

Introduction
As a company that manages our own infrastructure we need to be able to rapidly install new server capacity and ensure that the equipment entering our production environment is highly reliable. Prior to the creation and implementation of the Pirlo system, engineering personnel at Dropbox manually intervened in most aspects of server/switch provisioning and validation.
Pirlo was designed to eliminate and automate many of these manual processes. In this post we will describe Pirlo, a flexible system designed to validate and configure network switches and to ensure the reliability of servers before they enter production. We will explain the design of Pirlo and its components, and show how some of the design choices we have made enable Dropbox to manage our physical infrastructure operations efficiently and safely.
Installing new server capacity can be broken down into two major stages: (1) network switch provisioning/validation and (2) server validation. The Pirlo system automates these tasks through the TOR Starter and Server Validation components that feed our ClusterOps queue. The following sections of this blog post will break down each component in detail, and at the end we will summarize some of the impact that Pirlo has had on our operational efficiency. Throughout this article, you’ll see references to users and workers. Here, users are people and workers are technologies.
ClusterOps queue
At a high level, Pirlo consists of a distributed MySQL-backed job queue built in-house using many of the primitives available in Dropbox production such as gRPC, service discovery, and our managed MySQL clusters. While there are some excellent job queue systems such as Celery, we didn’t need the whole feature set, nor the complexity of a third-party tool. Leveraging in-house primitives gave us more flexibility in the design and allows us to both develop and operate the Pirlo service with a very small group of SREs.
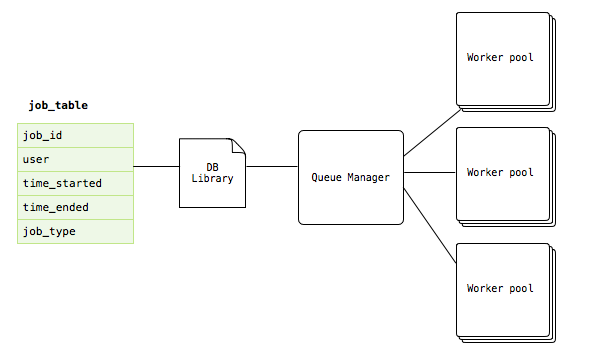
The ClusterOps queue was designed to be as generic as possible while providing flexibility to the different services implementing the queue. The queue provides a service with:
- A basic Job table.
- A Database utility using the SQLAlchemy toolkit.
- A Queue Manager thread interface.
- A Worker thread interface.
Switch provisioning
Switch provisioning at Dropbox is handled by a Pirlo component called the TOR Starter. The TOR Starter is responsible for validating and configuring switches in our datacenter server racks, PoP server racks, and at the different layers of our datacenter fabric that connect racks in the same facility together.
ClusterOps queue implementation
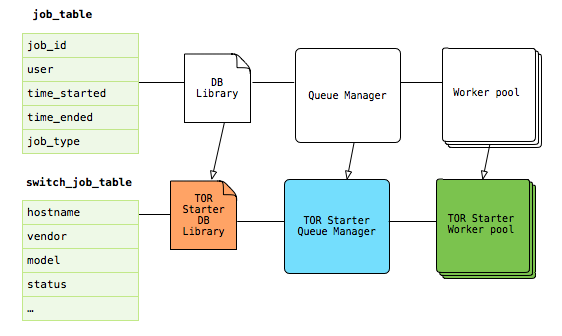
Writing the TOR Starter on top of the ClusterOps queue provides us with a basic manager-worker queuing service. We also have the ability to customize the queue to fit our needs in switch provisioning. The switch job table (shown below) is an extension of the basic job table. Similarly, the TOR Starter queue manager thread implementation is customized to queue switch jobs, and the TOR Starter worker implements all of the switch validation and provisioning logic.
Design
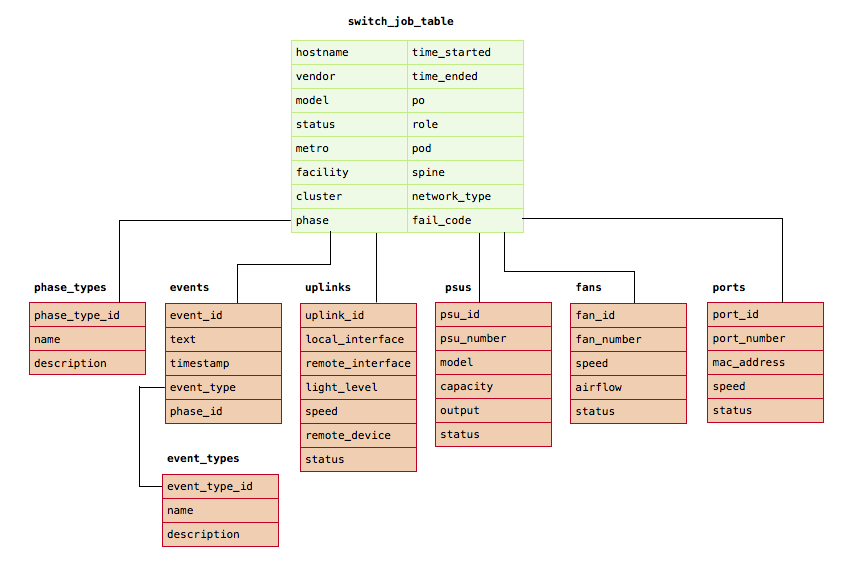
Along with all of the switch job attributes, there are several tables that provide a comprehensive view of a switch job. As a switch job is running, the current state can be queried by a client and displayed in our user interface. After a switch job has completed, all of the job’s state is kept in the database and can be queried for reporting and analytics purposes. Tables in the database also hold information related to each component in the switch such as its network uplinks, fans, and power supplies. All of the captured data from a switch is linked to a particular switch job.
