

With this post we begin a series of articles about our Service Oriented Architecture components at Dropbox, and the approaches we took in designing them. Bandaid, our service proxy, is one of these components. Follow along as we discuss Bandaid’s internal design and the approaches we chose for the implementation.
Bandaid started as a reverse proxy that compensated for inefficiencies in our server-side services. Later we developed it into a service proxy that accelerated adoption of Service Oriented Architecture at Dropbox.
A reverse proxy is a device or service that forwards requests from multiple clients to servers (i.e. backends). The most common use of reverse proxy is to provide load balancing for web applications. Additional uses for reverse proxies include web acceleration, SSL termination and various security features.
Although there are many reverse proxy implementations available, companies with private clouds that manage significant volumes of traffic often build their own reverse proxy solutions. Here are some of the reasons why they build their own:
- it allows for better integration with internal infrastructure;
- it makes it possible to reuse well known internal libraries;
- it reduces dependency and allows teams to make changes when they are needed;
- proprietary solutions are better suited to address specific company use-cases
Short facts about Bandaid
Bandaid supports:
- a rich set of load balancing methods (round-robin, least N random choices, absolute least connection, pinning peer);
- SSL termination;
- HTTP2 for downstream and upstream connections;
- metro rerouting;
- buffering of both requests and responses;
- logical isolation of endpoints running on the same or different hosts;
- dynamic reconfiguration without a restart;
- service discovery;
- rich per route stats;
- gRPC proxying;
- HTTP/gRPC health checking;
- support for weighted traffic management and canary testing
Internal Design
Like many of the core infrastructure components at Dropbox, Bandaid is written in Go. Selecting Go allowed for tight integration with services and a shortened development cycle. Bandaid’s primary components are shown in the image below. The Request Handler sends requests to a Queue. The queues pop requests to Workers (goroutines) and the workers process them and send them one-by-one to sets of hosts we’ll refer to as Upstream/Upstreams.
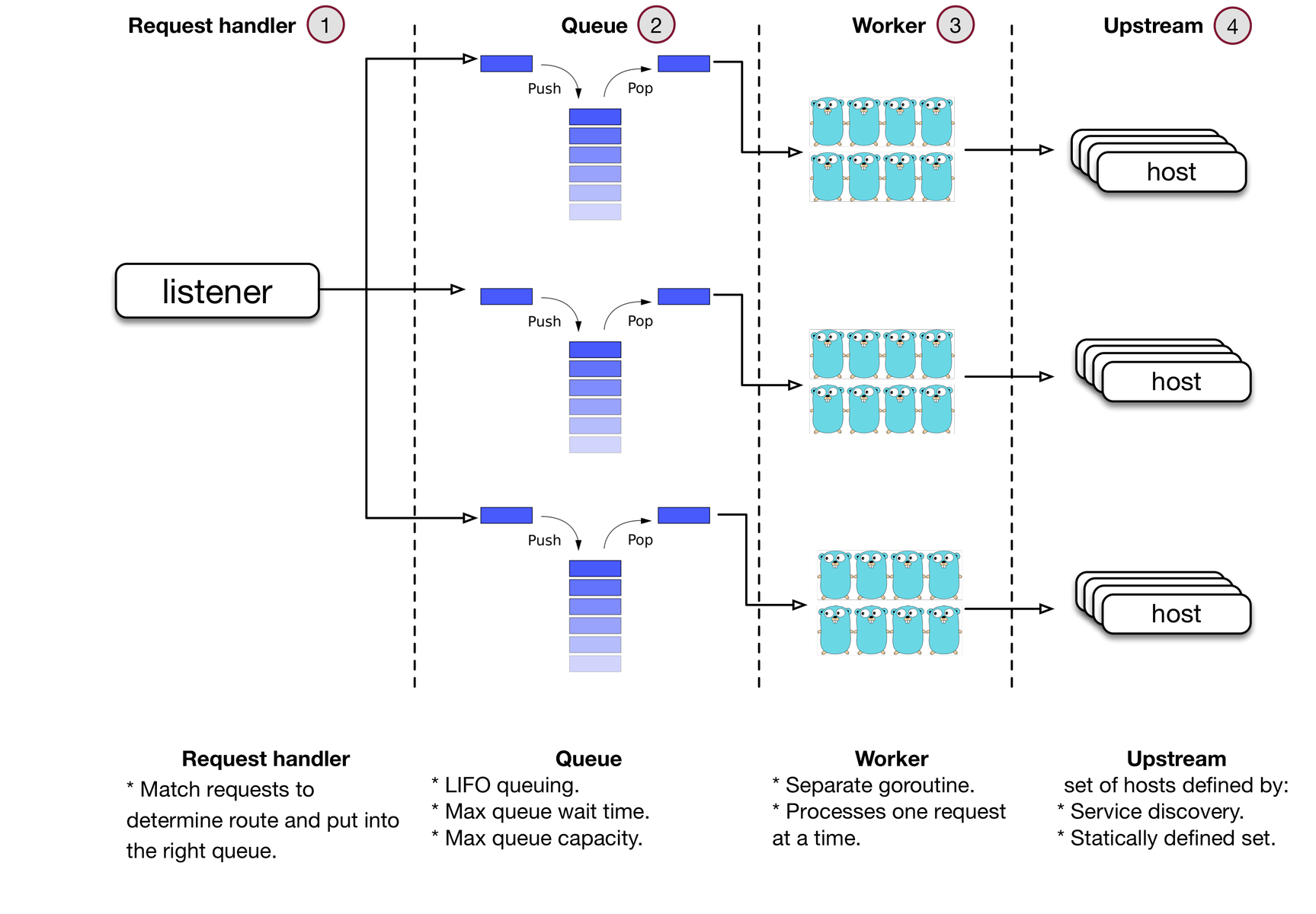
Queueing
It is important to discuss how our queueing mechanism functions in order to understand the request handling workflow in Bandaid.
