

In HBO’s Silicon Valley, lossless video compression plays a pivotal role for Pied Piper as they struggle to stream HD content at high speed.

Inspired by Pied Piper, we created our own version of their algorithm Pied Piper at Hack Week. In fact, we’ve extended that work and have a bit-exact, lossless media compression algorithm that achieves extremely good results on a wide array of images. (Stay tuned for more on that!)
However, to help our users sync and collaborate faster, we also need to work with a standardized compression format that already ships with most browsers. In that vein, we’ve been working on open source improvements to the Brotli codec, which will make it possible to ship bits to our business customers using 4.4% less of their bandwidth than through gzip.
What is Brotli?
Brotli is a Google open source project that includes a versatile encoder with a range of time/space settings. It’s already supported as an encoding format in Mozilla Firefox, Google Chrome, Android Browser, and Opera.
In the diagram below, we’ve depicted Brotli’s impact as applied to typical business use-case files (excluding photographs and video). For a bit of fun, we’ve also included the Weissman score—a metric created for the TV show Silicon Valley for evaluating compression algorithms. Note that the Weissman score favors compression speed over ratio in most cases.
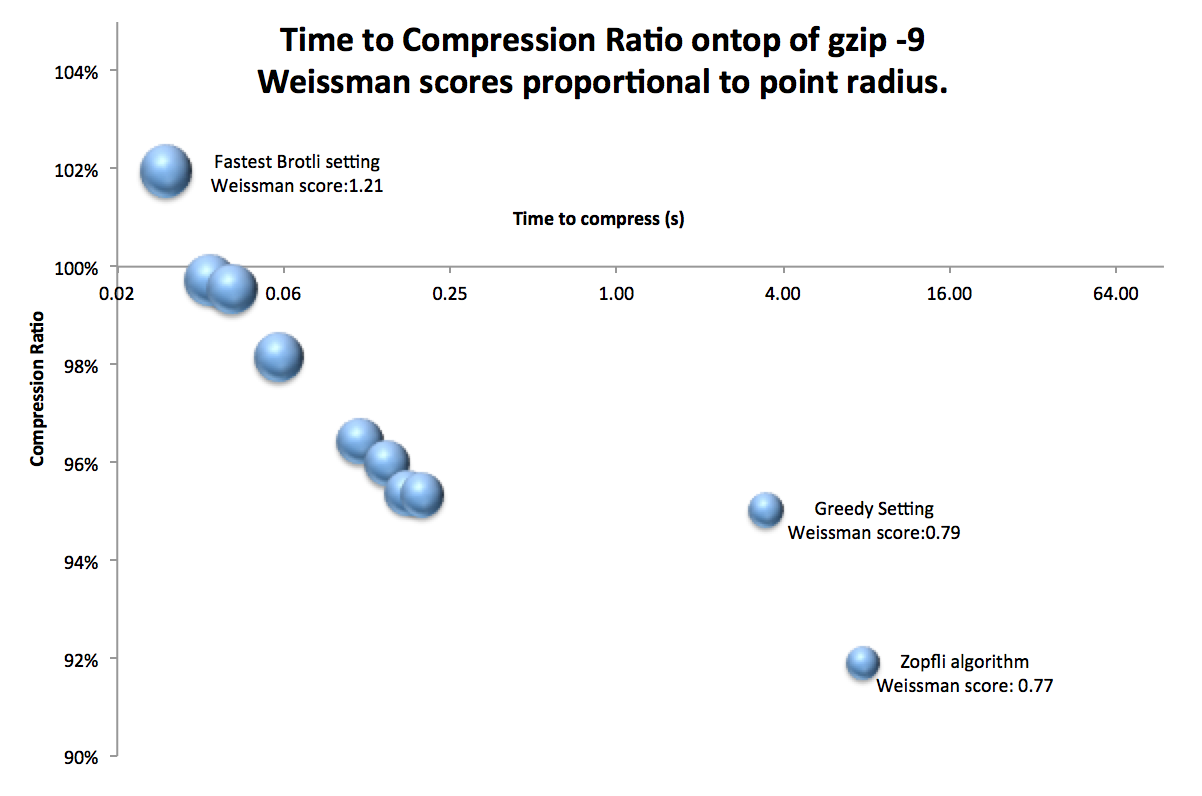
Requirements
We have two main requirements to implement Brotli in our storage pipeline:
1. We need to be able to rapidly ingest bytes in the Brotli format, meaning we need compression that runs significantly faster than line speed.