Switch provisioning process
The switch provisioning process begins once a user or switch discovery service creates a switch job via the TOR Starter client. The client makes a gRPC request using service discovery to find a healthy TOR Starter server. The switch is then verified for its eligibility to be provisioned and the switch job is placed into the work queue.
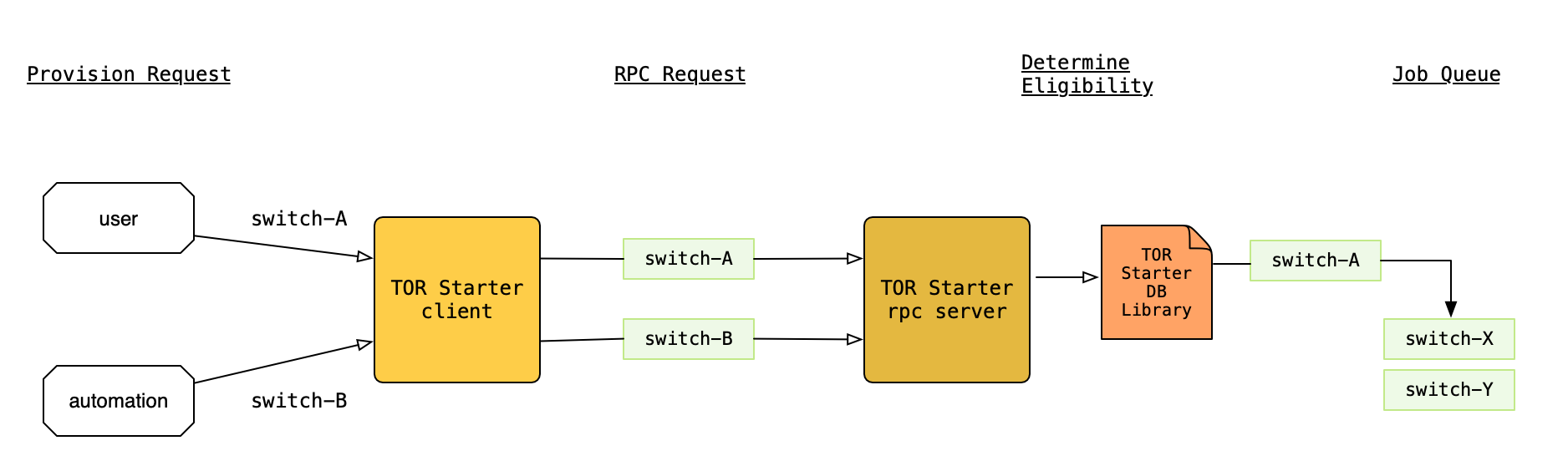
The queue manager determines which switch job to process from the job queue in first-in first-out order. Once a job has been selected, the queue manager assigns an appropriate job handler based on the job type. A job type is an enumerated identifier that allows us to map specific modules (job handlers) used in a switch job workflow. These modules provide the worker with all the instructions and tasks required to provision a switch. Once the job handler has been determined, the worker performs all the tasks and checks required to provision a switch and moves the job through various phases.
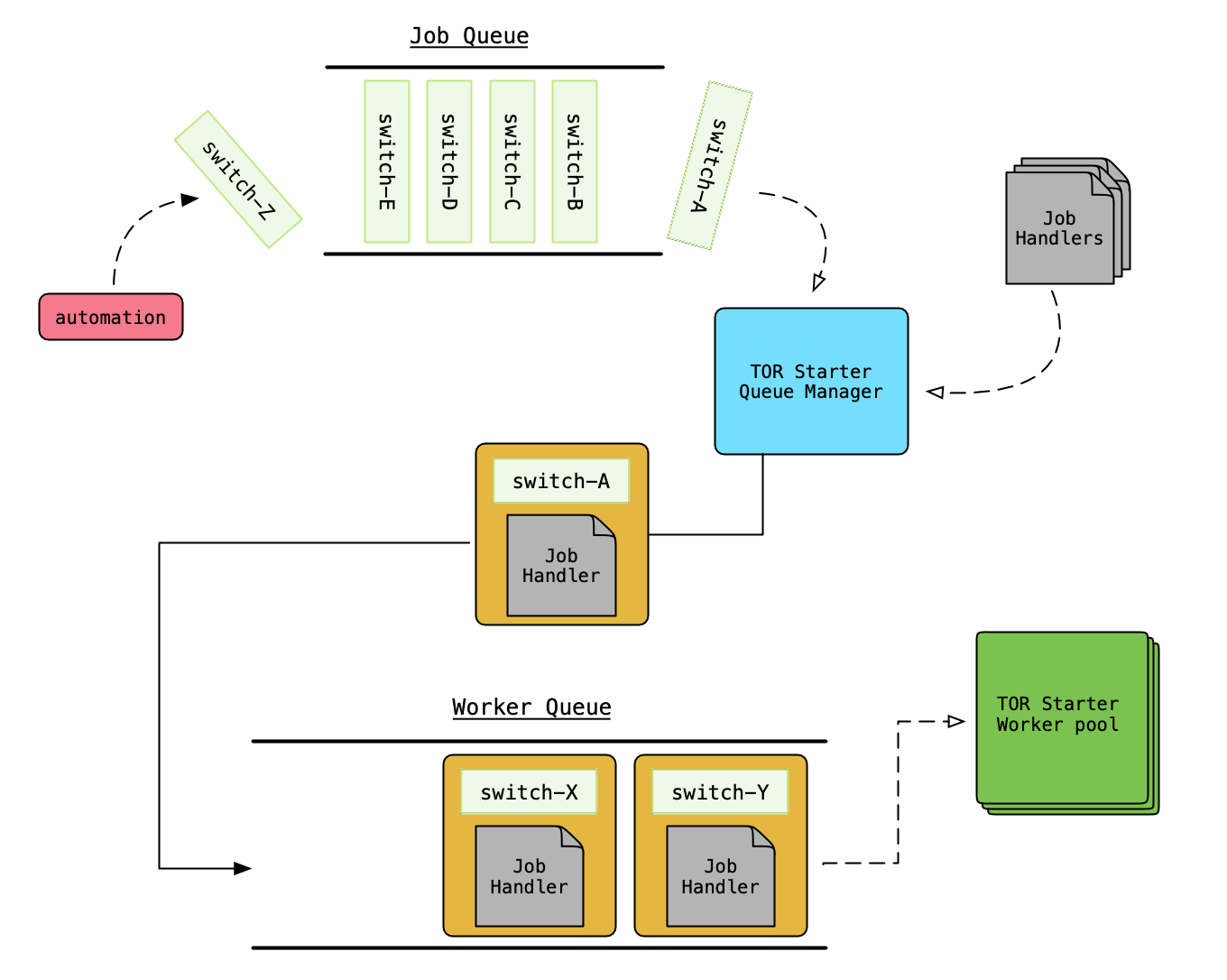
Life cycle of a switch job
The prerequisite to validating and configuring a switch is out-of-band connectivity. This is made possible by a series of out-of-band devices which are pre-installed during the network-core build phase of a network cluster. Once out-of-band connectivity to a switch has been confirmed, there are a series of checks that the switch must pass before we determine that the switch is production ready.
We have developed a plugin system which allows us to separate out the code that we run on the switch. Each plugin automatically sets a particular phase on the switch job when it starts running. As the switch job runs, each plugin transitions through each enumerated phase and the database is updated. Each plugin can throw enumerated failure codes that provide the operator with an idea about what failed. The failure codes can also be used for auto-remediation. Each plugin also logs events into the database, which are automatically associated with the switch job.
A few of the initial plugins that we execute during switch provisioning are described below:
| Plugin (short description) | Job Phase | Possible Failure Code |
|---|---|---|
