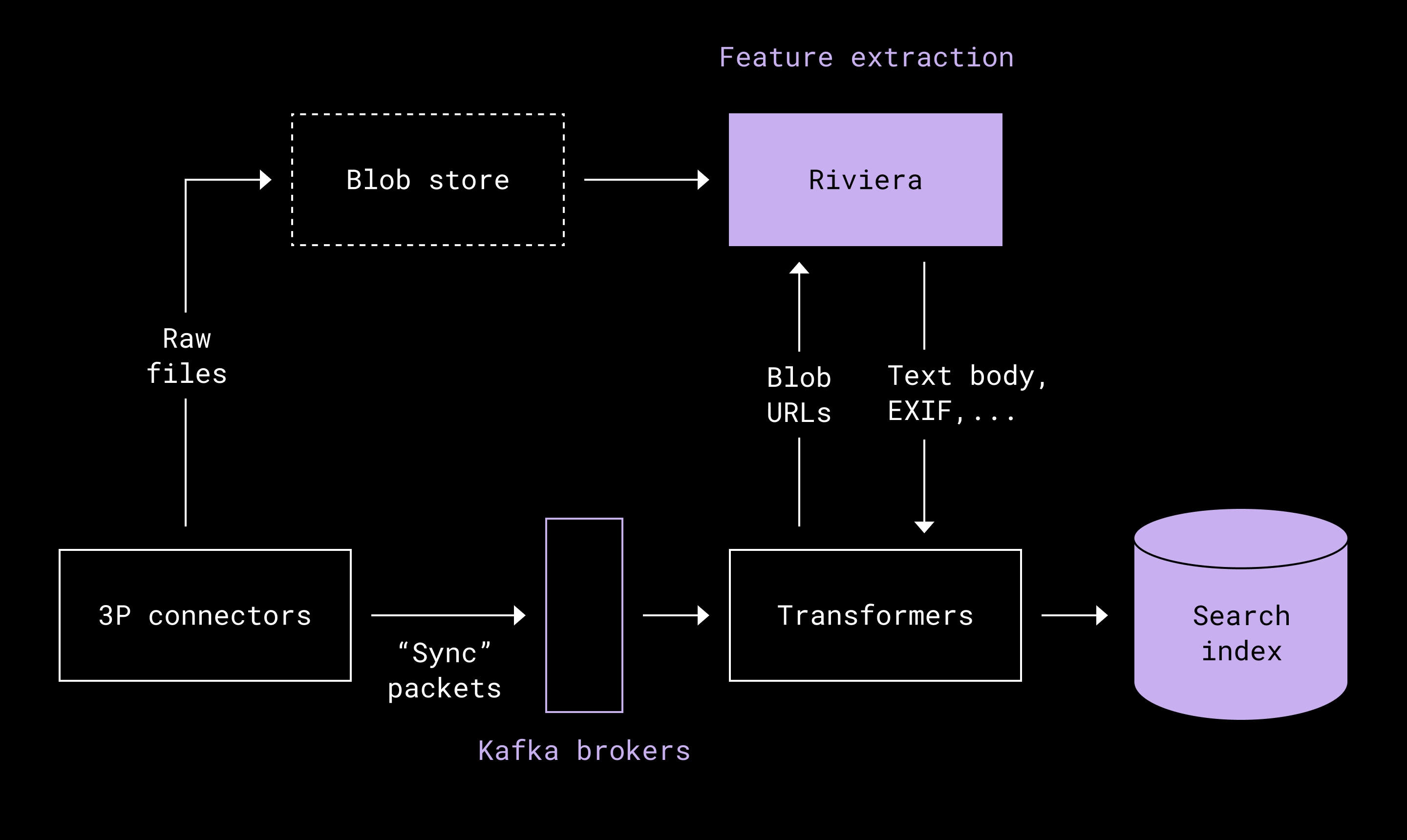
To generate metadata features at scale, we leveraged Riviera, our internal compute framework that already powers Dropbox Search. Riviera processes tens of petabytes of data daily and includes mature business logic for metadata extraction. By reusing it, we benefited from proven scalability and consistency with existing Dropbox search infrastructure.
Backfilling the index
Prior to this initiative, we avoided downloading or storing raw media blobs in order to reduce storage and compute costs. As a result, our existing search index lacked the necessary features to support rich, media-specific search experiences. To address this gap, we added support for ingesting multimedia blob content to compute the required features. We retain the raw content for preview generation and to compute future features.
Where possible, we download previews provided by third-party applications. These externally sourced previews are especially useful for design files like Canva, where we’re unable to generate our own. Using them also helps us reduce compute costs.
