

Compressing your files is a good way to save space on your hard drive. At Dropbox’s scale, it’s not just a good idea; it is essential. Even a 1% improvement in compression efficiency can make a huge difference. That’s why we conduct research into lossless compression algorithms that are highly tuned for certain classes of files and storage, like Lepton for jpeg images, and Pied-Piper-esque lossless video encoding. For other file types, Dropbox currently uses the zlib compression format, which saves almost 8% of disk storage.
We introduce DivANS, our latest open-source contribution to compression, in this blog post. DivANS is a new way of structuring compression programs to make them more open to innovation in the wider community, by separating compression into multiple stages that can each be improved independently:
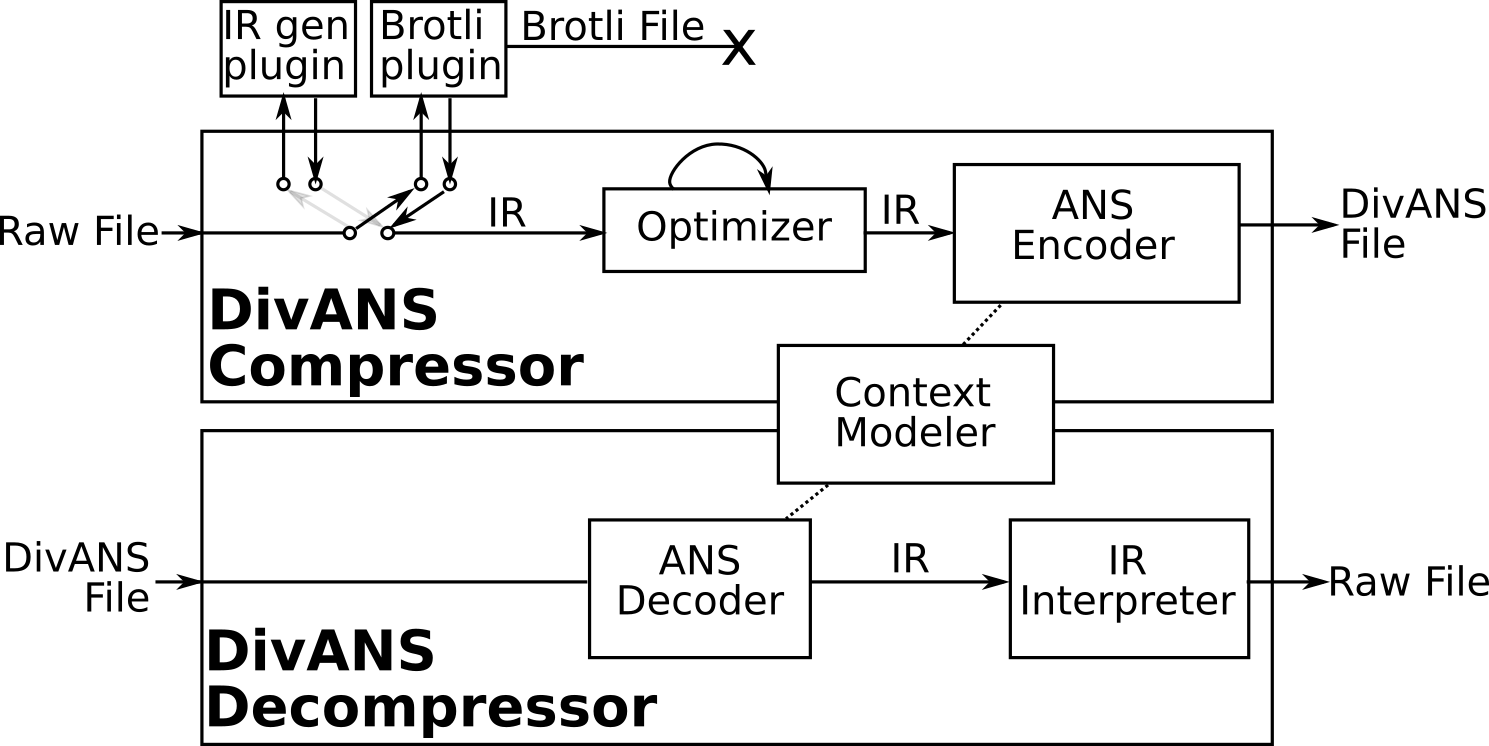
DivANS System Diagram The DivANS Compressor operates in 3 stages (top part of diagram):
- Taking a raw stream of bits from an original file and converting it to a common “Intermediate Representation” (IR) by calling into a plugin. We define a text-based format for a simple but effective IR, partially based on the internal representation that Brotli uses during compression. By making this IR explicit and standardized, researchers can modify any compression algorithm to emit the same IR, which can then be consumed by the following pieces.
