One of the best ways to find ways to improve performance, we’ve found, is to work closely with our customers. We love shared troubleshooting sessions with their own engineering teams to find and eliminate bottlenecks.
In one of these, we found a discrepancy in upload speeds between Windows and Linux. We then worked with the Windows Core TCP team to triage the problem, find workarounds, and eventually fix it. The issue turned out to be in the interaction between the Windows TCP stack and firmware on the Network Interface Controllers (NIC) we use on our Edge servers.
As a result, Microsoft improved the Windows implementation of the TCP RACK-TLP algorithm and its resilience to packet reordering. This is now fixed and available starting with Windows 10 build 21332 through the Windows Insider Program dev channel.
How we got there is an interesting and instructive tale—we learned that Windows has some tracing tools beyond our Linux-centric experience, and working with Microsoft engineers led to both a quick workaround for our users and a long-term fix from Microsoft. Teamwork! We hope our story inspires others to collaborate across companies to improve their own users’ experiences.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
What users don’t know Dropbox does for them
Dropbox is used by many creative studios, including video and game productions. These studios’ workflows frequently use offices in different time zones to ensure continuous progress around the clock. The workloads of such studios are usually characterized by their extreme geographic distribution and the need for very fast uploads/downloads of large files.
All of this is usually done without any specialized software, using a Dropbox Desktop Client. The hardware used for these transfers varies widely: Some studios use dedicated servers with 10G internet connectivity, while others simply rely on thousands of MacBooks with normal Wi-Fi connectivity.
On one hand, Dropbox Desktop Client has just a few settings. On the other, behind this simple UI lies some pretty sophisticated Rust code with multi-threaded compression, chunking, and hashing. On the lowest layers, it is backed up by HTTP/2 and TLS stacks.
The outer simplicity of Dropbox Desktop Client can be quite misleading, though. Balancing performance with resource consumption across heterogeneous hardware and different use-cases is quite tricky:
- If we push compression too much, we starve upload threads on 10G servers. But if we pull it another way we waste bandwidth on slow internet connections.
- If we increase the number of hashing threads to speed up server uploads, laptop users suffer CPU/memory usage, which can cause their laptops to heat up.
- If we improve the performance of hashing code, it can cause high iowait on spinning disks.
With so many different scenarios for optimization we try to understand each customer’s set of bottlenecks and make Dropbox Client adapt to its environment automatically, as opposed to bloating settings with a myriad of tunables.
How we spotted the problem
While doing routine performance troubleshooting for a customer we noticed slow upload speeds. As usual, our network engineers promptly established peering with the customer. This improved latencies a lot, but upload speed was still bogged down to a few hundred megabits per host—fast enough for most people, but too slow if you work with giant files all day.
Shameless plug: Dropbox has an open peering policy. If you need a more direct path and lower packet loss, please peer with us!
Looking into the problem, we noticed that only Windows users were affected. Both macOS and Linux could upload at the network’s line rate. We set up a testing stand in the nearest cloud provider and began to drill down on Windows usage in a controlled environment.
For us, as primarily Linux backend engineers, this was an interesting experience and learning opportunity. We started at the application layer with an API Monitor, a fairly sophisticated strace/ltrace analog for Windows.