Storage optimizations
Dash optimizes the file sizes and MIME types ingested to balance storage cost and file availability. We currently ingest about 97% of media files and are working to address the remaining gaps with smarter lifecycle management techniques.
Retrieving media files by metadata
When a user searches for media, we configure the query to match their input against the metadata features extracted during indexing. This includes fields like filenames, file paths, and location data. To enhance location-based search, we also apply custom query logic for interpreting geographic references.
Internally, we index a GPS location as a chain of IDs corresponding to the geographical hierarchy. For instance, we can look up the GPS coordinates of a photo to be from San Francisco in a process known as “reverse geocoding.” Then, we would build a chain of IDs corresponding to San Francisco, California, and the United States, respectively, and place these IDs in the index for the photo. This allows us to retrieve the photo when the user wants to search for a photo taken in San Francisco, California or the entire United States, respectively.
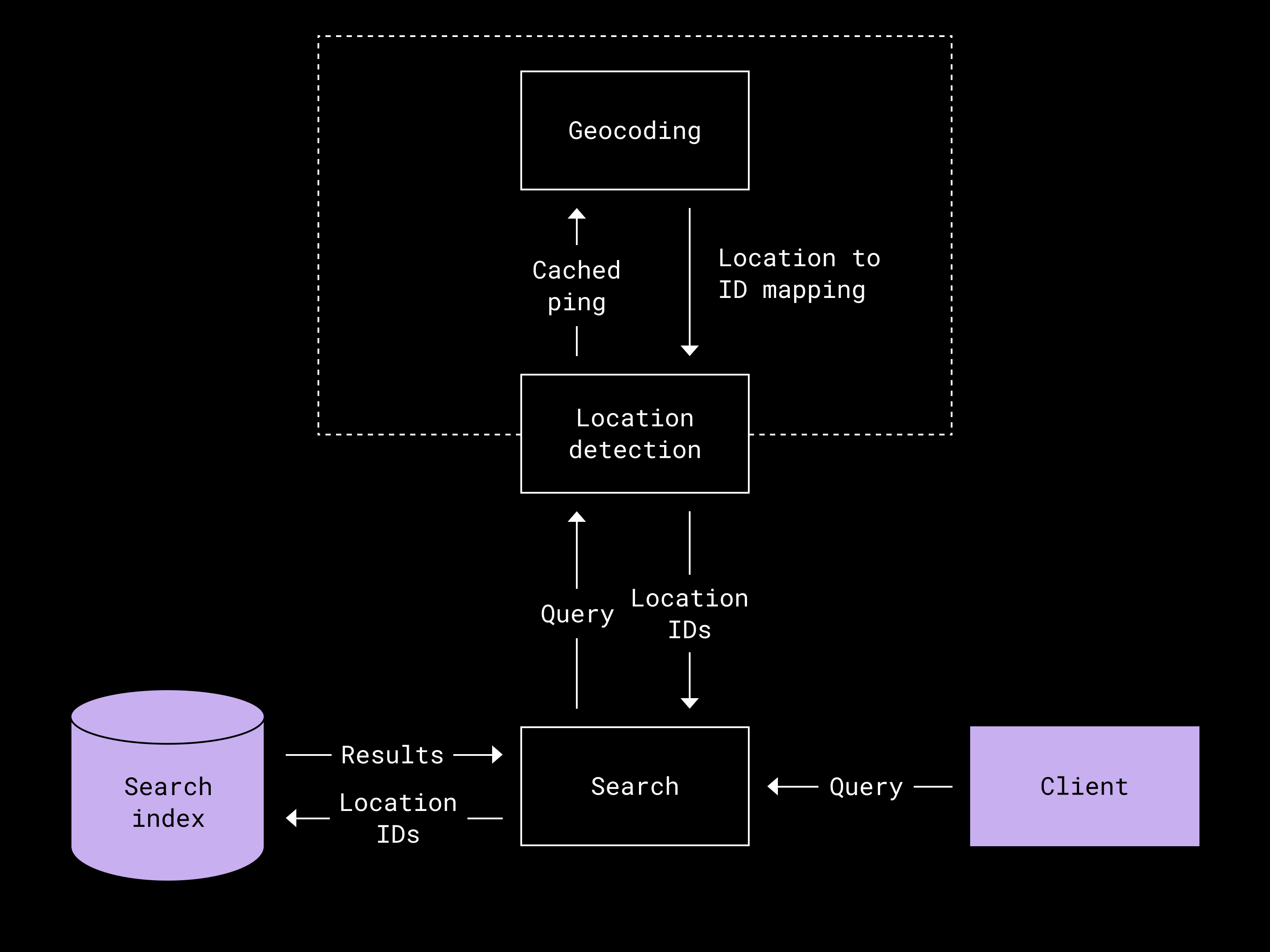
At query time, we identify substrings of the query that may potentially be geographical locations, and then we determine whether they map to a valid location ID. In practice, because the number of known geographical locations has a manageably small cardinality, we retrieve the entire mapping upon the service startup and cache it.
