

A SaaS company like Dropbox needs to update our systems constantly, at all levels of the stack. When it comes time to tune some piece of infrastructure, roll out a new feature, or set up an A/B test, it’s important that we can make changes and have them hit production fast.
Making a change to our code and then “simply” pushing it is not an option: completing a push to our web servers can take hours, and shipping a new mobile or desktop platform release takes even longer. In any case, a full code deployment can be dangerous because it could introduce new bugs: what we really want is a way to put some configurable “knobs” into our products, which a) give us the flexibility we need and b) can be safely tweaked in near real-time.
To satisfy this need, we built a system called Stormcrow, which allows us to edit and deploy “feature gates.” A feature gate is a configurable code path that calls out to Stormcrow to determine how to proceed. Typical code usage looks like this:
# Here we are in some Dropbox Python code.
# We need to decide whether to show a red button or a blue button to the user.
# Let's ask Stormcrow!
variant = stormcrow.get_variant("feature_x", user=the_user)
if variant == "RED_BUTTON":
show_red_button()
elif variant == "BLUE_BUTTON"
show_blue_button()
else:
show_default_button()Stormcrow feature gates
- Are rolled out to production within 10 minutes of being changed.
- Can be used across all Dropbox systems, from low-level infrastructure to product features on web, desktop or mobile.
- Provide advanced targeting capabilities, including the ability to segment users based on data in our analytics warehouse.
Building a one-size-fits-all feature gating system like this is tricky, because it needs to be expressive enough to handle all the different use-cases we throw at it on a daily basis yet robust enough to handle Dropbox-scale traffic. The rest of this blog post will describe how the system works and some of our lessons from building it.
Example
Suppose we wanted to run an A/B test to see what button colors are preferred by German users. And further suppose we already know that English speakers prefer blue buttons. In the Stormcrow UI, we might configure the feature like this:
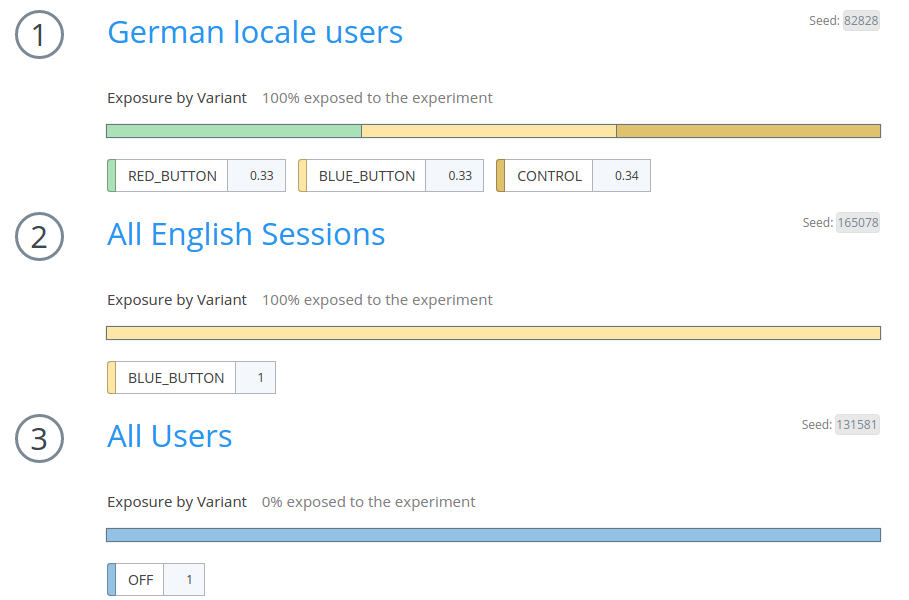
This shows that “German locale users” will be exposed at a rate of 33% RED_BUTTON , 33% BLUE_BUTTON , and 34% CONTROL , and English sessions are set to 100% BLUE_BUTTON. But all other users will receive OFF .
Notice that you can use heterogeneous population types in a given feature: the example uses both a “user” population and a “session” population—the former represents logged-in users only, while the latter represents any visit to our site.