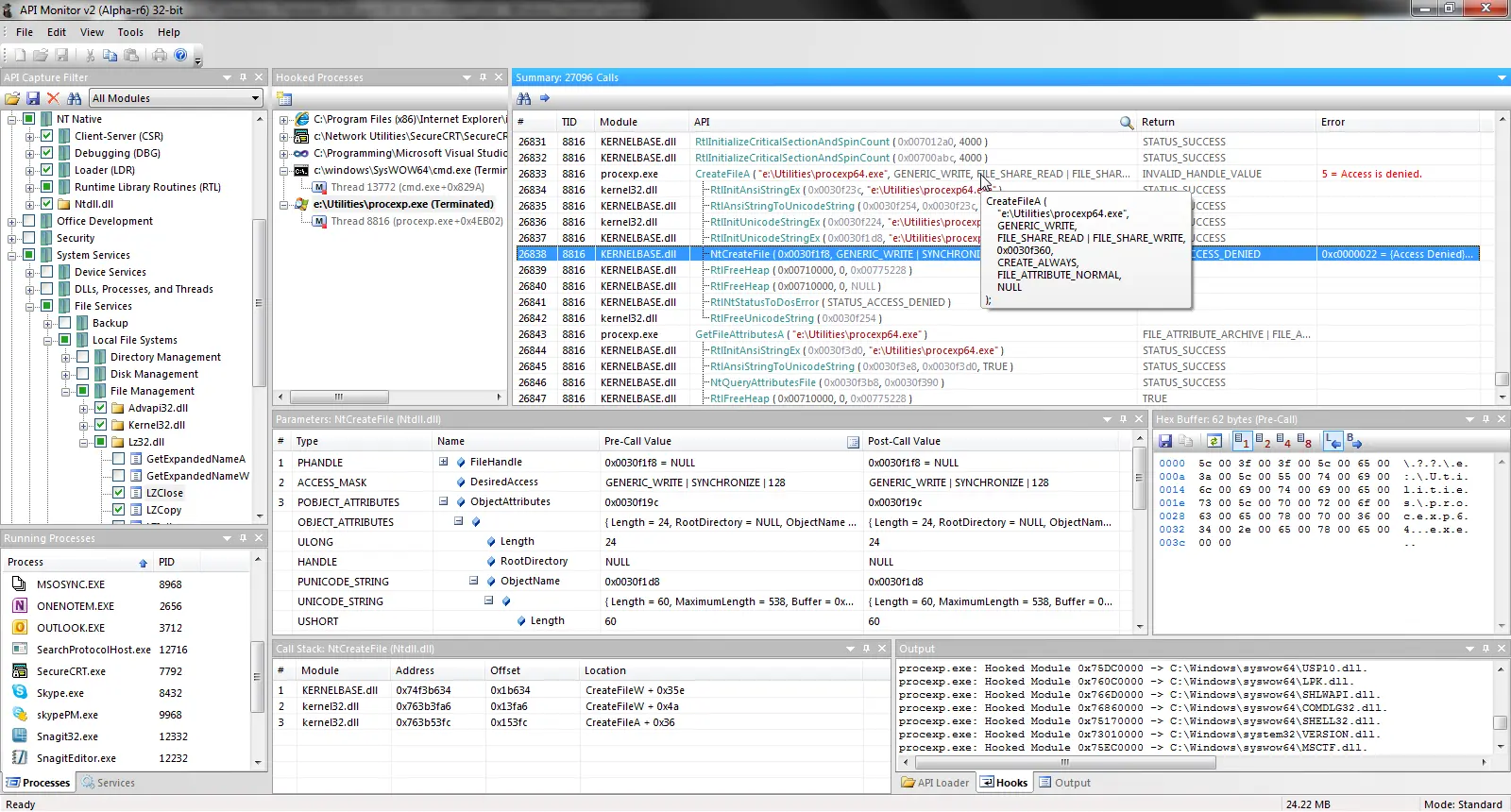
API Monitor for Windows
Our hypothesis was that we might be “app limited”, i.e. there was not enough data being held in the socket buffer, which could cause upload speed to be limited. But we quickly saw this was not the case. Instead, the application was waiting on IOCP events from the kernel. This usually indicates bottlenecks at the TCP level.
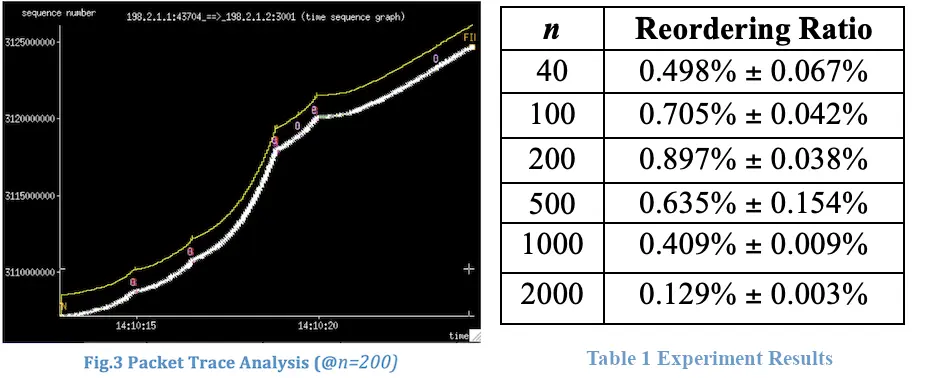
Now on familiar territory to us, we jumped into Wireshark. It immediately identified long periods of upload inactivity, in which the client’s machine was waiting for ACKs from the Dropbox side with a minuscule ~200kb of inflight data:

Wireshark: sender waits for 21ms (rtt) ACKs. Then immediately sends a new batch of segments.