- Taking an IR as input and optimizing it, resulting in a better IR. We have implemented a few simple optimizers for our IR so far, but having a standardized IR format allows researchers to experiment with all kinds of different optimizers.
- Taking an IR as input and converting it to a format that can be efficiently written out as bits (e.g., to a file) using a standard compression technique. The text format for IRs we have defined is not itself very compact; for example, it will typically be quite a bit larger than the compressed bitstream that Brotli emits. However, we have developed a technique for efficiently converting the IR into a set of probability tables that can be consumed by modern compressors to output the final stream of bits, with compression ratios competitive with the state of the art.
Conversely the DivANS Decompressor operates in just 2 stages (bottom part of diagram):
- Taking a DivANS bitstream and converting it into an IR representation
- Interpreting the IR representation to return the original file
At first glance, splitting a “single” operation into multiple steps might seem like adding unnecessary complexity. However, it’s instructive to consider the example of language compilers. Primitive compilers compiled a single programming language down to a single machine architecture, conceptually in a “single” operation. At some point in the evolution of compilers, intermediate representations were introduced which, while adding steps to the compilation process, had several advantages that helped propel the field forward:
- Compilers could accept multiple input languages (C, FORTRAN, Ada, C++, …) and emit the same IR for each
- Compilers could apply numerous kinds of optimizations to transform the IR into more efficient code, such as removing dead code, inlining functions, eliminating common subexpressions and propagating constants.
- Compilers could emit machine code for multiple architectures (x86, x86-64, arm, ppc, …)
Crucially, by standardizing on an IR format, it was possible for researchers to work on all of these problems in parallel (independently). We hope to spur the same kinds of benefits for the field of compression with the introduction of the DivANS IR.
In preliminary studies, we have already found concrete gains of 2% in compression ratios for many types of files by using DivANS. We describe these experiments in more detail later on in the post. In addition, we designed DivANS to also meet the following requirements:
- Be secure and deterministic/reproducible
- Decode at more than 100Mbit in a streaming manner
- Have better compression ratios than the best known methods that also satisfy these two properties
The DivANS IR
We chose to develop an IR that uses a Lempel-Ziv (LZ)-based representation of a compressed file. In an LZ representation, there are only 3 kinds of instructions for generating the stream of bytes of the original file:
insert: Insert fresh bytes directly (known as literals), using an entropy code (e.g. a Huffman code). This is the “base case” when you have never seen this data before in any form.copy: Copy previously seen byte data from somewhere else in file. Most files have a fair amount of repetition internally, which we can exploit.dict: Copy data from a predefined dictionary, possibly with some small alterations. There are many kinds of data that repeat not just within a file, but across files. For example, you would expect to see words like “the”, “and”, “that” occur very frequently across all English text documents.
Given a sequence of such commands, we can exactly (losslessly) reconstruct any input stream, but not necessarily very compactly. To achieve compression, we need to be able to predict future bytes based on what we’ve seen so far. This is achieved via the use of several probability tables, that contain statistics of various types. For example, consider a file that consists of alternating chunks of bits all set to 1, and then bits all set to 0. In this case, we’d like to give the compressor a “hint” that says: “if you’re in a ’1’ chunk, then you should assume that the next bits are going to be 1 as well, but if you’re in a ’0’ chunk, then you should assume the next bits are going to be 0.”
Thus, our IR defines a few kinds of such hints, which can help the compressor generate smaller files. These include
prediction: these are the probability tables themselves. Each of these corresponds to a “situation” in which you can guess what kind of bytes are likely to come next. In the example described above, we might have 2 tables, each of which would say that the probability of 1 or 0 is almost 100%.btype{l,c,d}: these are pointers into different parts of the probability tables. In our running example, we would have one of these commands every time we alternate between chunks, to say “now use the probability table for 1s (or 0s) to make your predictions.”
