

Recently, we translated the predictive power of machine learning (ML) into $1.7 million a year in infrastructure cost savings by optimizing how Dropbox generates and caches document previews. Machine learning at Dropbox already powers commonly-used features such as search, file and folder suggestions, and OCR in document scanning. While not all our ML applications are directly visible to the user, they still drive business impact in other ways.
What are Previews?
The Dropbox Previews feature allows users to view a file without downloading the content. In addition to thumbnail previews, Dropbox also offers an interactive Previews surface with sharing and collaborating capabilities, including comments and tagging other users.
Our internal system for securely generating file previews, Riviera, handles preview generation for the hundreds of supported file types. It does this by chaining together various content transformation operations to create the preview assets appropriate for that file type. For example, Riviera might rasterize a page from a multi-page PDF document to show a high-resolution preview on the Dropbox web surface. The full-content preview feature supports interactions such as commenting and sharing. The large image assets might later be converted into image thumbnails that will be shown to the user in a variety of contexts, including search results or the file browser.
At Dropbox scale, Riviera processes tens of petabytes of data each day. To speed up the Previews experience for certain classes of large files, Riviera pre-generates and caches preview assets (a process we call pre-warming). The CPU and storage costs of pre-warming are considerable for the volume of files we support.
Thumbnail previews when browsing files. Previews can be enlarged and interacted with as a proxy for the application file.
We saw an opportunity to reduce this expense with machine learning because some of that pre-generated content was never viewed. If we could effectively predict whether a preview will be used or not, we would save on compute and storage by only pre-warming files that we are confident will be viewed. We dubbed this project Cannes, after the famous city on the French Riviera where international films are previewed.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Tradeoffs in machine learning
There were two tradeoffs that shaped our guiding principles for preview optimization.
The first challenge was to negotiate the cost-benefit tradeoff of infrastructure savings with ML. Pre-warming fewer files saves money—and who doesn’t like that!—but reject a file incorrectly and the user experience suffers. When a cache miss happens, Riviera needs to generate the preview on the fly while the user is waiting for the result to appear. We worked with the Previews team to develop a guardrail against degrading user experience, and used the guardrail to tune a model that would provide a reasonable amount of savings.
The other tradeoff was complexity and model performance vs. interpretability and cost of deployment. In general, there is a complexity vs. interpretability tradeoff in ML: more complex models usually have more accurate predictions at the cost of less interpretability of why certain predictions are made, as well as possibly increased complexity in deployment. For the first iteration, we aimed to deliver an interpretable ML solution as quickly as possible.
Since Cannes was a new application of ML built into an existing system, favoring a simpler, more interpretable model let us focus on getting the model serving, metrics, and reporting pieces right before we added more complexity. Should something go wrong or we surface unexpected behavior in Riviera, the ML team could also more easily debug and understand whether the cause was Cannes or something else. The solution needed to be relatively easy and low cost to deploy for nearly half a billion requests per day. The current system was simply pre-warming all previewable files, so any improvement on this would result in savings—and the sooner the better!
Cannes v1
With these tradeoffs in mind, we targeted a simple, fast-to-train, and explainable model for Cannes. The v1 model was a gradient-boosted classifier trained on input features including file extension, the type of Dropbox account the file was stored in, and most recent 30 days of activity in that account. On an offline holdout set, we found this model could predict previews up to 60 days after time of pre-warm with >70% accuracy. The model rejected about 40% of pre-warm requests in the holdout, and performance was within the guardrail metrics we set for ourselves at the onset. There were a small number of false negatives (files that we predicted would not be viewed, but did end up being viewed in the subsequent 60 days), which would cause us to pay the cost of generating preview assets on the fly. We used the “percentage-rejected” metric minus the false negatives to ballpark the $1.7 million total annual savings.
Even before we explored the Previews optimization space, we wanted to ensure the potential savings outweighed the cost of building an ML solution. We had a ballpark estimate of the projected savings we wanted to target with Cannes. Designing and deploying ML systems in large, distributed systems means accepting some changes to the system will impact your estimates over time. By keeping the initial model simpler, we hoped the order of magnitude of the cost impact would remain worthwhile even if there are small changes to adjacent systems over time. Analyzing the trained model gave us a better idea of what we actually would save in v1 and confirmed the investment was still worthwhile.
We conducted an A/B test of the model on a random 1% sample of Dropbox traffic using our internal feature gating service, Stormcrow. We validated that model accuracy and pre-warms “saved” were in line with our results from offline analysis—which was good news! Because Cannes v1 no longer pre-warms all eligible files, we expected the cache hit rate to drop; during the experiment, we observed a cache hit rate a couple percentage points lower than the holdout population from the A/B test. Despite this drop, overall preview latency remained largely unchanged.
We were especially interested in tail latency (latency for requests above the 90th percentile), because cache misses that contributed to higher tail latency would more severely impact users of the Previews feature. It was encouraging that we did not observe a degradation to either preview tail latency or overall latency. The live test gave us some confidence to begin deploying the v1 model to more Dropbox traffic.
Live predictions at scale
We needed a way to serve real-time predictions to Riviera on whether to pre-warm a given file as files come through the pre-warming path. To solve this problem, we built Cannes as a prediction pipeline that fetches signals relevant to a file and feeds them into a model that predicts the probability of future previews being used.
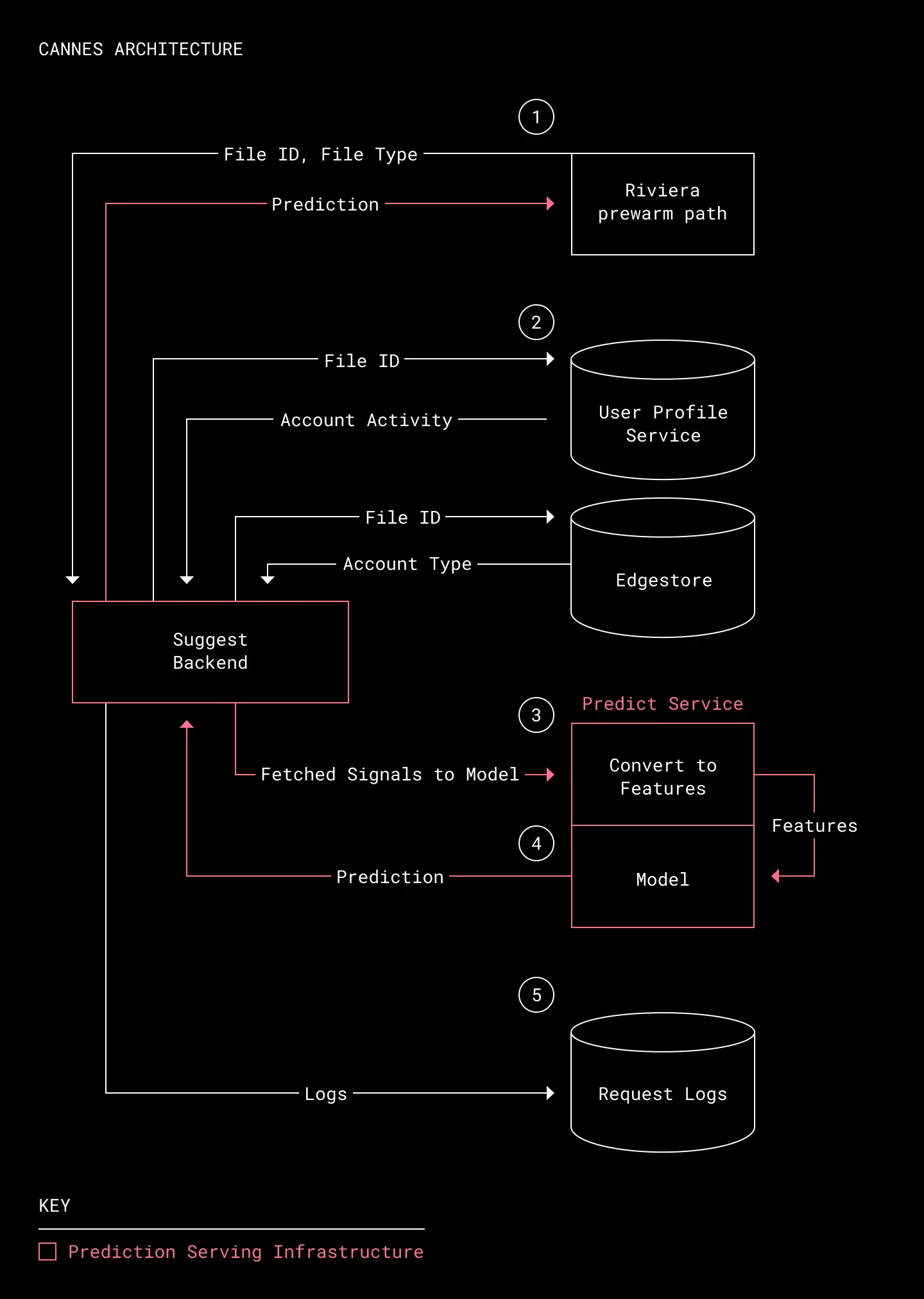
Cannes architecture
- Receive file id from Riviera pre-warm path. Riviera collects all file ids eligible for pre-warm. (Riviera can preview ~98% of files stored on Dropbox. There are a small number of files that are not a supported file type or otherwise cannot be previewed.) Riviera sends a prediction request with the file id we need a prediction for and the file type.
- Retrieve live signals. To collect the most recent activity signals for a file at prediction time, we use an internal service named the Suggest Backend. This service validates the prediction request, then queries for the appropriate signals relevant to that file. Signals are stored in either Edgestore (Dropbox’s primary metadata storage system) or the User Profile Service (a RocksDB data store which aggregates Dropbox activity signals).
- Encode signals into feature vector. The collected signals are sent to the Predict Service, which encodes the raw signals into a feature vector representing all relevant information for the file, then sends this vector to a model for evaluation.
- Generate a prediction. The model uses the feature vector to return a predicted probability that the file preview will be used. This prediction is then sent back to Riviera, which pre-warms files likely to be previewed up to 60 days in the future.
- Log information about request. Suggest Backend logs the feature vector, prediction results, and request stats—critical information for troubleshooting performance degradation and latency issues.
Additional consideration
Reducing prediction latency is important because the pipeline above is on the critical path for Riviera’s pre-warming functionality. For example, when rolling out to 25% of traffic, we observed edge cases that decreased Suggest Backend availability to below our internal SLAs. Further profiling showed that these cases were timing out on step 3. We improved the feature encoding step and added several other optimizations to the prediction path, bringing tail latency down for those edge cases.
Operationalizing ML
During the rollout process and beyond, we emphasized stability and making sure not to negatively impact the customer experience on the Previews surface. Close monitoring and alerting on multiple levels are critical components of the ML deployment process.
Cannes v1 metrics
Prediction serving infra metrics: Shared systems have their own internal SLAs around uptime and availability. We rely on existing tools like Grafana for real-time monitoring and alerts. Metrics include:
- Availability of Suggest Backend and Predict Service
- Data freshness of User Profile Service (our activity data store)
Preview metrics: We have key metrics for preview performance—namely, preview latency distribution. We left a 3% holdout for comparing previews metrics with and without Cannes, guarding against model drift or unanticipated system changes that could degrade model performance. Grafana is also a common solution for application-level metrics. Metrics include:
- Preview latency distribution (Cannes vs non-Cannes holdout), with extra attention to latency above p90
- Cache hit rate (Cannes vs non-Cannes holdout): total cache hits/total requests to preview content
Model performance metrics: We have model metrics for Cannes v1 that the ML team consumes. We built our own pipeline for calculating these metrics. Metrics of interest include:
- Confusion matrix, with extra attention to changes in rate of false negatives
- Area under ROC curve: While we directly monitor the confusion matrix stats, we also calculate an AUROC with an eye towards using it to compare to performance of future models.
The model performance metrics above are calculated hourly and stored in Hive. We use Superset for visualizing important metrics and creating a live dashboard of Cannes performance over time. Superset alerts built off the metrics tables proactively let us know when underlying model behavior has changed, hopefully well in advance of any client-facing impact.
However, monitoring and alerting alone are insufficient for ensuring system health; establishing clear ownership and escalation processes is also necessary. For instance, we documented specific upstream dependencies of ML systems that could impact the results of the model. We also created a runbook for the on-call engineer which details steps for troubleshooting whether the issue is within Cannes or another part of the system, and a path of escalation if the root cause is the ML model. Close collaboration between ML and non-ML teams thus helps ensure Cannes continues to run smoothly.
Current state and future exploration
Cannes is now deployed to almost all Dropbox traffic. As a result, we replaced an estimated $1.7 million in annual pre-warm costs with $9,000 in ML infrastructure per year (primarily from increased traffic to Suggest Backend and Predict Service).
There are many exciting avenues to explore for the next iteration of this project. There are more complex model types we can experiment with now that the rest of the Cannes system is in production. We can also develop a more fine-tuned cost function for the model based on more detailed internal expense and usage data. Another new Previews application we’ve discussed is using ML to make predictive decisions more granular than a binary prewarm/don’t-prewarm per file. We may be able to realize further savings by being more creative with predictive prewarming, reducing costs with no deterioration to the file preview experience from the user’s perspective.
We hope to generalize the lessons and tools built for Cannes to other infrastructure efforts at Dropbox. ML for infrastructure optimization is an exciting area of investment.
Thanks to the Previews and ML Platform teams for their partnership on Cannes. In particular, kudos to Zena Hira, Jongmin Baek, Jason Briceno, Neeraj Kumar, and Kris Concepcion on the ML team; Anagha Mudigonda, Daniel Wagner and Robert Halas on the Previews team; and Ian Baker, Sean Chang, Aditya Jayaraman, and Mike Loh on the ML Platform team.
About Us: The Intelligence team at Dropbox uses machine learning (ML) to drive outsized business and user value by leveraging a high fidelity understanding of users, content, and context. We work closely with other product and engineering teams to deliver innovative solutions and features. See open positions at Dropbox here!