Stormcrow features are built using a sequence of populations which are matched using a fall-through system: first we try to match population 1, and if we fail we fall through to population 2, and so on. As soon as we match a population, we pick a variant to show the user according to the chosen variant mix for that population.
It’s important to note that the variant assignment is stateless. It is randomized by hashing the user’s ID with a seed (the small gray box in the top right). Advanced Stormcrow users can even manipulate the seed to accomplish special behaviors. For example, if you want two different features to assign users the exact same way, you can give them the same seed.
How are populations defined?
- A selector is a code object that’s passed into Stormcrow in order to help it make decisions. We’ve made it so most commonly-used object models can also serve as Stormcrow selectors; for example, the
userandsessionobjects can both be used as selectors. - A datafield is a piece of code that takes in one or more selectors and extracts a value of a specified type: either a boolean, a date, a number, a set, or a string. Datafields are then combined using a simple rule engine that allows you to perform boolean logic with them.
user_email , taken straight from the code:
@dataField(TYPE.STRING, [SELECTOR_NAMES.USER], "The user's email as a string.")
def user_email(**sel):
return _user(**sel) and _user(**sel).emailThe @dataField decorator specifies that this datafield requires a USER object, and will produce a STRING . It also includes a help string so we can make autogenerated documentation. The actual body of the function simply pulls the user’s email out of the object.
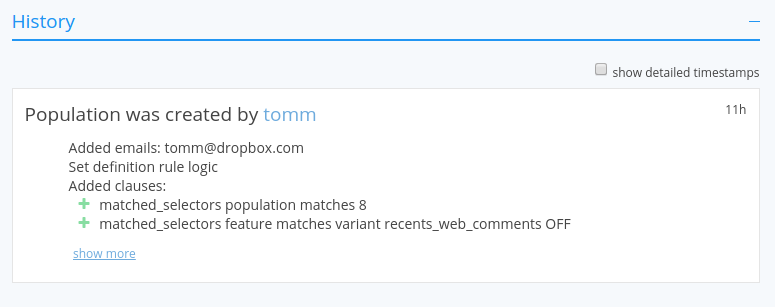
Once a datafield is defined, you can use it in a population. Here’s a population which matches users at Gmail and Yahoo domains, except for a couple of excluded addresses, plus tomm@dropbox.com :

Hive-based populations: connecting to our analytics data warehouse
Even with the ability to create arbitrary datafields, we face one limitation: we can only gate on information that’s accessible to our server code in some way, i.e., present in an already loaded model or in a database we can query efficiently. But there’s another big source of data at Dropbox: our Hive analytics warehouse. Sometimes a Dropboxer wants to select an arbitrary set of users by writing a HiveQL query, which can draw on all kinds of historical logging and analytics data.
Defining a population in this way is an exercise in moving data around. In order for the population definition to be accessible to Stormcrow, we need to move it out of our analytics warehouse and into a scalable datastore that’s query-able from production code. To do this, we built a data pipeline that runs every day and exports the full set of Hive-based populations for that day into production.
The main disadvantage of this kind of approach is data lag. Unlike a datafield, which always produces up-to-the-minute data, populations based on Hive exports only update on a daily basis. (And sometimes slower, if anything goes wrong with the pipeline.) While this is unacceptable for some kinds of gating, it works great for feature gates where populations change slowly. For example, a product launch to a predefined set of beta users is a good candidate for a Hive-based population.
Hive-based populations represent a fundamental trade-off between expressive power and data freshness: performing feature gating on complex analytics data incurs more lag and data engineering work than gating on commonly accessed data.
Derived populations: building complex populations out of simpler ones
One of Stormcrow’s most powerful features is its ability to define populations not only in terms of rules or queries like above, but also in terms of other populations and features. We call these derived populations. For example, here’s a population that is only matched when a) we match the “Android devices” population and b) we receive variant OFF for the feature recents_web_comments.