Note that these hints are completely optional—compressors and interpreters are free to ignore these lines and can still get back the original input—but they add enough flexibility to the IR to allow for many kinds of optimizations.
Since there are an infinite number of IRs that describe the same stream of bytes, the key is to find the most efficient versions. In general, this is a balancing act between the extra space it takes to describe probabilities vs the space saved by using them; if this is done badly, it might be more efficient to just insert the bytes directly!
IR generation example
Below is an example of the IR generated from a compression of the test string, “It snowed, rained, and hailed the same morning.” Blue letters indicate fresh data insertions, green letters indicates copies from previously in the file, and red letters indicate data pulled from the Brotli dictionary.
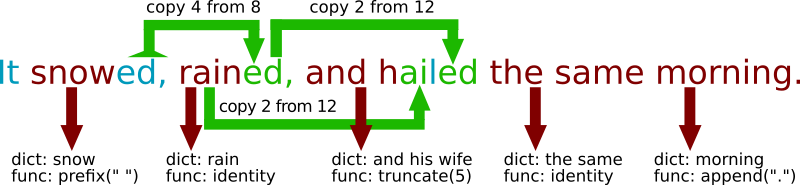
Here's what the IR looks like for this example:
insert 2 "It"
dict 5 word 4,649 "snow" func 6 " snow"
insert 3 "ed,"
dict 5 word 4,288 "rain" func 6 " rain"
copy 4 from 8
dict 5 word 12,552 "and his wife" func 48 "and h"
copy 2 from 12
insert 1 "l"
copy 2 from 12
dict 10 word 9,648 "the same " func 6 " the same "
dict 8 word 7,352 "morning" func 20 "morning."
Notice that only the initial “It”, the first “ed”, and the “l” in hailed are inserted from “scratch”; everything else is copied, either from previously in the sentence or from the dictionary (with small alterations).
Interactive IR Demo
You can see an expanded version of this example, as well as try DivANS on your own files (up to 2MB) interactively at https://dropbox.github.io/divans. Files larger than a megabyte tend to do better in DivANS.
Compressing the DivANS IR
Once we have an IR file, possibly optimized in various ways, we need to serialize it to a stream of bytes that can be efficiently compressed. We rely on Asymmetrical Numeral System (ANS), a method introduced by Dr. Jarek Duda that matches the compression ratio of the more commonly used arithmetic coding, while being considerably faster. These methods offer compression performances close to the theoretical bound—for instance, we showed in our previous blog post on Lepton that transcoding JPEGs previously encoded with Huffman coding with arithmetic coding can reduce the file size by 22%.
These are all entropy coding methods, which attempt to encode each symbol using a number of bits that is inverse of the probability of observing the symbol, i.e., common things are encoded using fewer bits than rarer things. There are theoretical guarantees that this is the most optimal compression scheme, but in practice, the actual compression efficiency is determined by how good your estimates of the probabilities are.
Adaptively Computing Probabilities
DivANS provides the ANS coder with dynamically updated probabilities to achieve maximum compression. It does so by creating a table of Cumulative Distribution Functions (CDFs), known as the prior table, which describes the probabilities of different output symbols in different contexts. DivANS then updates them continuously as the file is processed. In the following discussion, note that DivANS decodes files in chunks of 4 bits (1 nibble) at a time, and each nibble is a symbol for the ANS coder.
The full code is here, but the key takeaway is that several bits from recently observed bytes in the file are used to index into the prior table, where each CDF in the table can be thought of as a “situation.”
Example situations could be:
- A consonant was just seen, so a vowel or repeat consonant are likely.
- A period and space were just seen, so a capital letter is likely to follow.
- A number was seen, so another number (or comma) is likely to follow.
The situations aren’t limited to literal characters only, and can apply to the IR itself, such as
- The last few copy commands referenced data 25 bytes ago; so the next copy command may also reference data around 25 bytes ago.
- The last string literals was 3 bytes long before a copy was seen, so the next batch of literals is also likely to be short.
DivANS uses a selected few of the bits of previous bytes to index into a large table of CDFs, represented as a cube in the diagram below. You can think of this as a lookup function that takes as input recent nibbles and outputs a probability value for the next nibble. Note that it is possible to implement a different set of rules, or even infer rules or the underlying CDF more generally with a deep-learning approach (e.g. with an RNN).