But Wireshark’s tcptrace analog showed that bytes in flight were not limited by the receive window size. This meant there was likely something inside the sending side’s TCP stack preventing it from growing its congestion window:
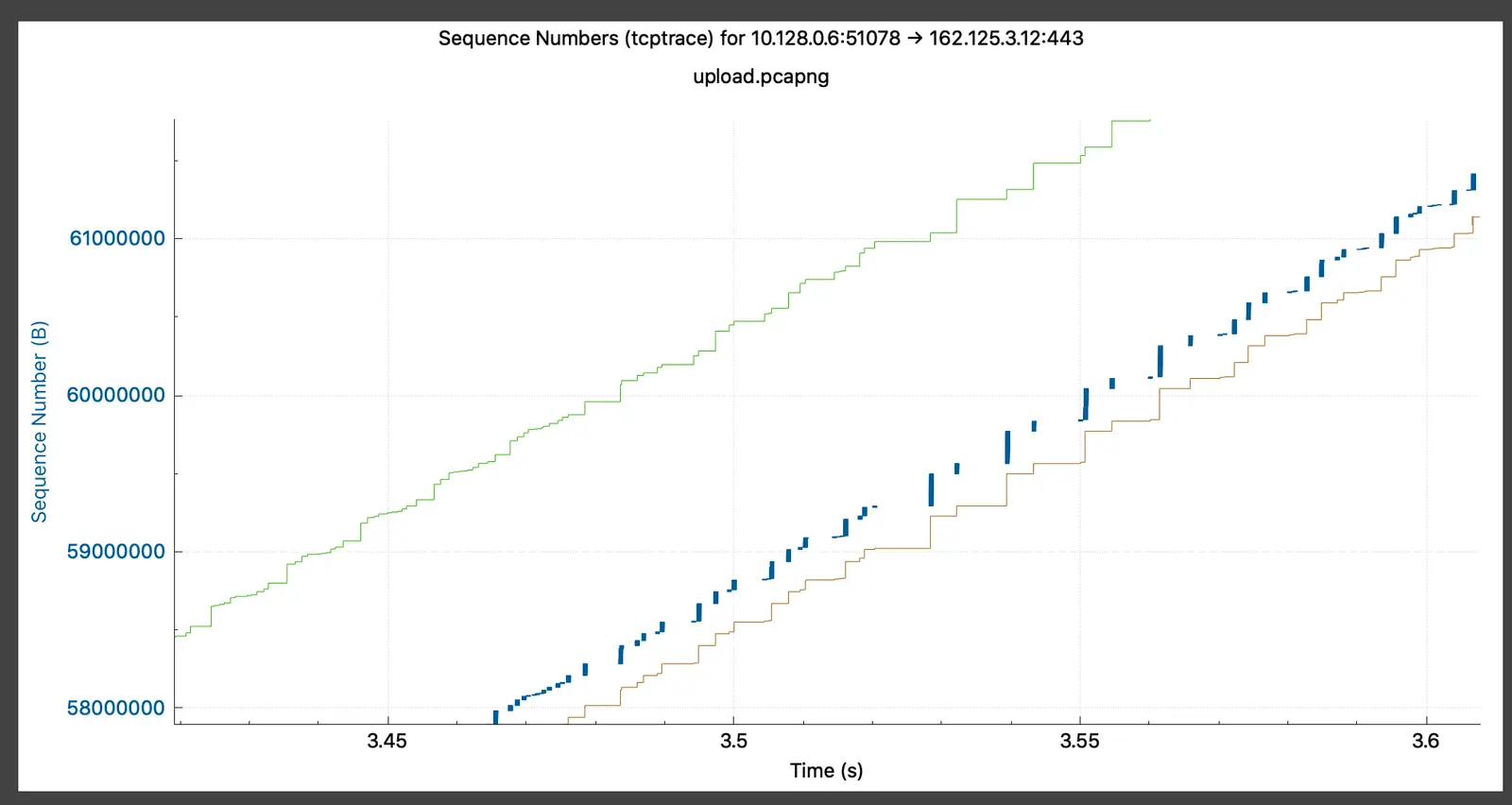
Note the gaps between blue lines (outgoing segment runs) and the distance to green line (receive window)
With this information, it was time to contact the Windows Core TCP Team to start digging into it together.