2. We need to be able to decompress any stream of bytes safely and repeatably.
Speed vs Space
The main challenge for compression on external traffic is the tradeoff between compression speed and compression ratio. On average, each file in Dropbox is written once and read just a handful of times in its lifetime. This means that if our desktop client or mobile client can comfortably compress the data faster than line speed, we save our users’ bandwidth and reduce the time to sync documents.
Unfortunately, with the default settings, which use the Zopfli algorithm, Brotli can’t quite keep up with faster internet connections. For instance, a fast internet connection can upload several megabytes per second, but Brotli may require up to 20 seconds to compress just 4 megabytes of data. As an alternative to the Zopfli compression, using a greedy algorithm like gzip -9 to do the compression can waste up to 10% of the space but can keep up with almost any line speed.
Brotli Overview
To understand tradeoffs in making a Brotli compressor, it will help to give an overview of Brotli. Brotli files have a metablock header which encodes a set of named Huffman tables. Each Huffman table describes shorthand for bytes that may appear in a file. For example, in a Huffman table used to compress an English text file, commonly used letter like a e i o and u would probably be described with fewer bits than z or x, and the bytes describing the letter ø might not have an entry in the table at all.
Here is an example Huffman table that might be helpful in encoding text with lots of h, u and m characters as in the long, Hawaiian word humuhumunukunukuapua'a:
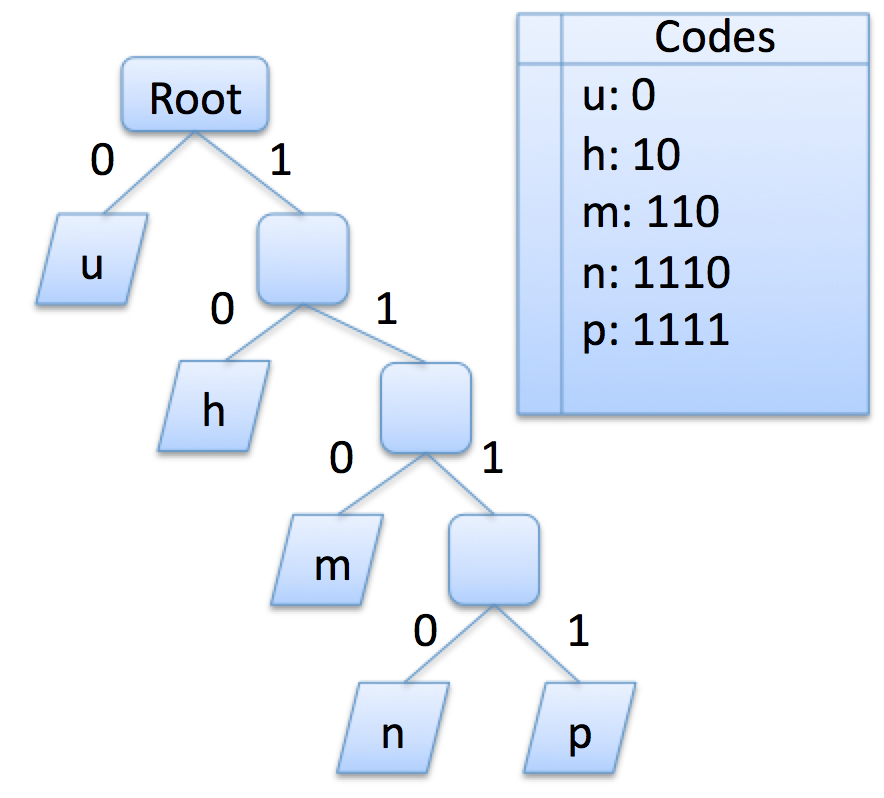
What you see is that the most common letter in the data we are trying to encode, u, is represented high up in the tree with a one-bit code of 0. H, the second most common, is one node down with a two-bit code 10. In this way, the more common letters are represented by fewer bits than the less common ones.