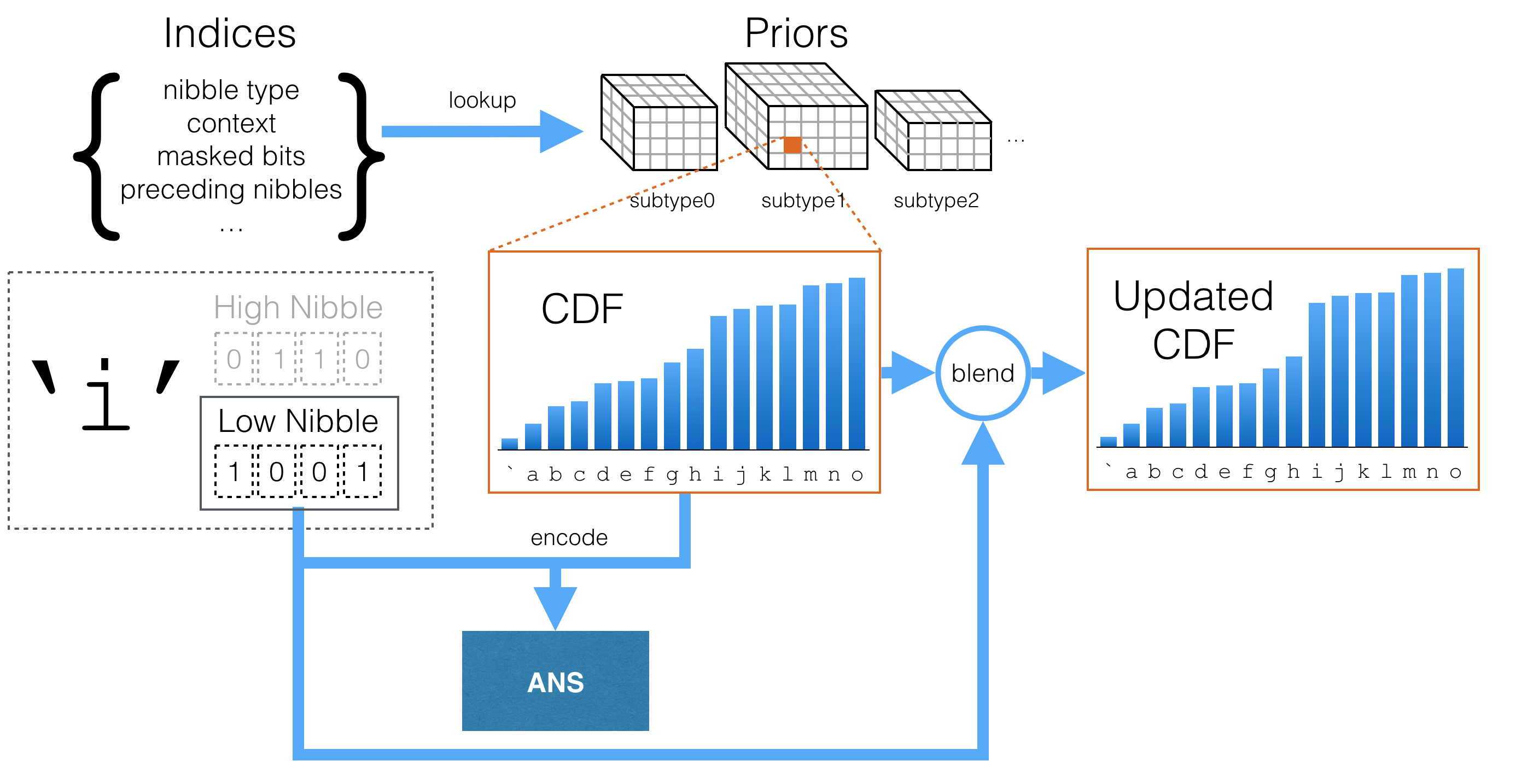
After the next nibble is read, the prior probabilities are adjusted based on the actual value of the nibble. Initially, DivANS assumes equal probabilities for all outputs, and updates them as it goes through the file. One could also encode knowledge about numbers and capitalization rules to begin with, but we instead learn the CDFs without any such assumptions. As the file is encoded and similar situations are encountered over and over, the CDFs start to converge to accurate guesses for future nibbles.