Debugging with Microsoft
The first thing Microsoft engineers suggested was to switch from our UNIX-y way of collecting packet dumps to a Windows-friendly way of doing the same thing:
> netsh trace start provider=Microsoft-Windows-TCPIP capture=yes packettruncatebytes=120 tracefile=net.etl report=disabled perf=no
There is also a tool called etl2pcapng that converts etl files to pcap. This lets you do in-depth packet analysis in Wireshark/tshark.
This was an eye-opening experience for us. We saw how far behind Linux is on the tracing tooling side. Even with all advances on the eBPF front, there’s still no unified format in Linux for collecting traces across all kernel subsystems. tcpdump is an awesome tool, but it only provides insight into what’s happening on the wire—it can’t connect that to other kernel events.
netsh trace, on the other hand, correlates events on the wire with events that happen on the TCP layer, timers, buffer management, socket layer, and even the Windows asyncio subsystem (IOCP).
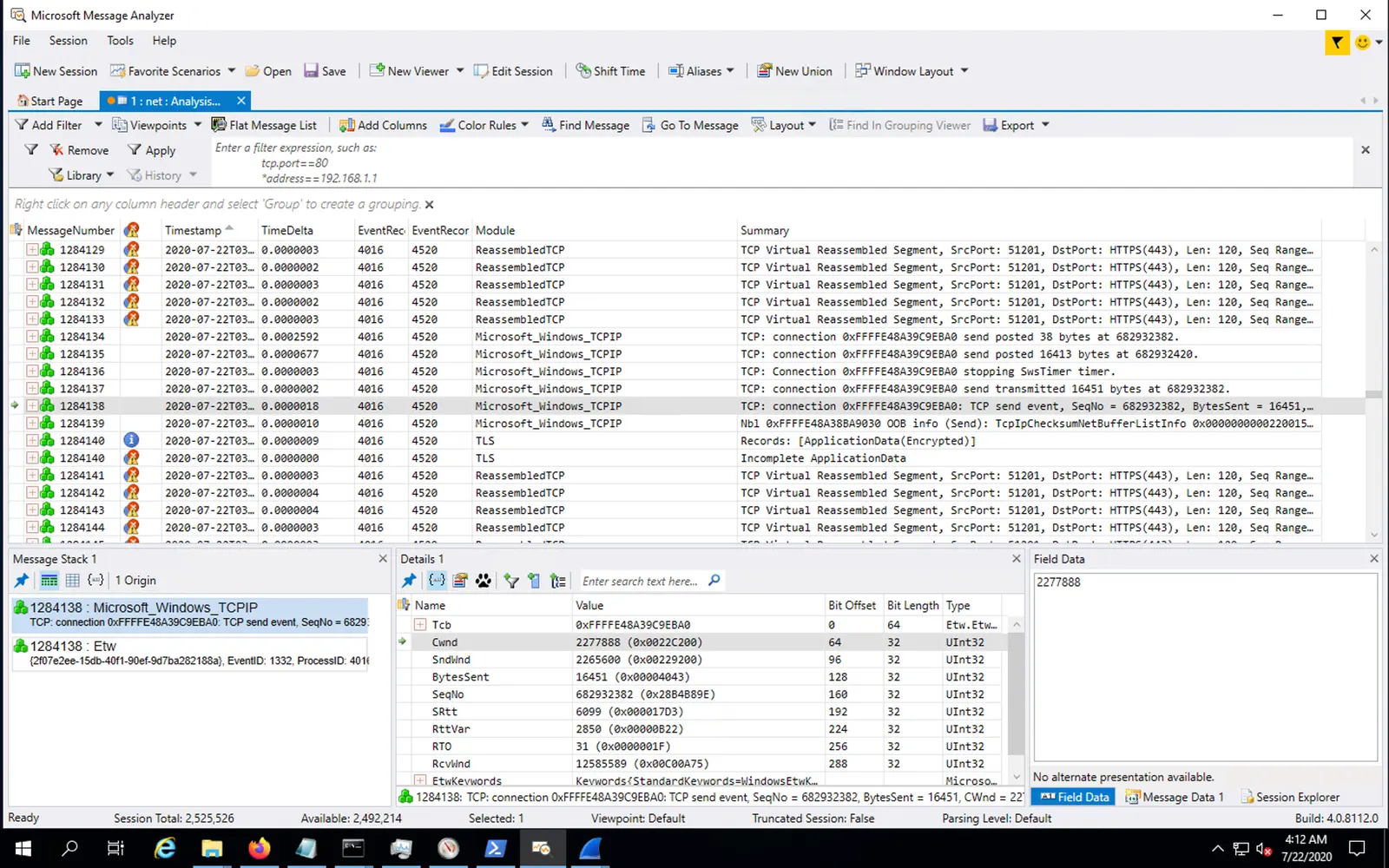
Microsoft Message Analyzer parsing netsh trace output. Imagine a combination of tcpdump, perf trace, strace, and ss.