Lastly, in the course of building multimedia search, we realized that many multimedia files are named in particular ways. Many of them are files in the filesystem, e.g. PhotoShoot-Revised1234.jpg. To support better matching, we added logic to tokenize camel case, hyphenated strings, and numeric suffixes during both indexing and retrieval.
Preview and metadata hydration at retrieval time
Our system ingests data at a rate that’s approximately three orders of magnitude higher than the query rate. This disparity makes it prohibitively expensive to generate and store previews for all multimedia files during ingestion, both in terms of compute and storage. To address this, we adopted a just-in-time approach, where previews are generated at query time. This strategy significantly reduces upfront costs while still supporting a responsive user experience.
As part of our storage optimization efforts, we considered precomputing previews during ingestion to enable deletion of the raw content afterward. However, we ultimately decided against this approach for two key reasons. First, managing the lifecycle of these additional preview artifacts would introduce significant code complexity. Second, retaining the raw content ensures future flexibility, allowing us to compute new features later without having to re-ingest the original files.
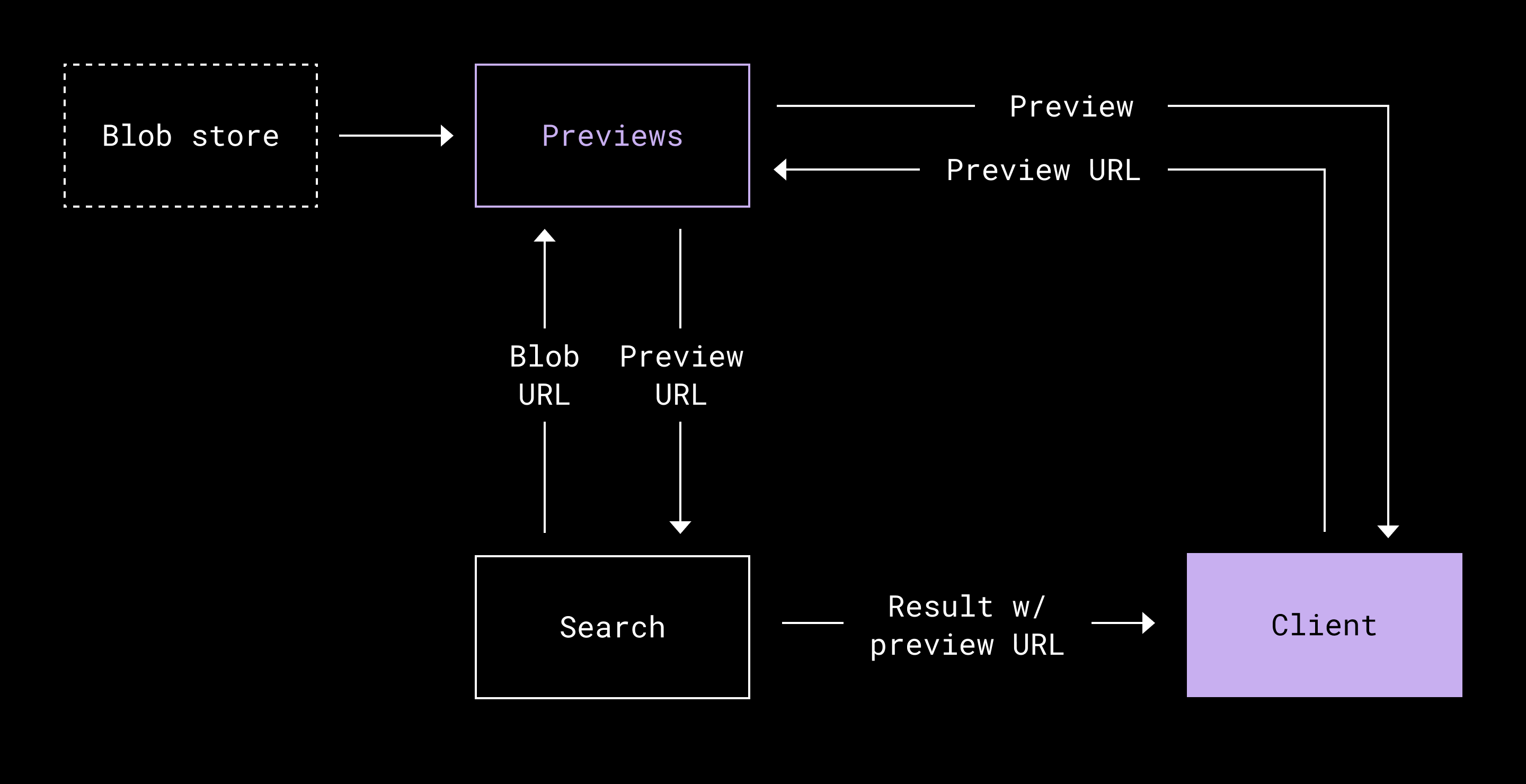
To power the just-in-time approach, we rely on an internal previews service built on top of Riviera, a framework originally developed for Dropbox Search. The previews service is designed to be fast, scalable, and efficient. It incorporates intelligent caching strategies, storing previews for up to 30 days. This allows us to serve previews quickly when needed without repeatedly generating them for every request.