Request queueing implemented inside the proxy allows for better management of overloaded backends. Bandaid always processes requests in Last In, First Out (LIFO) order. When the system is not overloaded, the queue will be empty (or almost empty). Thus there’s no real difference between popping requests from the front of the queue or the back of the queue. Where LIFO processing reduces overhead is when the system is overloaded. By processing the newest requests first—since the oldest requests are likely to time out soon—we avoid spending CPU cycles on expiring requests.
Bandaid queueing can also support dropping requests once the queue reaches a configurable maximum capacity threshold. However, we don’t recommend this since it’s hard to distinguish whether a queue is full due to system overload or because of bursty traffic.
Bandaid queues have two additional options that control how many requests from the same queue can be processed concurrently, and how quickly requests can leave the queue for processing.
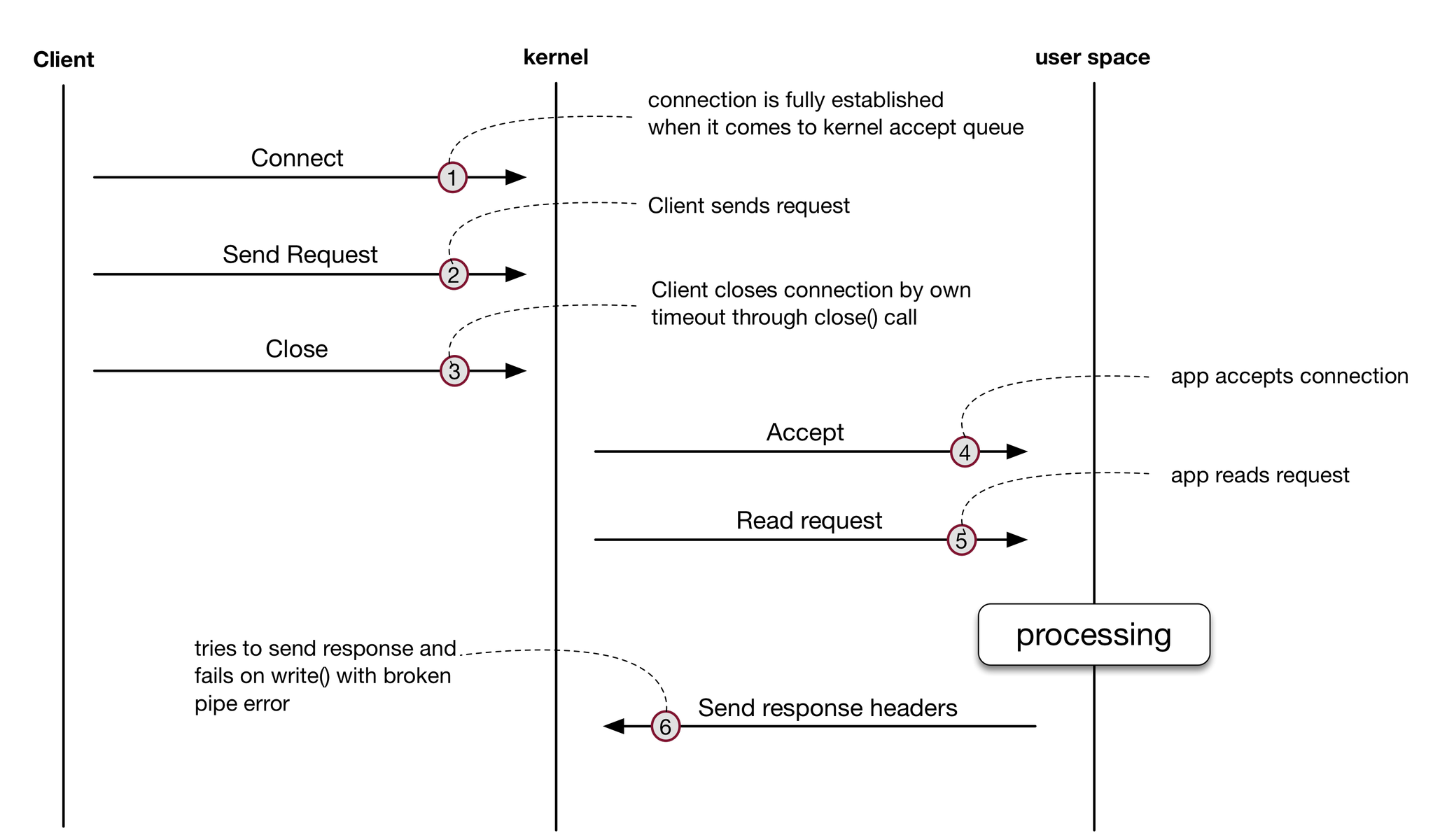
Because Bandaid always accepts TCP connections and pushes read requests into its own queues executed in the user-space, the kernel TCP accept queue [1] is always empty. One of the reasons for this decision is that clients may trigger a connection close unexpectedly, while the backend application is still processing the data. This consumes resources unnecessarily. Keeping the kernel accept queue empty and tracking the timing of connections in Bandaid queues allows to detect and propagate connection closure sooner, freeing up backend server resources. To do this, Bandaid simply fails those requests that are in the queue for more than the configurable timeout. Instead it forwards newly sent requests that have a lower probability of being closed by the client.