Message Analyzer allowed us to dig deeper and confirm our theory of small congestion windows. (Sadly, Microsoft Message Analyzer has since been retired, likely due to performance issues it had. Microsoft now advises to use pktmon to analyze logs along with packet dumps.)
We find packet reordering
At that point Microsoft engineers also suggested we look into packet reordering that was present on the link:
> tshark -r http2-single-stream.pcapng "tcp.options.sack_le < tcp.ack" | find /c /v "" 131
They explained:
This filter is not direct evidence of packet reordering. It filters for DSACKs which likely indicates reordering because it tends to cause spurious retransmissions. If a system already has reordering resilience, this filter is not true anymore.
Now the ball was on the Dropbox side to find where the reordering was introduced. Based on the SACKs observed in packet captures, it clearly happened somewhere before traffic hit our edge L7LBs (we use Envoy). Comparing the (mirrored) traffic on L4LBs (we use katran, an eBPF/XDP-based horizontally scalable, high-performance load balancer) to the traffic between L4LBs and L7LBs it became apparent that reordering happened somewhere there. We saw a reordering event for a single flow happening every 1-10 seconds.
Nowadays, Windows is using CUBIC congestion control, just like Linux does by default. To get to 10 Gbps over 100ms RTT a loss-based CUBIC needs <0.000003% packet loss. So even a tiny amount of perceived packet loss might greatly affect the performance.
Microsoft engineers also explained:
At the same time, traditionally, TCP used the “3 duplicate ACK” heuristic which meant that any reordering in the network of degree 3 or more in number of packets is perceived as loss.
After an approximate reordering location was identified we went through layer by layer, looking at each for an entity that could potentially reorder packets. We didn’t need to go far. First, we started by ruling out obvious stuff like network flapping and problems with the ECMP load-balancing.
Then system engineers looked at our sufficiently sophisticated network cards, which could potentially reorder packets (at least from an OS point of view). This is a side-effect of an Intel NICs feature called “Application Targeted Routing (ATR).” In theory, this feature should reduce CPU usage by directing packets to the CPU that currently owns processing of that TCP flow, therefore, reducing cache misses. In practice, this may cause the OS to think that there is a reordering on the link.
Especially severe reordering happens when a flow director’s filter table overflows and gets forcefully flushed:
$ ethtool -S eth0 | fgrep fdir
port.fdir_flush_cnt: 409776
port.fdir_atr_match: 2090843606356
It turns out that this is a known issue discussed in academic research papers (see Appendix A below).
Choosing a workaround
We considered a couple of alternative solutions to this problem:
- Pin proxy threads to CPUs. This, combined with IRQ pinning and XPS, should eliminate threads jumping from one core to another, removing the possibility of reordering. This is an ideal solution, but it would require quite a bit of engineering effort and rollout. We held off on this option unless we got closer to our CPU utilization limits on the Edge throughout the next couple of years.
- Reconfigure FlowDirector. 10G Intel NICs (ixgbe) used to have a FdirPballoc parameter that allowed changing the amount of memory that FlowDirector could use. But it’s not present in either i40e docs or newer kernel versions for ixgbe. We quickly lost interest in this path, so we didn’t go full “kernel-archeologist” on it to find out what had happened to this tunable.
- Just turn ATR off. Since we don’t rely on it in any way, we decided to go with this approach.
We used ethtool’s “priv flags” machinery to turn ATR off
# ethtool --set-priv-flags eth0 flow-director-atr off
Note that different drivers/firmwares would likely have a totally different set of flags there. In this example, flow-director-atr is specific to Intel i40e NICs.
After applying the change to a single PoP, server-side packet reordering immediately went down:

Here we use the “Challenge ACK” rate as a proxy for the incoming reordering, since this is what we send to the client when data doesn’t arrive in order.