During a search, we generate preview URLs for the relevant results, which are then passed to the frontend. The frontend fetches these URLs and displays the corresponding previews directly to the user. By reusing both the Riviera framework and the previews service, we also create the opportunity to reuse frontend components across both Dropbox and Dash. This ensures a consistent product experience across both platforms.
To improve latencies, we create the preview URLs in parallel with other search operations such as ranking the results, performing permission checks, and fetching additional metadata needed to render complete search results. By handling these tasks in parallel, we minimize the overall response time and ensure a responsive user experience.
.png/_jcr_content/renditions/Diagram%204%20(1).webp)
Sometimes, a user may want to enlarge a preview and view additional metadata, such as camera information. However, this is a less common operation, and sending all the extra metadata with every search result would be inefficient. When users request more detail—such as camera metadata or timestamp—we fetch it on-demand via a separate endpoint. This keeps the initial search response lean while still supporting deeper inspection when needed.
User experience
Searching through images and videos is a different experience than searching documents, especially since media files often have names like “IMG_1234” that don’t tell you much. That’s why fast, visual previews are essential—they help users quickly decide which file is relevant without needing to open each one.
We’ve designed our preview system to load quickly and adapt to different shapes and sizes of media, whether an image is tall, wide, or an unusual shape. The layout avoids awkward cropping and keeps things easy to browse. When a user wants a closer look, they can open a full-size preview that also shows helpful EXIF details like when the photo was taken, what kind of camera was used, and where it was captured.
Everything is built to feel smooth and fast, whether you’re using Dash on a phone or computer. The interface stays out of the way and puts the focus on the content, making it easy to browse quickly or dive into a specific file when needed.
Lessons learned and future direction
Building this vertical solution required collaboration across multiple teams. Initially, the strong interdependencies between teams risked making the workstream highly sequential. To address this, we defined clear API boundaries between systems, which allowed teams to work in parallel. This separation of concerns enabled faster execution and ensured that all components integrated seamlessly toward the end.
A significant portion of our development time was spent getting the preview experience to work end-to-end. It wasn’t immediately clear how to architect the entire system. One of the key challenges was building a new user experience for displaying media results. We accelerated UX development by temporarily proxying results from Dropbox Search through a custom endpoint. Although Dropbox Search did not include all third-party content ingested into Dash, it provided enough data to design and test the user interface. This strategy bought us valuable time to develop the backend infrastructure and complete the media backfill.
Leveraging the existing Dropbox infrastructure for previews saved us considerable development time and resulted in cleaner, more maintainable code. To monitor performance, we added metrics to track preview generation latencies. These metrics helped us identify bottlenecks and areas needing optimization. With additional instrumentation and a more aggressive use of concurrency, we were able to substantially reduce latency and improve the responsiveness of the system.
Looking ahead, we have plans to make multimedia search even smarter by incorporating advanced capabilities such as semantic embeddings and optical character recognition (OCR). These enhancements will bring new technical challenges, and we expect to continue making thoughtful trade-offs between cost and user value as we expand the system’s functionality.
Supporting multimedia search in Dash meant bridging the gap between how teams create and consume visual content and how our infrastructure finds and ranks that content at scale. From metadata-first indexing to just-in-time previews and geolocation-aware queries, each technical decision reflected a balance of cost, performance, and product value.
The addition of multimedia search marks a significant step forward in our journey to build a truly universal search tool. The result is a system that brings the same speed and intelligence to media as it does to text. As we continue to improve Dash, our focus remains on unblocking key customer hurdles so they can spend less time searching and more time creating.
Special thanks to Edward Cheung, Eric Cunningham, Westin Lohne, and Noorain Noorani who also contributed to this story.
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