When decoding the compressed byte stream back into the IR, DivANS follows the same procedure to update probability tables so that they can be used to reconstruct what the original symbols would have been, given the actual bytes written to the stream. Note that decoding and encoding have to operate in opposite order of each other; for speed, DivANS encodes in reverse and can therefore decode in forward order.
Experimental Results
Test datasets
We tested DivANS on two datasets. One was the well-known Silesia corpus, which contains medical images, giant html files, and books. However, this dataset has very different compression characteristics than the data stored in Dropbox, so we sampled 130,000 random chunks being uploaded to Dropbox. We measured the sizes and compression (encode) and decompression (decode) rates of DivANS, and several alternative algorithms (zlib, Brotli, Zstd, 7zip, bz2). For DivANS and Brotli, we compared 2 different compression levels (q9 and q11). For zlib, 7zip, bz2 and Zstd, we used maximum settings. All tests were performed on 2.6 GHz Intel Xeon E5 2650v2 servers in the Dropbox datacenters and no data chunks from the test were persisted.
Since Dropbox uses Lepton to compress image files, we only benchmark files where the Lepton compressor was not effective and where zlib obtains at least 1% compression to avoid measuring compression of files that already have a compression algorithm applied. This focuses the test data set down to one third of the uploaded files.
Measurements
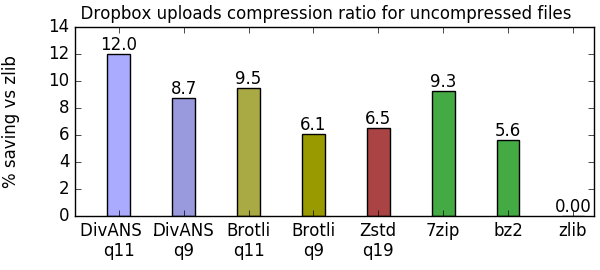
Measuring the Dropbox dataset, DivANS q11 saves 12% over zlib, and more than 2.5% over other algorithms at maximum settings.
If we choose to include files in the benchmark where neither zlib nor Lepton are effective, the benchmark covers all non-JPEG files, comprising two thirds of the uploaded files.
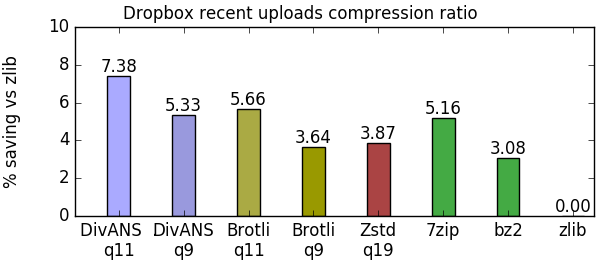
DivANS usually cannot get much extra savings out of the already-compressed files, but on some of the files it can be significantly more efficient than zlib. However, 88% of the overall savings from DivANS comes from processing the third of files that zlib is most effective upon.
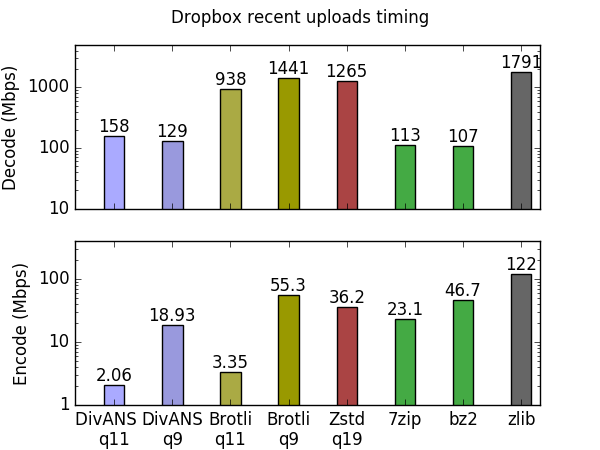
At these settings, DivANS and Brotli have similar encoding speeds. However, DivANS decode times are still five times slower than Brotli. This is because Brotli decompresses bytes using just a pair of table lookups and some bookkeeping, whereas DivANS has to maintain probability models for each nibble decoded and uses several vector instructions to maintain the CDFs and the ANS state. We expect that a few straightforward optimizations to improve the bookkeeping will bring the speed up a bit, to more than 200Mbps.