After the metablock header, the rest of the file is simply a repeated set of command blocks. Each command block consists of three things:
1. the index of the Huffman table to use
2. the amount of data to copy from other parts of the file and where to find that data
3. new data encoded using the selected Huffman table.
Effective Brotli Compression
The challenge for the compressor is to figure out when to start a new command block and switch Huffman tables, versus chugging along with the current command block. Each switch costs precious bits, so the tradeoff is a complex optimization. In the greedy mode, Brotli does some trial block splits, then merges with the last or second-to-last block only if the file size would go down. In Zopfli mode, Brotli tries to find the optimal block splits and uses those for the final file.
Here is an example of encoding a long word using the Huffman table above as Table A, with a choice of using a new Huffman Table B.

Our insight was a simple one: optimal may be the enemy of good. In working with compressed data, we noticed that often several distinct ways of representing the data had very similar sizes.
Our approach was simply to exclude 95% of the possible splits from the search. This still allowed for an occasional “creative” split to happen, since we were not restricted to a purely greedy approach, but it avoided most of the overhead with the search approach.
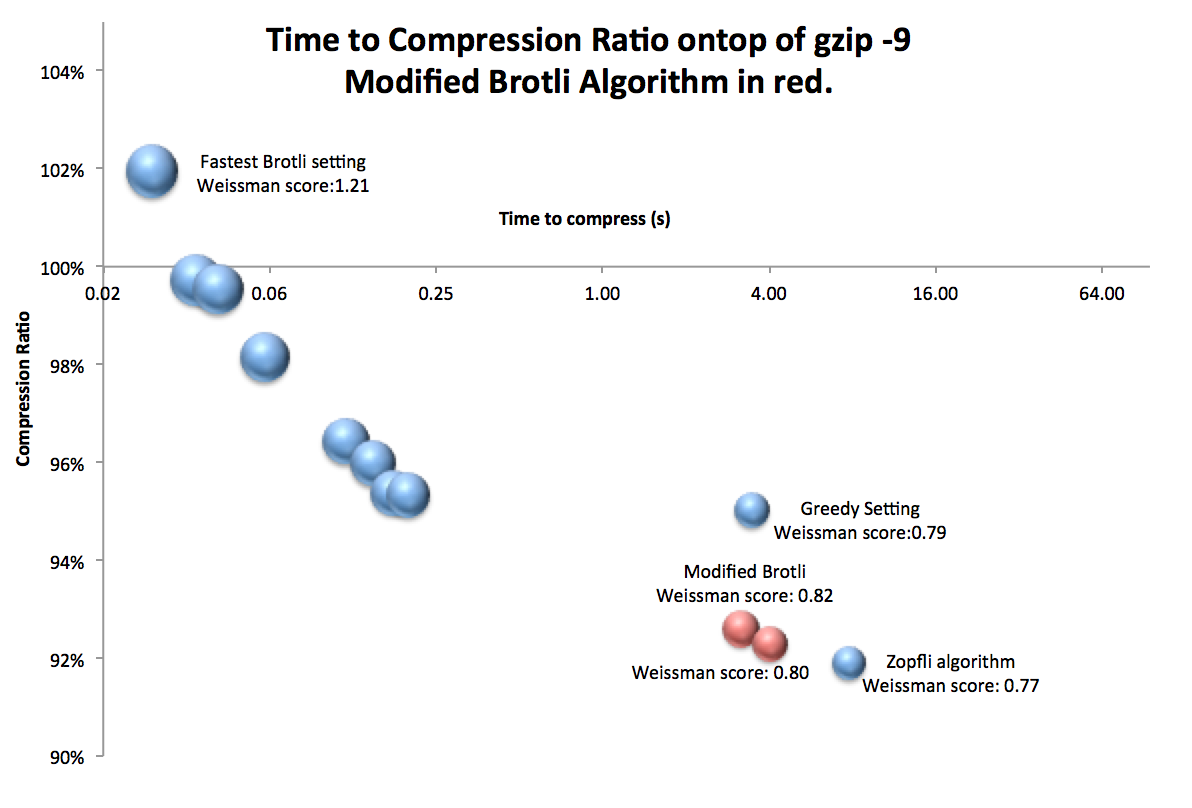
The approach adds an additional 0.45% to the file size when it misses a few optimal block splits, but the compression speed more than doubles, bringing it in line with upload speeds. Including videos and photographs that comprise the majority of Dropbox storage, the final percent savings in bandwidth with the modified Brotli compressor is 4.4%.
