

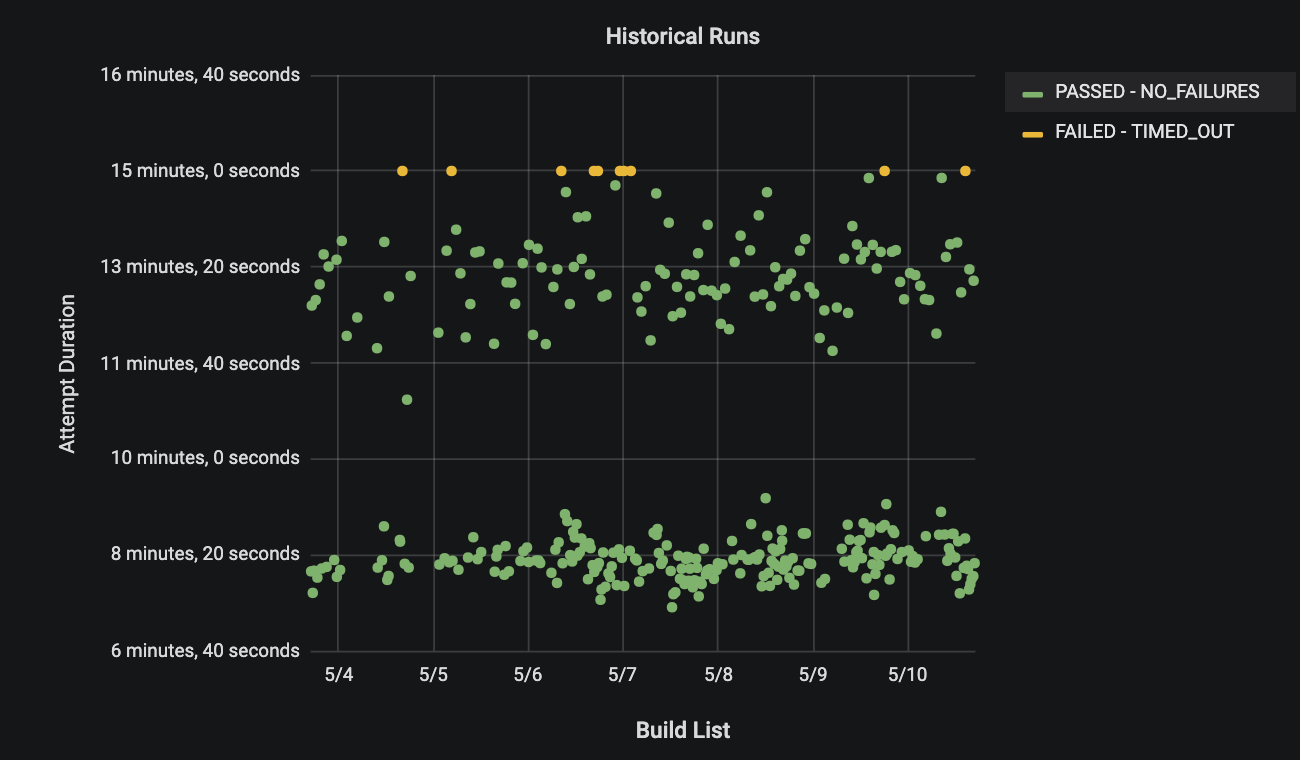
At Dropbox, we run more than 35,000 builds and millions of automated tests every day. With so many tests, a few are bound to fail non-deterministically or “flake.” Some new code submissions are bound to break the build, which prevents developers from cutting a new release. At this scale, it’s critical we minimize the manual intervention necessary to temporarily disable flaky tests, revert build-breaking commits, and notify test owners of these issues. We built a system called Athena to manage build health and automatically keep the build green.
What we used to do
To ensure basic correctness, all code at Dropbox is subjected to a set of pre-submit tests. A larger suite of end-to-end tests, like Selenium/UI tests, which are too flaky, slow, and costly to test before code changes are only run after code lands on the master branch, and we call these “post-submit” tests. We require both pre-submit and post-submit tests to pass to cut a new release.
To keep the build green, we initially established a rotation which reverted commits that broke post-submit tests and temporarily disabled, or “quarantined” flaky tests. Over time, the operational load of that rotation became too high, and we distributed the responsibility to multiple teams which all felt the burden of managing build health. Also, ineffective manual intervention to quarantine flaky tests made pre-submit testing a slow, frustrating experience. So we started brainstorming for a sustainable solution.