| Can we establish out of band connectivity? | OOB_CONNECT | OOB_CONNECT_FAIL |
| Are all power supplies present with power input? | PSU_CHECK | PSU_FAILURE |
| Are all system and psu fans present? | FAN_CHECK | SYSTEM_FAN_FAILURE |
| Does the serial number exist in our asset database? | ADB_CHECK | ADB_FAILURE |
| Do the expected number of uplinks exist? | LINK_CHECK | UPLINKS_COUNT |
| Are the uplinks upstream interfaces correct? | LINK_CHECK | UPLINKS_ORDER |
| Are the light levels of the uplinks correct? | LIGHT_CHECK | LIGHT_LEVEL_FAIL |
| Can each uplink establish connectivity? | CONNECTIVITY_CHECK | CONNECTIVITY_FAIL |
After the initial plugins have completed successfully, and we have determined that each uplink on the switch is able to establish network connectivity, we ensure the switch has the expected firmware installed. Firmware upgrades (or downgrades) are handled by a separate firmware plugin. Firmware is downloaded onto the switch by setting up a basic static route and downloading an image from a server in production.
Using the network database and configuration tool developed by our Network Reliability Engineering (NRE) team, the TOR Starter will request a config for the switch that gets copied onto the switch. Once the config has been loaded into memory, another plugin performs some final checks to ensure that all routing protocols are working as expected. At the end of switch provisioning a final plugin reboots the switch and validates that it boots up with the correct configuration.
During each phase, the TOR Starter captures the commands that are run on the switch along with the output. In the database, these are known as log events. We execute slightly different commands based on the type of switch and its role, but we keep the phases and failure codes generic across switch platforms. Most of the switch command output is parsed and we assign the failure codes based on specific output from the switch. When a switch job fails, the error is clearly indicated by the failure code. We can use the collected logs for further diagnosis. If a hardware component failure is detected, the corresponding table in the database is updated to reflect the component status as failed.