On the client side, the Windows platform overall upload speed immediately went up proportionally:

This is the Week-over-Week ratio for average per-chunk upload speeds.
As a follow up we also began tracking our Desktop Client upload/download performance on a per-platform basis. Rolling out the fix across the whole Dropbox Edge Network brought up Windows upload speeds to be on par with macOS:
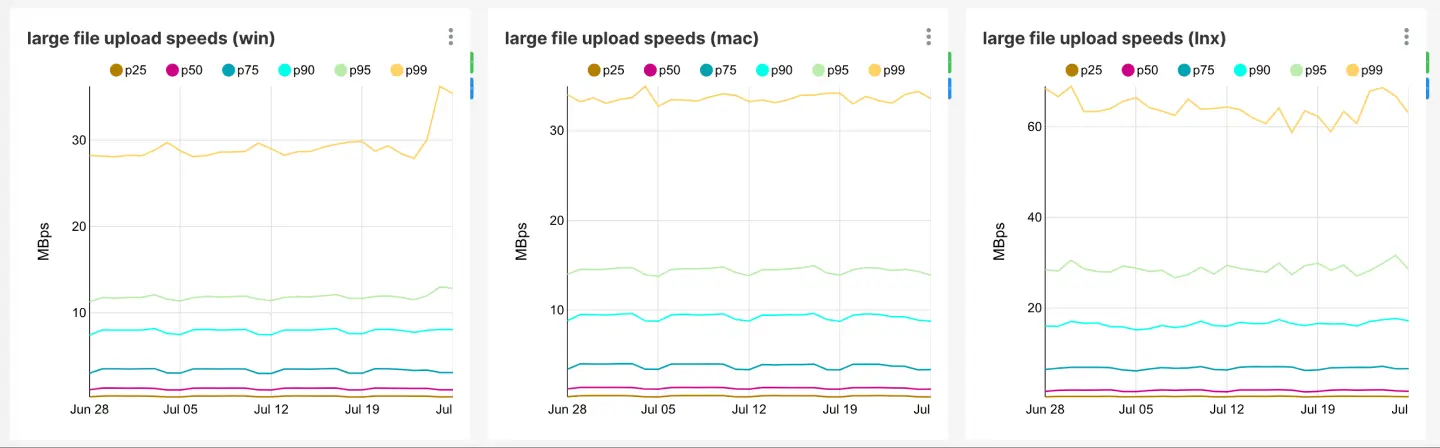
Linux upload speeds here are not representative. The large portion of Linux hosts are servers with dozens of CPUs, RAIDs, and 1+Gbit/s Internet connections.
Microsoft’s long-term fix
This was the end of the story for us, but the Windows Core TCP team started work on adding reordering resilience to the Windows TCP RACK implementation. This concluded recently with the Windows 10 build 21332. It fully implements the recently published Standards Track RFC “RFC 8985: The RACK-TLP Loss Detection Algorithm for TCP,” including the reordering heuristic. This heuristic upgrades TCP to be resilient to up to a round-trip-time worth of packet reordering in the network.
In theory, one can see that the rationale for the reordering heuristic covers our Flow-Director side-effect. One of the Microsoft team explained:
“Upon receiving an ACK indicating a SACKed segment, a sender cannot tell immediately whether that was a result of reordering or loss. It can only distinguish between the two in hindsight if the missing sequence ranges are filled in later without retransmission. Thus, a loss detection algorithm needs to budget some wait time -- a reordering window -- to try to disambiguate packet reordering from packet loss.“
In practice, we reran our tests with the newest available Windows 10 build (10.0.21343.1000) against a single PoP, while toggling ATR on and off. We didn’t observe any upload performance degradation.
Acknowledgments
Even though this specific issue was very deep in our infrastructure network stack, troubleshooting it required work from multiple teams from both Dropbox and Microsoft sides:
- Dropbox Networking: Amit Chudasma.
- Dropbox Desktop Client Sync Engine Team: Geoffry Song, John Lai, and Joshua Warner.
- Microsoft Core TCP Team: Matt Olson, Praveen Balasubramanian, and Yi Huang.
- … and of course all our customers’ engineers who participated in our shared performance improvement sessions!
Update (5/11/2021): For more on recent Windows TCP performance improvements, including HyStart++, Proportional Rate Reduction, and RACK-TLP, read “Algorithmic improvements boost TCP performance on the Internet”, a blogpost published by Microsoft’s TCP Dev team. It goes deeper into the theory behind these TCP features and provides benchmarks for TCP performance under different conditions.