Enter Athena
We landed on a new service, called Athena, which manages the health of our builds and requires minimal human intervention.
Athena reduces the human effort required to keep the build green by:
- Identifying commits that make a test deterministically fail, and notifying the author to revert the commit
- Identifying tests that are flaky and unreliable, and automatically quarantining them
What makes this tricky?
It can be challenging to determine whether a single test failure is a deterministic breakage or a spurious failure. Ultimately, a test is arbitrary user code, and tests can fail in various ways. The three main classes of non-deterministic test failures we see are non-hermetic tests, flaky tests, and infrastructural flakiness.
Non-hermetic tests
Hermetic tests only use declared dependencies and have no dependencies outside the build and test environment, which make their results reproducible.
A few tests at Dropbox depend on external resources that are hard to fake, like time. We often see tests that start failing when it’s a new UTC day, or at the end of every month. For example, code that tests whether a particular discount is valid starts failing after the discount expires. We call these environmental failures.
We mitigate these by keeping track of the latest “stable” commit, one where all tests have passed. Every time a new commit has all tests passing, we mark that commit as stable. If a test fails when run on a stable commit, it can indicate non-hermetic behavior or an environmental failure.
Flaky tests
Flaky tests are tests that behave non-deterministically with no change in input. Potential sources of non-determinism are dependence on random numbers, thread scheduling, improperly selected timeouts, and concurrency. With flaky tests, it’s impossible to say with 100% confidence whether a commit truly broke a test.
We mitigate this by retrying the same test up to ten times, and if the result isn’t consistent across the runs, we’re confident that the test is exhibiting a flake. We settled on ten retries after some experimentation.
Infrastructural flakiness
We have done a lot of work over the years to ensure that our tests have reliable resource guarantees so that their behavior is consistent. We run tests in a container, give them consistent CPU and memory via resource quotas, and do CPU and NUMA pinning. Unfortunately, with a thousand node cluster, we’re bound to have performance variations and straggling hosts.
The most common case of infrastructural flakiness we see is a test timing out on a poorly performing host. We mitigate this by retrying the test on a different host.
How does Athena work?
To apply the mitigations listed above, we created a service, Athena, that watches test results, reruns failing tests to identify if they’re flaky or broken, and takes actions like quarantine.
Athena watches test results for all new code submissions and marks tests that fail more than once within a few hours in post-submit testing as “noisy”, which is a temporary state while the system is unsure if the test failures are flakes, infrastructural, or a breakage.
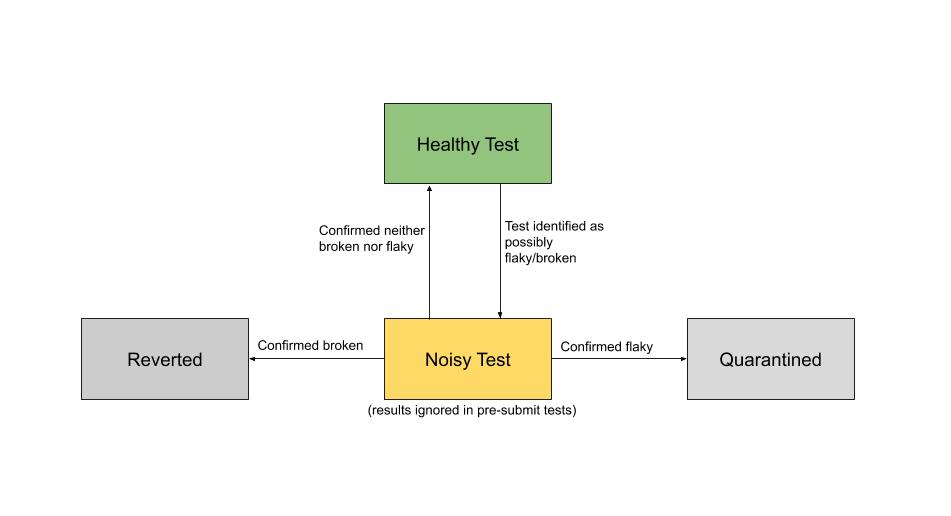
Flake Detection
To determine whether a test is flaky, we rerun it on a commit where it has passed before. The test is quarantined if it flaps from passing to failing across multiple hosts. To deal with environmental failures, the test is rerun on the latest stable commit.