User interface
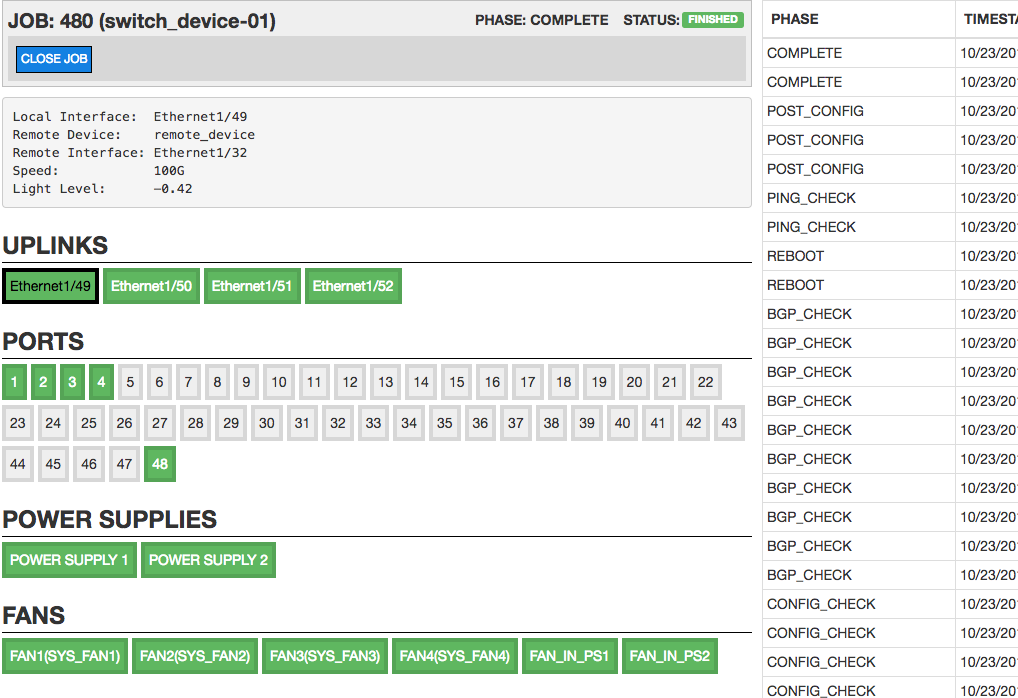
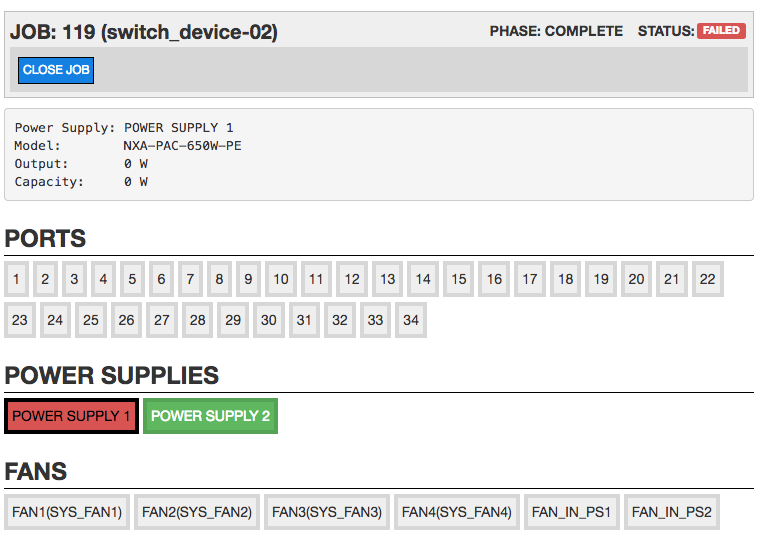
Along with the command line clients, Pirlo also has a user interface. The UI for the TOR Starter component provides the user with a holistic view of a switch job. For each switch job, captured data is visualized and shown along with a running list of the switch job events. From the UI a user can watch a switch job in near real-time as the worker is executing each plugin and transitioning through the phases of a job.
Shown below is the UI for a successfully completed switch job.
Server provisioning, repair and validation
ClusterOps queue implementation
Similar to the switch provisioning service, we are able to take advantage of the ClusterOps queue and customize it for server validation. The server job table (shown below) is an extension of the job table. The server validate queue manager thread implementation is customized to queue server jobs, and the server validate worker implements all of the validation logic for servers.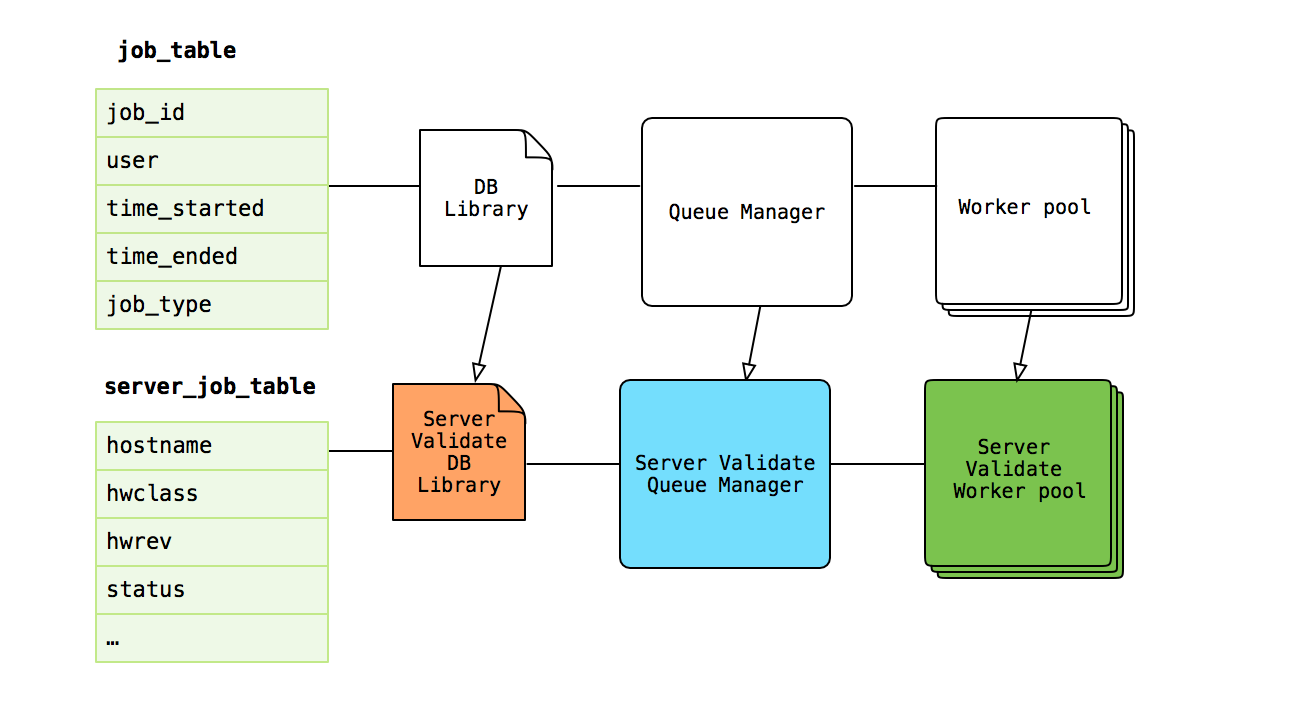
Hotdog
The operating system image we use for server validation is created with a tool called Debirf. . Once the image has been booted over the network, startup scripts rsync additional tooling that can be updated independently of the image. While the main use case for Hotdog is Pirlo automation, a user can also boot a host into Hotdog manually and log in interactively to perform ad-hoc debugging tasks on very problematic systems.
Design
The server job attributes, along with other tables provide a comprehensive state of a server job. As a server job is running, the current state can be queried by a client and displayed in our user interface. After a server job has completed, all of the server job state is kept in the database and can be queried for reporting and analytics purposes. Tables in the database also hold event data, such as logs and structured text. Additionally, server component benchmark results are stored in the database and are used for statistical analysis to detect outliers. In the server job table we also store a link to the server in our asset database, and a snapshot of all server inventory is sent to our asset database every time a server job runs.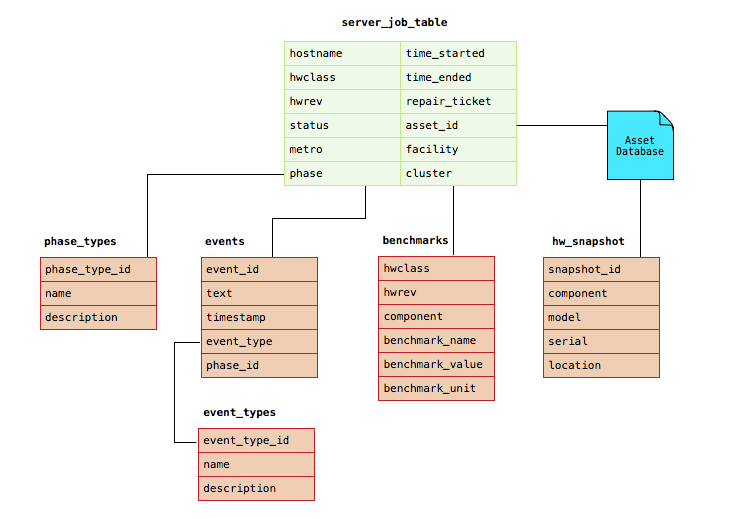
Life cycle of a server job
One prerequisite for validating a server is that the server be able to boot into Hotdog. Once the server boots into Hotdog there are a series of plugins that must run successfully before we determine that the server is production ready. This is exactly the same flow that the TOR Starter uses to validate and configure a switch and most of the concepts remain the same.
A server job is made up of a series of plugins that run in a stated order as determined by a specific job handler that maps directly to a job type. Using job types, we can have many different types of server validation jobs that execute the different plugins in any order. As with switch jobs, server jobs have enumerated phases and failure codes that are set by each plugin. Plugins can also log data that is stored in the database.
The validation job handler is used to determine production worthiness and runs a comprehensive series of plugins that cover component inventory verification, benchmarking, and stress testing the server. Other job handlers have been created to only run a few of these tasks. Server jobs can be created by a user or via automation, depending on the job type. Server jobs can be one of following job types: Provision or Validation.
Provision job Some server jobs are created by an automation hook the very first time servers land at our data centers. Upon completion of a successful switch provision job, server provision jobs are created for all servers in the corresponding rack. Provision jobs configure and perform validations along with long burn-in tests that create a realistic, high-load situation in order to test various hardware components.
Validation job Server validation jobs provide a comprehensive suite of tests, updates, and BOM validations for machines transitioning out of repair. A transition out of repair indicates the Datacenter Operations team has finished replacing the defective hardware component(s) and they consider the server to be repaired. Pirlo validation jobs are created automatically once the Datacenter team has moved a server status from repair to repaired. A Pirlo validation job ensures the repair action was successful and begins transitioning the server back into our production environment.
Below are some of the initial plugins that are executed when validating a server. This early process ensures that a host is at least healthy enough to boot, and it sets up the server with dependencies required by the more sophisticated plugins. If any of these early plugins fail, we log as much data as we can from out-of-band interfaces to help the user determine why the server can’t boot.
| Plugin (short description) | Job Phase | Possible Failure Code |
|---|---|---|
| Does the bmc interface ping? | IPMI_PING | IPMI_PING_FAIL |
| Can we obtain power status via bmc? | IPMI_POWER | IPMI_POWER_FAIL |
| Are we able to pxe boot the machine? | SET_PXE_BOOT | SET_PXE_BOOT_FAIL |
| Did the machine boot the Hotdog image? | HOTDOG_CHECK | HOTDOG_FAIL |
| Are we able to establish a ssh session? | VERIFY_SSH | SSH_FAIL |
The worker plugins execute all commands on the server via SSH. By design, the server runs no Dropbox daemons or service discovery; thus it can not independently send any data back to the worker.
There is a generic framework that any plugin can use for long-running commands. It polls a status file on the server to determine whether a process has timed out/crashed. While polling is not ideal, we poll very infrequently and it hasn’t been a scalability concern.
Bill of materials (BOM) verification
We maintain a detailed set of server bill of materials (BOM) that describe all the possible combinations of components we can use in each of our server classes. This allows us to regulate the allowed make and model of every server component in the fleet. The database also has a list of valid component configurations for each hardware class, allowing us to gate the different combinations that are permitted.
An example of a whitelisted memory config:
CPU1:
DIMM_1: [HMA42GR7MFR4N-TF, M393A2G40DB0-CPB]
DIMM_3: [HMA42GR7MFR4N-TF, M393A2G40DB0-CPB]
CPU2:
DIMM_1: [HMA42GR7MFR4N-TF, M393A2G40DB0-CPB]
DIMM_3: [HMA42GR7MFR4N-TF, M393A2G40DB0-CPB]
We verify the BOM against this list of server components:
- Root and Storage Disks
- Memory Modules
- CPUs
- RAID Controllers
- Network Cards
The two main benefits of BOM verification:
- Consistency and safety in server component swaps. The wrong component can not be swapped into a machine and pass validation.
- Ensuring replacement components we receive from our vendors have been qualified by our Hardware Engineering team and are permissible for production.
Firmware verification
For each server component such as RAID controller, BMC, BIOS, and Network card, the Hardware Engineering team has qualified specific firmware versions. A plugin upgrades (or downgrades) all components to their desired firmware revisions by executing a tool supplied by the Hardware team that bundles all vendor firmware images and desired BIOS settings.
Stressing and benchmarking
One of the major functions in server validation is the ability to stress and benchmark components. Stressing components such as memory, cpu, and disk allows us to actually cause issues that we may not see during idle operation. The most interesting server failure cases often involve server components that are not completely failed, but which fail when they are stress tested in our isolated environment. Some of the stress testing utilities are listed below:
| Component | Utility | Description |
|---|---|---|
| Memory | Stressapptest | Maximized randomized traffic to memory |
| CPU | Stressapptest, mprime | Exercises CPU with artificial load @ 100% |
| Disk | FIO | Stresses disk while verifying data integrity |
Benchmarking new or failed components against a known baseline also allows us to verify desired functionality and proper configuration of servers. Servers that fail to meet thresholds indicate that something is misconfigured, faulty, or has some other unknown issue. We want to make sure underperforming or broken servers do not make it into production. Some of the benchmarking utilities are listed below:
| Component | Benchmark | Description |
|---|---|---|
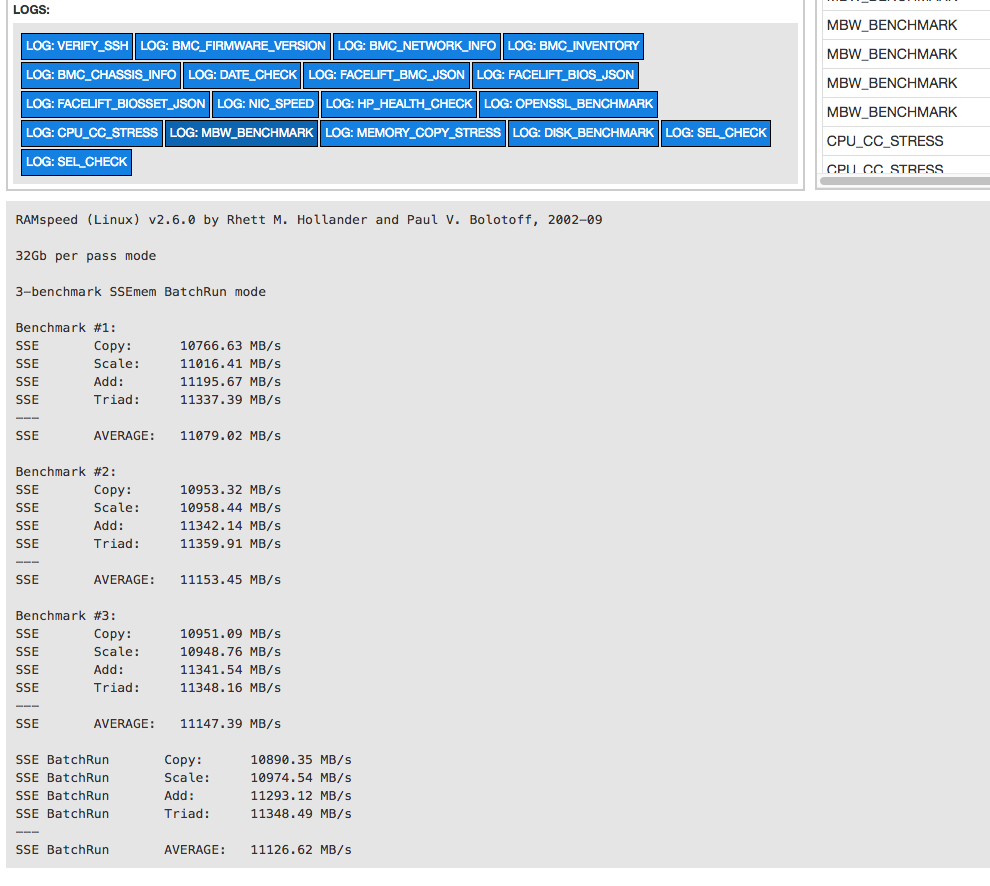
| Memory | RAMSpeed | Measures the cache and memory performance of the CPU/Ram. |
| CPU | OpenSSL | Measures how fast the CPU can calculate cryptographic hashes. |
| Disk | FIO | Measures disk I/O - read and write speeds. |
A series of plugins execute different stress testing and benchmarking tests based on the class of server being tested and the components within the server. New plugins can be added very easily when we want to add a new test. Each stress test or benchmark plugin can log data as events, and can also store structured data in the special benchmark results table. We can do reporting on the benchmarks table for all server jobs to see how each individual server performs against other similar servers. This helps us to refine our thresholds for failure and easily discover anomalies.
Final steps
As with switches, we only consider servers to be validated once they successfully execute all plugins for a job type. At the end of validation, we automatically move the server back into production to get re-imaged by our operation system installer. If a server is in repair, we transition the status of a repair ticket in our ticketing system and we add a small summary of the server job with a direct link to the UI as a comment in the ticket.
User interface
The Pirlo UI component for server validation is shown below. Similar to switch jobs, each server job contains a table with a log of all phases and you can watch the worker execute a live server job in real-time. As with switch jobs, all finished server jobs can be accessed and viewed in their final state.
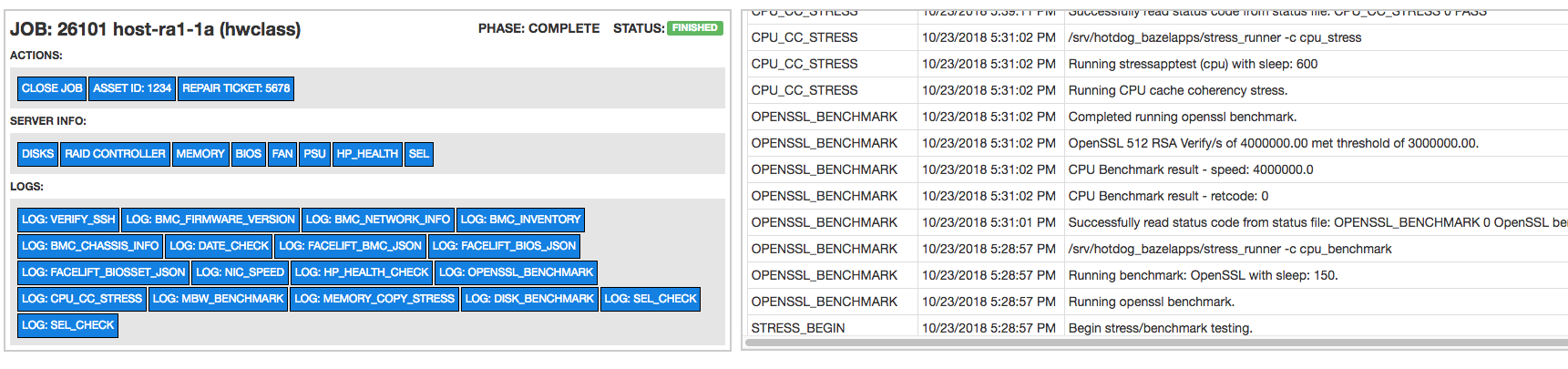
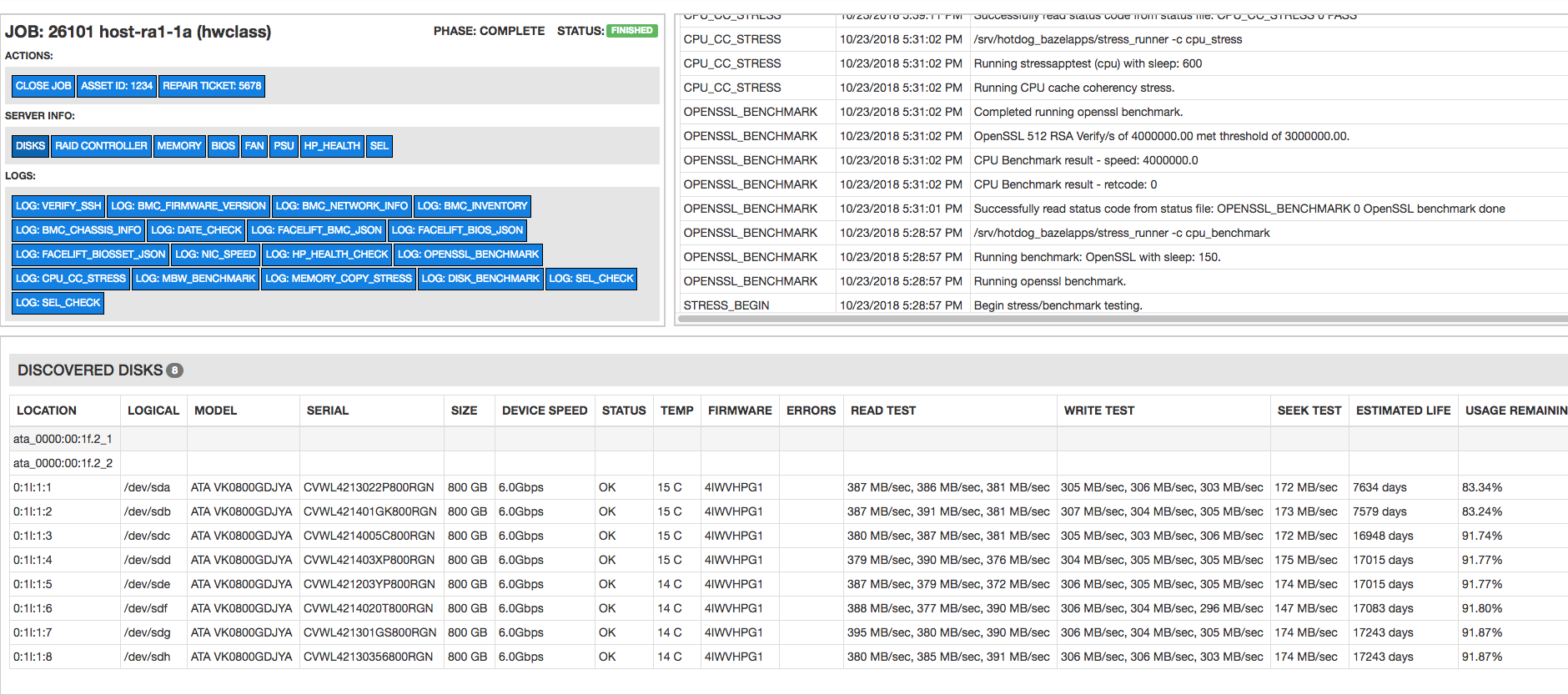

Results
Pirlo was designed to automate or eliminate manual processes. Like any business case that looks to automate a previously manual process, the team hypothesized that the creation of Pirlo would primarily:
- Reduce Errors, Downtime, and Associated Rework: Limit downtime, outages, and inefficiencies associated with incomplete or erroneous provisioning or triage.