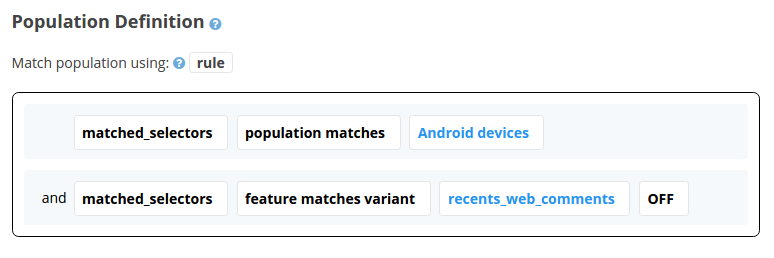
This capability solves the problem of complicated rule configurations being copied and pasted again and again throughout the tool. Instead, feature gating at Dropbox aims to build a core set of basic populations, which can be mixed and matched to produce arbitrarily complex targeting. We’ve found in practice that designing derived population hierarchies is very similar to refactoring code.
In fact, you can look at derived populations as a way to replace coded “if” statements to choose between experiments. Rather than write logic of the form “if user is in Experiment A show them thing A, otherwise if they’re in not in Experiment A but are in Experiment B show them thing B…” you can express these relationships directly in the Stormcrow UI.
Selector inferring: making the API easier to use by magically inferring additional information
Like any complicated software system, Dropbox has a number of internal models used in our code. For example, the user model represents a single user account, and the team model represents a Dropbox Business team. The identity model is how we represent paired accounts: it ties together a personal plus a business user model into a single object. All of our models are connected via various one-to-many and many-to-one relationships.
In Dropbox product code, we typically have access to one or more of these models. For developer convenience, it’s nice if Stormcrow understands our model relationships well enough to “infer” extra selectors automatically. For example, a developer may have access to a user object u and want to query some feature which is gated on team information. While they could write
variant = stormcrow.get_variant("team_related_feature", user=u, team=u.get_team())it is much more convenient if Stormcrow can fill in the details automatically, so the developer only needs to write
variant = stormcrow.get_variant("team_related_feature", user=u)
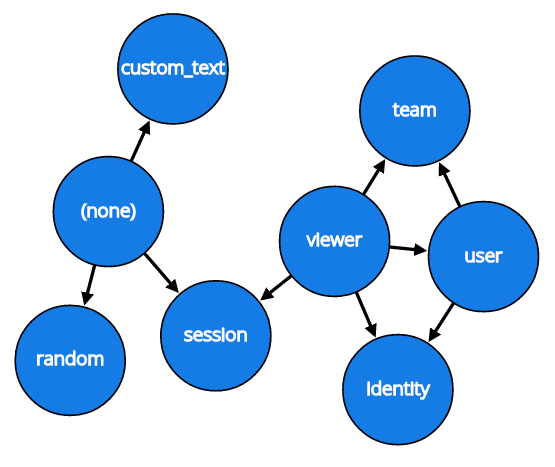
In Stormcrow we represent Dropbox’s model relationships as a graph which we call the selector inferring graph. In this graph, each node is a model type, and an edge from node A to node B means that we can infer model B from model A. When a Stormcrow call happens, the first thing we do is take the selectors we were given and compute their transitive closure in this graph.
Of course, inferring may introduce a performance cost in the form of extra computation or network calls. To make it more efficient, inferring produces thunks, which are lazily evaluated so that we only compute them if a selector is actually needed to make a gating decision. (See the “Performance dangers” section below for more on the risks of Stormcrow making network calls.)
Here’s our actual selector inferring graph. Each node represents a selector type that Stormcrow knows about. For example, we can see that viewer is a very handy model to have, because we can use it to infer session , team , user , and identity . In addition, the special node (none) represents selectors that can be auto-inferred from “thin air”: for example, the session is always auto-inferred in our server code, so there’s no need to pass any selectors to use it.
Deployment: web and internal infrastructure
If you have a large fleet of production servers, how should the feature gating configuration be deployed to them? Keeping feature gating information in a database is the obvious answer, but then you need a network call to retrieve it. Given that there may be a large number of feature gates evaluated on a typical page load on dropbox.com, this can result in a huge numbers of configuration fetches against the database. Even if you mitigate these problems with a carefully designed caching system (using local caching + memcached, for example), the database becomes a single point of failure for the system.
Instead, we deploy a JSON file called stormcrow_config.json to all of our production servers. This deployment simply uses our internal push system and is pushed every time a change is made to Stormcrow configuration.
All of our servers run a background thread called the “Stormcrow loader” which constantly watches the stormcrow_config.json copy on disk, reloading it when it changes. This allows Stormcrow to reload without interruption to the server.
If the configuration file is not found for some reason, Stormcrow has the ability to fall back to direct database access—but this is highly frowned upon for any system that might produce nontrivial amounts of traffic.
Deployment: desktop and mobile
Feature gating on the desktop and mobile platforms is a little different. For these clients, it makes more sense for them to batch request feature and variant information. When they request Stormcrow information from our backend, they receive information like the following:
{
"feature_a": "VARIANT_X",
"feature_b": "OFF",
"feature_c": "CONTROL",
...
}Monitoring
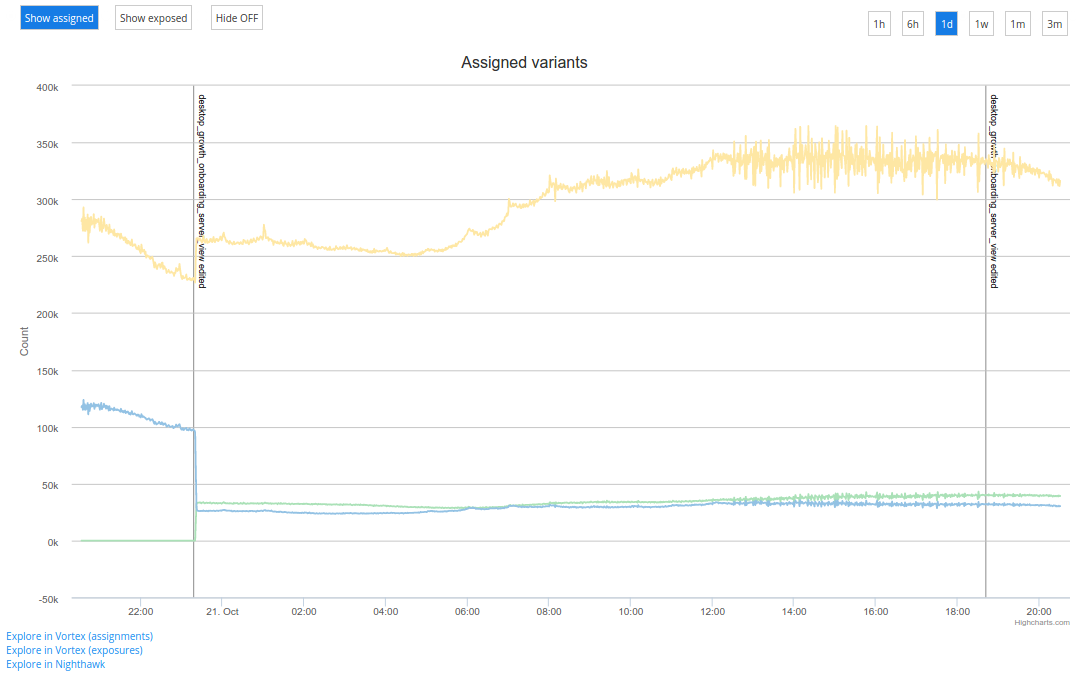
Users can also click the links at the bottom to drill into the data in more detail, using our in-house tool Vortex or other data exploration tools.
Performance dangers
Because of Stormcrow’s modular datafield design, it’s possible for people at Dropbox to write datafields that are not performant. Often this is done with the best of intentions: someone creates a new datafield which is perfectly safe for their small use-case, but could be used by someone else to send huge amounts of traffic toward a fragile system.
This has taught us an important lesson: avoid database calls or other I/O in the feature gating system!
Instead, one should pass as much information into the system from the caller as possible. This puts the performance onus on the caller, and makes I/O more predictable: if the caller always does the I/O no matter what, then a Stormcrow edit can’t change the performance characteristics of the code.
In an ideal world, Stormcrow would be completely “pure” (in the functional programming sense) and would not perform any I/O at all. We haven’t been able to do this yet for practical reasons: sometimes the necessity of providing a convenient API for the caller means that Stormcrow needs to do some of its own heavy lifting. Sometimes you want to gate on information that lives a database call away, so it makes sense to have the capability to (safely) do this. It helps to have a highly scalable data store like Edgestore around for such tasks.
Auditing challenges
Feature gates are awkward because they aren’t checked into version control: instead, they are a separate piece of state which can change independently of your code. Code pushes at Dropbox happen in a predictable fashion via our “daily push” system (for our backend), or via the release processes for the desktop or mobile platforms. But feature gate edits, by their very nature, can happen at any hour of the day or night. So, it’s important to have good auditing tools so we can track feature-gating related regressions down as fast as possible.
Stormcrow tackles this in the following ways: providing full audit history and by tracking features in our codebase with static analysis.
Audit history is simple enough: we just show a “news feed” style view of all edits to a given feature and population. This feed shows all edits that could affect the given item, including edits to transitive dependencies (which can arise through derived populations).
- A list of all occurrences of the feature in the current master branch.
- A “historical view”, showing the commit hashes where the feature entered and/or exited our codebase.
can_see_weathervane :
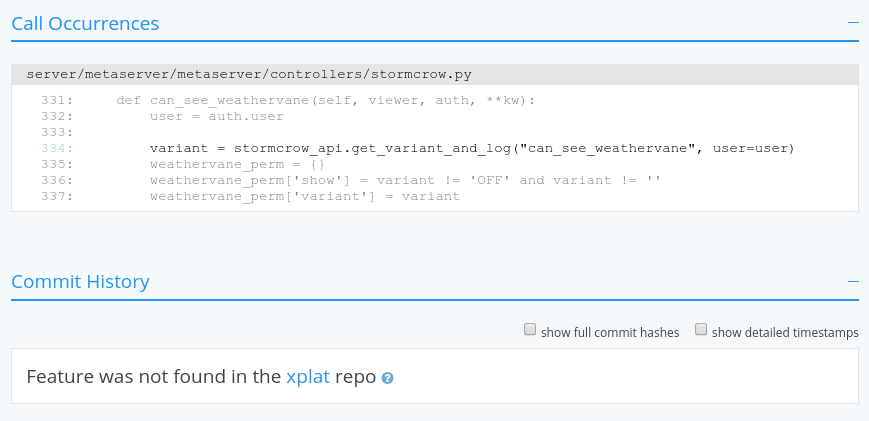
The static analyzer also performs the important task of making sure the most common variant found in our production code matches up with what our unit tests are testing. It knows how to send “nag" emails to feature owners about this and other issues, such as stale features that aren’t used anymore and should be removed from the codebase.
These tools make it straightforward to track down how a given feature affects our code.
QA and Testing
For manual testing of our features, Stormcrow supports “overrides.” Overrides allow Dropboxers to temporarily put themselves into any feature or population. We also have a notion of “datafield overrides,” which allow you to change a single datafield value. For example, you can force your locale to be German in order to test the German experience.
For unit tests, we run a mock Stormcrow where every feature is given a “default” variant to use in tests. Stormcrow variants can also be overridden by any test. We even have special decorators to say “make sure this test passes under all possible variants.”
Conclusion
Providing a unified feature gating service at Dropbox’s scale involves lots of considerations, from infrastructure issues like data fetching and configuration management all the way up to UI and tooling. We hope this post is useful to people working on their own feature gating systems.
Does your company’s handle feature gating differently? Please let us know in the comments!
Thanks to the following people for help on this post: Mor Katz, Christopher Park, Lee Sheng, Kevin Zhou, Taylor McIntyre.
P.S. Why is this system called Stormcrow? Because this system replaced our previous feature-gating system, which was called Gandalf (“You shall not pass!”). The Lord of the Rings fans will recognize “Stormcrow” as one of Gandalf’s many names. Plus we had a bird thing going on for internal project names at the time.