Breakage Detection
Breakage detection is more involved. For every noisy test, we run a bisect to find a potential transition point where the test went from pass to fail, and we rerun the test there ten times to confirm it’s truly broken and not just flaky.
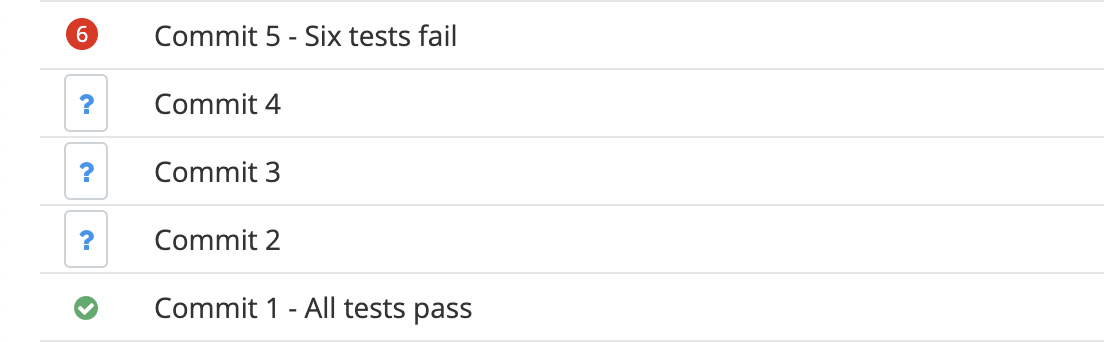
def find_offending_commit(test, commits, latest_stable_commit):
# commits where the test might have transitioned from pass to fail
potential_transition_points = []
for commit in reversed(commits):
if is_test_failing(test, commit) or is_test_unknown(test, commit):
potential_transition_points.append(commit)
else:
# if we see a pass, we're guaranteed not to have broken the commit before
# this point
break
if not potential_transition_points:
return NoIssues() # the test isn't broken
if len(potential_transition_points) == 1:
# potential culprit
commit = potential_transition_points[0]
# deflake the test: run it 10 times to confirm it's broken
is_failure = trigger_test(test, commit, deflake_num_runs=10)
if not is_failure:
return NoIssues() # just a flake
# rerun on the stable commit to confirm it's not environmental issues
is_failure = trigger_test(test, latest_stable_commit)
if not is_failure:
return Breakage(test=test, commit=commit)
# bisect logic
midpoint = (len(potential_transition_points) / 2) - 1
middle = potential_transition_points[midpoint]
is_failure = is_test_failing(test, middle, run_if_unknown=True)
# run bisect with a limited set
if is_failure:
new_candidates = potential_transition_points[:midpoint+1]
else:
new_candidates = potential_transition_points[midpoint+1:]
return find_offending_commit(test, new_candidates, latest_stable_commit)
How did it work out?
We’ve been running Athena for a few months in production now, and we’ve doubled the number of test quarantines and removed the need for manual test quarantines from our team.
Operational Overhead
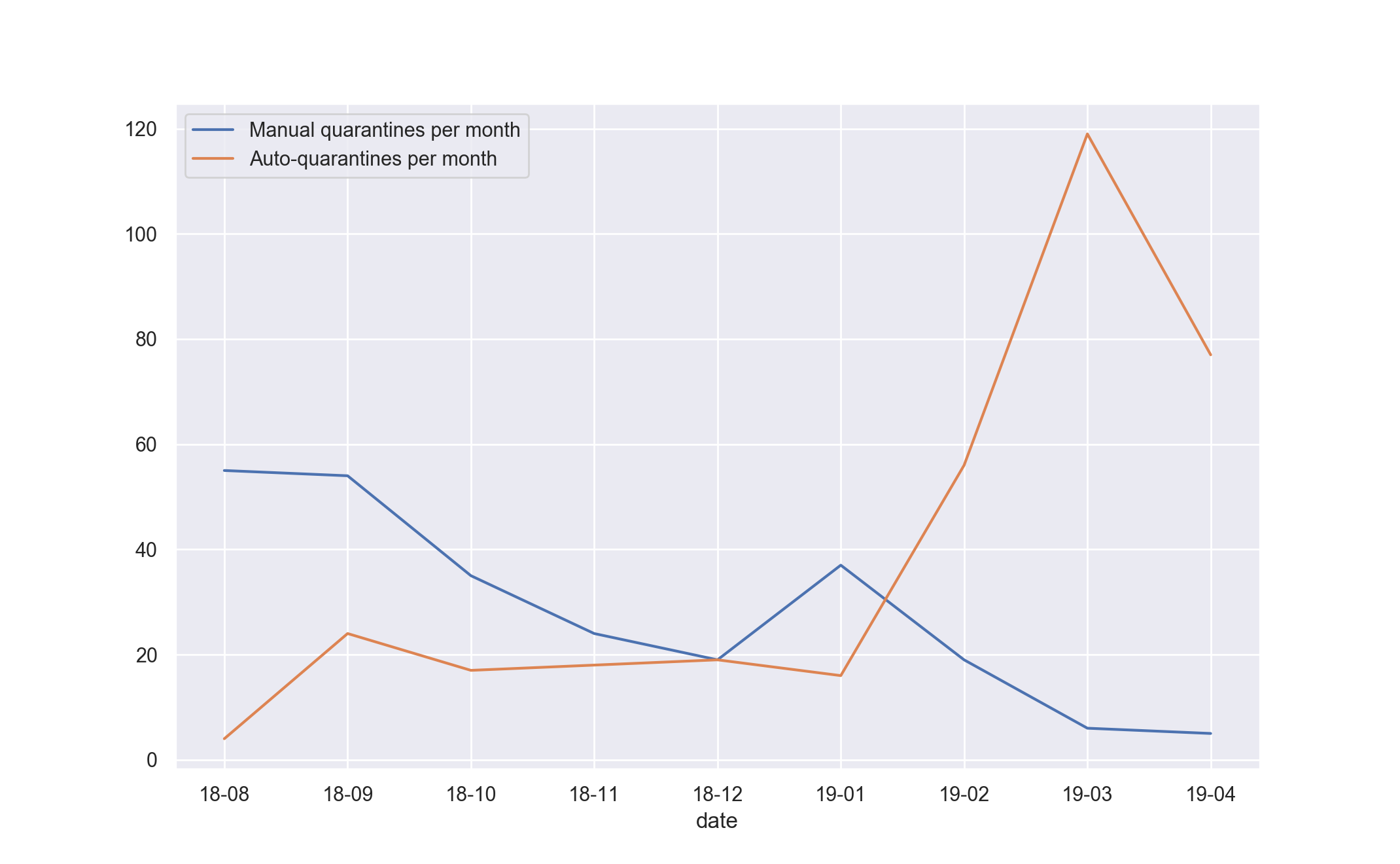
We quarantine much more aggressively than we ever have, which might be alarming. In reality, this is required to keep pre-submit tests free from spurious flakes and applies a consistent quality bar to all of our tests.
Athena doesn’t auto-revert commits, but it sends a message to the author and the team that owns the test suite. While reverting would be simple to automate, getting the build back to stable is not time sensitive (since broken test results are ignored in pre-submit) and might interfere with a forward fix for a critical issue, so we skipped that for now.
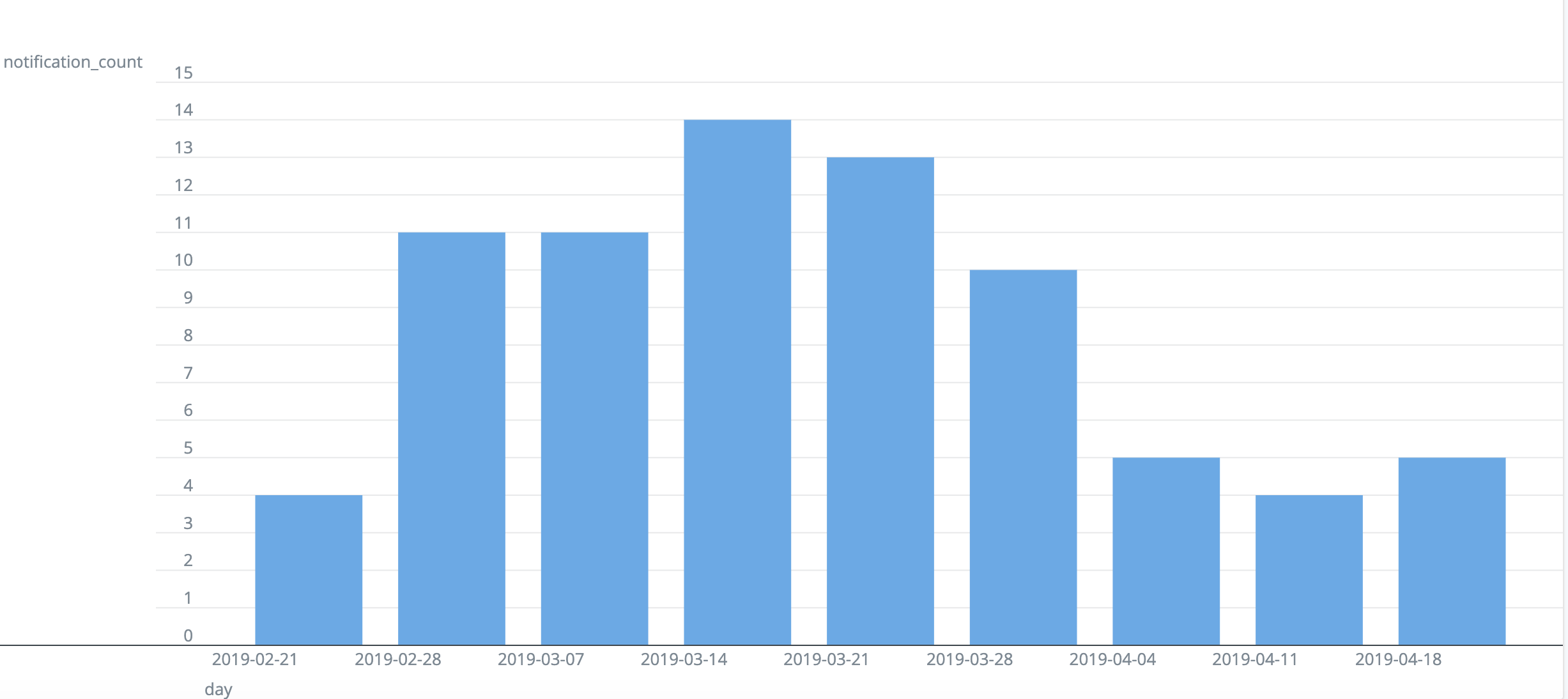
Capacity
We used to automatically run our most expensive tests (such as Selenium UI tests) on most commits to make it easy for humans to identify breakages. Athena allowed us to experiment with “rate limiting” these, instead running the test suite at most once every ten minutes.
However, this meant that teams lost the ability to visually scan and quickly find commits that broke a test. Additionally, Athena didn’t expose any information about its progress, which led to lack of trust in the system (“is it actually doing anything?”).
To resolve the issue, we added a simple UI to visualize progress. This helped the developers know that Athena is chugging along. This also made Athena self serve, which reduced support load on us.
Rate limiting ensures that capacity use in continuous integration (CI) grows slowly, and reduces the spikiness in demand for hosts in peak hours. Overall, we reduced our testing cluster size by ~8%.
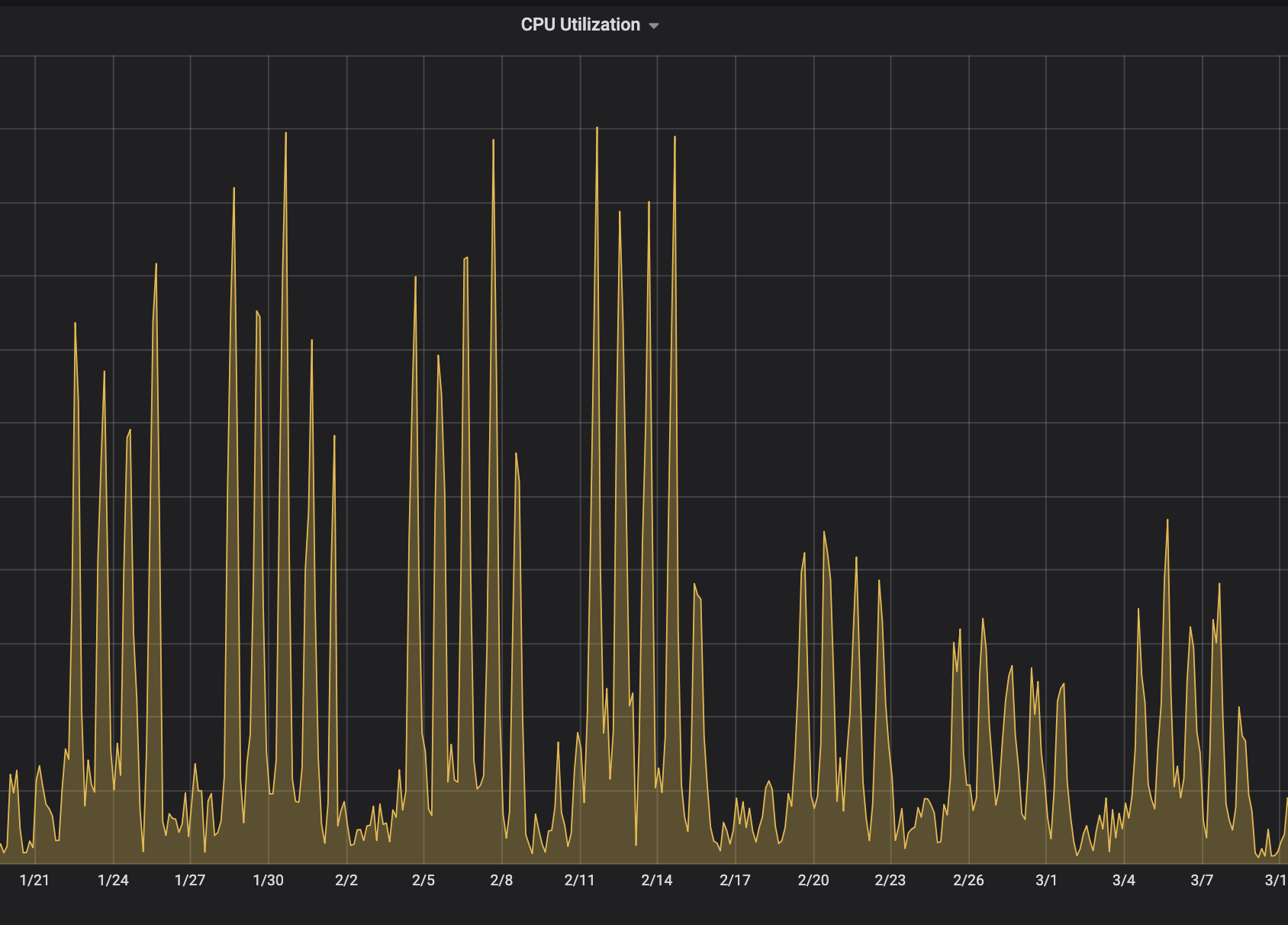
What’s next?
We have not yet applied Athena to our desktop tests, so we plan to do that next. This will involve understanding new failure modes, such as different OSs and their variants.
For breakage detection, even though we do a bisect today, some clusters have enough spare capacity that we can do an “n-sect” to run tests across all possible transition points in parallel to catch breakages faster.
Finally, we want to experiment with auto-revert if the build has stayed broken for a few hours since in theory that should not interfere with a critical fix.
Conclusion
CI enables our organization to release quickly and safely, but it can also impose work for managing the build, frustration due to flaky pre-submit failures, and significant machine costs. Simple automation like Athena helps significantly cut down on those costs.
What we learned:
- Keep notifications high-signal (accurate): It’s very easy to spam developers with inaccurate or un-actionable notifications that they will be trained to ignore. High-signal notifications help keep trust in the system high and drive manual action
- Automation helps reduce bikeshedding: Just as formatters like
gofmthelp avoid debates about code style, automation for quarantine helps maintain a high bar of test quality in our test suites, without debate as to what warrants quarantining and why - Indicate progress for long running actions: Any long running, asynchronous workflow requires some kind of indication that it’s not stuck, helping to reduce user confusion, and maintain trust that the system is doing its job
Credits
A lot of the ideas here come from Facebook’s talk at GTAC 2014. Special thanks to Roy Williams for this talk, which inspired us to build our auto-quarantine and noisy test ignoring system and taught us the power of automation to reduce bikeshedding.
This work wouldn’t be possible without the various papers and constant support from John Micco, who helped us with the design of the breakage detection system, and the CI primitives required to make this a reality.
Also, thanks to our ex-intern Victor Ling, who built the first prototype of Athena, and George Caley, who added significant features like ignoring noisy tests in pre-submit, auto-quarantine, and the simplified UX.
Are you interested in working on Developer Infrastructure at scale? We’re hiring!