- Increase Operational Efficiency: Reduce human intervention time, acting as a force multiplier for operations engineers.
Previously, server provisioning and validation required an operations engineer to use playbooks and subject matter expertise in tandem with various server error logs to prescribe a series of remediation or configuration actions for the to-be-provisioned or failed hardware. Following the remediation actions, the engineer would release the machine back into production by sending the server to our re-imaging system. If the remediation actions didn’t cure or properly prepare the server for re-imaging, the server would be sent back to the operations engineer for additional triage. These manual operations consumed a significant portion of our operations engineers’ time and resources and also caused a lot of churn with the server re-imaging system.
We hypothesized that by …
- Holistically health-checking (inclusive of BOM validation, component health and benchmark/stress testing) and providing diagnostics for a server
- Applying firmware patches for hardware subcomponents while in the pit-stop
- Gating release of machines into the re-imaging system on a clean bill of health
Pirlo would:
Reduce the amount of server failure recidivism, enabling operations engineers to increase their task load with the assurance of releasing holistically healthier machines back into production.
Since the internal beta release of Pirlo, the hypothesis seems to be validated. To properly evaluate this, let’s break this down into two sections: the first being the server recidivism, and the second being the output efficiency of operations engineers.
Prior to the advent of Pirlo, any server that did not obtain a first-pass success, incurred server failure recidivism. Operations engineers manually managed diagnoses, validations, and remediations. When re-imaging a candidate server failed, or service errors were discovered after re-imaging, the server would be sent back to the operations engineer for triage. This process would repeat until the candidate server successfully provisioned.
We thought Pirlo would increase first-pass success by checking for many of the common hardware failures that occur during and immediately after re-imaging.
Over time, Pirlo saw continuous improvement by the development team: incorporation of newly discovered systemic issues, software updates, and benchmark/diagnostic suites. The table below summarizes the first-pass success rate for systems released to production since January of 2018 following the beta release of Pirlo:
| First-Pass Success Rate (%) | |
|---|---|
| January | 84.4 |
| February | 82.8 |
| March | 93.7 |
| April | 92.9 |
| May | 87.1 |
| June | 91.0 |
| July | 93.7 |
| August | 91.7 |
| September | 95.5 |
| October | 96.5 |
With the advent of rapid adoption and continuous improvement of the Pirlo system, first-pass success increased by 12.2%. This should have meant that operations engineers would be empowered to use their newfound time to work on repairing and validating other servers (a force multiplier effect).
In fact, they did. Operations engineers steadily increased their output by 40+% in that same period of time. While first-pass success for released servers reduced the amount of servers competing for an engineer’s attention, it also reduced the amount of babysitting (waiting for a server to pass re-imaging). Rather than having engineers manually running tests using playbooks, Pirlo performed an automated sequential battery of tests that reduced the need for hands-on attention and concurrently increased diagnostic accuracy. The decreased time-to-remediation allowed engineers to address more issues in the same amount of time. The following table displays issues remediated per engineer per working day over the same time period as the First-Pass Success Rate table above:
| Average Workday Remediations per Operations Engineer | |
|---|---|
| January | 7.77 |
| February | 6.48 |
| March | 9.91 |
| April | 10.79 |
| May | 11.42 |
| June | 11.95 |
| July | 10.14 |
| August | 12.76 |
| September | 11.82 |
| October | 10.96 |
During this time, the size of the server fleet within the internal Dropbox cloud increased by more than 15%. At the same time, the average percentage of machines in a non-functional or state-requiring-repair remained below 0.5%. Finally, during this time period, the headcount of Operations Engineers remained the same.
The advent of Pirlo in combination with a pursuit of best practices and operational excellence permitted the operations teams at Dropbox to act with a force multiplier.
Conclusion
We’re hiring!
Dropbox is hiring for a variety of positions across infrastructure. Please visit our jobs website for specifics. The Cluster Operations team is hiring SREs to build tools and workflows that improve safety and efficiency in monitoring, operating, and expanding Dropbox’s Physical Infrastructure.


