

Dropbox syncs petabytes of data every day across millions of desktop clients. It is vital that we constantly improve the sync experience for our users, to increase our users’ productivity in their everyday lives. We also constantly strive to better leverage our infrastructure, increasing Dropbox’s operational efficiency. Because the files themselves are being sent to and from Dropbox during sync, we can leverage redundancies and recurring patterns in common file formats to send files more tersely and consequentially improve performance. Modern compression techniques identify and persist these redundancies and patterns using short bit codes, to transfer large files as smaller, losslessly compressed, files. Thus, compressing files before syncing them means less data on the wire (decreased bandwidth usage and latency for the end user!) and storing smaller pieces in the back end (increased storage cost savings!). To enable these advancements, we measured several common lossless compression algorithms on the incoming data stream at Dropbox including 7zip, zstd, zlib, and Brotli, and we chose to use a slightly modified Brotli encoder, we call Broccoli, to compress files before syncing.
Today, we will dive into the Broccoli encoding, provide an overview of the block sync protocol, and explain how we are using them in conjunction to optimize block data transfers. All together, these improvements have reduced median latencies by more than 30% and decreased data on the wire by the same amount. We will talk about the principles we kept in mind and what we have learned along the way. We will also touch upon how our new investments can help us in the future.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Why now?
We recently finished an ambitious re-write of our sync engine (codenamed “Nucleus”). This rewrite gave us an opportunity to rethink a decade’s worth of assumptions and reimagine what would serve us best for the next one. While compression in our file sync protocol is not a new optimization, new compression research has unlocked a host of new algorithms since we built our original sync engine. Our critical analysis of the new compression options led to even better performance when we rolled out Nucleus.
Why Broccoli encoding?
We had previously been using zlib for years but our measurements indicated we could do better with newer algorithms. While Dropbox had done research into generic file compression algorithms as well as Lepton, a novel image recompression algorithm, these techniques did not suit themselves to operating at network speeds on client machines.
Why the Brotli file format
Our initial research into Brotli was promising, and we identified 5 key advantages.
- File size: Brotli can use unicode or binary context bytes to dynamically select Huffman tables during runtime, which makes a multi-percent difference in final file size.
- Pre-coding: Since most of the data residing in our persistent store, Magic Pocket, has already been Brotli compressed using Broccoli, we can avoid recompression on the download path of the block download protocol. These pre-coded Brotli files have a latency advantage, since they can be delivered directly to clients, and a size advantage, since Magic Pocket contains Brotli codings optimized with a higher compression quality level.
- Security: Nucleus is written in Rust and only Brotli and zlib have implementations in the safe subset of Rust. This means that even if clients sent Dropbox intentionally garbled data, the decompressor resists bugs and crashes.
- Familiarity: We are already making use of Brotli for many of our static web assets.
- HTTP support: Brotli is a standard for HTTP stream compression, so choosing brotli-format files allows us to use the same format to send to both web browsers and Nucleus
None of the other options we tested checked all five of the boxes above.
Broccoli requirements
We codenamed the Brotli compressor in Rust “Broccoli” because of the capability to make Brotli files concatenate with one another (brot-cat-li). We decided on the broccoli package because it is:
- Faster: we were able to compress a file at 3x the rate of vanilla Google Brotli using multiple cores to compress the file and then concatenating each chunk.
- In-process, Simple to use: Broccoli is a function call from Python and a Reader/Writer interface in Golang. Because Dropbox has strict security requirements on running raw C code, Google’s Brotli would need to be run inside a specially crafted low-privilege jail which comes with ongoing maintenance costs and a significant performance degradation, especially for small files.
To unlock multithreaded compression (and concatenate-ability), we would need to compress chunks of the file and generate a valid Brotli output. In our design process we discovered a subset of the original Brotli protocol, if modified, could allow files to be stitched together after being compressed. Read more about what changes we made below in the appendix.
Block sync protocol: An overview
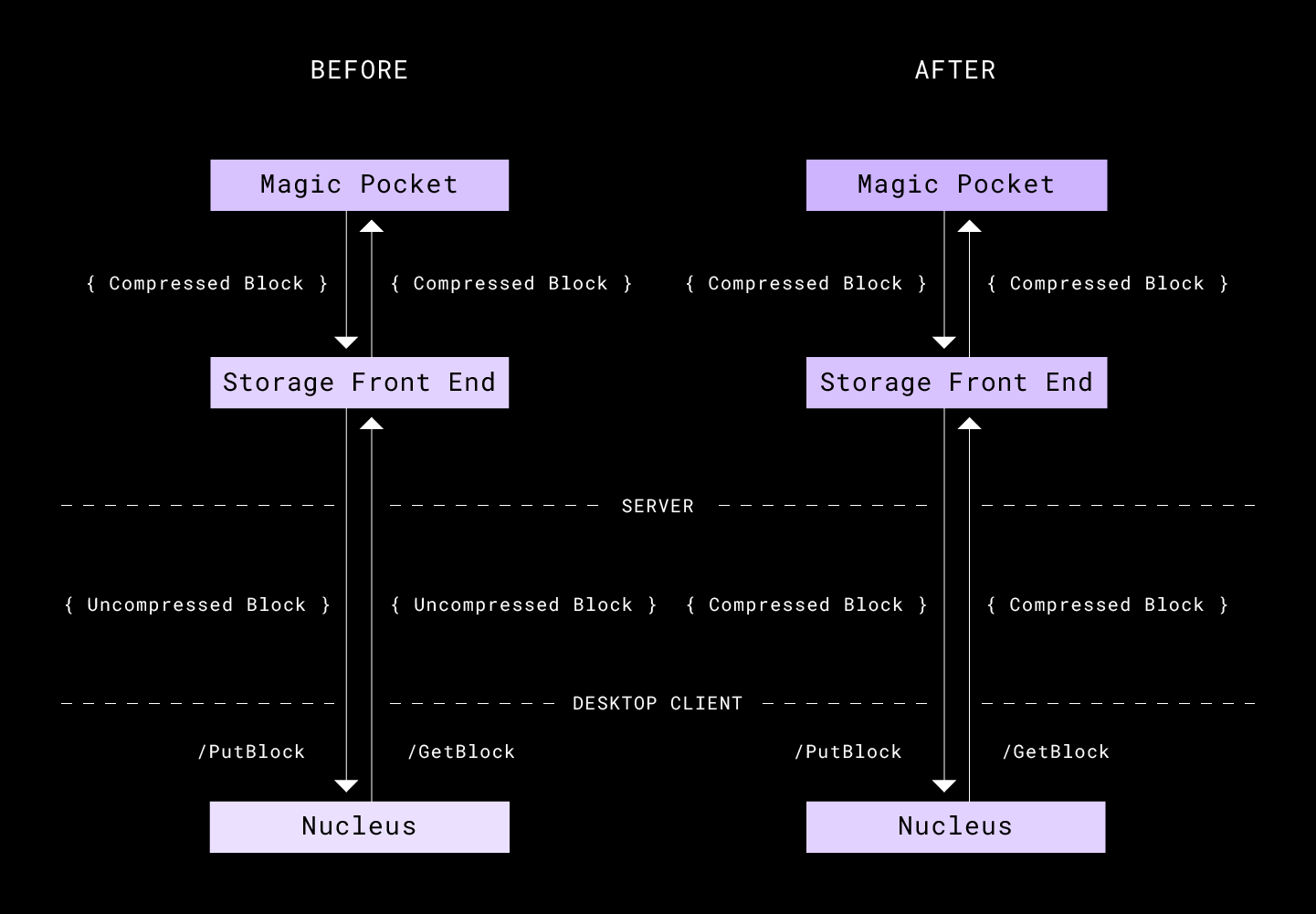
In the following section we summarize how our desktop client uploads and download files to help explain how we layered Broccoli into the protocol. The client sync protocol consists of two sub-protocols: one to sync file metadata, for example filename and size, and one to sync blocks, which are aligned chunks of up to 4 mebibyte (MiB) of a file. This first part, the metadata sync protocol, exposes an interface for the block sync engine to know which blocks are required to be uploaded or downloaded to complete the sync process and arrive at a sync complete state. Today we will focus on the second part, the block sync protocol.
The block sync protocol implements a simple interface to transfer data between the client and the server. After stripping off additional information related to authentication and various other optimizations, the protocol appears as follows:
rpc PutBlock (PutBlockRequest) returns PutBlockResponse;
rpc GetBlock (GetBlockRequest) returns GetBlockResponse;
message PutBlockRequest {
bytes block_hash = 1;
bytes block = 2;
}
message PutBlockResponse {}
message GetBlockRequest {
bytes block_hash = 1;
}
message GetBlockResponse {
bytes block = 1;
}
To perform an upload, the client uses the PutBlock end-point and supplies the block and the block hash. This allows us to check the hash on the server to assert that the data wasn’t corrupted on the wire. On download we ask the server through the GetBlock end-point to return a block for a particular block hash. On the server, the storage layer then talks to Magic Pocket to store and retrieve the blocks.
Compressed uploads
Implementation
For uploads, the path was quite clear because we already allowed for compression on the storage layer. We need to now supply the block format to the newly compressed block and the hash of the uncompressed block.
message PutBlockRequest {
bytes block_hash = 1;
bytes block = 2;
// An enum describing what compression type is needed.
BlockFormat block_format = 3;
}
message PutBlockResponse {}
We need the hash of the uncompressed block because now that we have added a layer of optimization in compression we have also exposed ourselves to a durability issue. Corruption is now possible while compressing the block on the client as our clients rarely have ECC memory. We see a constant rate of memory corruption in the wild and end-to-end integrity verification always pays off.
An extra decompression call on the request path can be expensive, but is needed to make sure the compressed file encodes the original. Thinking about the hard tradeoff between durability and performance is actually very easy for us as we can always pick durability as it has always been table stakes principle for infrastructure at Dropbox. Broccoli decompression is cheap, but we still needed to know if it is non-trivial and if it will have more effects than just added latency. For example, we now might need to scale the number of machines. When we benchmarked different block sizes (the maximum is 4MiB) across different kinds of files, we realized this check operates upwards of 300 MiB per second per core, and this is a cost we are willing to pay for the improvements in overall latency and savings in storage.
Results
For the upload path, we noticed that the the daily average percentage savings in bandwidth usage were around ~33%. When aggregated daily and normalized that 50% of the users save around 13%, 25% of users save around 40%, and 10% of the users benefit the most by saving roughly 70% while uploading files.
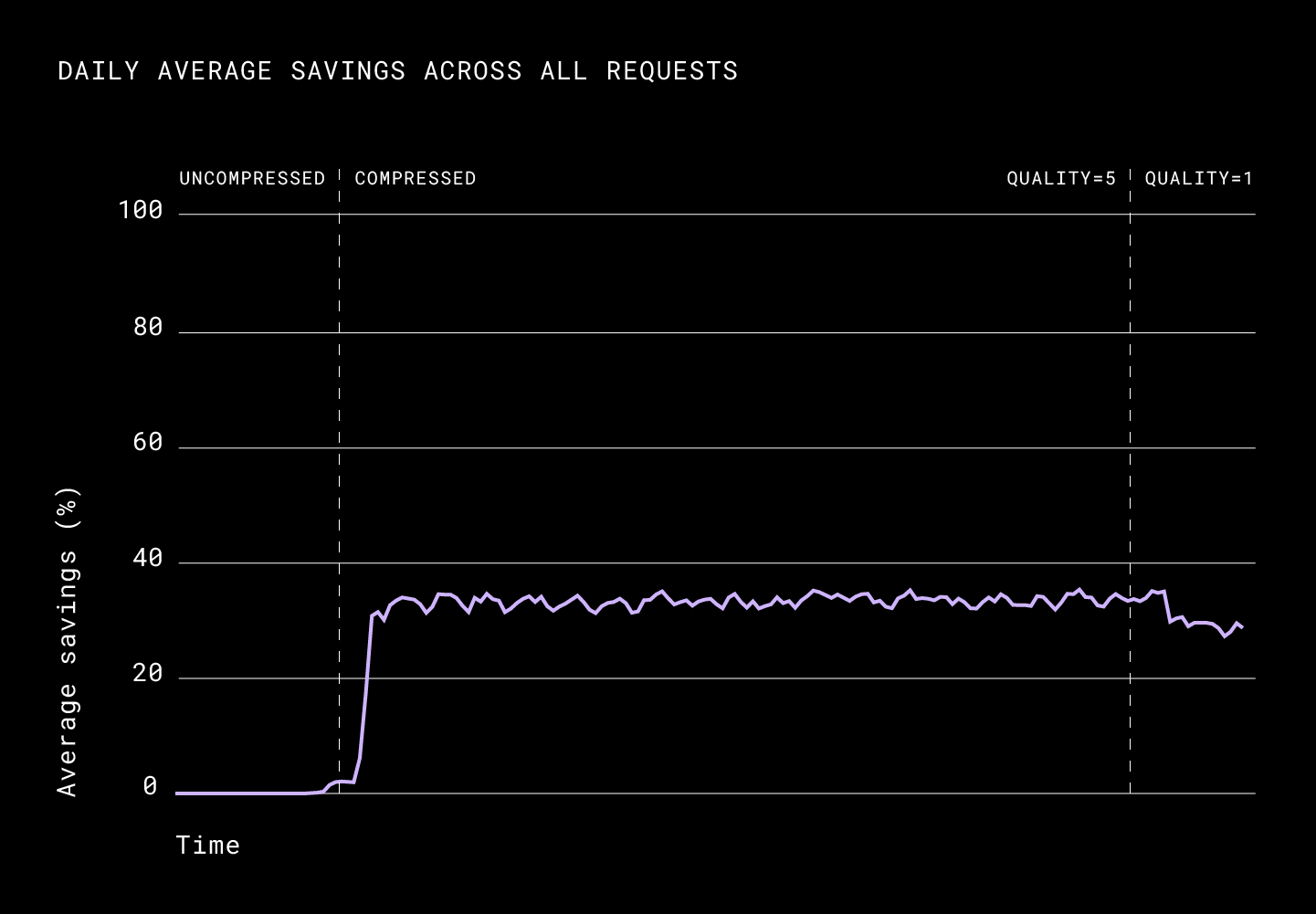
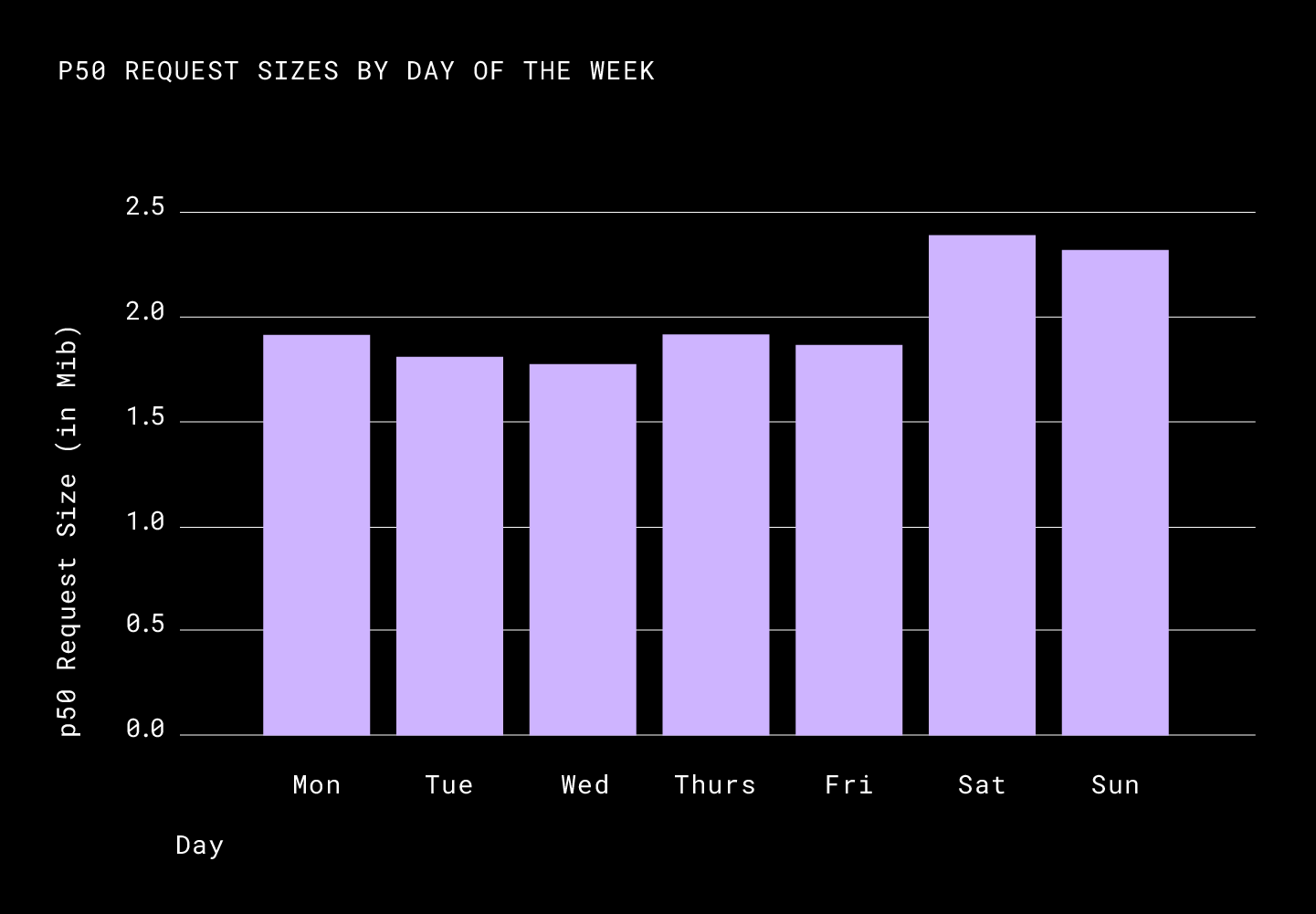
The p50 of the average size of the request was considerably down from 3.5MiB to roughly 1.6MiB per request. We didn’t see any considerable changes for the p75 request size, which points to the fact that more than a quarter of data that Dropbox hosts and serves is incompressible. This was not surprising as most videos and images are largely incompressible by Broccoli. As for latency, the p50 was down considerably again with an average of a ~35% improvement.
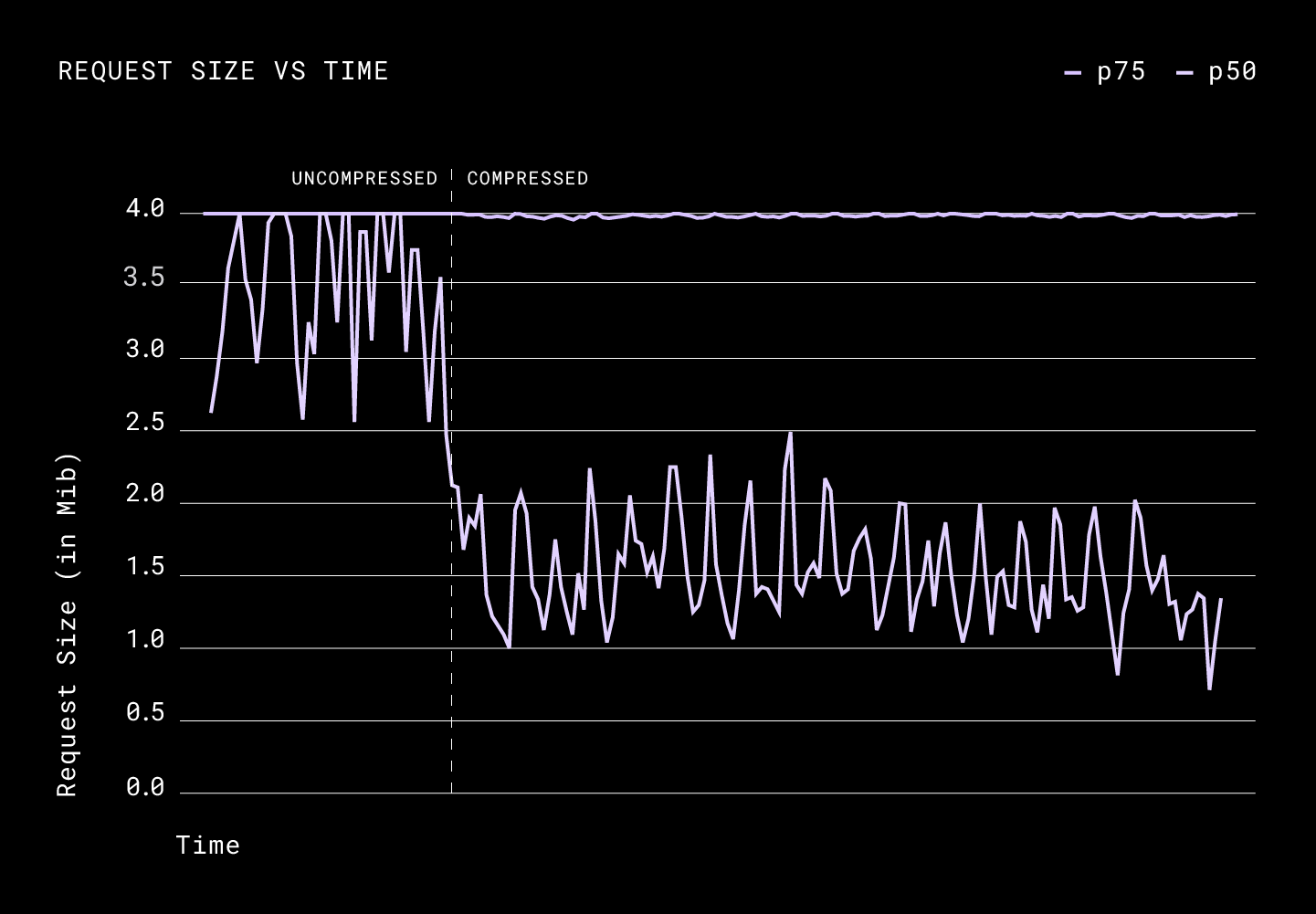
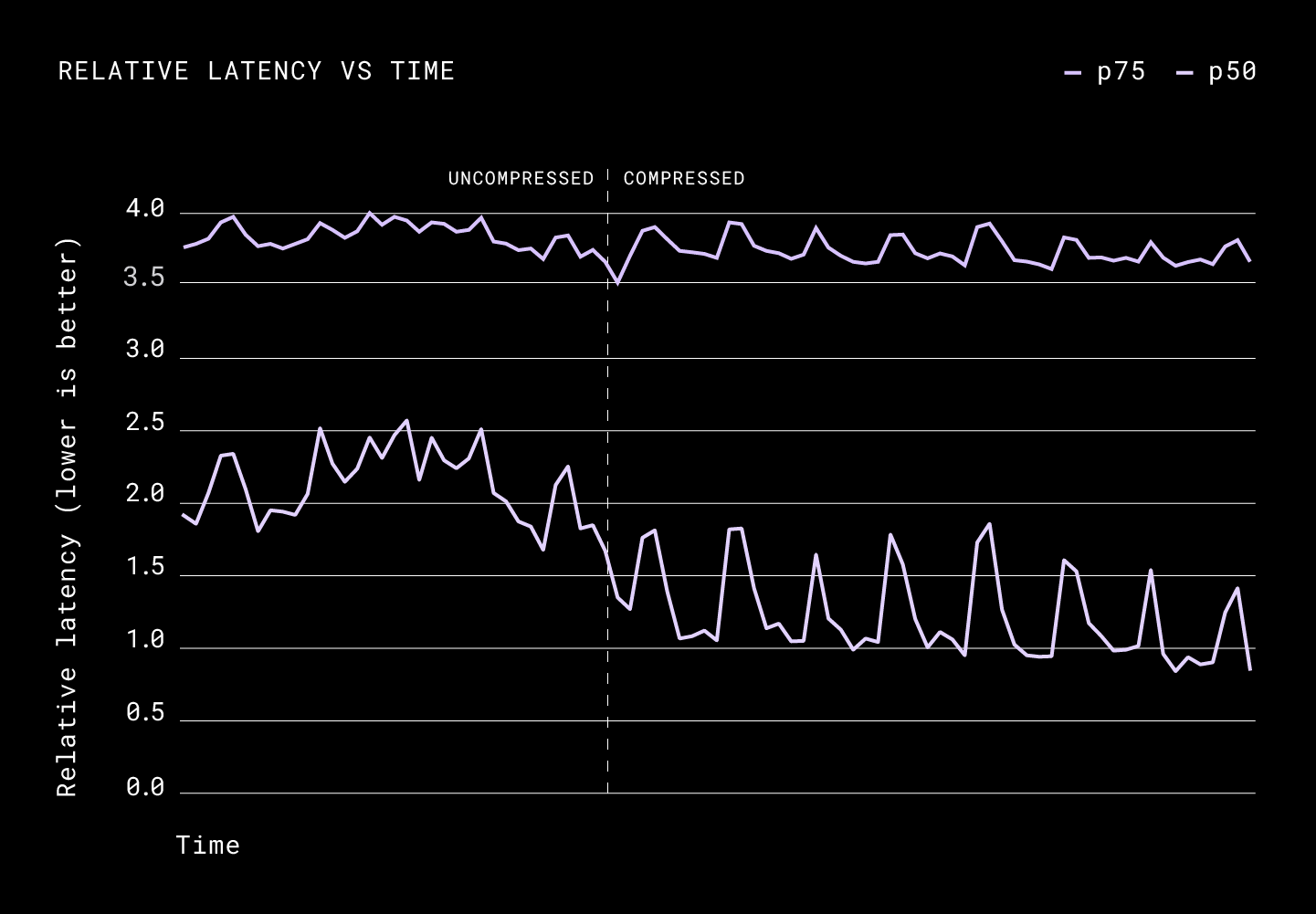
Notice how the request size and latency fluctuate periodically. When grouped by the day of the week we saw was that these numbers differed greatly on the weekend, pointing to the fact that users generally work with highly compressible files, such as email, word and pdf documents, during the week and more incompressible content over the weekend, such as movies and pictures.
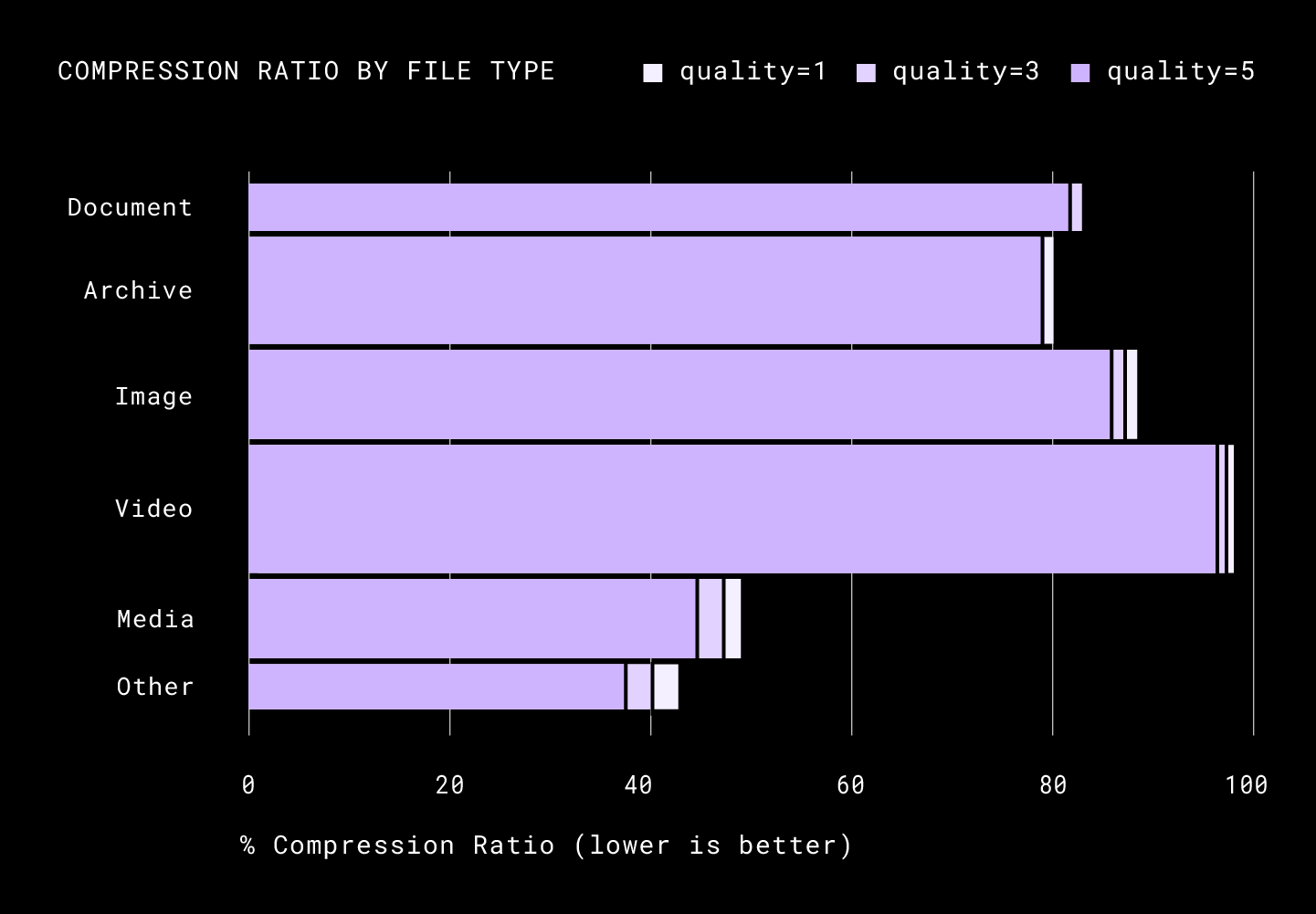
If we break down the upload by file extension, we notice that most of the savings is coming from non-image media, archives, and documents. The figure below shows the compression savings at various quality levels for incoming files. The vertical size of each bar illustrates how large the uncompressed file is as a ratio with all uploads. The area of the bar indicates how much space it occupies in Dropbox’s network pipes after applying each of the three illustrated Broccoli compression quality options.
Deployment Challenges
Rolling out the above changes went relatively smoothly until one of the curious engineers on our network team found that compression was actually a bottleneck on high bandwidth connections (100Mbps+ links). Broccoli allows us to set quality levels and we had chosen the precise settings used for durable long-term storage, which is quality = 5, window size = 4 MiB. After benchmarking we decided to go ahead with a lower quality level to remove this bottleneck at the cost of slightly larger compressed data. This decision was based on the principle of putting the user first, to avoid higher latencies in file uploads, even though it means somewhat increased network usage on the server, for us. After making this change we saw a significant improvement in the upload speeds for larger files as we were saturating more of the bandwidth than before. The possibility of compression being a bottleneck was not obvious to us when we started thinking about the problem and served as perfect reminder to constantly challenge our assumptions.
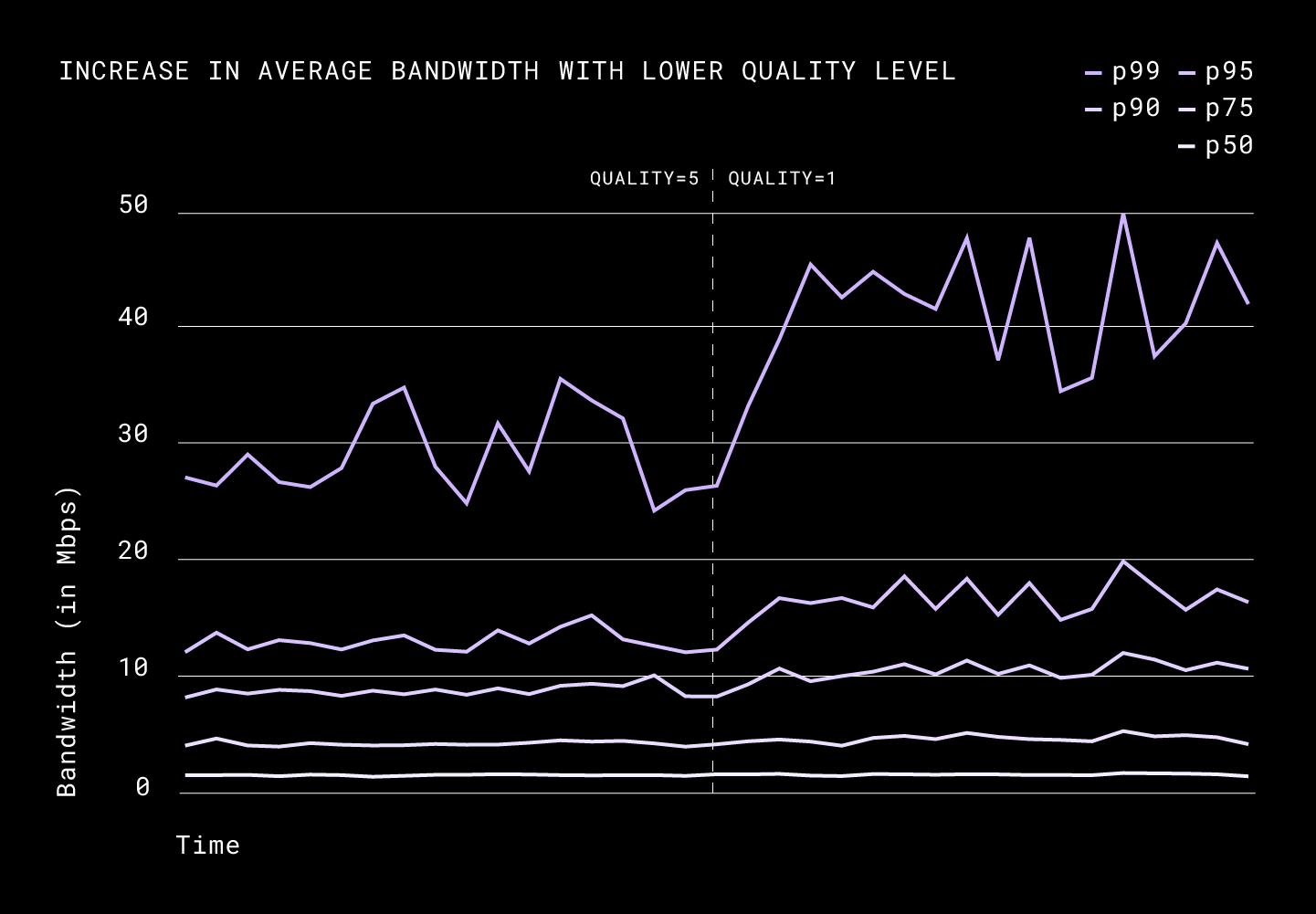
While our overall percentage savings was down from ~33% to ~30%, we managed to speed up the large file uploads bandwidth from ~35Mbps to ~50Mbps (at peak) increasing upload link throughput.
Compressed downloads
Implementation
The download path was slightly trickier as there were different approaches we could take. Choosing compression format could be either client-driven or server-driven. We ended up doing a combination of the two with the client as the main driver but allowing the server to help guide the client in cases where it’s better to fall back to simpler formats.
message GetBlockRequest {
bytes block_hash = 1;
BlockFormat block_format = 2;
}
message GetBlockResponse {
bytes block = 1;
BlockFormat block_format = 2;
}
This flexibility avoided client-server version skew problems, and it would theoretically allow for an overloaded server to skip out on compression during heavy traffic and return the raw bytes. The other benefit of having the server control the value sent to the client is that we can, with the data available only on the server, decide if compressing is actually the most efficient way to send down the block. It is important to note that in cases where the data is incompressible Brotli adds additional bytes on top to make the size of the compressed block larger than its uncompressed version. This happens more frequently for small blocks and since we know the size of the block when we fetch it from Magic Pocket we can decide to just return the data as uncompressed. As we continue to collect more data on what cases are more common than others we can target these relatively minor performance wins.
Results
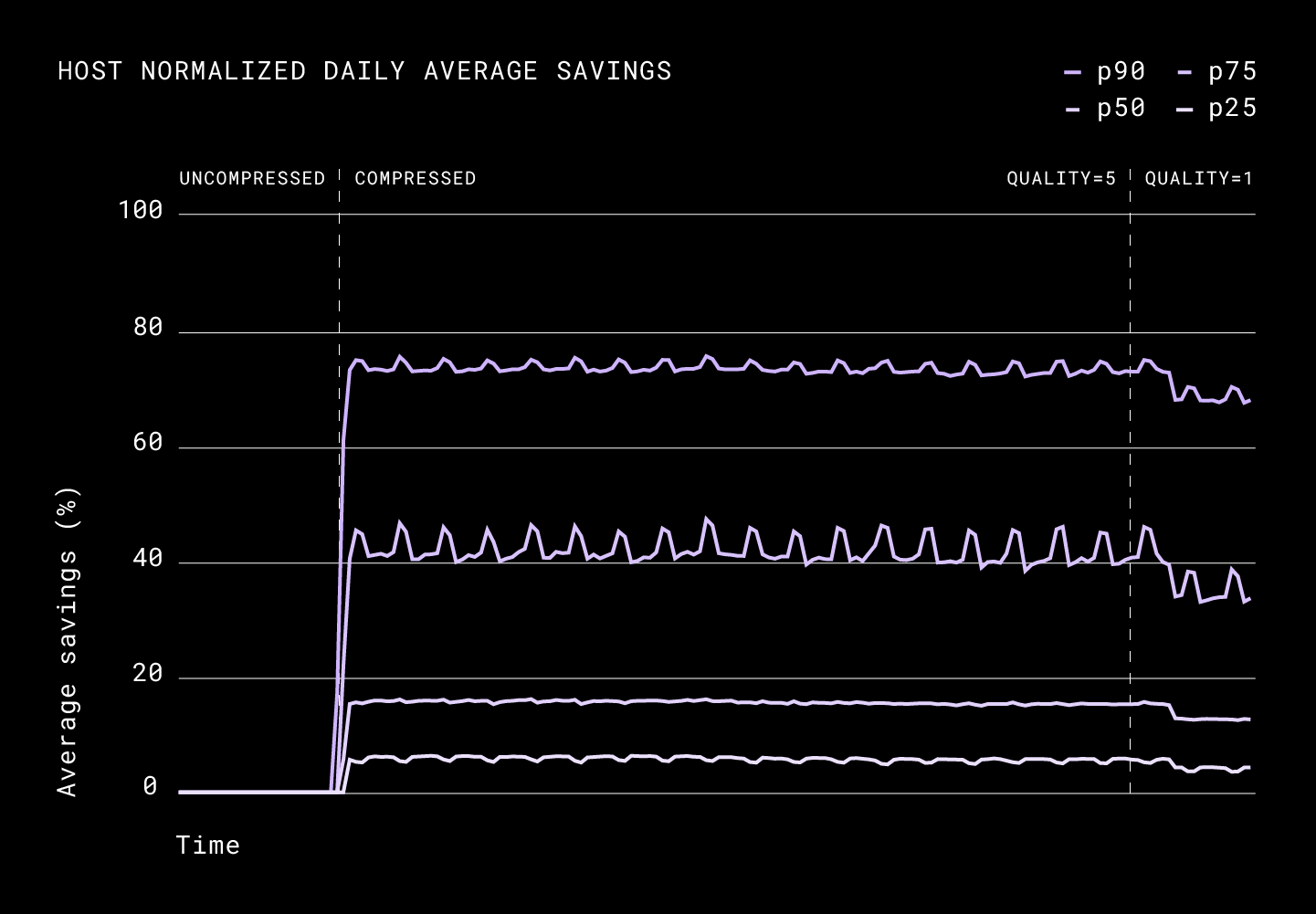
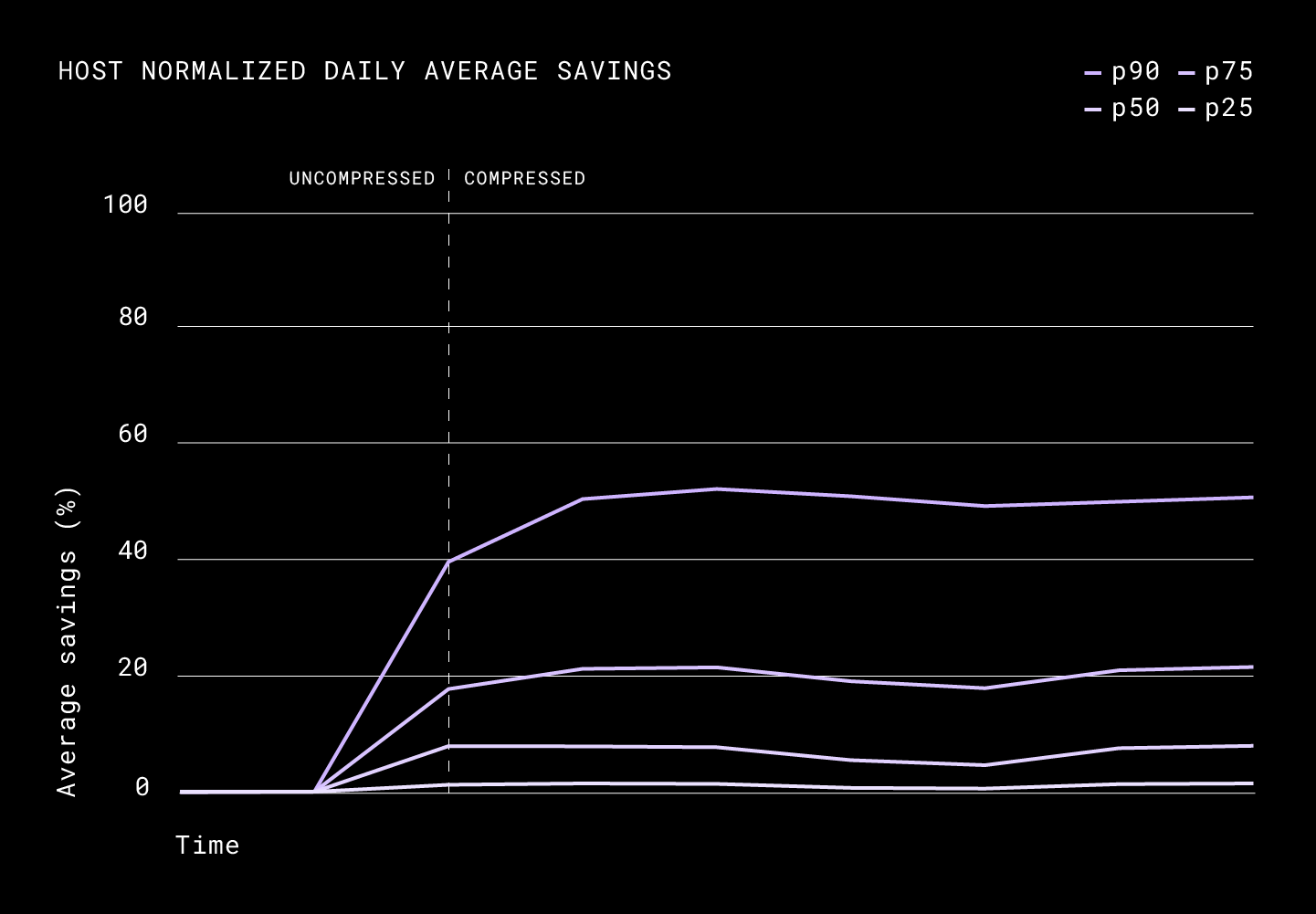
With download compression, we noticed that the average daily savings for all requests was around ~15%. When normalized by hosts, we saw 50% of the users saving 8%, 25% of the users saving around 20%, and 10% of users benefitting most from download compression saving around 50%.
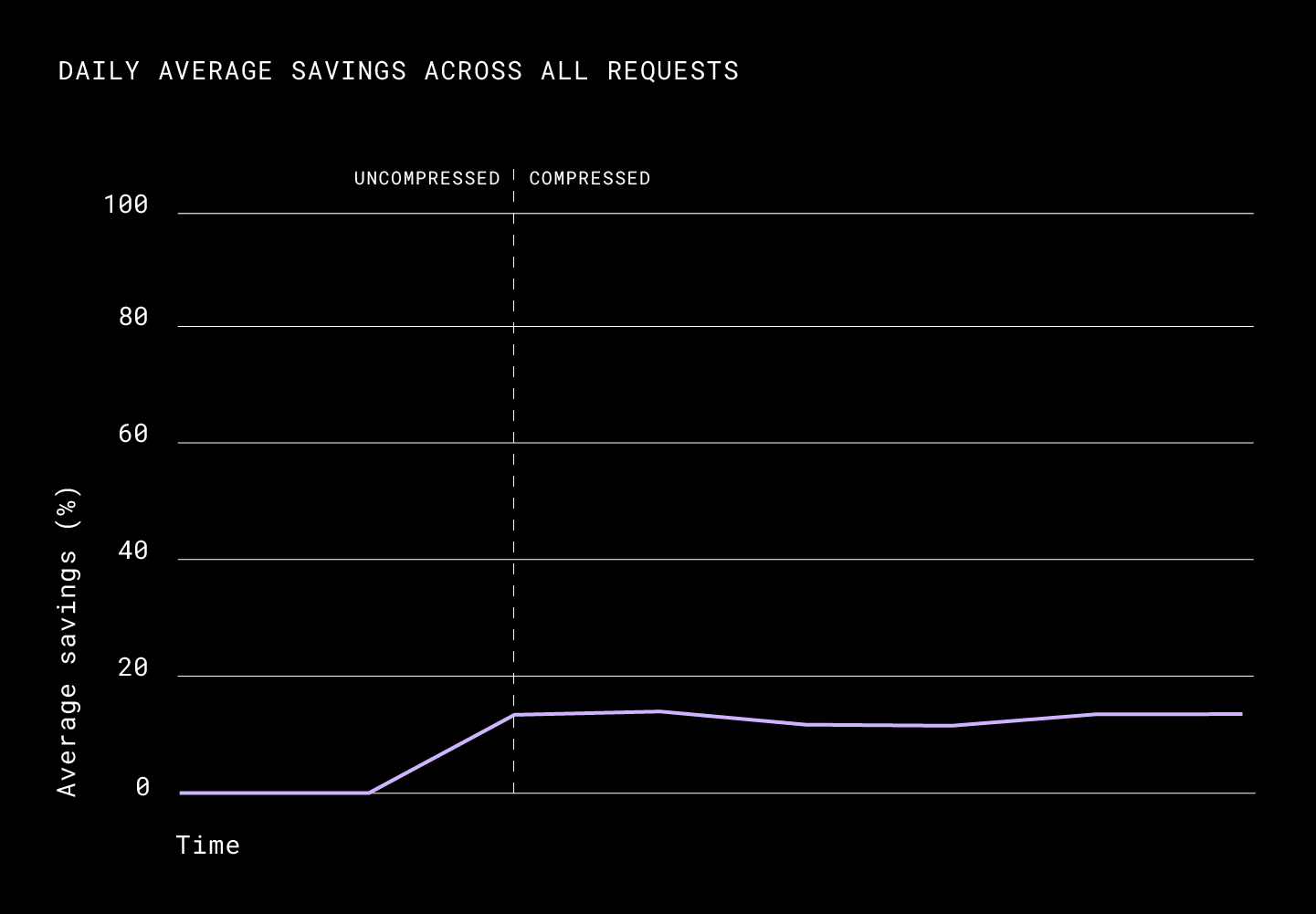
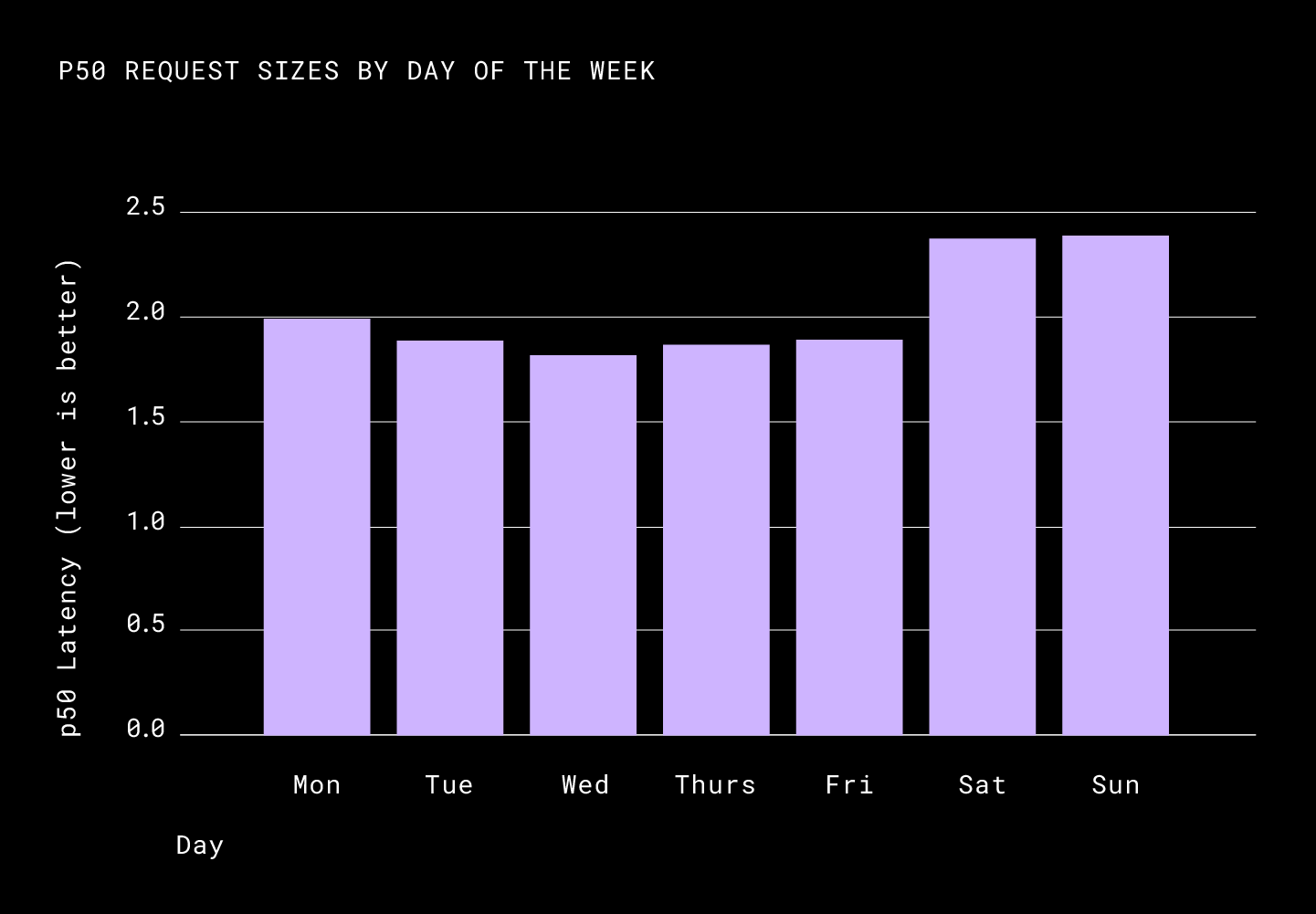
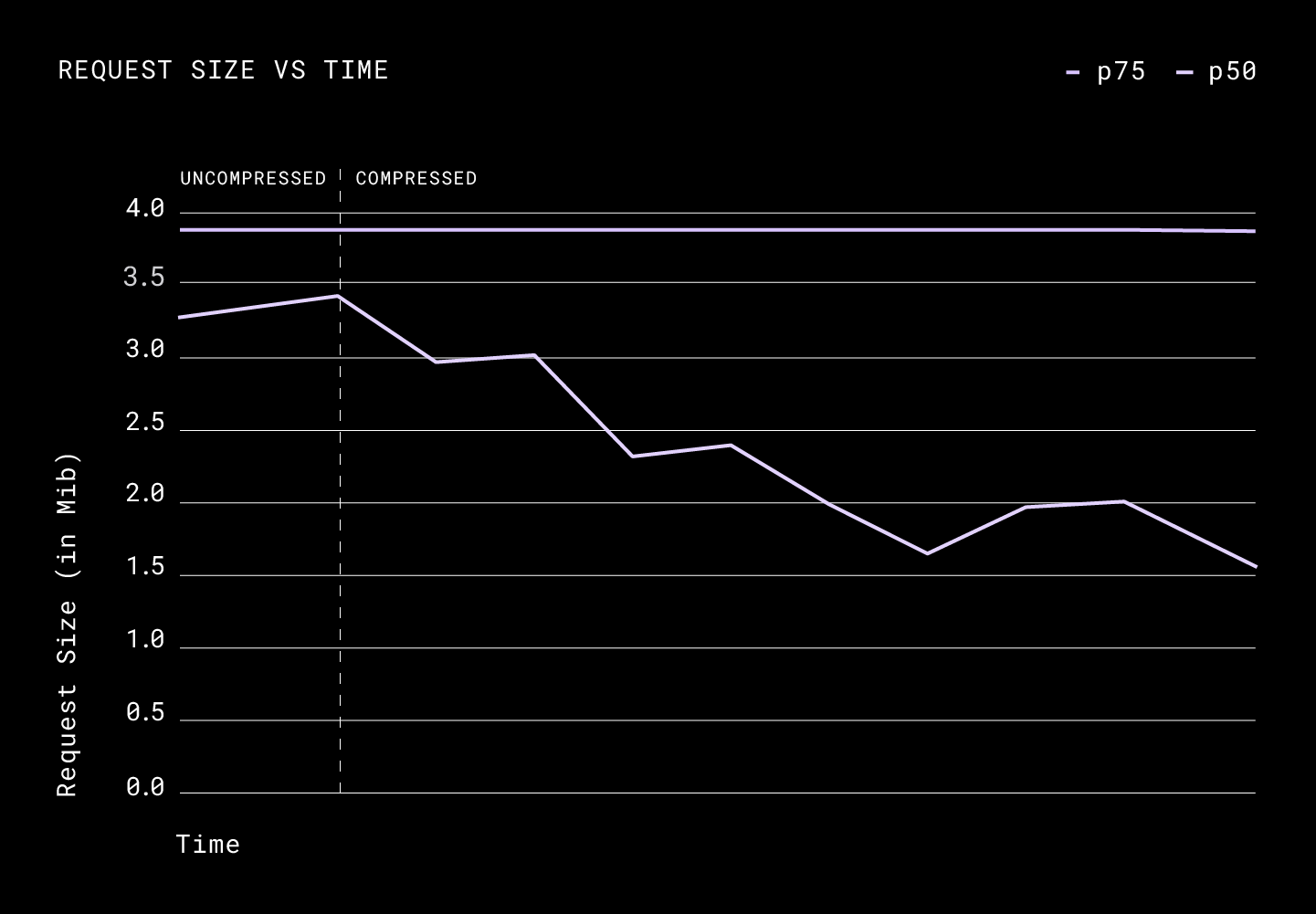
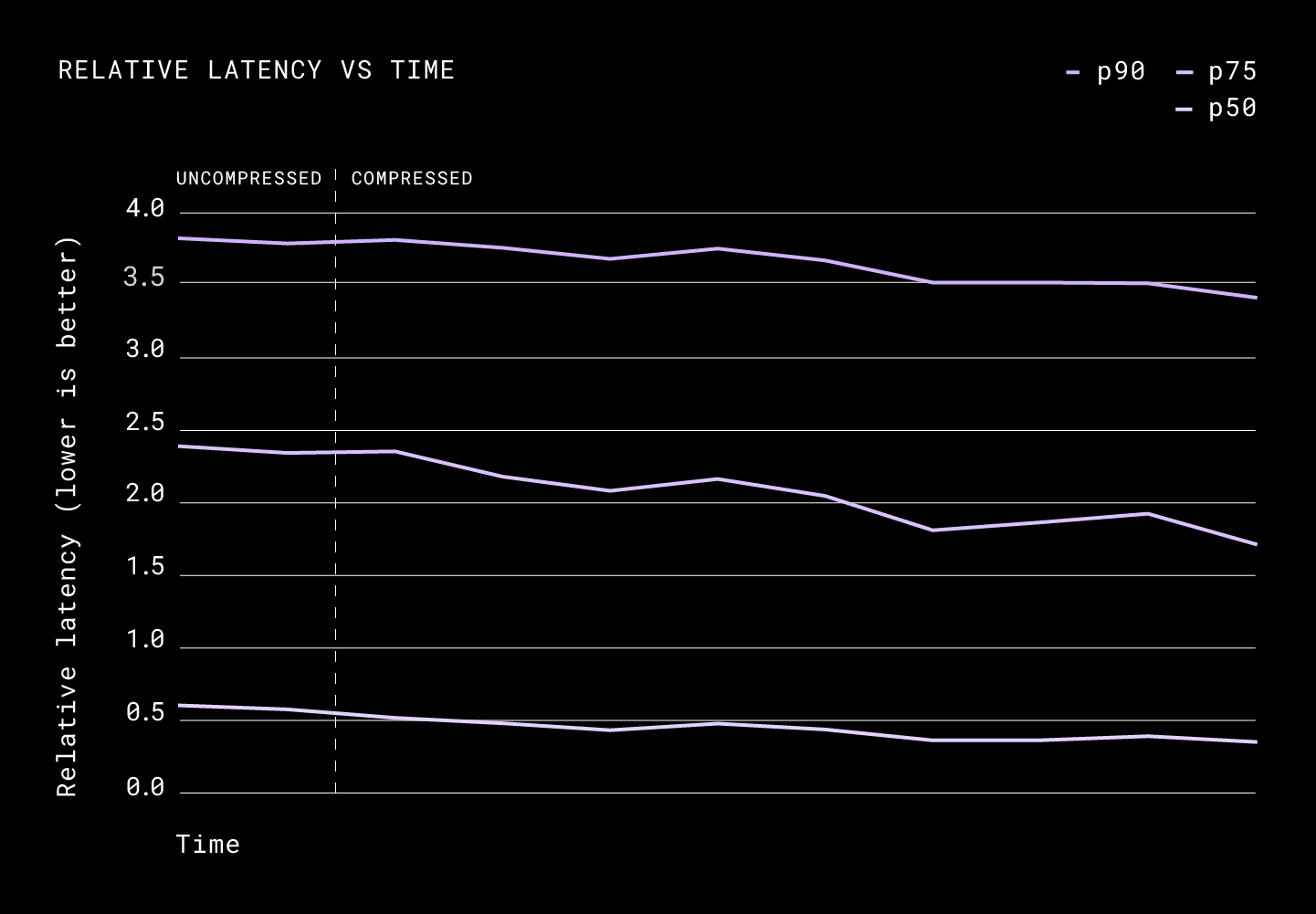
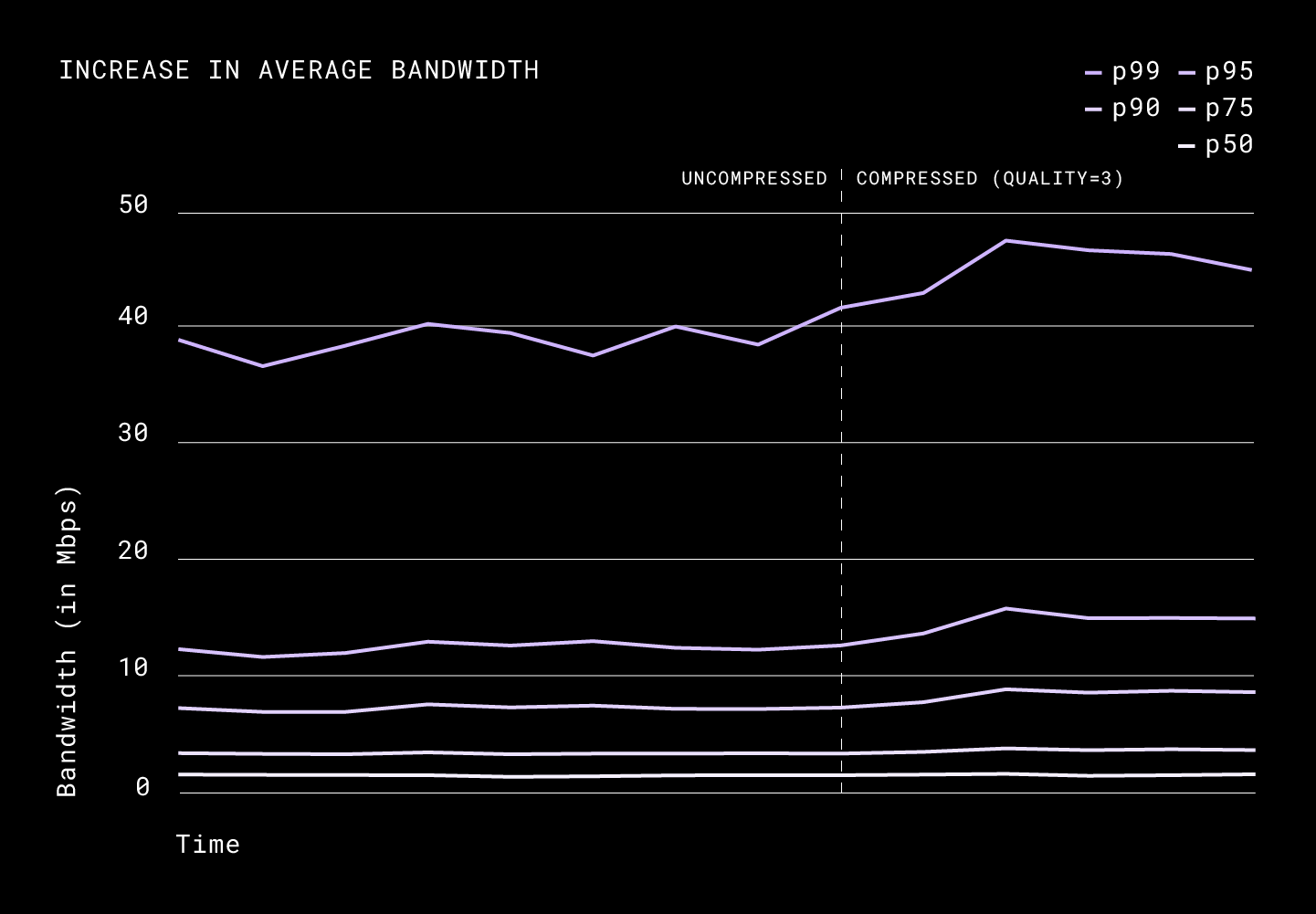
The p50 of the request size was down from 3.4 MiB to 1.6MiB. Unlike what we saw in the results of upload compression, compressed downloads impacted the latencies heavily. We saw a 12% improvement in the p90, a 27% improvement in the p75, and a 50% improvement in the p50.
While there wasn’t a lot of change in bandwidth for the majority of the clients, we saw p99 average daily bandwidth improve from 80Mbps to 100Mbps (at peak). This probably means that high bandwidth connections got more out of their download link with this change.
Deployment challenges
Rolling out the changes in the download path hit a hiccup early in our internal alpha rollout (for Dropbox employees only) when one of the clients crashed. We have a zero-crash policy and try to design the desktop client to recover from every known issue. Generally, we believe that one client crashing in internal alpha can lead to thousands of clients crashing when we hit stable. Upon further investigation, we found there were two problems on the decompression path in the client: there was a bug in the decompression library, and we were expecting the decompression to never fail. We fixed this by switching off sending compressed downloads on the server, committing a patch upstream to rust-brotli-decompressor, and allowing falling back to vanilla downloads on decompression failures instead of crashing on the client. This issue validated having an internal alpha before a stable release as well as our choice of the hybrid client-sever protocol in deciding compression technique. As for the crash, it was clear that we wanted to once again fail open on errors in the optimization path by falling back to vanilla path and alerting on the compression failures.
Future work
In the future, there is room for reducing CPU time wherever we can detect that the underlying data is incompressible. We can consider using the following techniques:
- Maintaining a static list of the most common incompressible types within Dropbox and doing constant time checks against it in order to decide if we want to compress blocks
- Before compressing uploads, detecting if we are saturating our upload link or if it is blocked on compression, and then deciding the relevant quality level and window size combinations dynamically
- Using heuristics, which calculate the Gaussian distribution and Shannon entropy of the byte stream, to filter out likely incompressible blocks
As for Broccoli, we have open sourced the Rust library for contributions.
Acknowledgements
We would like to thank Alexey Ivanov, Geoffry Song, John Lai, Rajat Goel, Jongmin Baek, and Mehant Baid for providing their valuable feedback. We would also like to acknowledge the emeritus of the Sync and Storage teams for their contributions in this area.
Appendix: Broccoli protocol
Recap: Brotli data representation
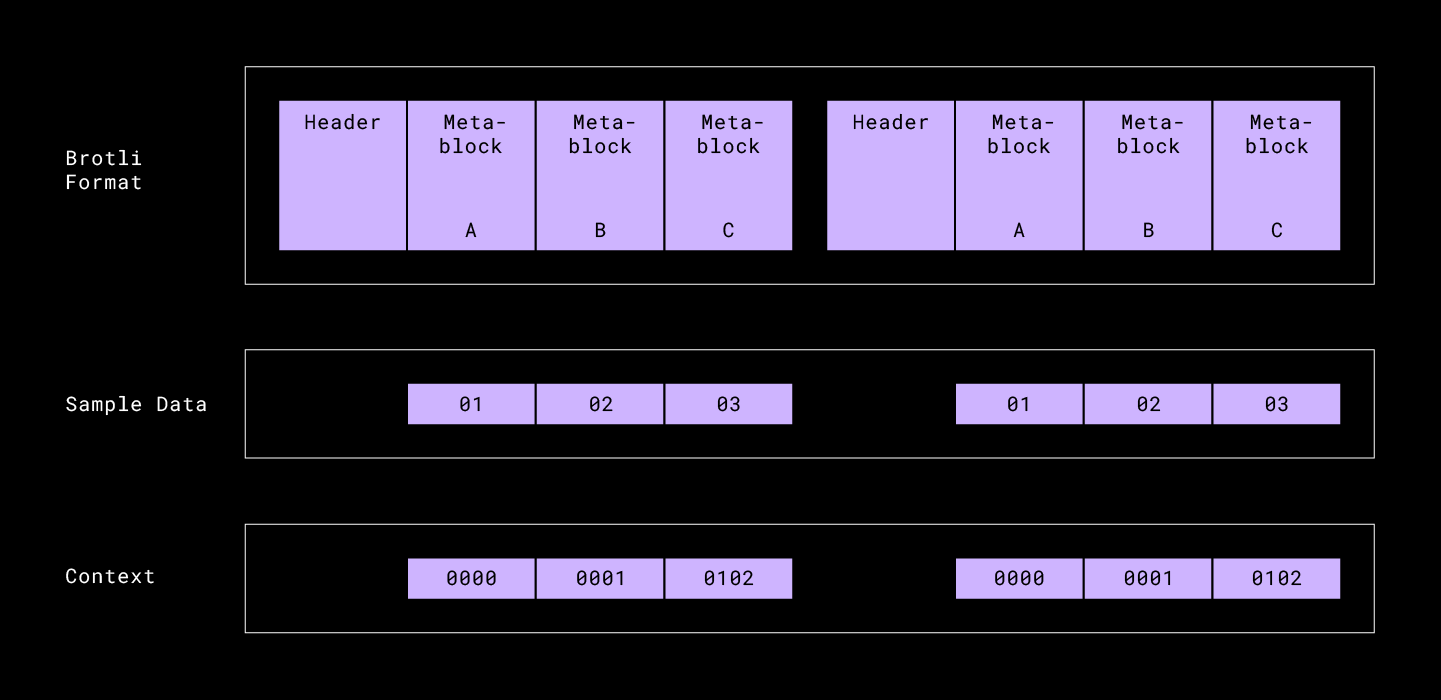
Brotli compressed data consists of a header and a series of meta-blocks. Each meta-block internally contains its own header (which describes the representation of the compressed part) and the compressed data. The compressed data consists of a series of commands, where each command has a sequence of literal bytes and a pointer to the duplicated string that is represented as a pair <length, backward distance>. These commands are represented using prefix codes, the descriptions of which are compacted within the meta-block header. The commands also use a global context to decipher how to apply these prefix codes and how to back-reference the global static dictionary that contains common redundancies. The final uncompressed data is the concatenation of the uncompressed sequences of each meta-block.
Protocol alterations
Some of the conveniences mentioned above make it difficult to concatenate in O(1) time. To address the issues that prevented concatenation, we took each problem in turn.
Context
As the file is decoded byte-by-byte, Huffman tables are selected for each byte using the preceding one or two bytes of the file. Luckily, Brotli has the capability of storing raw byte meta-blocks. So we always configured the first 2 bytes of a file to be stored in its own raw byte meta-block, and so those two bytes always set up the following Huffman table context properly. In the above visual example, if we blindly concatenate the encoded blocks we will observe different contexts for the starting meta-blocks — 0000 for the first meta-block A and then 0203 for the second meta-block A (where as it should still be 0000 based on how it was original encoded).
Bit alignment and fractional bytes
Brotli is bit aligned, not byte aligned. The fraction of the final byte’s used bits is not possible to ascertain without decoding the whole file. Since the first bytes must use raw byte meta-blocks to seed the Huffman table context, we are fortunate that these raw byte meta-blocks are additionally required to be byte-aligned and will always end up on a byte boundary, solving this problem at the same time.
Dictionary
Brotli includes a built-in dictionary of common phrases that are back-referenced while encoding.
Based on the spec, the dictionary is essentially prepended to the file and is accessed by fetching bytes preceding the beginning of the stream. Therefore, if two Brotli chunks are blindly concatenated, then a dictionary fetch in the second block will fetch bytes from the first block instead of from the dictionary. For example in the above visual example, assuming 03 is in the dictionary, a blind concat will result in faulty backward distance for the second meta-block C. While the dictionary is designed to speed up the lookups, in our measurements we found that deactivating the dictionary cost only an excess of about 0.1% additional file size in storage and transfer.
Final meta-block
The bit that marks a block as the “last” meta-block is arbitrarily early in the file and must be scanned for sequentially. In the above example, notice how for the second encoded block we will need to traverse to the header to find the last meta-block. The last meta-block is allowed to contain no output, so we simply used the last meta-block bit code after our final raw byte meta-block. This allowed the last two nonzero bits to be dropped in order to make way for a subsequent file.
Putting it all together
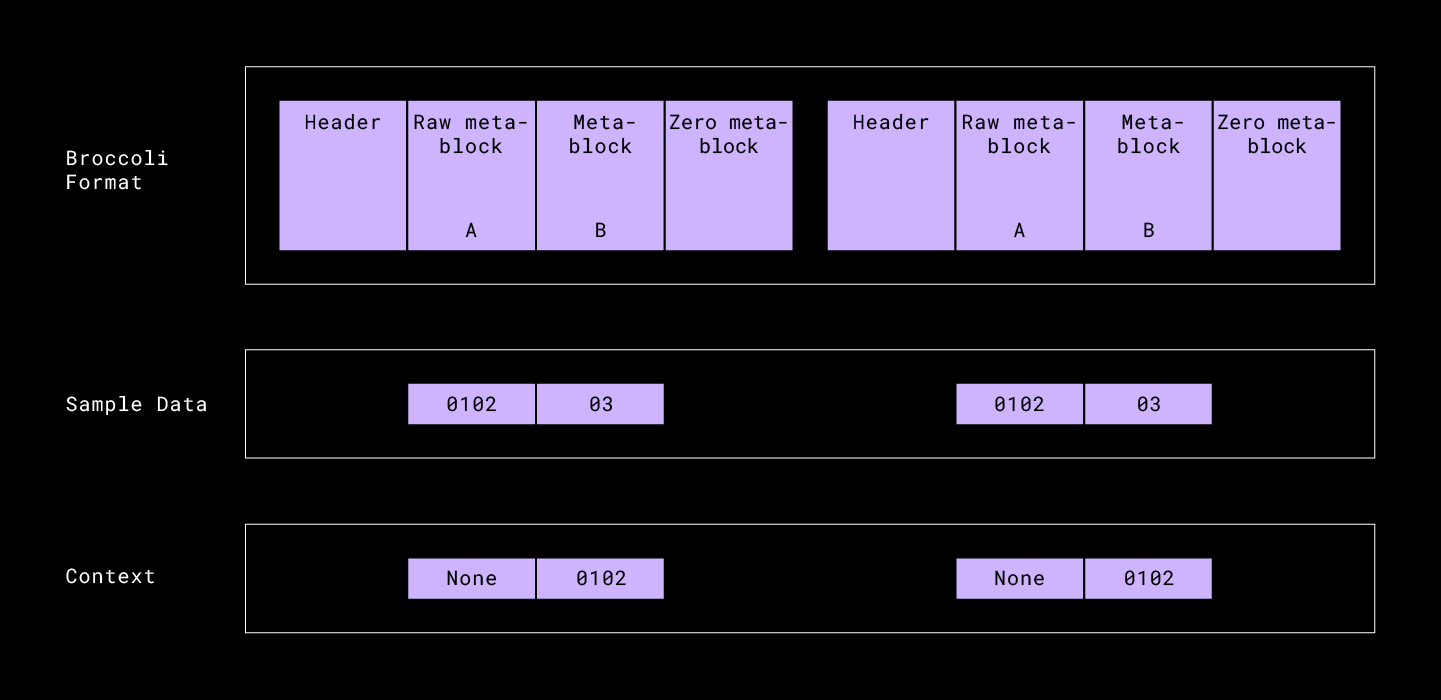
Thus we were able to structure a concatenate-able Brotli stream with these small tweaks to the compressor:
- First, we changed the format to start with an uncompressed raw-byte meta-block of size two, which were the first two bytes of the file stream (and the context). This ensured that the Huffman context priors were correctly chosen and the decompressor could expect byte alignment
- Then, we set the compressor to ignore any matches in the dictionary so we don’t accidentally reference anything we shouldn’t be referencing
- Finally, we made sure the last meta-block was empty (zero meta-block), so it required constant time to identify and drop the last meta-block (the final two bits, followed by zeros)
With these restrictions, we can now concatenate files in constant time by simply removing the last pair of non-zero bits. Additionally we added a custom Broccoli header which encoded the software version of the package that created it so that our blocks would be self-describing. Brotli allows for metadata meta-blocks which contain comments and, in our case, a header. So all of our Broccoli files have the 3 byte magic number e19781 in the first 8 bytes. For more in-depth parsing of the header bytes, see this Golang broccoli header parser.