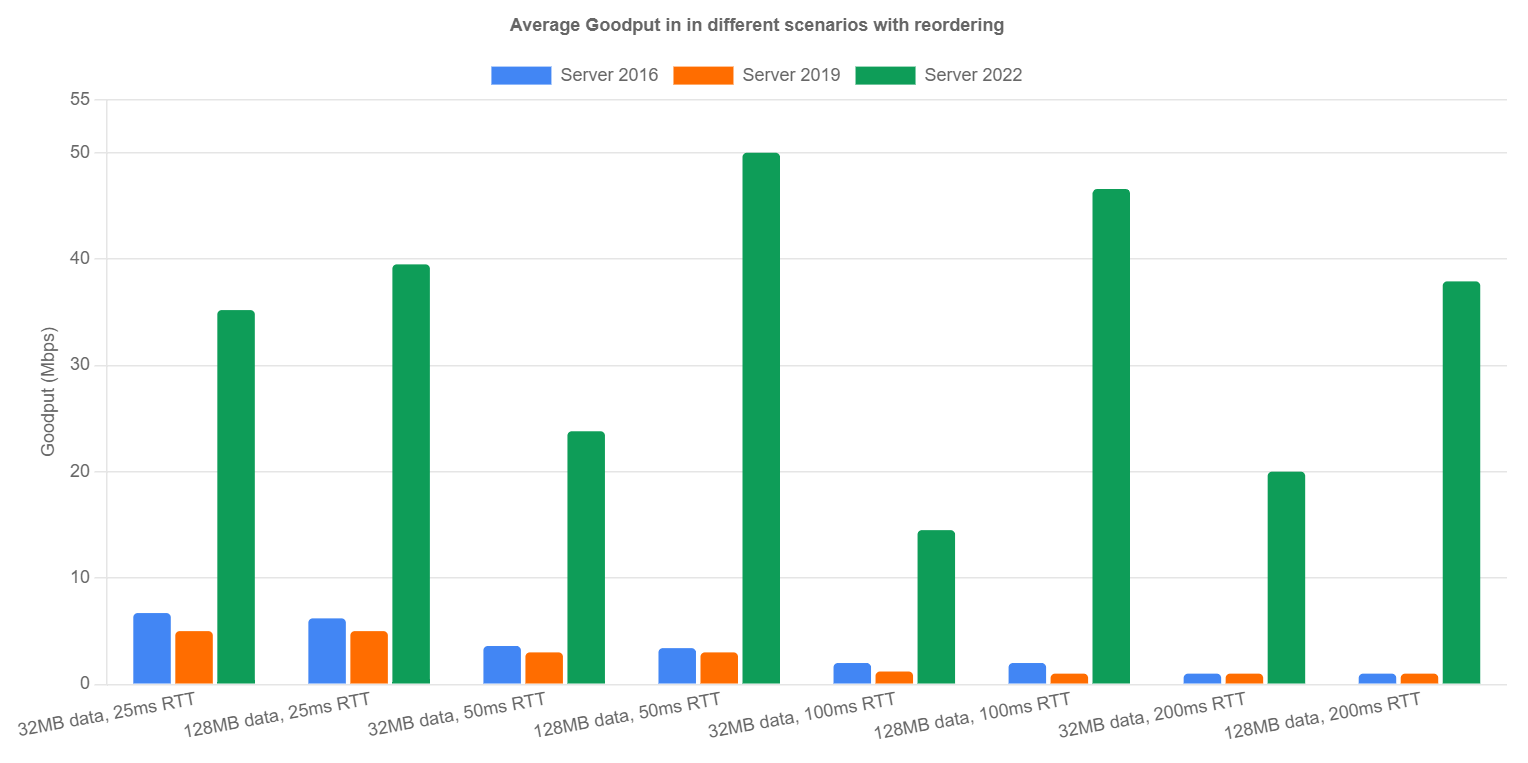
Microsoft’s benchmarks for TCP reordering resilience before and after the full RACK-TLP implementation.
Appendix A. Academic research
We were not the first to stumble upon this problem. Once we identified the culprit and started doing research, we found that it’s a known problem in HPC clusters. For example, here are a couple of excerpts from the paper, “Why Does Flow Director Cause Packet Reordering?” by Fermilab: