

Dropbox, to our customers, needs to be a reliable and responsive service. As a company, we’ve had to scale constantly since our start, today serving more than 700M registered users in every time zone on the planet who generate at least 300,000 requests per second. Systems that worked great for a startup hadn’t scaled well, so we needed to devise a new model for our internal systems, and a way to get there without disrupting the use of our product.
In this post, we’ll explain why and how we developed and deployed Atlas, a platform which provides the majority of benefits of a Service Oriented Architecture, while minimizing the operational cost that typically comes with owning a service.
Monolith should be by choice
The majority of software developers at Dropbox contribute to server-side backend code, and all server side development takes place in our server monorepo. We mostly use Python for our server-side product development, with more than 3 million lines of code belonging to our monolithic Python server.
It works, but we realized the monolith was also holding us back as we grew. Developers wrangled daily with unintended consequences of the monolith. Every line of code they wrote was, whether they wanted or not, shared code—they didn’t get to choose what was smart to share, and what was best to keep isolated to a single endpoint. Likewise, in production, the fate of their endpoints was tied to every other endpoint, regardless of the stability, criticality, or level of ownership of these endpoints.
In 2020, we ran a project to break apart the monolith and evolve it into a serverless managed platform, which would reduce code tangles and liberate services and their underlying engineering teams from being entwined with one another. To do so, we had to innovate both the architecture (e.g. standardizing on gRPC and using Envoy’s gRPC-HTTP transcoding) and the operations (e.g. introducing autoscaling and canary analysis). This blog post captures key ideas and learnings from our journey.
Metaserver: The Dropbox monolith
Dropbox’s internal service topology as of today can be thought of as a “solar system” model, in which a lot of product functionality is served by the monolith, but platform-level components like authentication, metadata storage, filesystem, and sync have been separated into different services.
About half of all commits to our server repository modify our large monolithic Python web application, Metaserver.
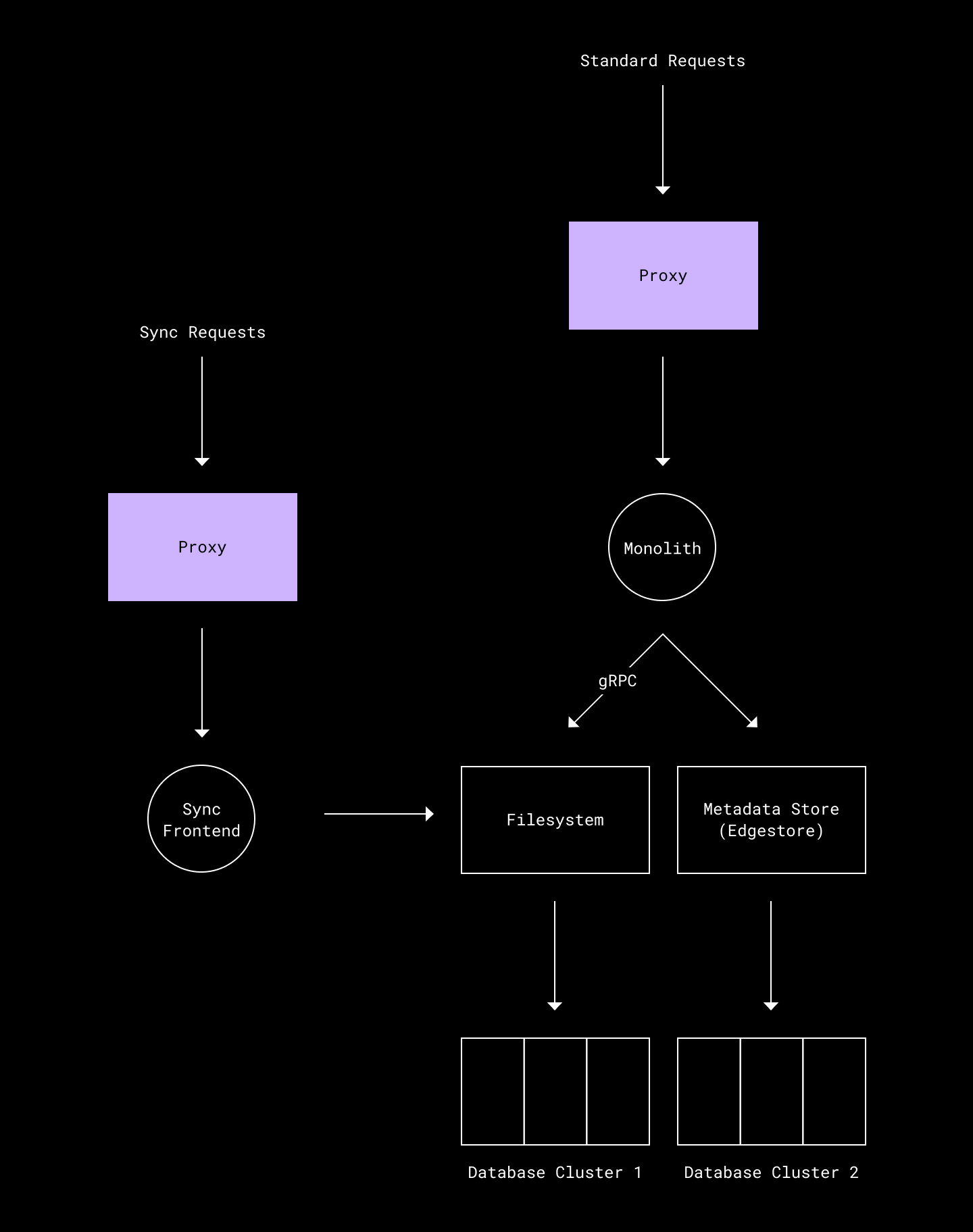
Extremely simplified view of existing serving stack
Metaserver is one of our oldest services, created in 2007 by one of our co-founders. It has served Dropbox well, but as our engineering team marched to deliver new features over the years, the organic growth of the codebase led to serious challenges.
Tangled codebase
Metaserver’s code was originally organized in a simple pattern one might expect to see in a small open source project—library, model, controllers—with no centralized curation or guardrails to ensure the sustainability of the codebase. Over the years, the Metaserver codebase grew to become one of the most disorganized and tangled codebases in the company.
//metaserver/controllers/ …
//metaserver/model/ …
//metaserver/lib/ …Metaserver Code Structure
Because the codebase had multiple teams working on it, no single team felt strong ownership over codebase quality. For example, to unblock a product feature, a team would introduce import cycles into the codebase rather than refactor code. Even though this let us ship code faster in the short term, it left the codebase much less maintainable, and problems compounded.
Inconsistent push cadence
We push Metaserver to production for all our users daily. Unfortunately, with hundreds of developers effectively contributing to the same codebase, the likelihood of at least one critical bug being added every day had become fairly high. This would necessitate rollbacks and cherry picks of the entire monolith, and caused an inconsistent and unreliable push cadence for developers. Common best practices (for example, from Accelerate) point to fast, consistent deploys as the key to developer productivity. We were nowhere close to ideal on this dimension.
Inconsistent push cadence leads to unnecessary uncertainty in the development experience. For example, if a developer is working towards a product launch on day X, they aren’t sure whether their code should be submitted to our repository by day X-1, X-2 or even earlier, as another developer’s code might cause a critical bug in an unrelated component on day X and necessitate a rollback of the entire cluster completely unrelated to their own code.
Infrastructure debt
With a monolith of millions of lines of code, infrastructure improvements take much longer or never happen. For example, it had become impossible to stage a rollout of a new version of an HTTP framework or Python on only non-critical routes.
Additionally, Metaserver uses a legacy Python framework unused in most other Dropbox services or anywhere else externally. While our internal infrastructure stack evolved to use industry standard open source systems like gRPC, Metaserver was stuck on a deprecated legacy framework that unsurprisingly had poor performance and caused maintenance headaches due to esoteric bugs. For example, the legacy framework only supports HTTP/1.0 while modern libraries have moved to HTTP/1.1 as the minimum version.
Moreover, all the benefits we developed or integrated in our internal infrastructure, like integrated metrics and tracing, had to be hackily redone for Metaserver which was built atop different internal frameworks.
Over the past few years, we had spun up several workstreams to combat the issues we faced. Not all of them were all successful, but even those we gave up on paved the way to our current solution.
SOA: the cost of operating independent services
We tried to break up Metaserver as part of a larger push around a Service Oriented Architecture (SOA) initiative. The goal of SOA was to establish better abstractions and separation of concerns for functionalities at Dropbox—all problems that we wanted to solve in Metaserver.
The execution plan was simple: make it easy for teams to operate independent services in production, then carve out pieces of Metaserver into independent services.
Our SOA effort had two major milestones:
- Make it possible and easy to build services outside of Metaserver
- Extract core functionalities like identity management from the monolith and expose them via RPC, to allow new functionalities to be built outside of Metaserver
- Establish best practices and a production readiness process for smoothly and scalably onboarding new multiple services that serve customer-facing traffic, i.e. our live site services
- Break up Metaserver into smaller services owned and operated by various teams
The SOA effort proved to be long and arduous. After over a year and a half, we were well into the first milestone. However, the experience from executing that first milestone exposed the flaws of the second milestone. As more teams and services were introduced into the critical path for customer traffic, we found it increasingly difficult to maintain a high reliability standard. This problem would only compound as we moved up the stack away from core functionalities and asked product teams to run services.
No one solution for everything
With this insight, we reassessed the problem. We found that product functionality at Dropbox could be divided into two broad categories:
- large, complex systems like all the logic around sharing a file
- small, self-contained functionality, like the homepage
For example, the “Sharing” service involves stateful logic around access control, rate limits, and quotas. On the other hand, the homepage is a fairly simple wrapper around our metadata store/filesystem service. It doesn’t change too often and it has very limited day to day operational burden and failure modes. In fact, operational issues for most routes served by Dropbox had common themes, like unexpected spikes of external traffic, or outages in underlying services.
This led us to an important conclusion:
- Small, self contained functionality doesn’t need independently operated services. This is why we built Atlas.
- It’s unnecessary overhead for a product team to plan capacity, set up good alerts and multihoming (automatically running in multiple data centers) for small, simple functionality. Teams mostly want a place where they can write some logic, have it automatically run when a user hits a certain route, and get some automatic basic alerts if there are too many errors in their route. The code they submit to the repository should be deployed consistently, quickly and continuously.
- Most of our product functionality falls into this category. Therefore, Atlas should optimize for this category.
- Large components should continue being their own services, with which Atlas happily coexists.
- Large systems can be operated by larger teams that sustainably manage the health of their systems. Teams should manage their own push schedules and set up dedicated alerts and verifiers.
Atlas: a hybrid approach
With the fundamental sustainability problems we had with Metaserver, and the learning that migrating Metaserver into many smaller services was not the right solution for everything, we came up with Atlas, a managed platform for the self-contained functionality use case.
Atlas is a hybrid approach. It provides the user interface and experience of a “serverless” system like AWS Fargate to Dropbox product developers, while being backed by automatically provisioned services behind the scenes.
As we said, the goal of Atlas is to provide the majority of benefits of SOA, while minimizing the operational costs associated with running a service.
Atlas is “managed,” which means that developers writing code in Atlas only need to write the interface and implementation of their endpoints. Atlas then takes care of creating a production cluster to serve these endpoints. The Atlas team owns pushing to and monitoring these clusters.
This is the experience developers might expect when contributing to a monolith versus Atlas:
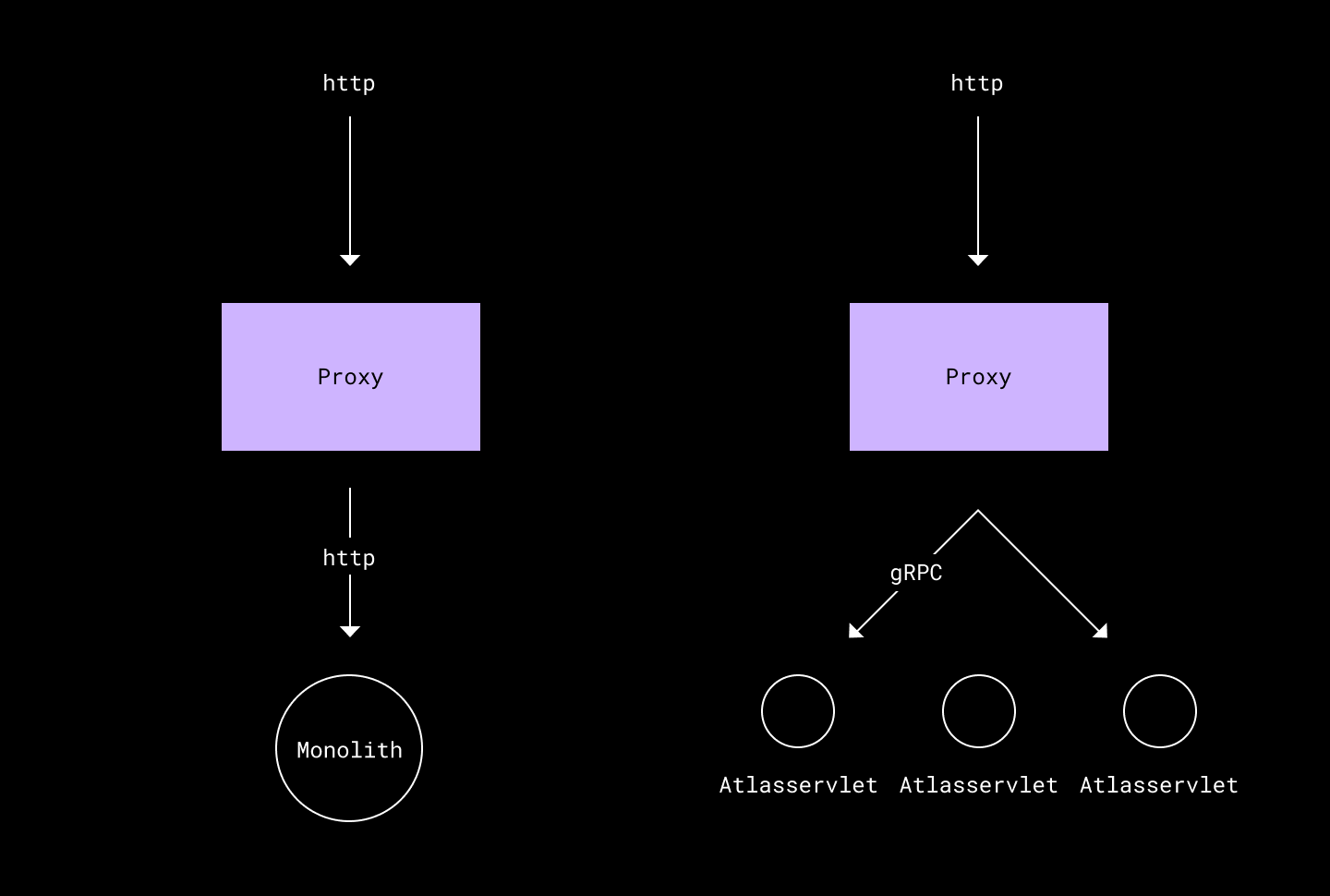
Before and after Atlas
Goals
We designed Atlas with five ideal outcomes in mind:
- Code structure improvements
Metaserver had no real abstractions on code sharing, which led to coupled code. Highly coupled code can be the hardest to understand and refactor, and the most likely to sprout bugs when modified. We wanted to introduce a structure and reduce coupling so that new code would be easier to read and modify. - Independent, consistent pushes
The Metaserver push experience is great when it works. Product developers only have to worry about checking in code which will automatically get pushed to production. However, the aforementioned lack of push isolation led to an inconsistent experience. We wanted to create a platform where teams were not blocked on push due to a bug in unrelated code, and create the foundation for teams to push their own code in the future. - Minimized operational busywork
We aimed to keep the operational benefits of Metaserver while providing some of the flexibility of a service. We set up automatic capacity management, automatic alerts, automatic canary analysis, and an automatic push process so that the migration from a monolith to a managed platform was smooth for product developers. - Infrastructure unification
We wanted to unify all serving to standard open source components like gRPC. We don’t need to reinvent the wheel. - Isolation
Some features like the homepage are more important than others. We wanted to serve these independently, so that an overload or bug in one feature could not spill over to the rest of Metaserver.
We evaluated using off-the-shelf solutions to run the platform. But in order to de-risk our migration and ensure low engineering costs, it made sense for us to continue hosting services on the same deployment orchestration platform used by the rest of Dropbox.
However, we decided to remove custom components, such as our custom request proxy Bandaid, and replace them with open source systems like Envoy that met our needs.
Technical design
The project involved a few key efforts:
Componentization
- De-tangle the codebase by feature into components, to prevent future tangles
- Enforce a single owner per component, so new functionality cannot be tacked onto a component by a non-owner
- Incentivize fewer shared libraries and more code sharing via RPC
Orchestration
- Automatically configure each component into a service in our deployment orchestration platform with <50 lines of boilerplate code
- Configure a proxy (Envoy) to send a request for a particular route to the right service, instead of simply sending each request to a Metaserver node
- Configure services to speak to one another in gRPC instead of HTTP
Operationalization
- Automatically configure a deployment pipeline that runs daily and pushes to production for each component
- Set up automatic alerts and automatic analysis for regressions to each push pipeline to automatically pause and rollback in case of any problems
- Automatically allocate additional hosts to scale up capacity via an autoscaler for each component based on traffic
Let’s look at each of these in detail.
Componentization
Logical grouping of routes via servlets
Atlas introduces Atlasservlets (pronounced “atlas servlets”) as a logical, atomic grouping of routes. For example, the home Atlasservlet contains all routes used to construct the homepage. The nav Atlasservlet contains all the routes used in the navigation bar on the Dropbox website.
In preparation for Atlas, we worked with product teams to assign Atlasservlets to every route in Metaserver, resulting in more than 200 Atlasservlets across more than 5000 routes. Atlasservlets are an essential tool for breaking up Metaserver.
//atlas/home/ …
//atlas/nav/ …
//atlas/<some other atlasservlet>/ …Atlas code structure, organized by servlets
Each Atlasservlet is given a private directory in the codebase. The owner of the Atlasservlet has full ownership of this directory; they may organize it however they wish, and no one else can import from it. The Atlasservlet code structure inherently breaks up the Metaserver code monolith, requiring every endpoint to be in a private directory and make code sharing an explicit choice rather than an unexpected outcome of contributing to the monolith.
Having the Atlasservlet codified into our directory path also allows us to automatically generate production configs that would normally accompany a production service. Dropbox uses the Bazel build system for server side code, and we enforced prevention of imports through a Bazel feature called visibility rules, which allows library owners to control which code can use their libraries.
Breakup of import cycles
In order to break up our codebase, we had to break most of our Python import cycles. This took several years to achieve with a bunch of scripts and a lot of grunt work and refactoring. We prevented regressions and new import cycles through the same mechanism of Bazel visibility rules.
Orchestration
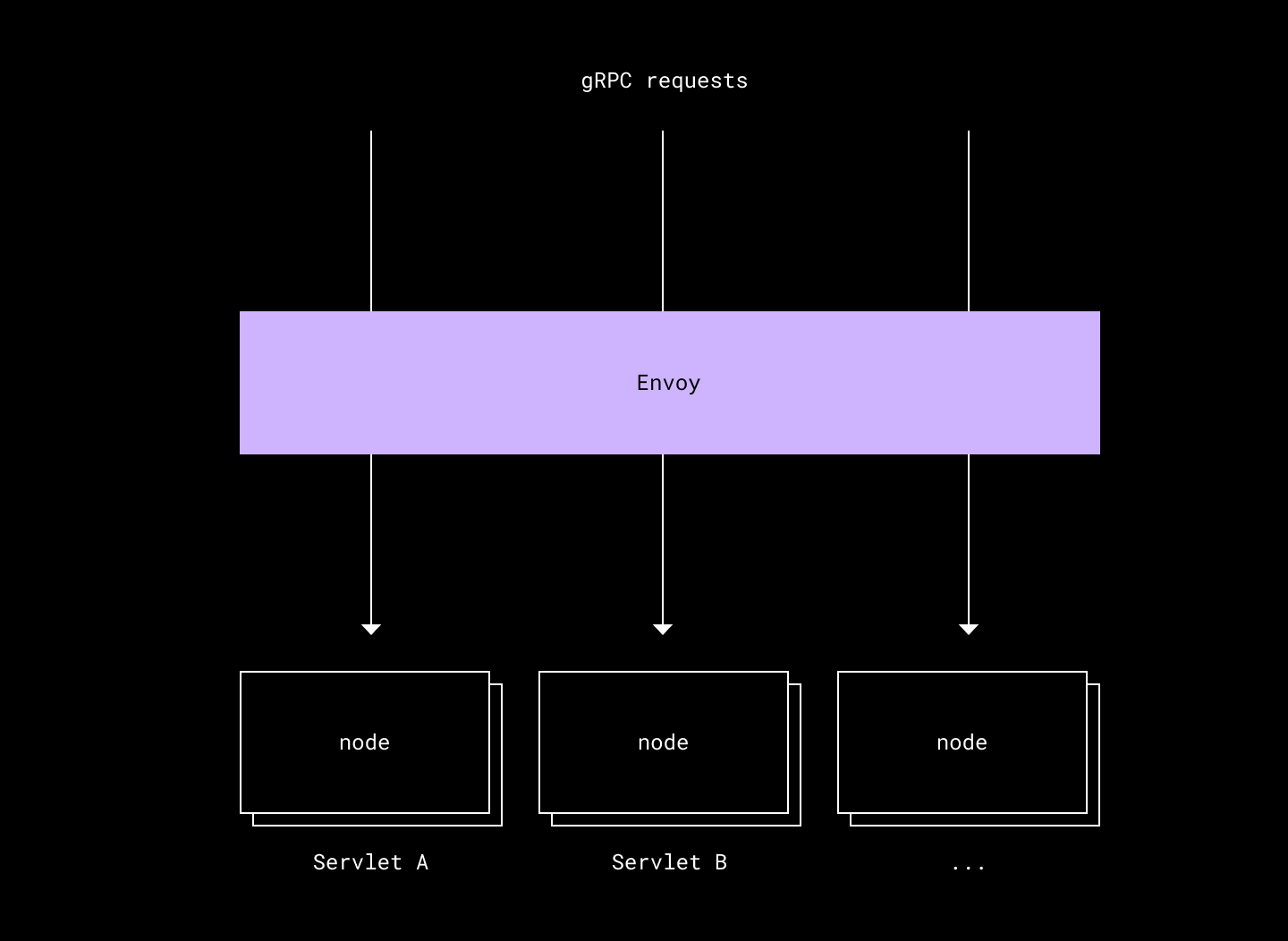
Atlas cluster strategy
In Atlas, every Atlasservlet is its own cluster. This gives us three important benefits:
- Isolation by default
A misbehaving route will only impact other routes in the same Atlasservlet, which is owned by the same team anyway. - Independent pushes
Each Atlasservlet can be pushed separately, putting product developers in control of their own destiny with respect to the consistency of their pushes. - Consistency
Each Atlasservlet looks and behaves like any other internal service at Dropbox. So any tools provided by our infrastructure teams—e.g. periodic performance profiling—will work for all other teams’ Atlasservlets.
gRPC Serving Stack
One of our goals with Atlas was to unify our serving infrastructure. We chose to standardize on gRPC, a widely adopted tool at Dropbox. In order to continue to serve HTTP traffic, we used the gRPC-HTTP transcoding feature provided out of the box in Envoy, our proxy and load balancer. You can read more about Dropbox’s adoption of gRPC and Envoy in their respective blog posts.
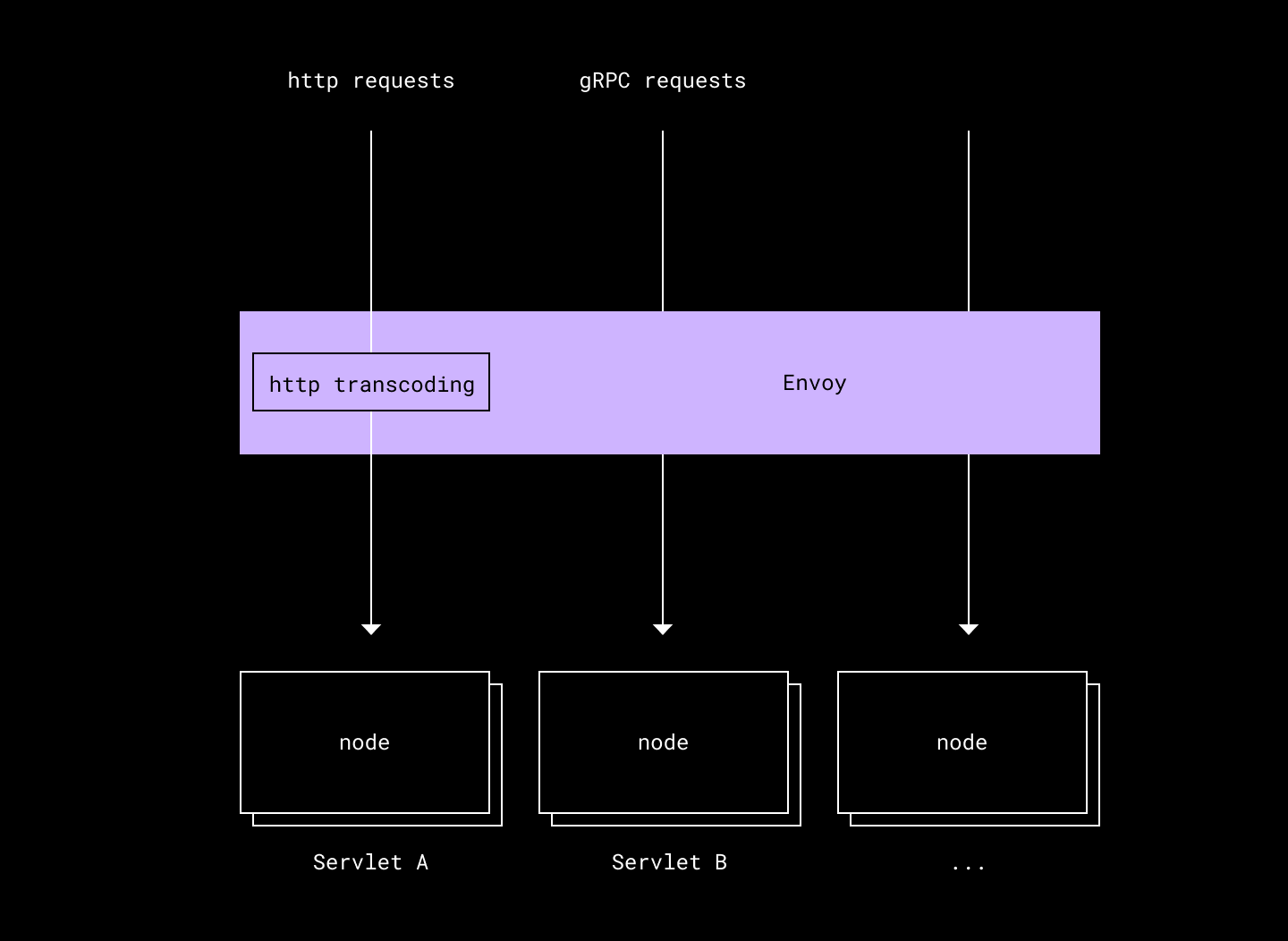
http transcoding
In order to facilitate our migration to gRPC, we wrote an adapter which takes an existing endpoint and converts it into the interface that gRPC expects, setting up any legacy in-memory state the endpoint expects. This allowed us to automate most of the migration code change. It also had the benefit of keeping the endpoint compatible with both Metaserver and Atlas during mid-migration, so we could safely move traffic between implementations.
Operationalization
Atlas’s secret sauce is the managed experience. Developers can focus on writing features without worrying about many operational aspects of running the service in production, while still retaining the majority of benefits that come with standalone services, like isolation.
The obvious drawback is that one team now bears the operational load of all 200+ clusters. Therefore, as part of the Atlas project we built several tools to help us effectively manage these clusters.
Automated Canary Analysis
Metaserver (and Atlas by extension) is stateless. As a result one of the most common ways a failure gets introduced into the system is through code changes. If we can ensure that our push guardrails are as airtight as possible, this eliminates the majority of failure scenarios.
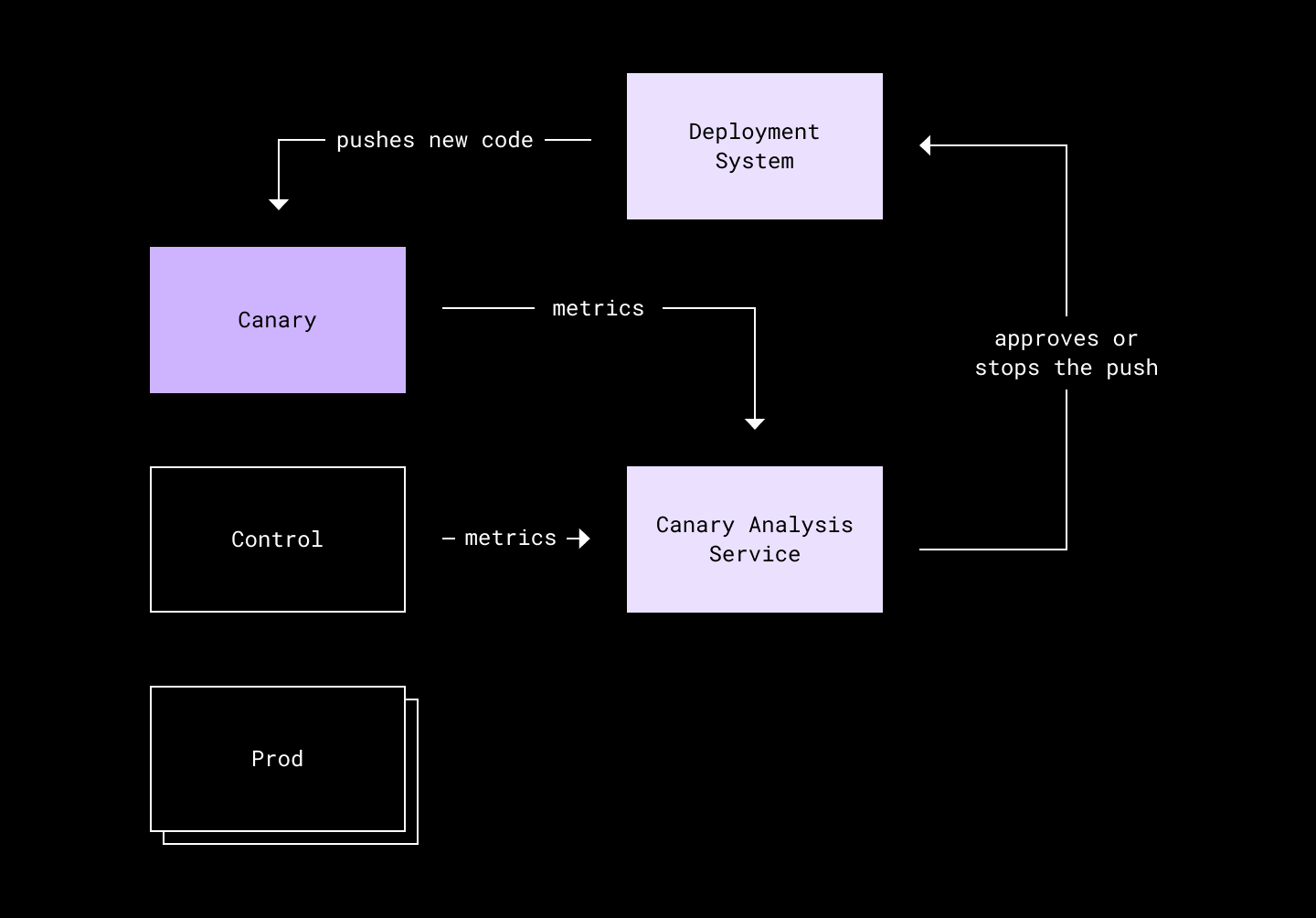
Canary analysis
We automate our failure checking through a simple canary analysis service very similar to Netflix’s Kayenta. Each Atlas service consists of three deployments: canary, control, and production, with canary and control receiving only a small random percentage of traffic. During the push, canary is restarted with the newest version of the code. Control is restarted with the old version of the code but at the same time as canary to ensure the operate from the same starting point.
We automatically compare metrics like CPU utilization and route availability from the canary and control deployments, looking for metrics where canary may have regressed relative to control. In a good push, canary will perform either equal to or better than control, and the push will be allowed to proceed. A bad push will be stopped automatically and the owners notified.
In addition to canary analysis, we also have alerts set up which are checked throughout the process, including in between the canary, control, and production pushes of a single cluster. This lets us automatically pause and rollback the push pipeline if something goes wrong.
Mistakes still happen. Bad changes may slip through. This is where Atlas’s default isolation comes in handy. Broken code will only impact its one cluster and can be rolled back individually, without blocking code pushes for the rest of the organization.
Autoscaling and capacity planning
Atlas's clustering strategy results in a large number of small clusters. While this is great for isolation, it significantly reduces the headroom each cluster has to handle increases in traffic. Monoliths are large shared clusters, so a small RPS increase on a route is easily absorbed by the shared cluster. But when each Atlasservlet is its own service, a 10x increase in route traffic is harder to handle.
Capacity planning for 200+ clusters would cripple our team. Instead, we built an autoscaling system. The autoscaler monitors the utilization of each cluster in real time and automatically allocates machines to ensure that we stay above 40% free capacity headroom per cluster. This allows us to handle traffic increases as well as remove the need to do capacity planning.
The autoscaling system reads metrics from Envoy’s Load Reporting Service and uses request queue length to decide cluster size, and probably deserves its own blog post.
Execution
Stepping stones, not milestones
Many previous efforts to improve Metaserver had not succeeded due to the size and complexity of the codebase. This time around, we wanted to deliver value to product developers even if we didn’t succeed in fully replacing Metaserver with Atlas.
The execution plan for Atlas was designed with stepping stones, not milestones (as elegantly described by former Dropbox engineer James Cowling), so that each incremental step would provide sufficient value in case the next part of the project failed for any reason.
A few examples:
- We started off by speeding up testing frameworks in Metaserver, because we knew that an Atlas serving stack in tests might cause a regression in test times.
- We had a constraint to significantly improve memory efficiency and reduce OOM kills when we migrated from Metaserver to Atlas, since we would be able to pack more processes per host and consume less capacity during the migration. We focused on delivering memory efficiency purely to Metaserver instead of tying the improvements to the Atlas rollout.
- We designed a load test to prove that an Atlas MVP would be able to handle Metaserver traffic. We reused the load test to validate Metaserver’s performance on new hardware as part of a different project.
- We backported workflow simplifications as much as feasible to Metaserver. For example, we backported some of the workflow improvements in Atlas to our web workflows in Metaserver.
- Metaserver development workflows are divided into three categories based on the protocol: web, API, and internal gRPC. We focused Atlas on internal gRPC first to de-risk the new serving stack without needing the more risky parts like gRPC-HTTP transcoding. This in turn gave us an opportunity to improve workflows for internal gRPC independent of the remaining risky parts of Atlas.
Hurdles
With a large migration like this, it’s no surprise that we ran into a lot of challenges. The issues faced could be their own blog post. We’ll summarize a few of the most interesting ones:
- The legacy HTTP serving stack contained quirky, surprising, and hard to replicate behavior that had to be ported over to prevent regressions. We powered through with a combination of reading the original source code, reusing legacy library functions where required, relying on various existing integration tests, and designing a key set of tests that compare byte-by-byte outputs of the legacy and new systems to safely migrate.
- While splitting up Metaserver had wins in production, it was infeasible to spin up 200+ Python processes in our integration testing framework. We decided to merge the processes back into a monolith for local development and testing purposes. We also built heavy integration with our Bazel rules, so that the merging happens behind the scene and developers can reference Atlasservlets as regular services.
- Splitting up Metaserver in production broke many non-obvious assumptions that could not be caught easily in tests. For example, some infrastructure services had hardcoded the identity of Metaserver for access control. To minimize failures, we designed a meticulous and incremental migration plan with a clear understanding of the risks involved at each stage, and slowly monitored metrics as we rolled out the new system.
- Engineering workflows in Metaserver had grown organically with the monolith, arriving at a state where engineers had to page in an enormous amount of context to get the simplest work done. In order to ensure that Atlas prioritizes and solves major engineering pain points, we brought on key product developers as partners in the design, then went through several rounds of iteration to set up a roadmap that would definitively solve both product and infrastructural needs.
Status
Atlas is currently serving more than 25% of the previous Metaserver traffic. We have validated the remaining migration in tests. We’re on a clear path to deprecate Metaserver in the near future.
Conclusion
The single most important takeaway from this multi-year effort is that well-thought-out code composition, early in a project’s lifetime, is essential. Otherwise, technical debt and code complexity compounds very quickly. The dismantling of import cycles and decomposition of Metaserver into feature based directories was probably the most strategically effective part of the project, because it prevented new code from contributing to the problem and also made our code simpler to understand.
By shipping a managed platform, we took a thoughtful approach on how to break up our Metaserver monolith. We learned that monoliths have many benefits (as discussed by Shopify) and blindly splitting up our monolith into services would have increased operational load to our engineering organization.
In our view, developers don’t care about the distinction between monoliths and services, and simply want the lowest-overhead way to deliver end value to customers. So we have very little doubt that a managed platform which removes operational busywork like capacity planning, while providing maximum flexibility like fast releases, is the way forward. We’re excited to see the industry move toward such platforms.
We’re hiring!
If you’re interested in solving large problems with innovative, unique solutions—at a company where your push schedule is more predictable : ) —please check out our open positions.
Acknowledgements
Atlas was a result of the work of a large number of Dropboxers and Dropbox alumni, including but certainly not limited to: Agata Cieplik, Aleksey Kurkin, Andrew Deck, Andrew Lawson, David Zbarsky, Dmitry Kopytkov, Jared Hance, Jeremy Johnson, Jialin Xu, Jukka Lehtosalo, Karandeep Johar, Konstantin Belyalov, Ivan Levkivskyi, Lennart Jansson, Phillip Huang, Pranay Sowdaboina, Pranesh Pandurangan, Ruslan Nigmatullin, Taylor McIntyre, and Yi-Shu Tai.