We found it’s much easier to manage connections in the user-space queue; it gives us more control over both the queue and requests. See the scenario below for more details.
- Client attempts to connect to the server. If the accept queue in the kernel is not full the connection will be successfully established after a three-way handshake.
- Client sends requests.
- NOTE: Since the client doesn’t know anything about the state of the server it will send requests even if the server cannot accept any more connections or is not ready to process new requests.
- In the case of a slow server, the client will wait until the configured timeout and then will close the connection (with
FIN-ACKflags) because no response is received from the server. - The server application finally gets a delayed connection from the kernel accept queue via the
accept()call. It doesn’t detect that connection is already closed, since it was closed normally (viaFIN, instead ofRST), and continues to the request step. - The server application reads the request.
- The application then processes the request and tries to send a response. The server gets
RSTafter the firstwrite()call as the connection is already closed on the client side. The next write call will raiseSIGPIPEsignal or returnbroken pipe errorwhen the signal is ignored.
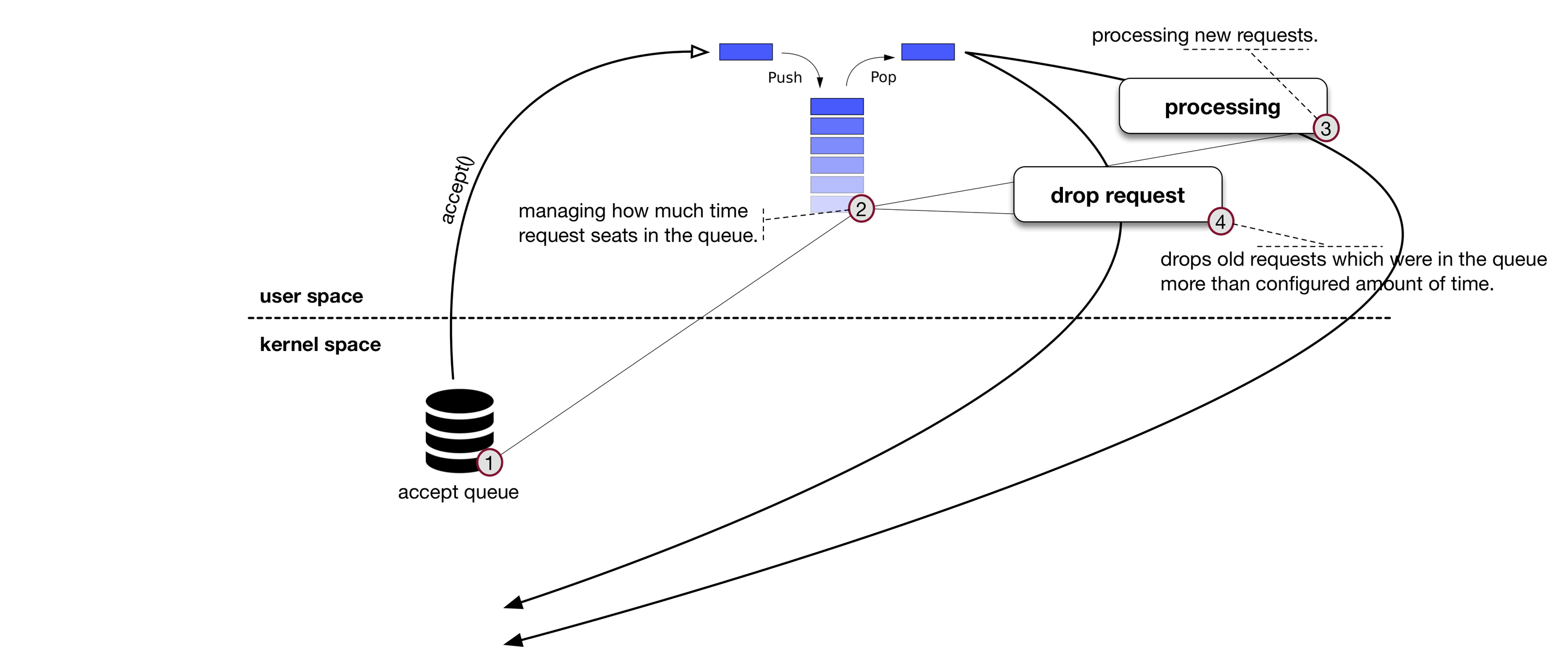
Aggressive retries from the client side make the situation worse since the server is already overloaded and cannot process the extra requests. These requests will keep the kernel accept queue full, exhausting it with already closed connections. There are multiple ways to solve this problem; here are a few:
- impose exponential backoff between client retries;
- decrease the size of the accept queue in the kernel;
- manage connection timeouts in the user-space queue
At times it may be difficult to control timeouts between retry attempts on the client side (e.g. a third-party application accessing the server through an API).
Bandaid implements connection management in the user-space LIFO queue by keeping the kernel queue empty. Old connections that sit in the queue for more than a specified amount of time are closed without being processed. New requests will go through for processing.
Request handling
Since Bandaid supports multiple queues it needs a mechanism to determine which queue to push requests to; this is done by the Request handler. Currently, the Request handler can only distinguish requests by their URL and hostname. It matches this information with a configurable list of URL patterns and hostnames that belongs to each queue. In the future we’ll have additional matching methods.
Worker Pool
Bandaid has a fixed-size pool of workers that process requests. This approach (as opposed to running an unlimited number of worker goroutines) makes it possible to precisely control upstream concurrency. The number of workers is configurable, but depends on the size of the serving set (number of healthy upstream hosts). Oversubscription occurs when this number is set much higher than number of healthy upstream hosts.
In each worker loop iteration a worker pops a request from the queue, and calls the current request processor to handle the request. Since the number of workers controls how many concurrent requests can be processed, the number should be tuned so that there is enough workers to utilize the full upstream capacity. This configuration option should be chosen carefully because oversubscription will reduce the effectiveness of graceful degradation. When services in an upstream are overloaded sending more requests to that upstream will result in increased rate of failed requests or add latency. To mitigate this Bandaid drops these extra requests, keeping the load on the upstream at an appropriate level.
Upstreams
Upstreams are composed of the following components: queues that receive incoming requests; a single dequeuer that serves as multiplexer; and a request processing work pool. Note that it’s possible to have multiple upstreams. The role of dequeuer is discussed in the section below where we talk about the various use cases made possible by Bandaid.
Important use cases
Weighted traffic management
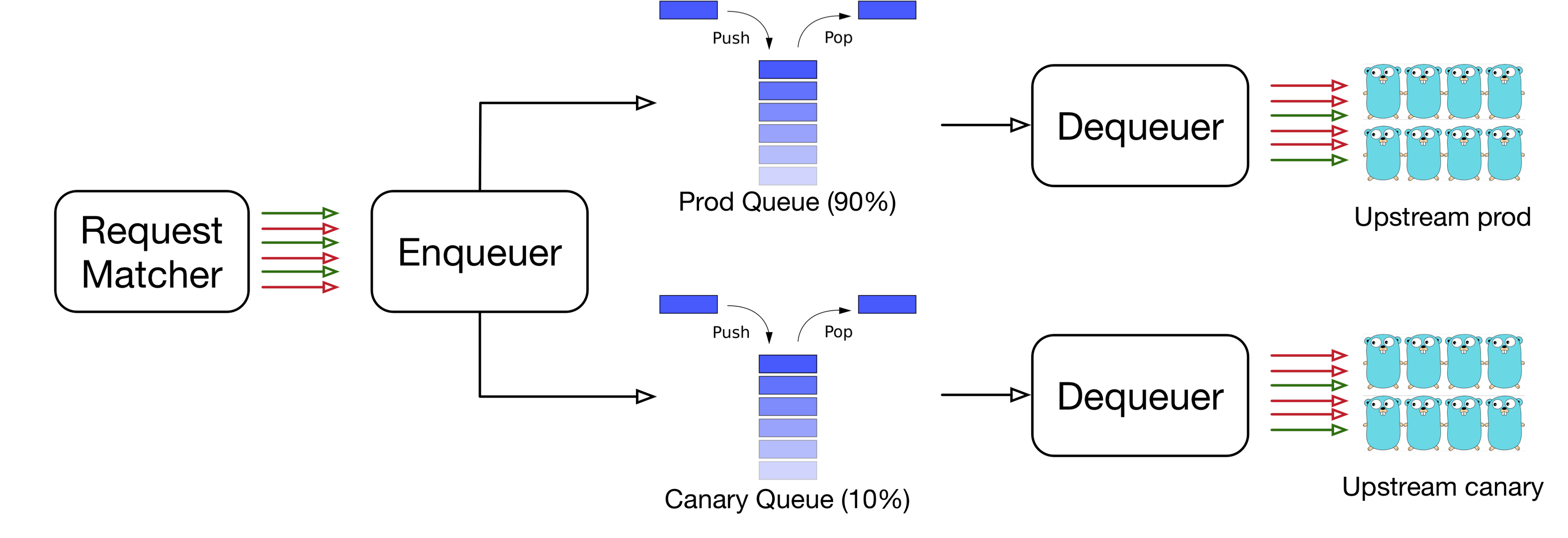
This is an important Bandaid feature that enables canary deployments of services at Dropbox. This makes it possible to route a configurable percentage of traffic to a deployment with particular version of software (for example, send 10% of traffic to a new deployment).
In the design of Bandaid multiple queues may belong to a single upstream. Each queue may have its own properties such as weight, queue size, rate limit, priority level and number of concurrent connections. There are also two extra enqueueing and dequeueing interfaces built on top of queues. These features enable weighted traffic management and prioritization functionalities in Bandaid.