As an added bonus, the Brotli Weissman score goes up by 6.5%. I’m sure Richard Hendricks would be gleeful!
Brotli Decompression in Rust
Once the files have been uploaded, they need to be durably persisted as long as the user wishes, and at a moment’s notice they may need to be restored to their original bits exactly in a repeatable, secure way.
For Dropbox, any decompressor must exhibit three properties:
1. it must be safe and secure, even against bytes crafted by modified or hostile clients,
2. it must be deterministic—the same bytes must result in the same output,
3. it must be fast.
With these properties we can accept any arbitrary bytes from a client and have full knowledge that those bytes factually represent the file data.
Unfortunately, the compressor supplied by the Brotli project only has the third property: it is very fast. Since the Brotli decompressor consists of a substantial amount of C code written by human beings, it is possibly neither deterministic nor safe and secure against carefully crafted hostile data. It could be both secure and deterministic, but there is simply too much code to reason through a mathematical proof of this hypothesis.
Operating at Dropbox scale, we need to guarantee the security of our data, so our approach was to break down the problem into components. By writing a new Brotli decompressor in a language that is safe and deterministic, we only needed to analyze the language, not all the code written in it. This is because such a language would prevent us from executing unsafe code (eg. array out of bounds access) or nondeterministic code (eg reading uninitialized memory), so therefore we can trust the code to repeatably produce the same output without any security risks.
The Rust programing language fits the bill perfectly: it’s a language that promises memory safety without garbage collection, concurrency without data races, and abstractions without overhead. It also has sufficient performance for our needs. That means that code written in Rust has the same memory requirements as the equivalent code written in C. At Dropbox, many of our services are actually memory bound, so this is a key advantage over a garbage collected language.
We created rust-brotli, a direct port of the C decompressor into safe Rust. We also went one step further and wrote our own Rust memory allocator that can be used to allocate memory in the standard way using Boxes, or from a fixed size allocation on the heap, or even a pool on the stack.
This allows us to put an upper bound on the memory we would allow for the decode of a single 4MB block. After the virtual memory is allocated, we enable a timer using the alarm syscall, to avoid a runaway process that never returns control. Finally, we enter the process into the secure computing (SECCOMP) mode, disabling any system calls except for read, write, sigreturn and exit.
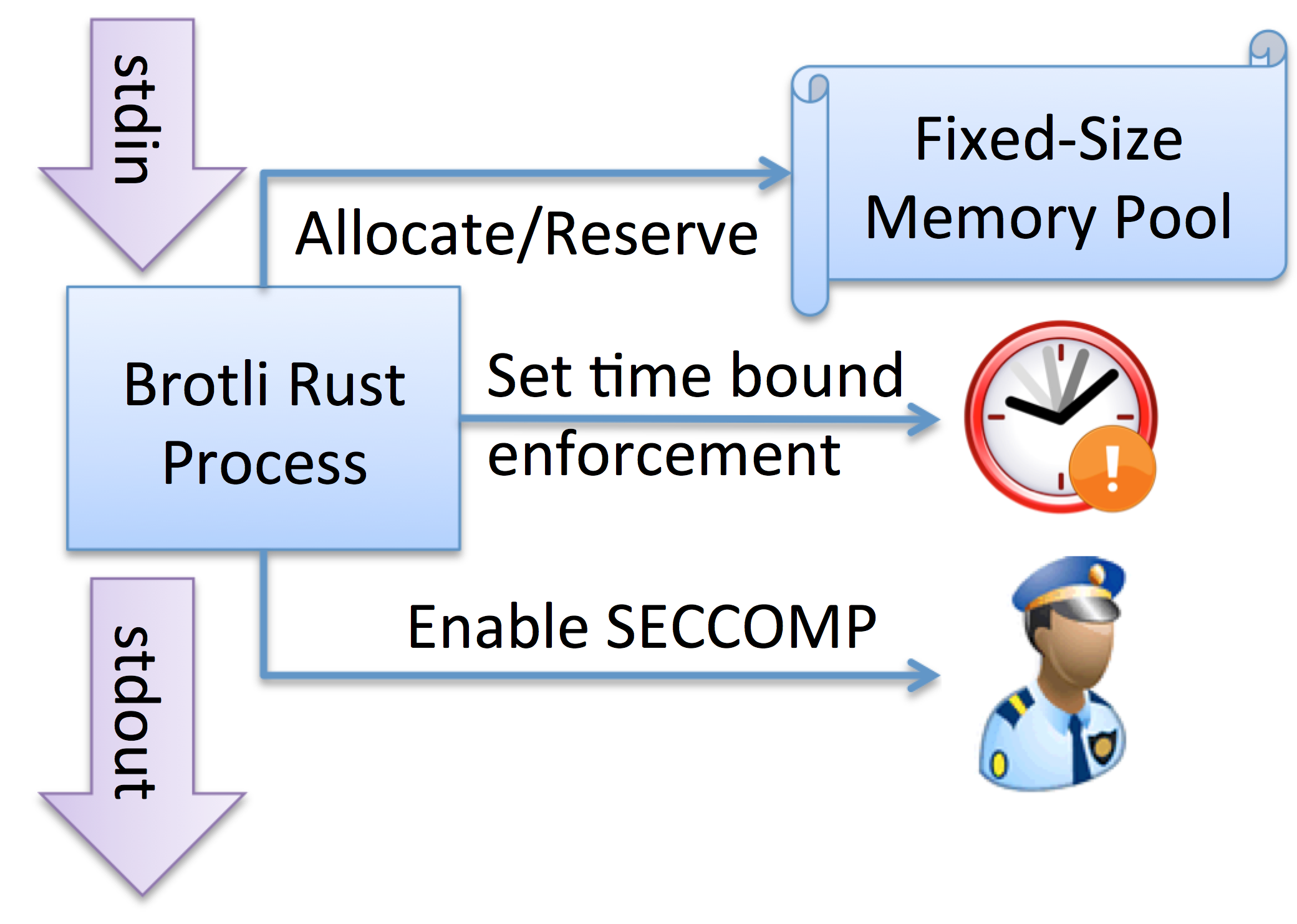
The Port
Porting Brotli from C to Rust required a couple of steps to ensure it met our goals:
1. A foundational memory manager with a malloc-like interface needed to be created to abstract away any stdlib access. This ensured we could add SECCOMP support later and could operate without the stdlib. We created rust-alloc-no-stdlib for this purpose.
2. The bit_reader and Huffman modules were ported directly using the provided memory manager. Unit tests were created by running the C Brotli decompressor on various inputs and recording all data that entered or left the bit_reader or Huffman modules respectively. This made sure that all modules were dependable and could be expected to be correct when debugging the main decoder.
3. The BrotliState continuation structure was ported and lifetimes were mapped. This required discerning which pointers were statically sized data, owned data, or aliases to other data.
4. The main decode loop was ported, with stubbed out helpers. A common pattern in the decode.c was to pass the state struct into helpers alongside a bit_reader or a pointer to a Huffman table. The main loop had to be modified to pull those structures out of the main state struct. Sometimes the state struct could be broken down into related modules that could be independently borrowed by helper functions.
5. The control flow of the decode loop had to be modified to remove gotos and fallthroughs in case statements.
6. Integration tests needed to pass. The major bugs encountered centered around a handful of negative array indices being used to access slices of referenced arrays, the -- operator being interpreted as a no-op (repeated negation) rather than predecrement, and an errors where C performed a shift operation on an integer rather than a byte.
Performance
So given the safety, determinism and correctness, the final cornerstone is the speed of the Rust-based decompressor. Currently the decompressor runs at 72% of the speed of the vanilla -O3 optimized Brotli decompressor in gcc-4.9 for decompressing 4 megabyte blocks of data. This means it is able to safely decompress Brotli data at 217 MB/s on a Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz.
Where is the 28% of the time going?
a) Zeroing memory: Telling the Rust allocator to avoid zeroing the memory when allocating for Brotli improves the speed to 224 MB/s.
b) Bounds checks: decompressing a Huffman coded file with backwards references requires a lot of table lookups.
Sometimes code can have unexpected bounds checks:
fn sum_array_len_2(buffer : [i32], offset : usize) -> i32{
let sum : i32 = buffer[offset + 1];
return sum + buffer[offset + 0];
}The above code counter-intuitively requires not one, but two array bounds checks.
The reason for this is that offset + 1 may inadvertently wrap in release mode (it would panic in debug). This could cause the first overflow check to succeed where the second could fail.
The fix in this case could be to restrict the range of the index variable so it will not wrap:
fn sum_array_len_2(buffer : [i32], offset : u32) -> i32{
let sum : i32 = buffer[offset as usize + 1];
return sum + buffer[offset as usize+ 0];
}On many machines, the usize would give 64 bits of computational range to the addition. On those machines, the Rust compiler is intelligent enough to only insert a single bounds check in the above function since the 64 bit add will not wrap in any case where two 32 bit integers are added.
However, many of the bounds checks cannot be elided like one of the two in the above example. To measure their effect, we made a macro fast!((array)[index]) to toggle between the safe operator[] on slices or else the unsafe get_unchecked() method, depending on whether a --features=unsafe flag was passed to the rust-brotli build. Activating unsafe mode results in another gain, bringing the total speed up to 249MB/s, bringing Brotli to within 82% of the C code.
c) Offsets: The Brotli C code caches direct pointers to buffers and passes those to helper functions or saves them for future Brotli decode calls. Sometimes it even uses negative offsets on those pointers. Rust discourages a class of aliasing errors by enforcing that a single mutable pointer to a given object exists at a time and bars negative slice indices altogether. To operate properly, the Rust decompressor has to track the base slice plus an offset to avoid any negative array accesses and also to avoid two mutable borrows of a single buffer.
d) Control flow: the original codebase had a number of gotos and case statements that would explicitly fall through. Neither of these features are present in Rust and they were emulated using a while loop encompassing a match statement, so that a fallthrough could be translated into a continue, and a break retains the semantics of a C break.
These slight performance tradeoffs are easily mitigated by the fact that Brotli decompression actually is a fully streamable. That means that irrespective of the total time of the decompression, it’s possible to simply decompress the stream of bytes as they are downloaded and to overlap the cost of decompression with the byte download. Thus, only the first or last packets add to the time of the complete download. And since the data can traverse the network compressed, fewer bytes have to be downloaded, resulting in users being able to sync their Dropbox faster.
The security and safety of Rust in a SECCOMP sandbox without the overhead of a garbage collector is a big win. It is worth the minor computational overhead of decompressing in a safe language with bounds checked arrays and determinism guarantees.