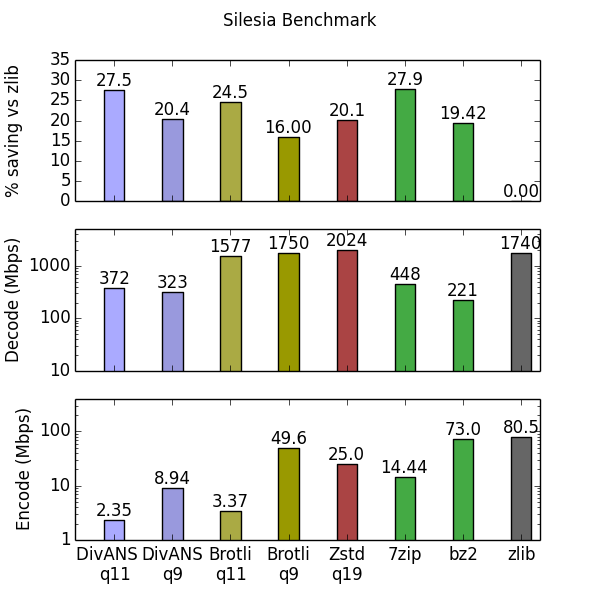
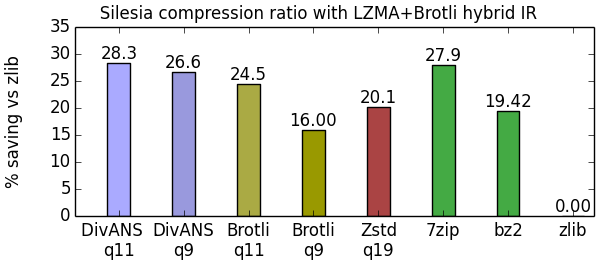
For the Silesia corpus, DivANS q11 gets 2.7% space savings over Brotli and Zstd but lags behind 7zip. However, as mentioned earlier, Silesia is not very representative of Dropbox data.
Hybrid LZMA/Brotli Compression IR Mashup
Notice that the 7zip LZMA algorithm does better on Silesia. This is because LZMA’s produced IR better fits one of the included binary files ( mozilla), which occupies 20% of the archive. As a proof of concept, we demonstrated the flexibility of the IR to capture real-world compression gains. We added 3 print statements to the LZMA codec to produce the standard DivANS IR in its compression routine. Then we wrote a script to interleave the hints from Brotli with the IR from LZMA. The result from mashing up the Brotli and LZMA IR’s improves the overall compression of DivANS beyond the the other algorithms in Silesia. Automating and productionizing this technique would be likely to improve both compression speed and ratio in aggregate.
Closing Thoughts
Research directions
The DivANS system today is already able to get a better compression ratio than alternatives on Dropbox data (albeit with a performance cost). However, we are even more excited about opening up the code and the DivANS Intermediate Representation (IR) to the world. We hope that by lowering the bar for creating new compression algorithms, the community can focus compression research on three separate directions:
- creating efficient IR representations of raw files in significantly less time than DivANS
- optimizing IR representations
- encoding IRs into efficient bit representations
Using Rust: fast, reliable, productive: pick 3
DivANS is written in the Rust programming language, since Rust has guarantees about safety, security, and determinism in the safe subset of the language. Rust can also be as fast as hand-tuned C code and doesn’t need a garbage collector. Rust programs embed well in any programming language that support a C foreign function interface (FFI) and even allow runtime selection of the memory allocator through that C FFI. These properties make it easy to embed the DivANS codec in a webpage with WASM, as shown above.
Rust also recently added support for SIMD intrinsics and has intuitive, safe support for multithreading, colloquially called “fearless concurrency”. We use vector instructions to manipulate the CDFs. We decode the IR commands and the literals themselves each on separate threads. The entire multithreading initiative was started after the decompressor was completely written, and it leaned heavily on rustc‘s guidance to refactor the code into independent halves.
Call to action
Ideally, several disparate algorithms would generate DivANS IR (not just Brotli, and not just in Rust), and ideally other compression algorithms could also take the DivANS IR as input and produce an efficient bitstream from that input. Pull requests welcome!