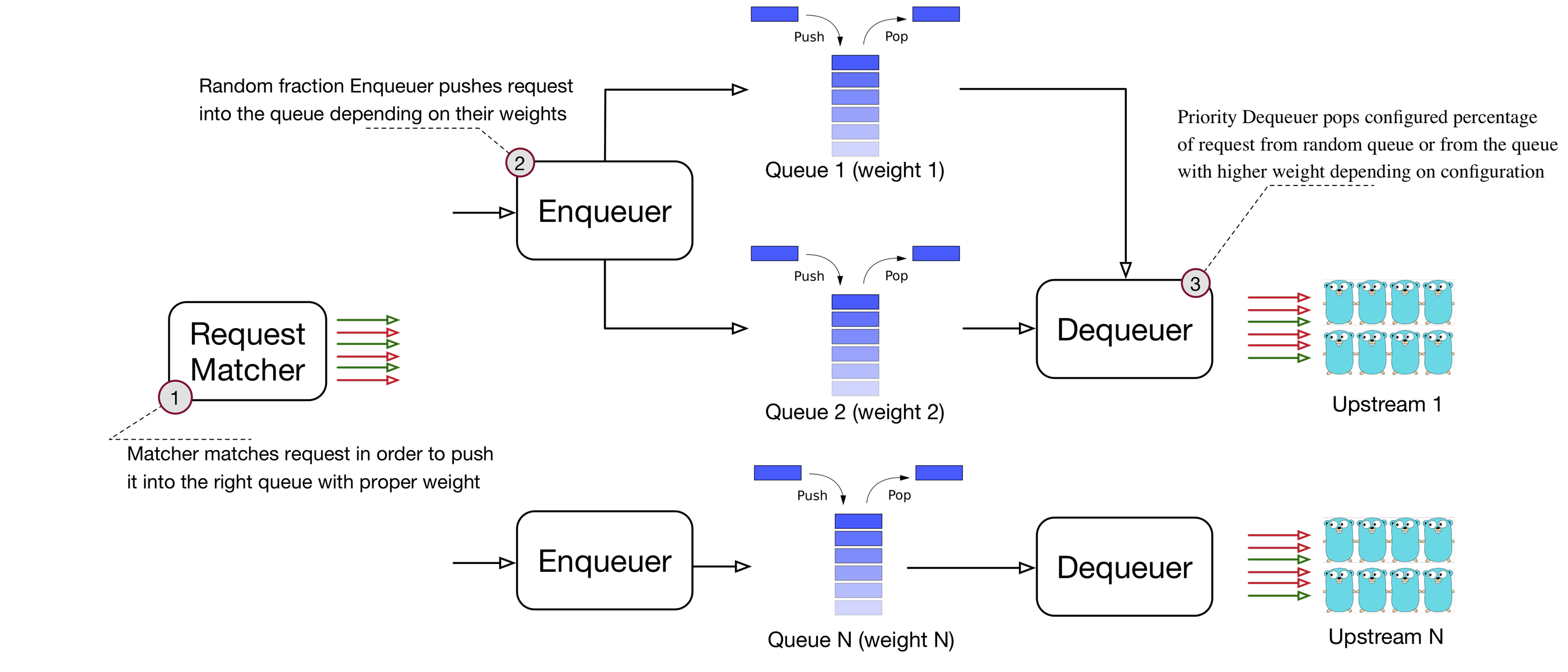
The enqueuer interface makes decisions about where to push requests based on queue weights. Queues with higher weights are more likely to take new requests. This allows us to implement traffic shifting as it’s shown in the next picture: 90% of traffic goes to one upstream (production) and 10% to another (canary). As mentioned earlier Bandaid supports hot config-reloading (dynamic reconfiguration without a restart). A new configuration can be applied without having to restart Bandaid. This simplifies development operations and allows us to see results within a few seconds from the push of a new configuration.
The dequeuer determines dequeueing order based on the queue’s priority level. Requests are popped from higher priority queues sooner than from lower priority queues. Hence, when the system is overloaded, low priority requests are more likely to be slowed down than high priority requests.
Multiple queues can share the same priority level. To ensure fairness among these equal priority queues, the priority dequeuer will semi-randomly shuffle them and will pop requests in the shuffled order.
Strict priority-based dequeuing can result in starvation (i.e., requests with lower priority will never be served because there are always requests in higher priority queues). To combat this, Bandaid provides another option that controls how fairly queues are popped. At one extreme, queues are treated as if they all have the same priority; at the other extreme, the priority dequeuer will always favor high priority requests over low priority requests.
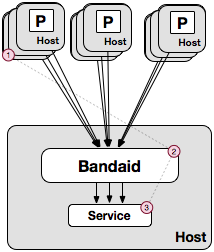
Logical isolation within the upstream
Some backends may serve critical and non-critical routes from the same host. In this case performance degradation on non-critical routes may affect the responsiveness of critical routes. This is because the number of requests each individual host can handle is limited, so if it spends all its resources on serving non-critical routes, then it won’t be able to handle critical routes.
One solution for this problem is to serve critical and non-critical routes from different hosts. Another approach involves performing isolation at the proxy level. This helps reduce operational overhead and minimizes the number of hardware instances.
Bandaid allows configuring the following properties to control the behavior of critical and non-critical routes: rate limiting, number of concurrent connections, and queue priority.
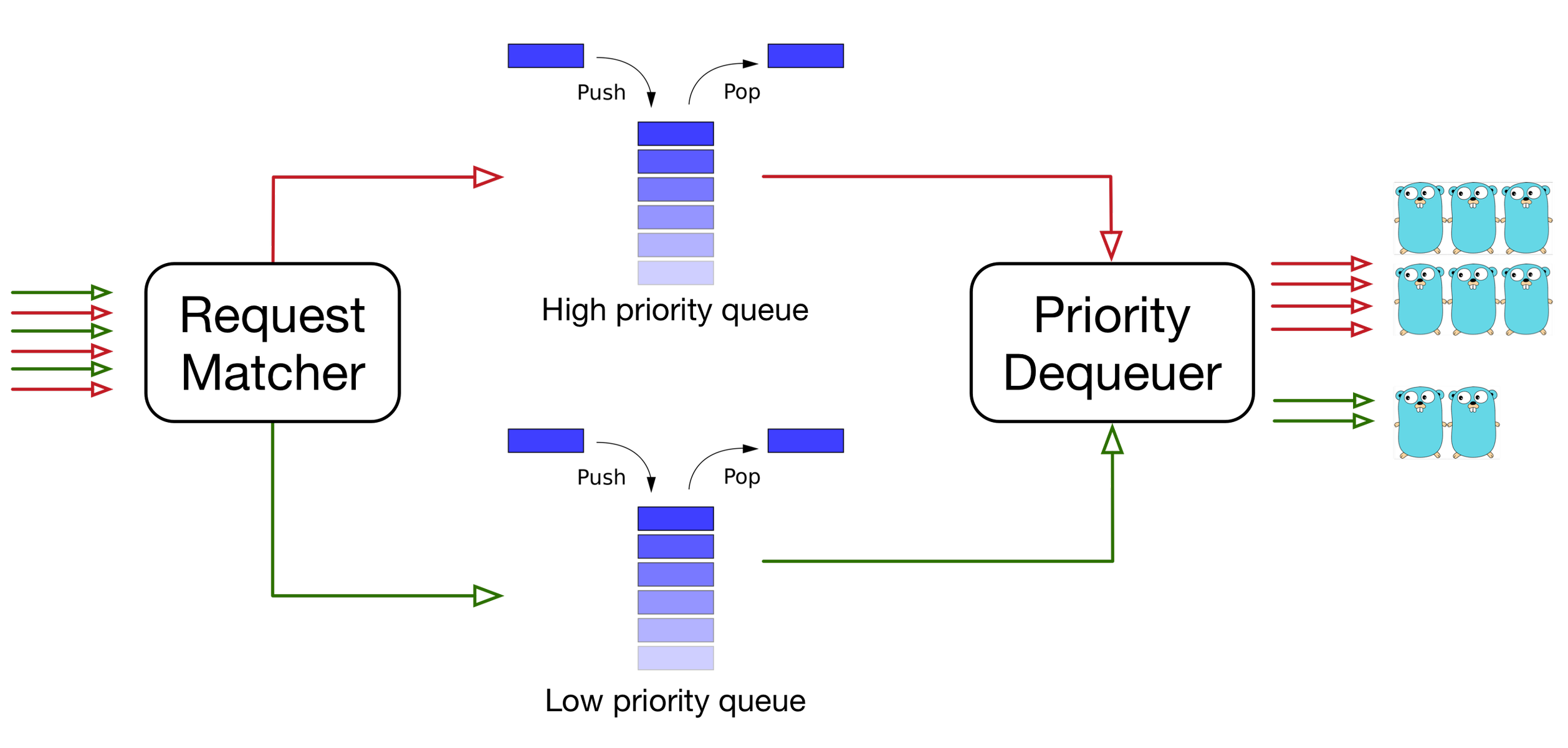
The image shows two queues in use, but there is no such limit in Bandaid—the same upstream may handle requests from multiple queues.
HTTP/gRPC Reverse proxy
This is a classic load-balancing use case. See the section on load balancing methods below for more details.
Limiting the number of concurrent connections
Backend servers may have a limitation on the number of supported concurrent connections. In this case Bandaid handles all incoming connections (which can be a large number) and controls the number of connections (typically a much smaller number) forwarded to each backend process. Bandaid can be configured to reply with a specific status code when the limit of concurrent connections is reached.
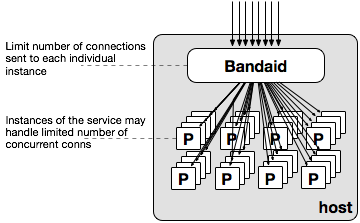
Below, outgoing TCP connections are being reduced by multiplexing them using Bandaid. Each host in the picture has multiple instances of clients and each client is establishing its own TCP connection with Bandaid. Bandaid reduces the number of concurrent connections when it communicates with the service by reusing inactive connections (keep-alive, http2).
HTTP Protocol transition
Some of the services still use HTTP 1.0 and Bandaid can be used to translate the newest version of HTTP protocol to the oldest, or vice-versa.

Load-balancing methods
The current version of Bandaid supports multiple load balancing methods. Unfortunately, there is no perfect method that works equally efficiently in all cases. Different scenarios require different load-balancing approaches.
Round Robin
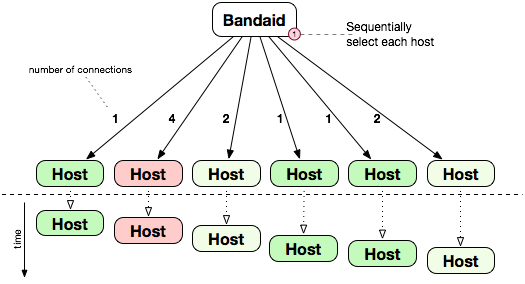
This is a well known load-balancing method that is simple to implement. When configured, Bandaid will send the same number of connections to each host. This method doesn’t take into consideration hosts/services or connection slowness. It is likely to cause a slight imbalance when hosts perform differently. This situation is schematically shown in the image below. Red hosts perform more slowly than the green hosts. In the Round Robin implementation the number of connections processed by the red hosts will continue growing because Bandaid will send new requests to these hosts even if they are not done processing old requests.
Let’s take a closer look at the following scenario: the round robin load-balancing method is used with various ratios between the number of slow and healthy backends. The probability that a worker will get stuck serving slow hosts can be found as V = KR/(1 + K*(R-1)) where
C - number of backends in bad state
Lc - average latency across C machines (time between accepting the connection and finishing processing)
P - number of backends in normal state
T - total number of machines or T = C + P
Lp - average latency across P machines.
K - [0, 1] ratio between C (bad hosts) and T (total number of hosts). K = C/T, or C = K T, or P = (1-K)T
R - ratio between Lc and Lp → R = Lc/Lp or Lc=R*Lp
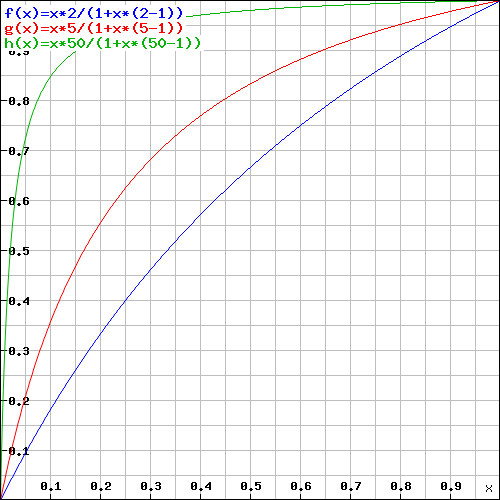
The graph at right shows a few examples of V for different ratios between slow backends and the total number of backends in upstream for various R values:
- Blue line: R=2 (average latency across bad machines is two times higher than the average latency across good machines)
- Red line: R=5
- Green line: R=50
You can see in the figure the rapid increase of the green line which means that slow hosts performing 50 times slower than others may consume ~70% of all capacity, even in cases when only 5% of these slow/bad machines are present.
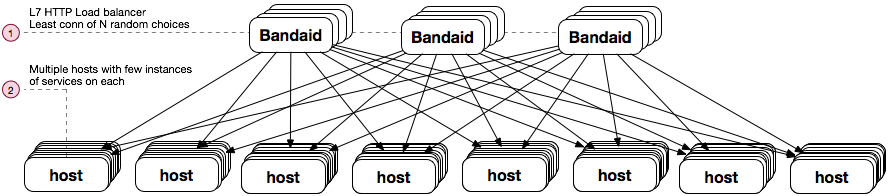
Least number of connections of N random choices
This is an effective method for backends that do not perform equally in terms of the time it takes them to process requests. Here, the load balancer needs to send a smaller number of requests to a slow host and a greater number of requests to faster/healthy hosts. The load balancing method that allows us to do so is least connections of N random choices [2].
The image below shows the main principle and the steps for the method. In this example N=2 (i.e. two random choices).
- Bandaid randomly selects two hosts from the serving set.
- Bandaid selects hosts with the fewest number of connections.
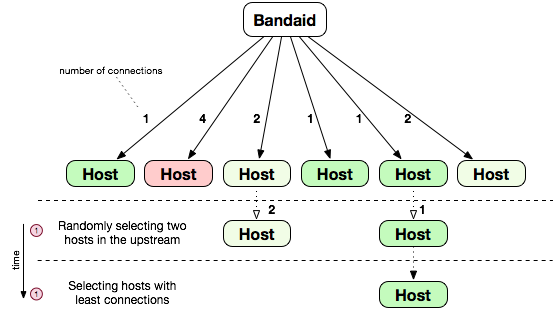
An adverse situation can exist where an upstream host is failing requests at a high rate (especially in the case of a small serving set) and is selected as the one with the least connections. This is because the algorithm is not aware of server health or resource utilization and only cares about the number of concurrent connections.
A derivative of this load-balancing technique is the Absolute Least Connections method. Because the number of connections could change while we search, we freeze (lock) the current state while Bandaid searches for the host with the least number of connections. Once found Bandaid will direct new connections to this host.
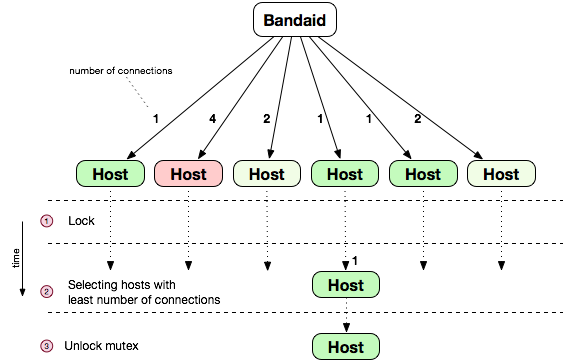
In addition to this, Bandaid randomizes starting positions to add distribution across hosts that have the same least number of connections. This is done to avoid establishing all the connections with the first host from the serving set that has the smallest number of connections.
Pinning peer
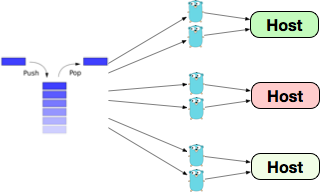
For this method each worker (goroutine) belongs to a specific host in the upstream. The worker takes the next request from the queue only after the previous request has been processed by the host. This automatically reduces the load on slow hosts because each Bandaid worker is directly limited by the performance of the host.
Synthetic tests
Seeing how each load-balancing method behaves and getting additional evidence that the theory works as expected is key before trying it in production. Testing requires an additional time investment in building a test environment that simulates sets of backends. Long term, testing allows us to validate code much faster and helps identify the right load-balancing method.
Results of synthetic tests for load-balancing methods implemented in the current version of Bandaid are shown below. The test environment had the following conditions:
- 100,000 requests sitting in the queue and ready to be served;
- 100 workers in the workpool;
- 10 backend machines in an upstream.
Each backend host had its own processing latency shown on the following graph:
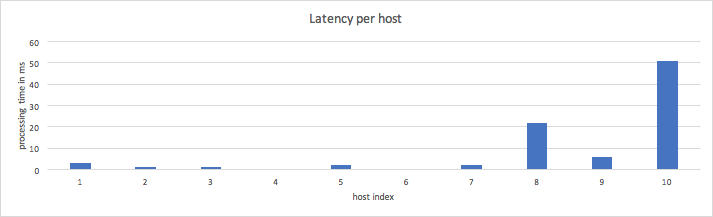
The next graph shows the distribution of requests across backend servers in the upstream for each load-balancing method. As expected, the distribution of requests for the round-robin method is almost the same for each backend and doesn’t depend on their processing time. Other methods (absolute least connections, least connections of N random choices and pinning peer) send more requests to the backends with smaller processing times.
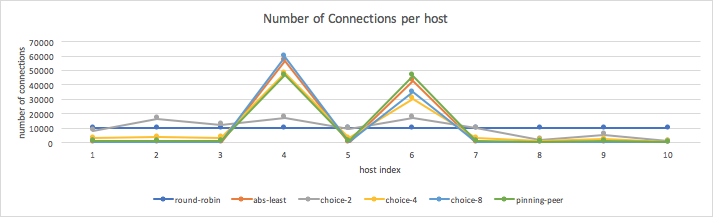
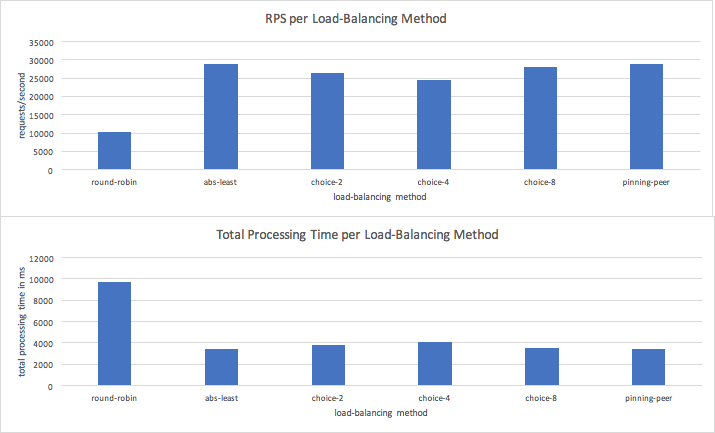
Better distribution when using random choices and pinning-peer methods reduces total processing time and increases the total request rate across all backends.
Exclusion in retry attempts
It is important to support the exclusion of backends that were previously tried during retry attempts. Otherwise there is some probability that future retry attempts could be made with the same bad/unhealthy hosts.
The next graph shows the ratio of failed requests to total requests for each load-balancing method, with and without exclusions. In this scenario 20% of all hosts were failing hosts. A maximum of four retry attempts were configured. A failed/unhealthy host in this test environment was a host that immediately replied with an error status code.
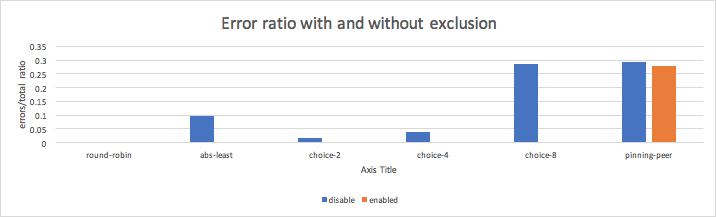
As you can see from the results in the graph above, enabling exclusions reduced the error rate for all tested methods except pinning peer. This was expected because retry attempts in the case of pinning peer won’t make much difference—the worker is host bound and will attempt all retries with one host.
That’s all for this post! In the future, look out for further posts on Bandaid, including:
- Publishing Bandaid performance test data
- Open sourcing Bandaid
[1] How TCP backlog works in Linux
[2] The Power of Two Random Choices: A Survey of Techniques and Results [pdf]
We’re hiring!
Do you like traffic-related stuff? Dropbox has a globally distributed edge network, terabits of traffic, millions of requests per second, and a small team in Mountain View, CA. The Traffic team is hiring both SWEs and SREs to work on TCP/IP packet processors and load balancers, HTTP/2 proxies, and our internal gRPC-based service mesh. Not your thing? We’re also hiring for a wide variety of engineering positions in San Francisco, New York, Seattle, Tel Aviv, and other offices around the world.


