

Dropbox scale
Why do we need Edge?
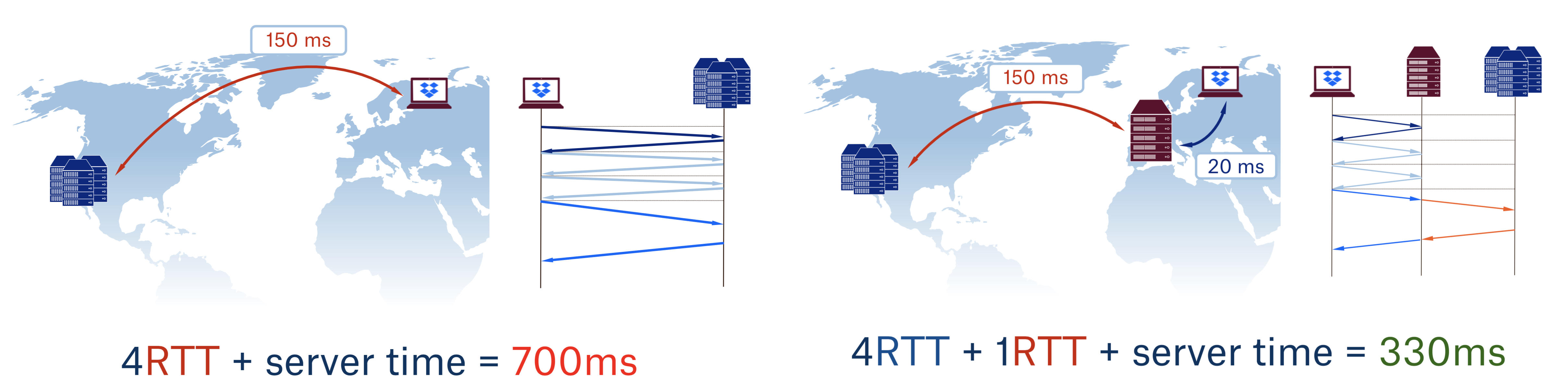
As you can see, by simply putting the PoP close to the user one can improve latency by more than factor of two.
But that is not all. Our users benefit greatly from faster file uploads and downloads. Let’s see how latency affects TCP congestion window (CWND) growth during file uploads:
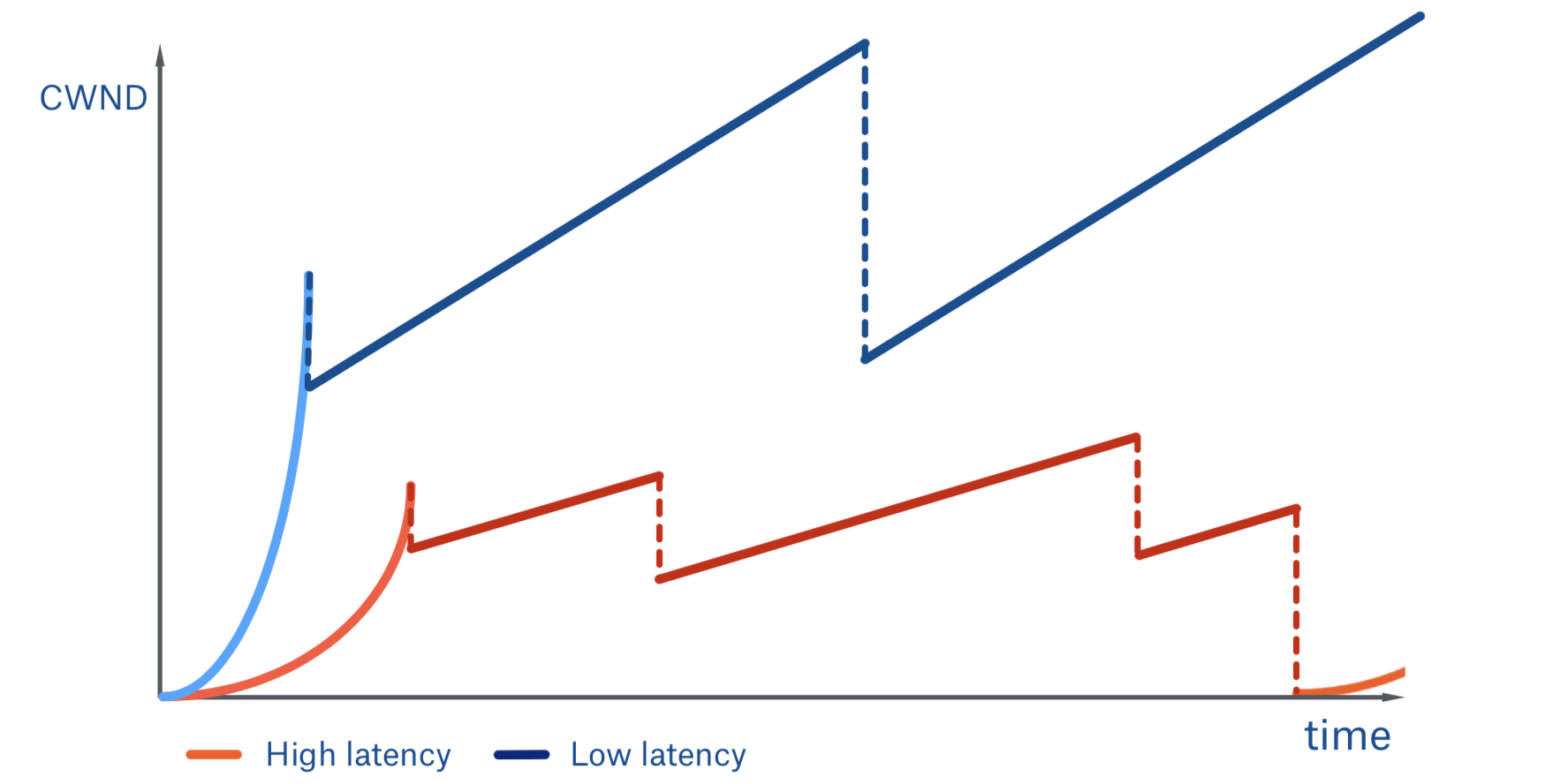
Here we can see a low and high latency connection comparison that represents a connection with and without a PoP respectively:
- The client with lower latency is progressing through slow start faster, because it is an RTT-bound process
- This client also settles on the higher threshold for congestion avoidance, because of the lower level of packet loss. This happens because that packets need to spend less time on the public, and possibly congested, internet links—once they hit the PoP we take them into our own backbone network.
- Aside from all latency-related performance gains, building our own Edge network gives us (traffic engineers) a lot of freedom: for example we can easily experiment with new low- and high-level protocols, external and internal loadbalancing algorithms, and more closely integrate with the rest of the infrastructure. We can do things like research BBR congestion control effects on file download speed, latency, and packet loss.
PIcking PoP Locations
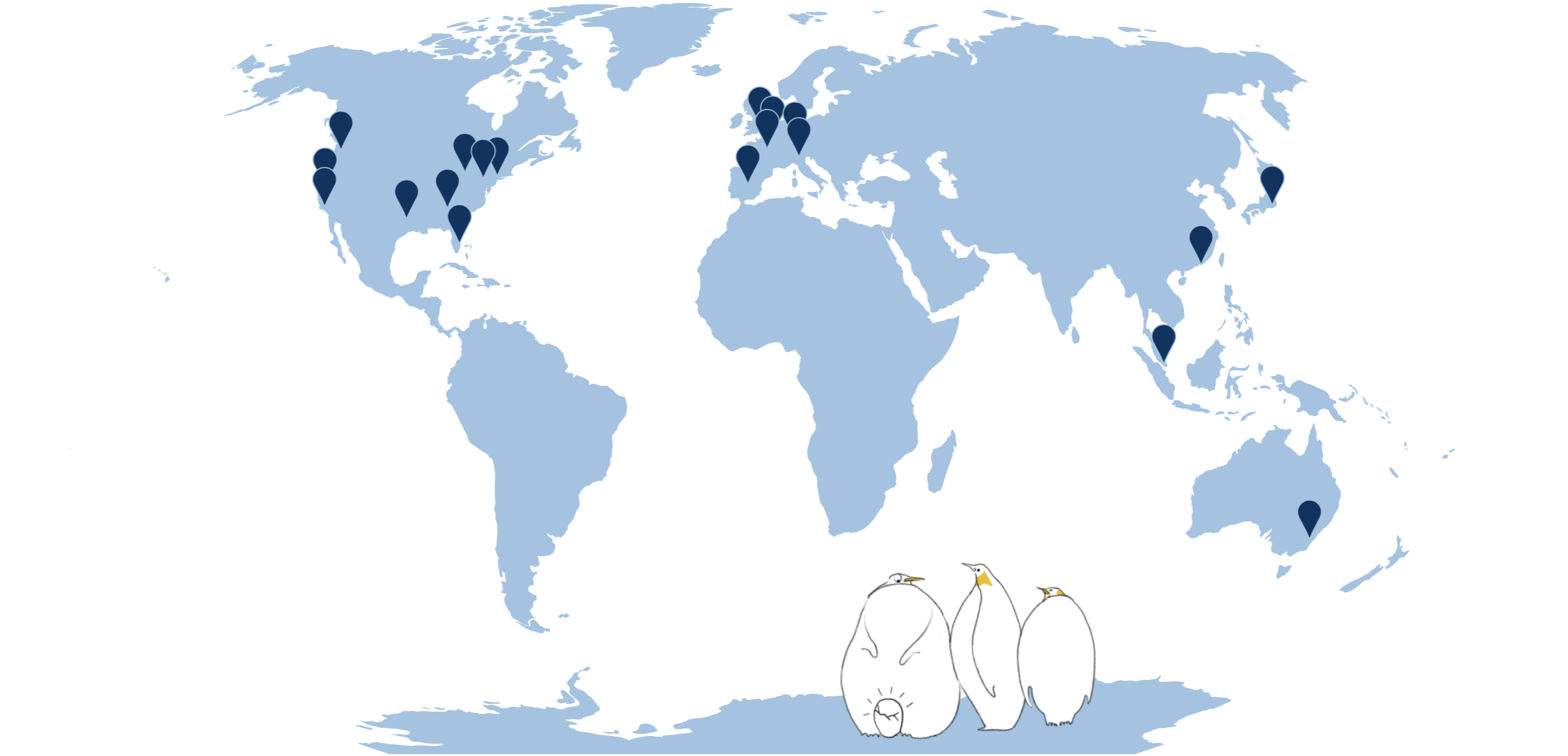
As of today, Dropbox has 20 PoPs around the world:
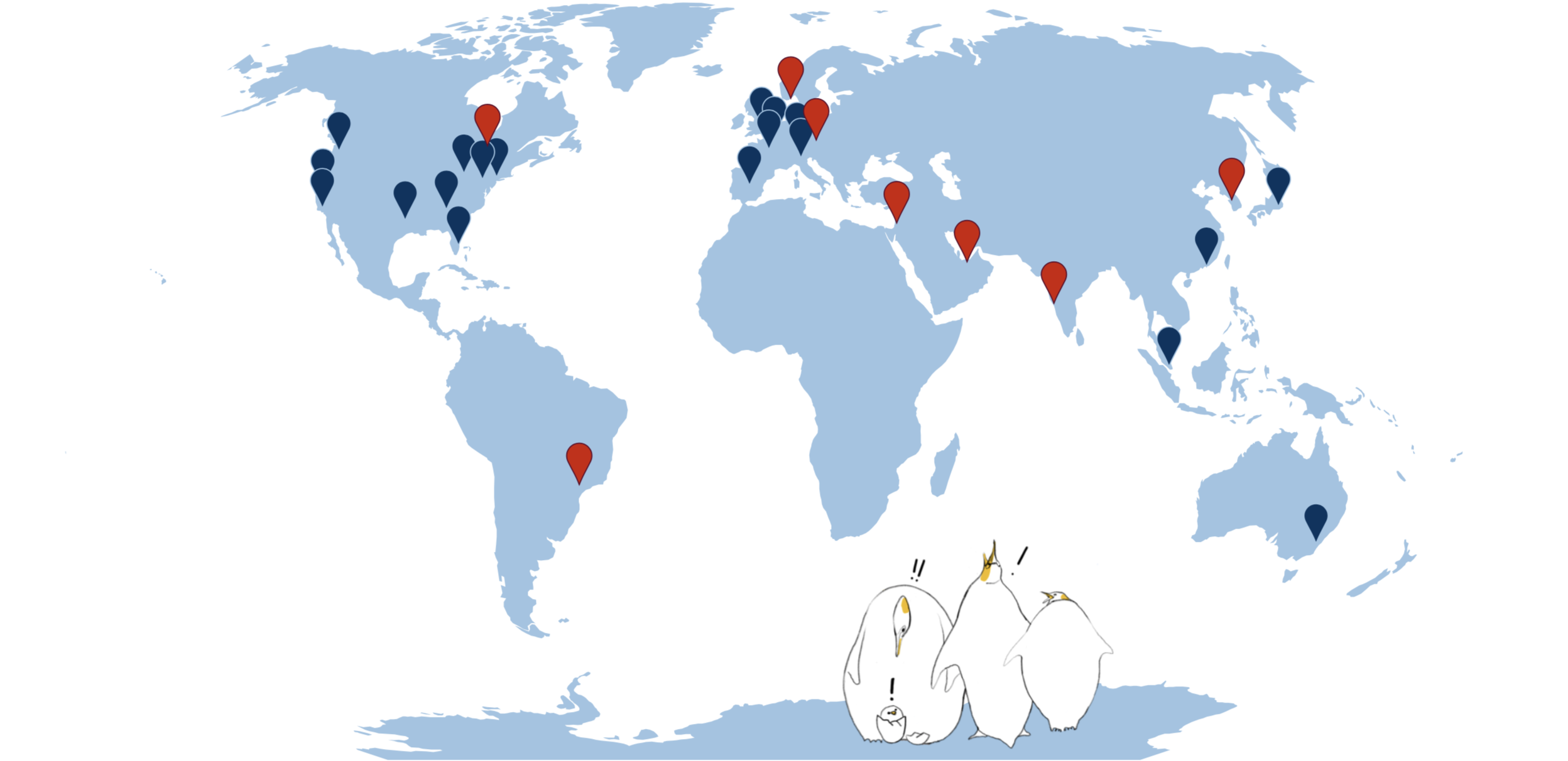
The process of PoP selection, which was easy at first, now becomes more and more complicated: we need to consider backbone capacity, peering connectivity, submarine cables, but most importantly the location with respect to all the other PoPs we have.
The current PoP selection procedure is human guided but algorithm-assisted. Even with a small number of PoPs without assistive software it may be challenging to choose between, for example, a PoP in Brazil and a PoP in Australia. The problem persists as the number of PoPs grows: e.g. what location will benefit Dropbox users better, Vienna or Warsaw?
We try to alternate new PoP placement between selecting the most advantageous PoP for the existing and potential Dropbox users.
A tiny script helps us brute-force the problem by:
- Splitting the Earth into 7th level s2 regions
- Placing all the existing PoPs
- Computing the distance to the nearest PoP for all the regions weighted by “population”
- Doing exhaustive search to find the “best” location for the new PoP
- Adding it to the map
- Looping back to step 3, etc.
By “population” one can use pretty much any metric we want to optimize, for example total number of people in the area, or number of existing/potential users. As for the loss function to determine the score of each placement one can use something standard like L1 or L2 loss. In our case we try to overcompensate for the effects of latency on the TCP throughput.
Some of you may see that the problem here that can be solved by more sophisticated methods like Gradient Descent or Bayesian Optimization. This is indeed true, but because our problem space is so small (there are less than 100K 7th level s2 cells) we can just brute-force through it and get a definitively optimal result instead of the one that can get stuck on a local optimum.
GSLB
Let’s start with the most important part of the Edge—GSLB. GSLB is responsible for loadbalancing users across PoPs. That usually means sending each user to the closest PoP, unless it is over capacity or under maintenance.
GSLB is called the “most important part” here because if it misroutes users to the suboptimal PoPs frequently, then it makes the Edge network useless, and potentially even harms performance.
The following is a discussion of commonly used GSLB techniques, their pros and cons, and how we use them at Dropbox.
BGP anycast
Anycast is the easiest loadbalancing method that relies on the core internet routing protocol, BGP. To start using anycast it is sufficient to just start advertising the same subnet from all the PoPs and internet will deliver packet to the “optimal” one automagically.
Even though we get automatic failover and simplicity of the setup, anycast has many drawbacks, so let’s go over them one by one.
Anycast performance
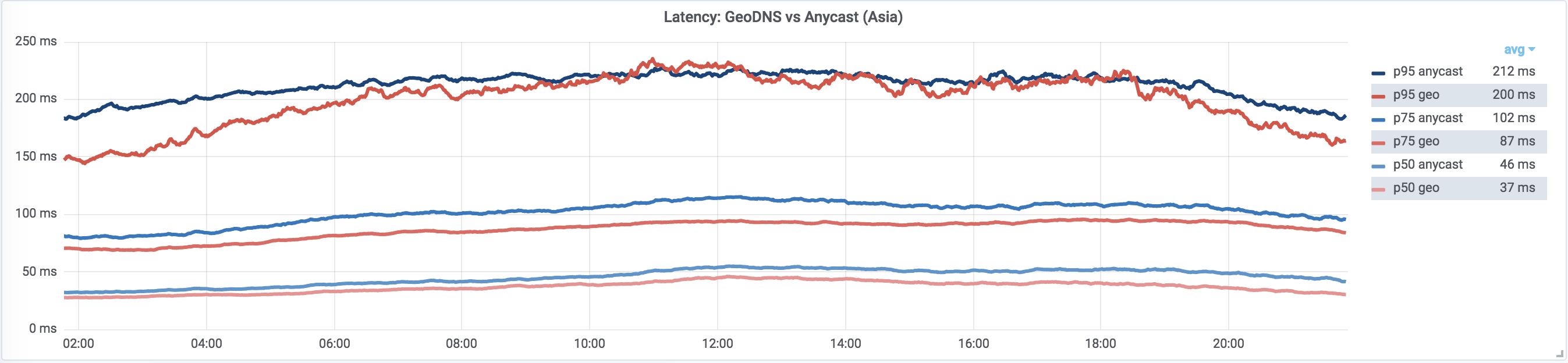
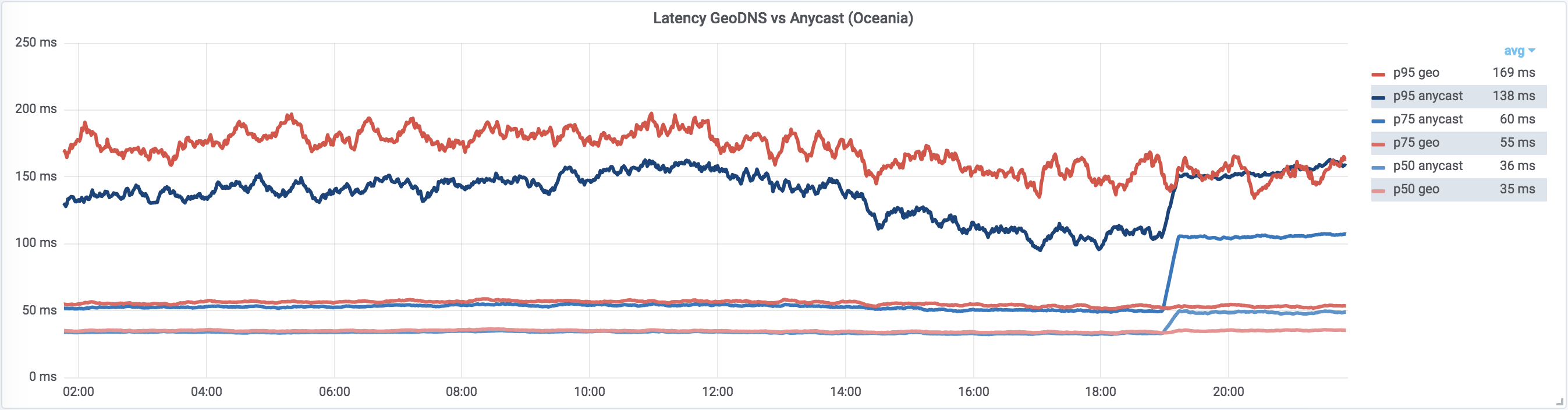
Above, we mentioned that BGP selects the “optimal” route and for the most part that is true. The problem is that BGP does not know anything about link latency, throughput, packet loss, and so on. Generally in the presence of multiple routes to the destination, it just selects one with the least number of hops.
Anycast-based loadbalancing is mostly optimal but it behaves poorly on high percentiles.
This is true for a small and medium number of PoPs. But there is a conjecture that “critical” misrouting probability (e.g. probability of routing user to a different continent) in an anycasted network drops sharply with number of PoPs. Therefore it is possible that with increasing number of PoPs, anycast may eventually start outperforming GeoDNS. We’ll continue looking at how our anycast performance scales with the number of PoPs.
Traffic steering
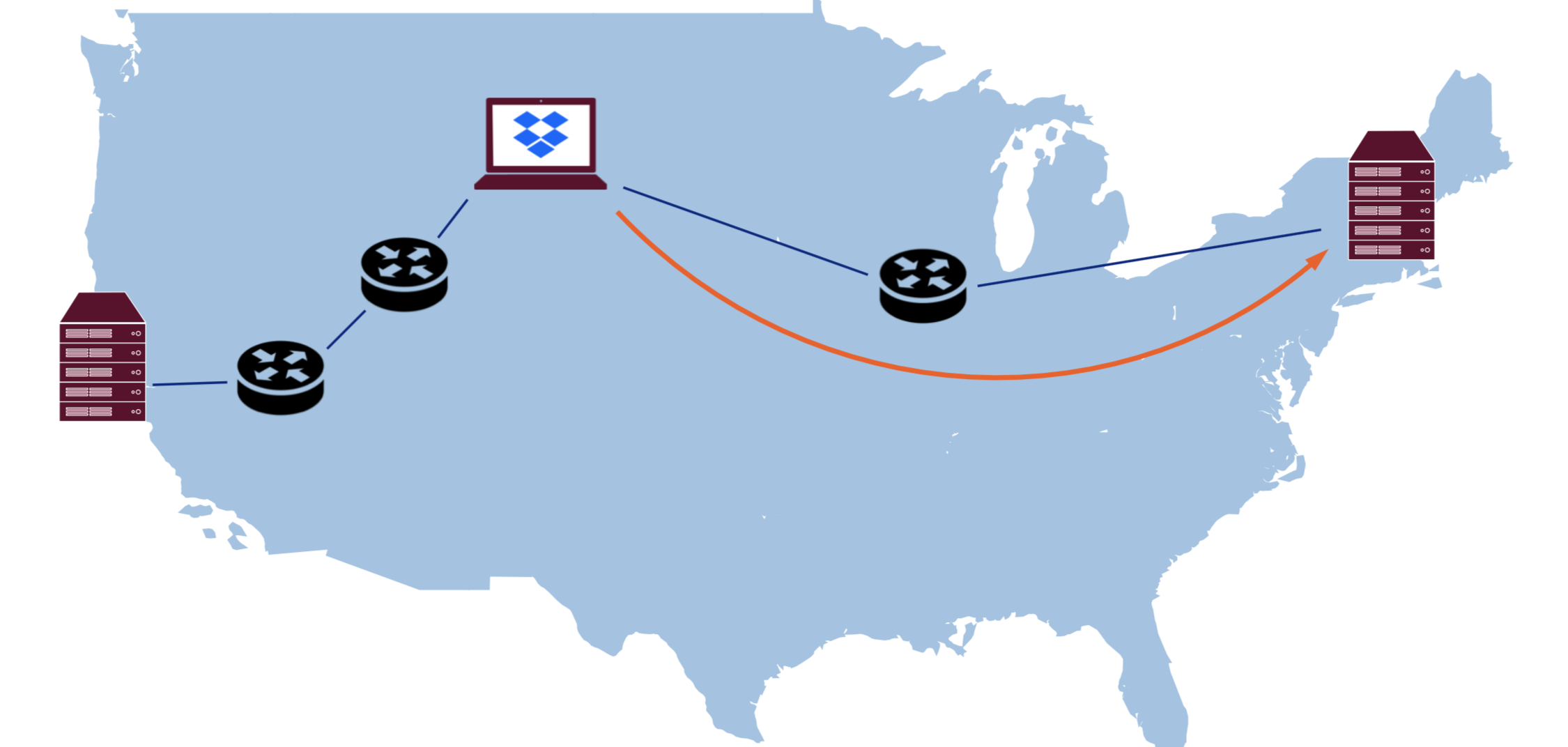
With anycast, we have very limited control over traffic. It is hard to explicitly move traffic from one PoP to another. We can do some traffic steering using MED attributes, prepending AS_PATHs to our announces, and by explicitly communicating with traffic providers, but this is not scalable.
Also note that in the N WLLA OMNI mnemonic AS_PATH is somewhere in the middle. This effectively means that it can be easily overridden by an administrator and in practice this makes BGP anycast pick the “cheapest” route, not the “nearest” or the “fastest.”
Another property of anycast is that graceful drain of the PoP is impossible—since BGP balances packets and not connections. After the routing table change, all inflight TCP sessions will immediately be routed to the next best PoP and users will get an RST from there.
Troubleshooting
Generally reasoning about traffic routing with anycast becomes very non-trivial, since it involves the state of internet routing at a given time. Troubleshooting performance issues with anycast is hard and usually involves a lot of traceroutes, looking glasses, and back and forth communication with providers along the way.
Note that, as in the case of a PoP drain, any connectivity change in the internet has a possibility of breaking users’ connections to anycasted IP addresses. Troubleshooting intermittent connection issues due to internet routing changes or faulty/misconfigured hardware can be challenging.
Tools
Here are couple of tricks you can use to make troubleshooting a bit easier (especially in case of anycast).
Of course having a random request ID associated with every request that goes through the system and can be traced in the logs is a must. In case of the Edge, it is also helpful to echo back a header with the name of the PoP you’re connected to (or embed this into the unique request ID).
Another useful thing that is commonly used is to create “debug” sites that can pre-collect all the troubleshooting data for the user so that they can attach it to the support ticket e.g.: github-debug.com, fastly-debug.com, and of course dropbox-debug.com, which was heavily inspired by them.
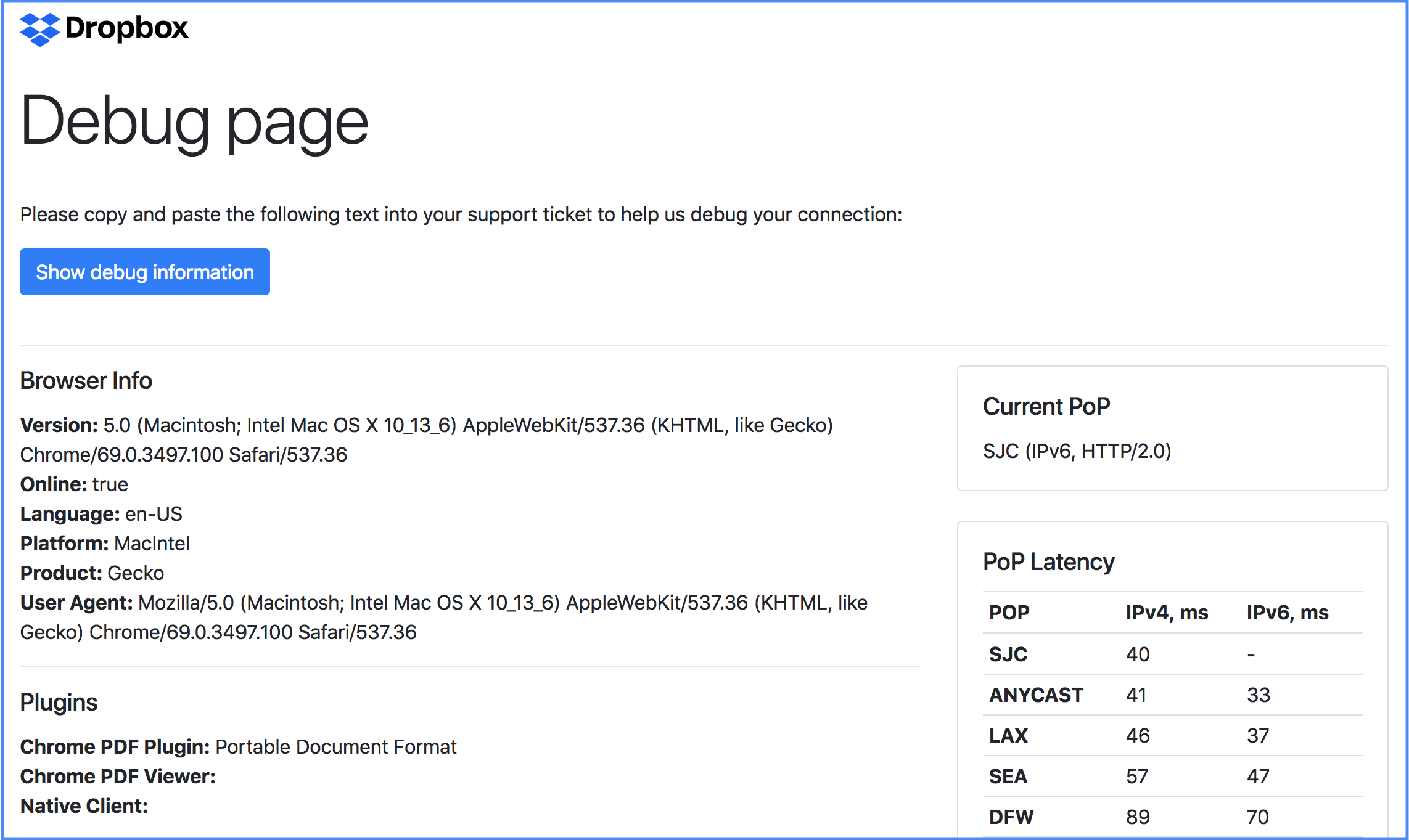
Anycast at Dropbox
With all that said, we still use anycast for our APEX domains like dropbox.com (without www) and as a fallback in case of major DDoS attacks.
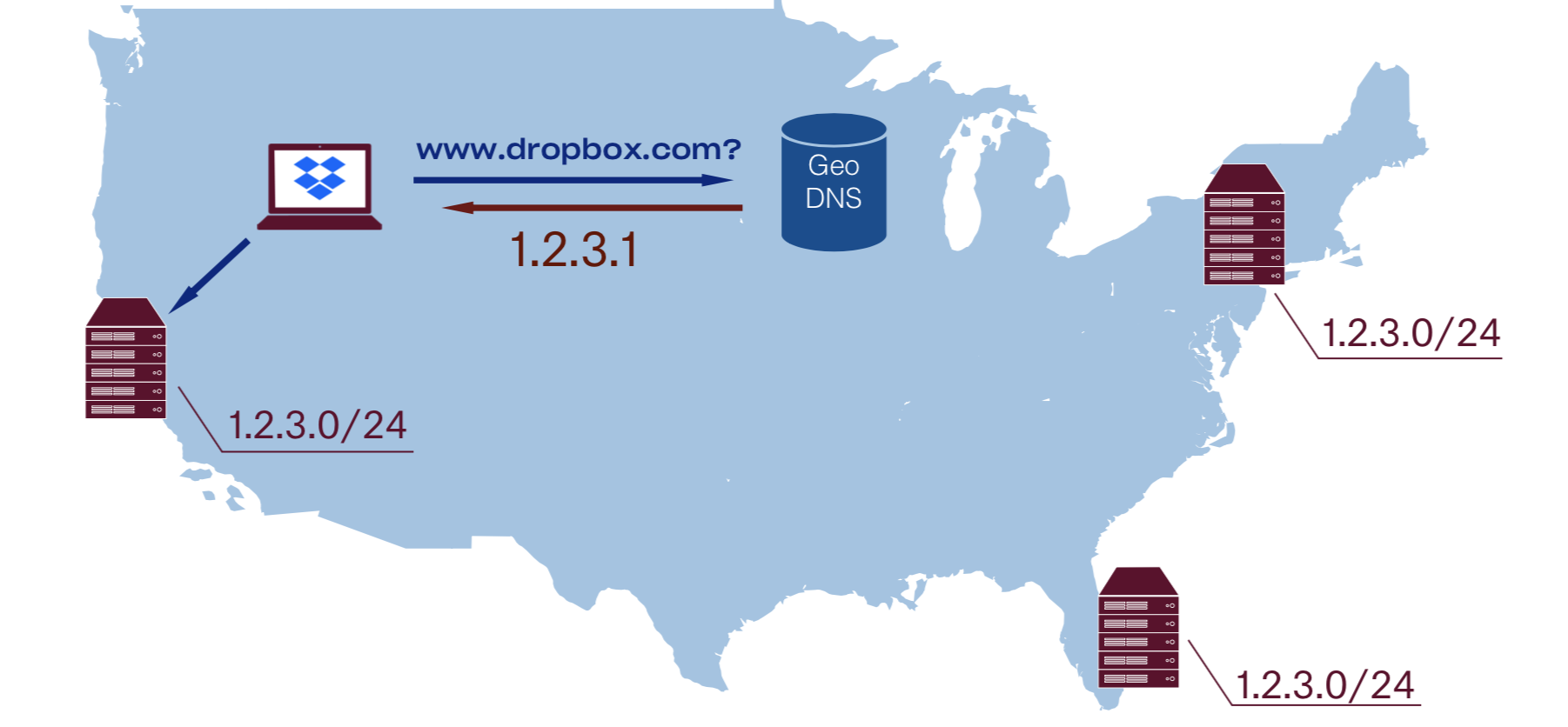
GeoDNS
Let’s talk about another common solution for implementing GSLB: GeoDNS. In this approach each PoP has its own unique unicast IP address space and DNS is responsible for handing off different IP addresses to different users based on their geographical location.Let’s talk about another common solution for implementing GSLB: GeoDNS. In this approach each PoP has its own unique unicast IP address space and DNS is responsible for handing off different IP addresses to different users based on their geographical location. fallback in case of major DDoS attacks.
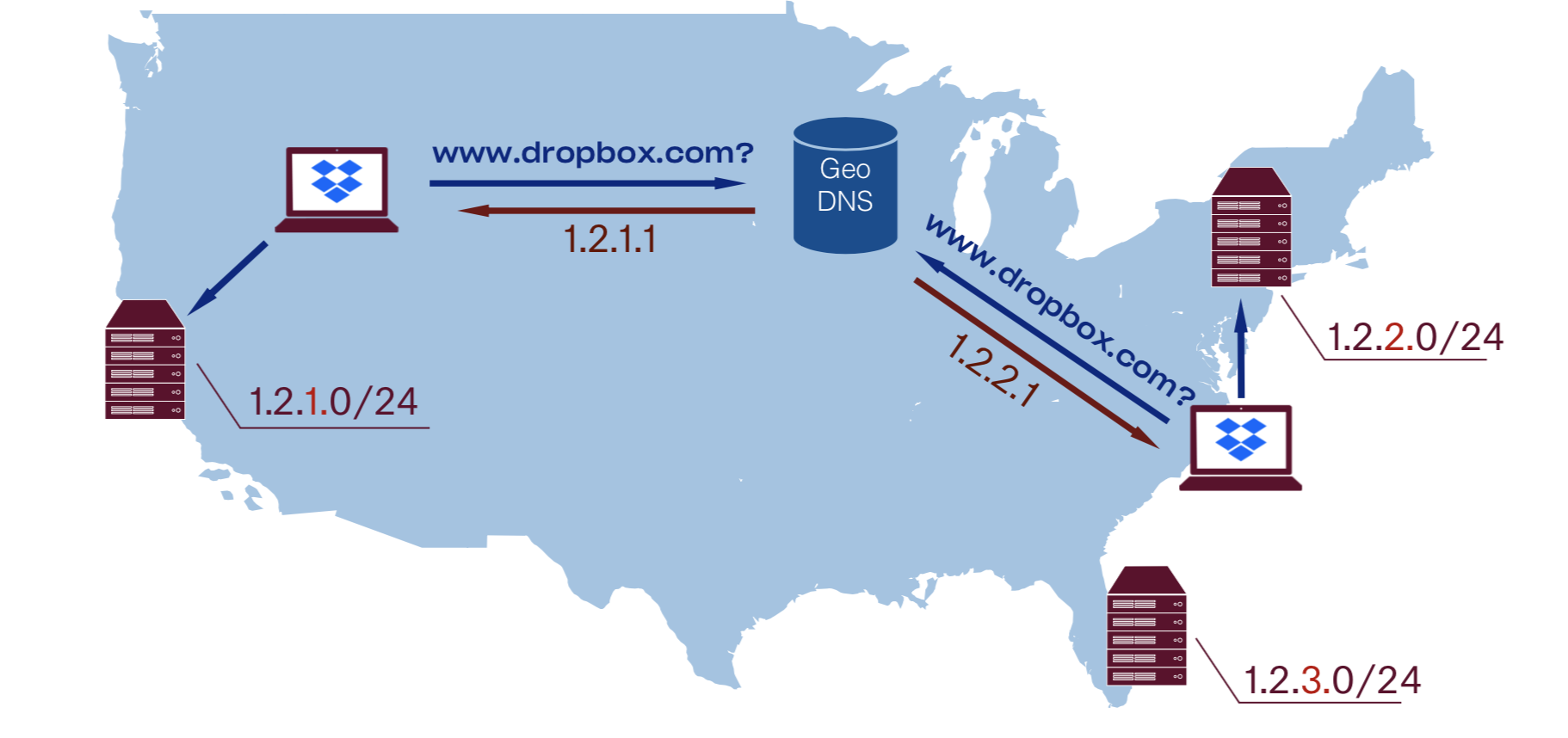
This gives us control over traffic steering and allows graceful drain. It is worth mentioning that any kind of reasoning about unicast-based setup is much easier, therefore troubleshooting becomes simpler.
As you can see, there are a lot of variables involved: we rely on a DNS provider guessing user IP by their DNS resolver (or trust EDNS CS data), then guessing user location by their IP address, then approximate physical proximity to latency.
Note that different DNS providers will likely end up with different decisions, based on their algorithms and quality of their GeoIP database, therefore monitoring performance of multi-provider DNS setup is much harder.
Aside from that, DNS also has a major problem with stale data. Long story short: DNS TTL is a lie. Even though we have TTL of one minute for www.dropbox.com, it still takes 15 minutes to drain 90% of traffic, and it may take a full hour to drain 95% of traffic:
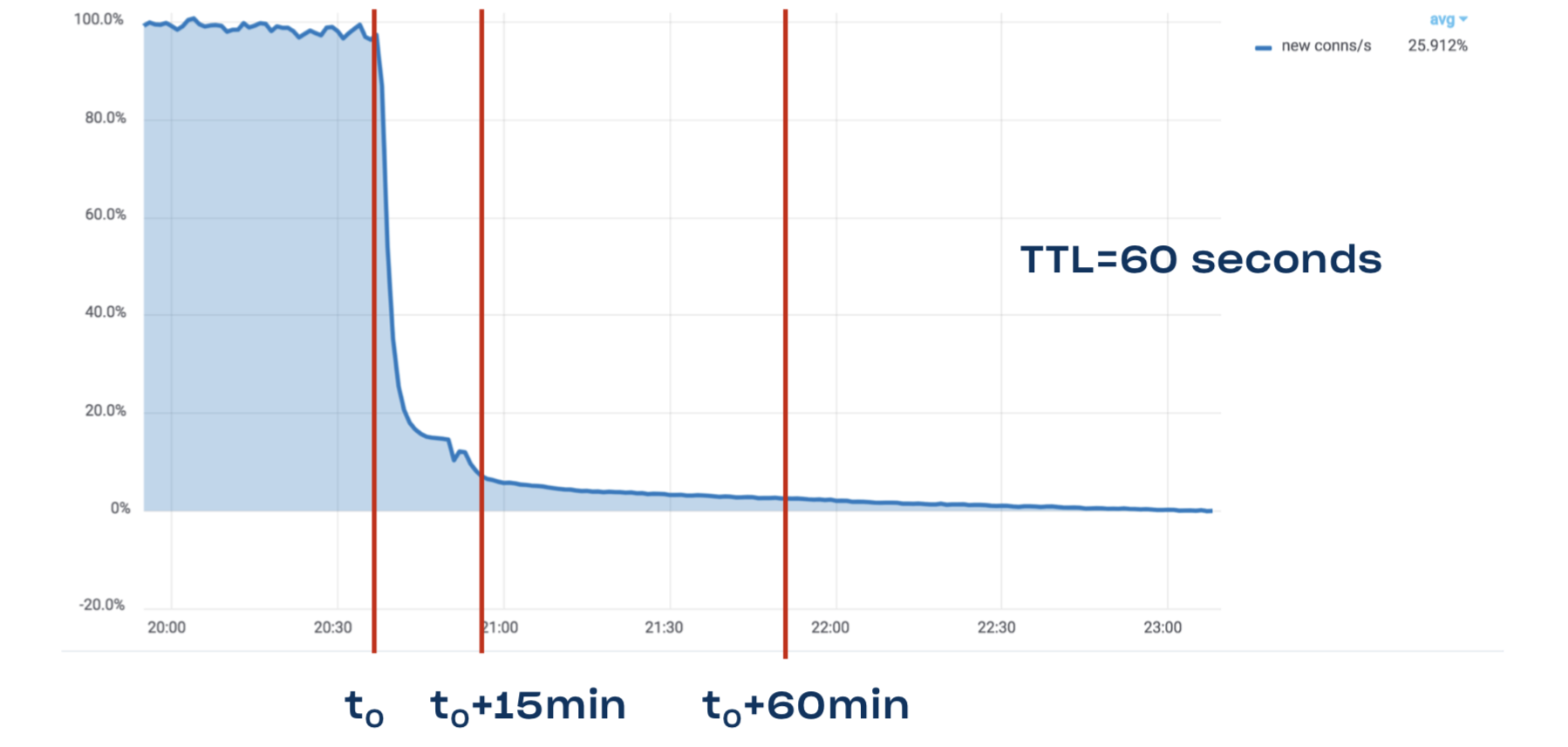
GeoDNS at Dropbox
Our DNS setup evolved quite a bit over last few years: we started with a simple continent→PoP mappings, then switched to country→PoP with a per-state mapping data for serving network traffic to large countries like the US, Canada, etc. At the moment, we are juggling relatively complex LatLong-based routing with AS-based overrides to work around quirks in internet connectivity and peering.
Hybrid unicast/anycast GSLB
Let’s very briefly cover one of the composite approaches to GSLB: hybrid unicast/anycast setup. By combining unicast and anycast announces along with GeoDNS mapping, one can get all the benefits of unicast along with an ability to quickly drain PoPs in case of an outage.
One can enable this hybrid GSLB by announcing both PoP’s unicast subnet (e.g. /24) and one of its supernets (e.g. /19) from all of the PoPs (including itself).
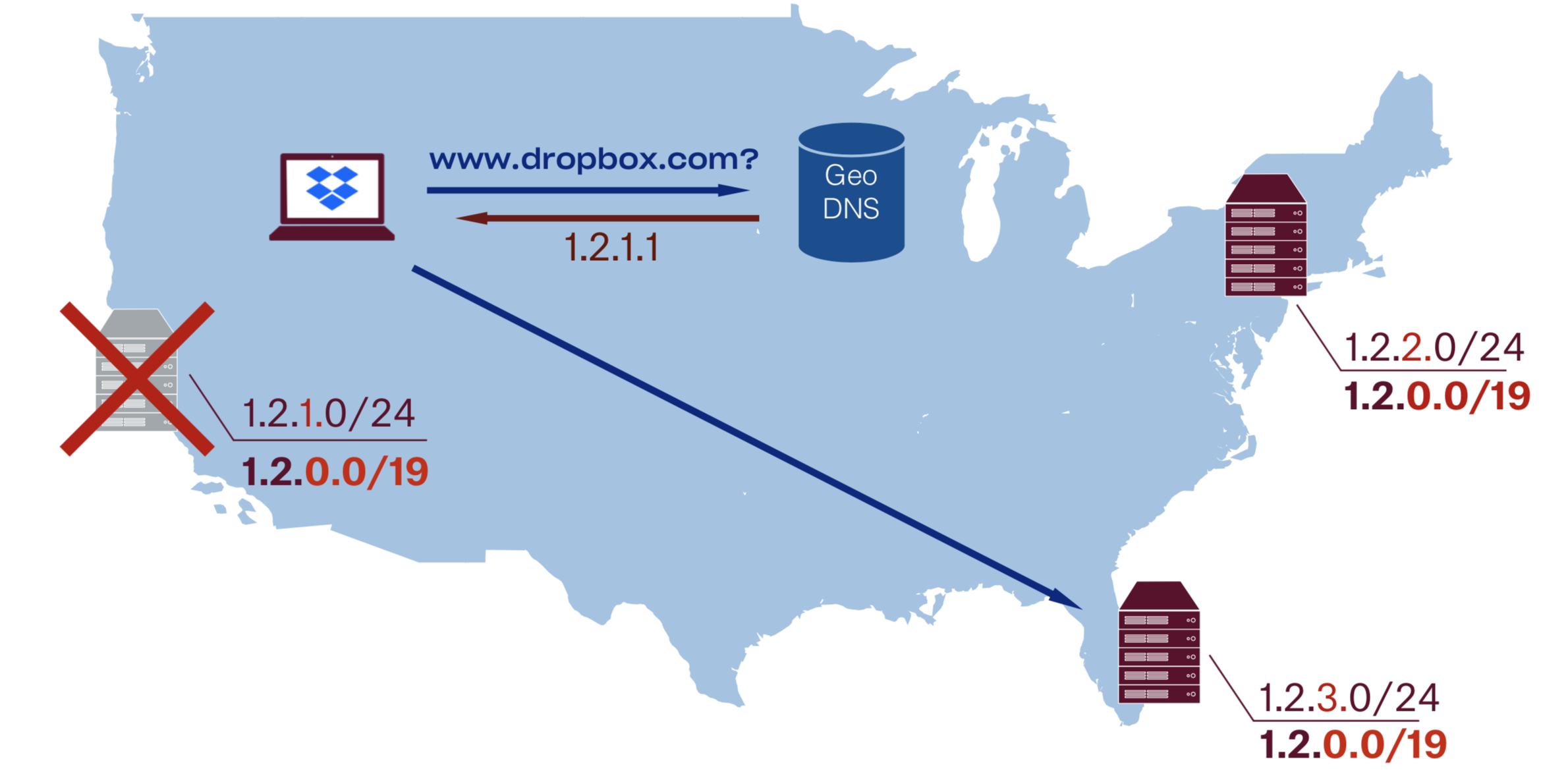
This implies that every PoP should be set up to handle traffic destined to any PoP: i.e. have all the VIPs from all the PoPs in the BGP daemons/L4 balancers/L7 proxies configs.Such an approach gives us the ability to quickly switch between unicast and anycast addresses and therefore immediate fallback without waiting for DNS TTL to expire. This also allows graceful PoP draining and all the other benefits of DNS traffic steering. All of that comes at a relatively small operational cost of a more complicated setup and may cause scalability problems once you reach the high thousands of VIPs. On the bright side, all PoP configs now become more uniform.
Real User Metrics
All the GSLB methods discussed up until now have one critical problem: none of them uses actual user-perceived performance as a signal, but instead rely on some approximations: BGP uses number of hops as a signal, while GeoIP uses physical proximity. We want to fix that by using Real User Metrics (RUM) collection pipeline based on performance data from our desktop clients.Companies that do not have an app usually do latency measurements with the JS-based prober on their website.Years ago we invested in an availability measurement framework in our Desktop Clients to help us estimate the user-perceived reliability of our Edge network. The system is pretty simple: once in a while a sample of clients run availability measurements against all of our PoPs and report back the results. We extended this system to also log latency information, which gave us sufficient data to start building our own map of the internet. We also built a separate resolver_ip→client_ip submap by joining DNS and HTTP server logs for http requests to random subdomain of a wildcard DNS record. On top of which we apply a tiny bit of post-processing for EDNS ClientSubnet-capable resolvers.
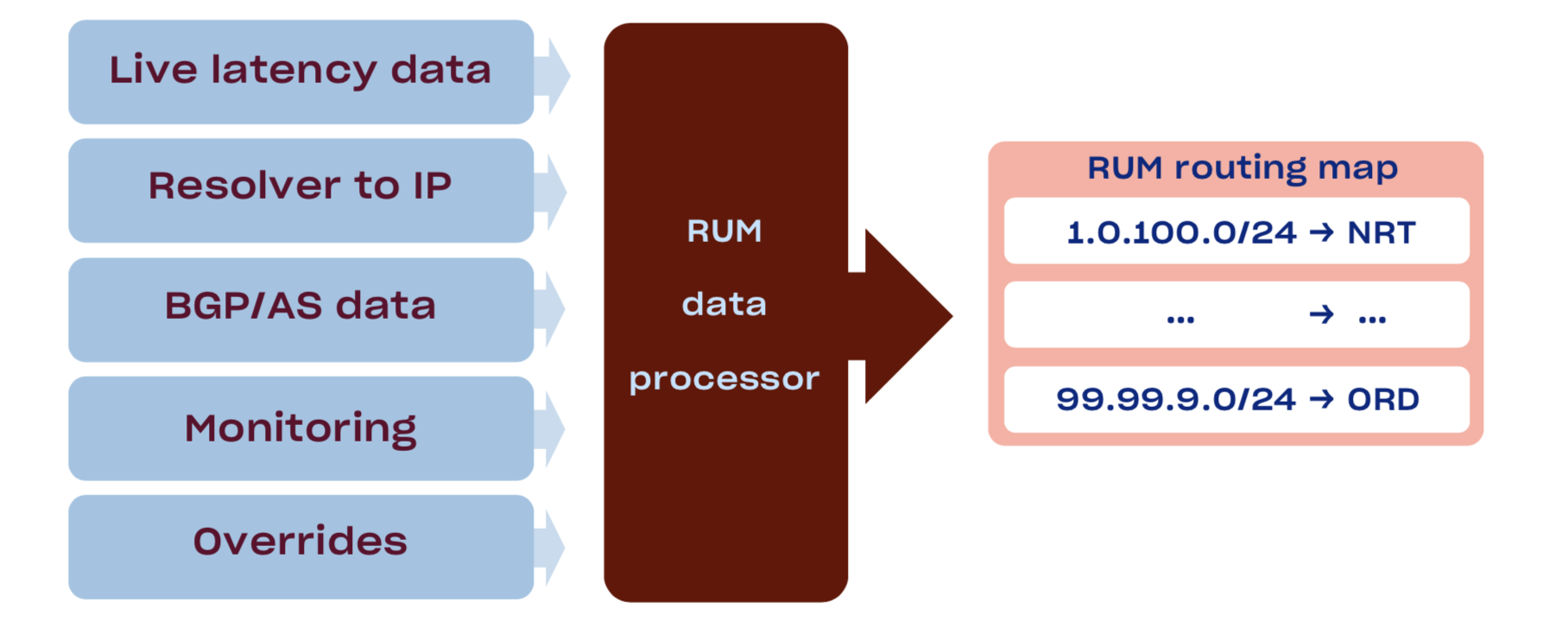
We combine the aggregated latencies, resolver_ip→client_ip map, BGP fullview, peering information, and capacity data from our monitoring system to produce the final map of client_subnet→PoP.
We are also considering adding a signal from the web server logs, since we already have TCP_INFO data, including number of retransmits, cwnd/rwnd, and rtt.
After which we pack this map into a radix tree and upload it to a DNS server, after which it is compared to both anycast and GeoIP solutions.
Specifics of map generation are up in the air right now: we’ve tried (and continue trying out) different approaches: from simple HiveQL query that does per-/24 aggregation to ML-based solutions like Random Forests, stacks of XGBoosts, and DNNs. Sophisticated solutions are giving slightly better, but ultimately comparable results, at the cost of way longer training and reverse engineering complexity. At least for now, we are sticking with the solution that is easier to reason about and easier to troubleshoot.
Data anonymization and aggregation We anonymize and aggregate all latency and availability data by /24 subnet in case of IPv4 and /56 in case of IPv6. We don’t operate directly on real user IPs and enforce strict ACL and retention policies for all RUM data. Data cleanup Data cleanup is a very important step in the map data pipeline. Here are couple of common patterns that we’ve found during our map construction:
- Standard
GetTickCount64timer on Windows is quantized by around 16ms. In our Python client we’ve switched totime.perf_counter(). - TCP and HTTP probes are way less reliable than HTTPS. This is mostly due to IP and DNS hijacking in the wild. Good examples of this are Wi-Fi captive portals.
- Even unique DNS requests can be received multiple times. Both due to lost responses and proactive cache refreshes by some DNS servers even unique queries like
UUID4.perf.dropbox.comcan be duplicated. We take that into account when joining the HTTP and DNS logs. - And of course there are all kinds of weird timing results from negative and submicrosecond results to ones that are older than our universe (they probably came from another one).
Data extrapolation Currently we use the following techniques for speculatively expanding the resulting map:
- If all the samples for an AS end up in the same “best” PoP we consider that all IP ranges announced by that AS should go to that PoP.
- If AS has multiple “best” PoPs then we break it down into announced IP ranges. For each one we assume that if all measurements in a range end up at the same PoP we can extrapolate that choice to the whole range.
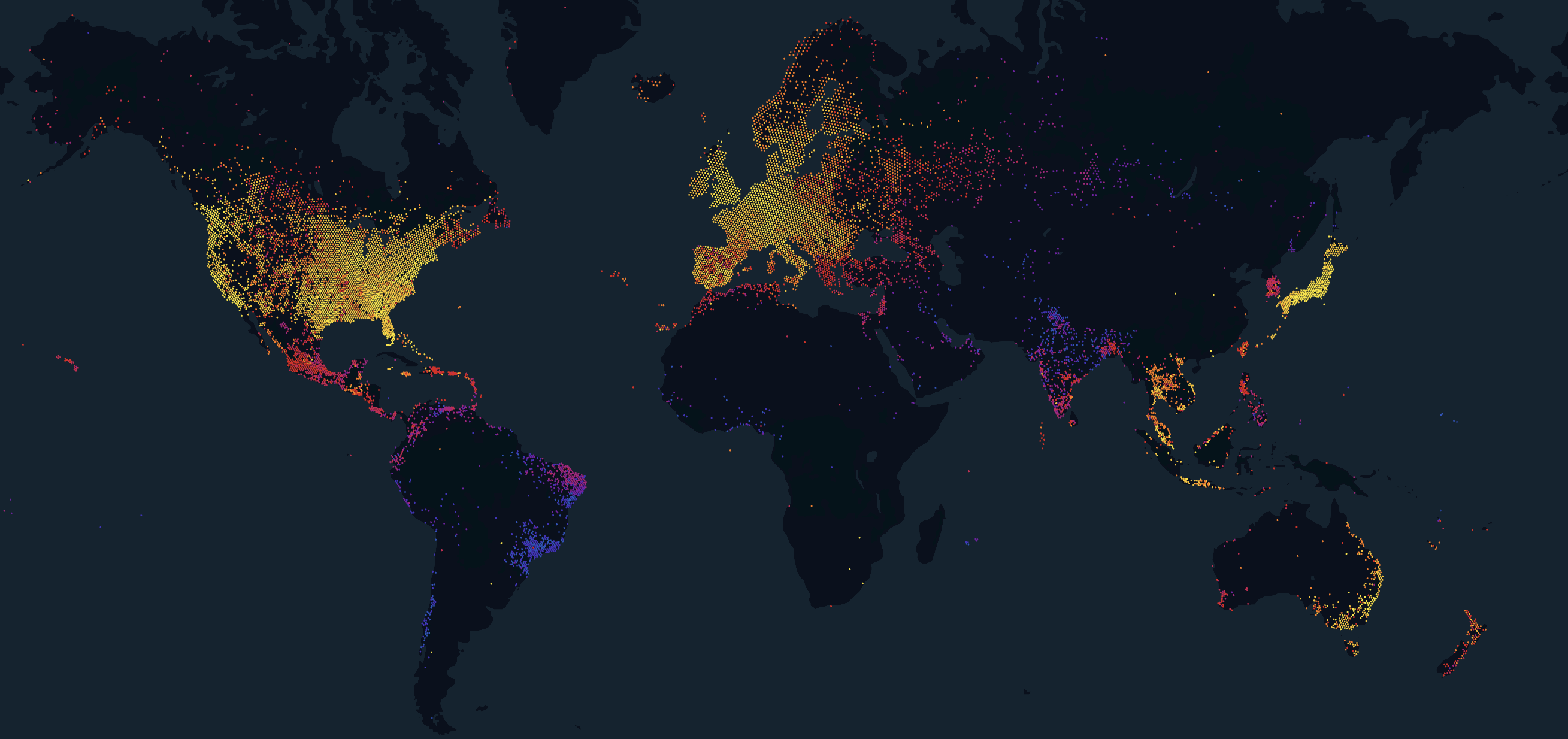
This technique allows us to double our map coverage, make it more robust to changes, and generate a map using a smaller dataset. Troubleshooting DNS map Once a RUM-based map is constructed, it is crucial to be able to estimate how good it is by using a single value, something like an F1 score used for binary classification or BLEU score used for evaluating machine translation. That way, one can not only automatically prevent bad maps from going live, but also numerically compare the quality of different map iterations and construction algorithms. Another common approach for the map evaluation is to test it against the subset of data that training process did not see. For interactive slicing and dicing of data and ad-hoc troubleshooting, we map subnets back into the lat/long coordinates, aggregate their stats by h3 regions and then draw them with kepler.gl. This is very helpful to quickly eyeball maps that have low scores.
We went with h3 here instead of s2 because Kepler has built-in support for it, and generally h3 has simpler Python interface, therefore making it easier for us to experiment with visualizations. Whisper: also hexagons look cooler =)
The same approach can be used for visualizing current performance, week-over-week difference, difference between GeoIP database versions, and much more.
Another way of visualizing IP maps is to skip the whole GeoDNS mapping step and plot IP addresses on the 2D plane by mapping them on a space filling curve, e.g. Hilbert curve. One can also place additional data in the height and color dimensions. This approach will require some heavy regularization for it to be consumable by humans and even more ColorBrewer2 magic to be aesthetically pleasing.
RUM DNS at Dropbox
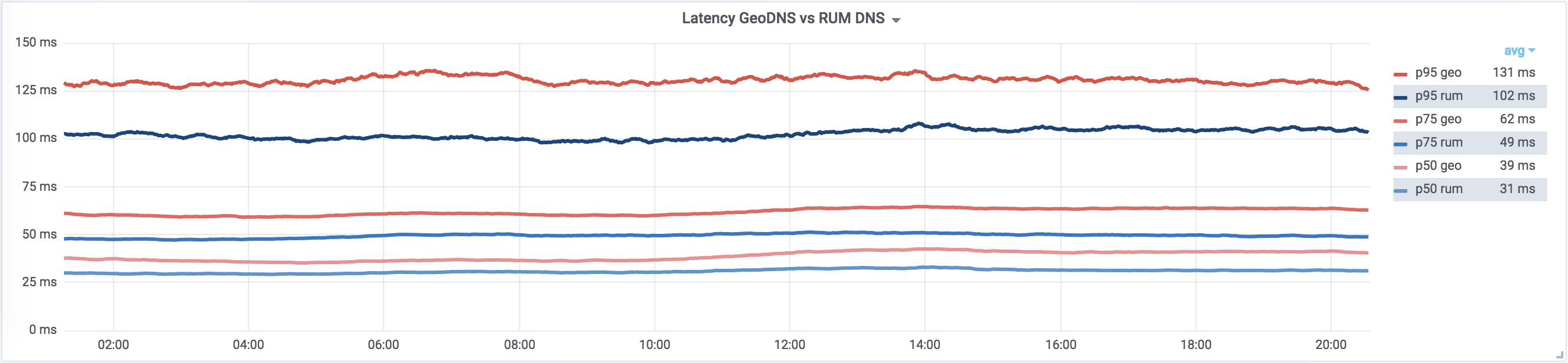
RUM-based DNS is an actively evolving project, and we have not shipped it to our main VIPs yet, but the data we’ve collected from our GSLB experiments shows that it is the only way we can properly utilize more than 25-30 PoPs. This project will be one of our top priorities in 2019, because even metrics collected from an early map prototypes show that it can improve effectiveness of our Edge network by up to 30% using RUM DNS.
It will also provide all the byproducts needed for the Explicit Loadbalancer… Speaking of which…
Explicit loadbalancing
A quick note about another more explicit way of routing users to PoPs. All these dances with guessing users’ IP address based on their resolver, GeoIP effectiveness, optimality of decisions made by BGP, etc. are all no longer necessary after a request arrives at the PoP. Because at that point in time, we know the users’ IP and even have an RTT measurement to them. At that point, we can route users on a higher level, like for example embedding a link to a specific PoP in the html, or handing off a different domain to a desktop client trying to download files.
The same IP→PoP map that was constructed for RUM DNS can be reused here, now exposed as an RPC service.
This loadbalancing method allows for a very granular traffic steering, even based on per-resource information, like user ID, file size, and physical location in our distributed storage. Another benefit is almost immediate draining of new connections, though references to resources that were once given out may live for extended periods of time.
Very complex schemes can be invented here, for example we can hand off whole URLs that in the domain name embed information for external DNS-based routing and at the same time embed information for internal routing inside path/queryargs, that will allow PoP to make more optimal routing decision. Another approach is to put that additional data as an opaque blob into the encrypted/signed cookie. All of these possibilities sound exciting, so care must be taken to not overcomplicate the system.
Explicit loadbalancing at Dropbox
We are not currently using this as an external loadbalancing method but instead rely on it for internal re-routing. The traffic team is actively preparing foundation for using it though.
Inside a point of presence
Network architecture
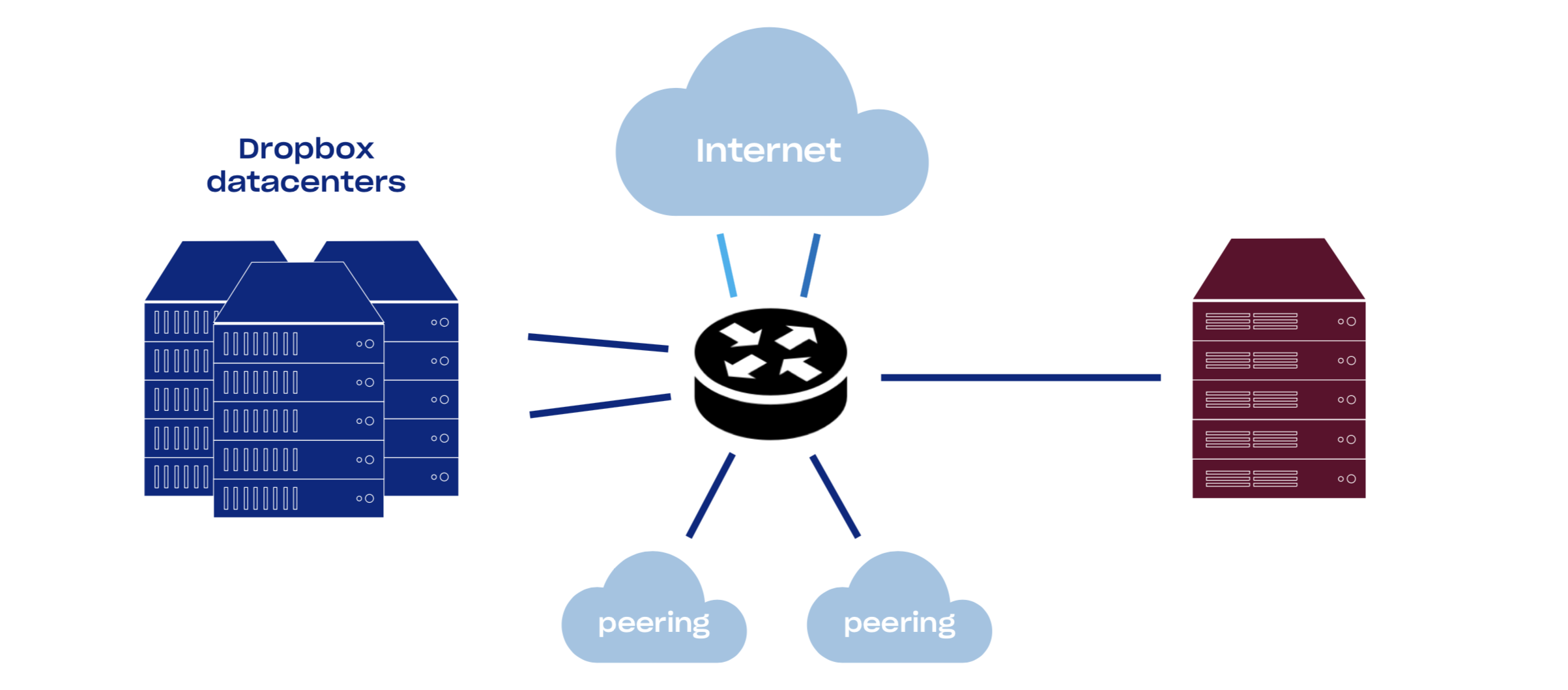
PoPs consist of network equipment and sets of Linux servers. An average PoP has good connectivity: backbone, multiple transits, public and private peering. By increasing our network connectivity, we decrease the time packets spend in the public internet and therefore heavily decrease packet loss and improve TCP throughput. Currently about half of our traffic comes from peering.
Dropbox has an open peering policy, so feel free to peer with us all around the world.
You can read more about network setup in the Evolution of Dropbox’s Edge Network post.
L4 loadbalancer
Our PoPs consist of multiple nginx boxes that are acting as L7 proxy and L4 loadbalancers (L4LBs) spreading load between them.
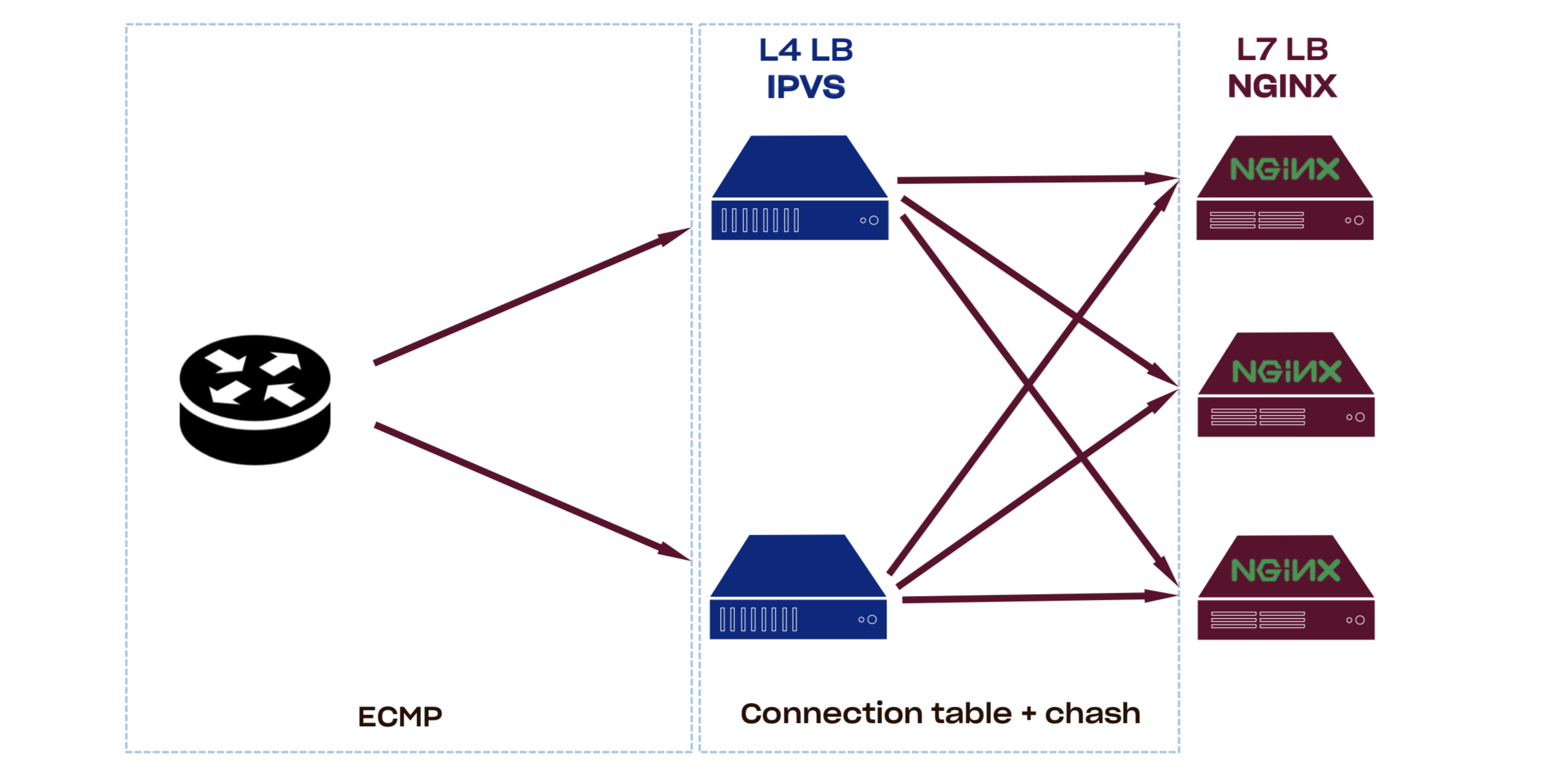
There are two main approaches for building high performance packet processors right now.
Kernel
Do packet processing early in network stack. This allows in-kernel data structures and TCP/IP parsing routines to be reused. For quite a while now, Linux has IPVS and netfilter modules that can be used for connection-level loadbalancing. Recent kernels have eBPF/XDP combo which allows for a safer and faster way to process packets in kernel space. Tight coupling with kernel though has some downsides: upgrade of such LB may require reboot, very strict requirements on kernel version, and difficult integration testing.
This approach is used by companies like Facebook and Dropbox.
Userspace
Create a virtual NIC PCIe device with SRIO-V, bypass the kernel through DPDK/netmap/etc, and get RX/TX queues in an application address space. This gives programmers full control over the network, but tcp/ip parsing, data structures, and even memory management must be done manually (or provided by a 3rd party library). Testing this kind of setup is also much easier.
This approach is used by companies like Google and Github.
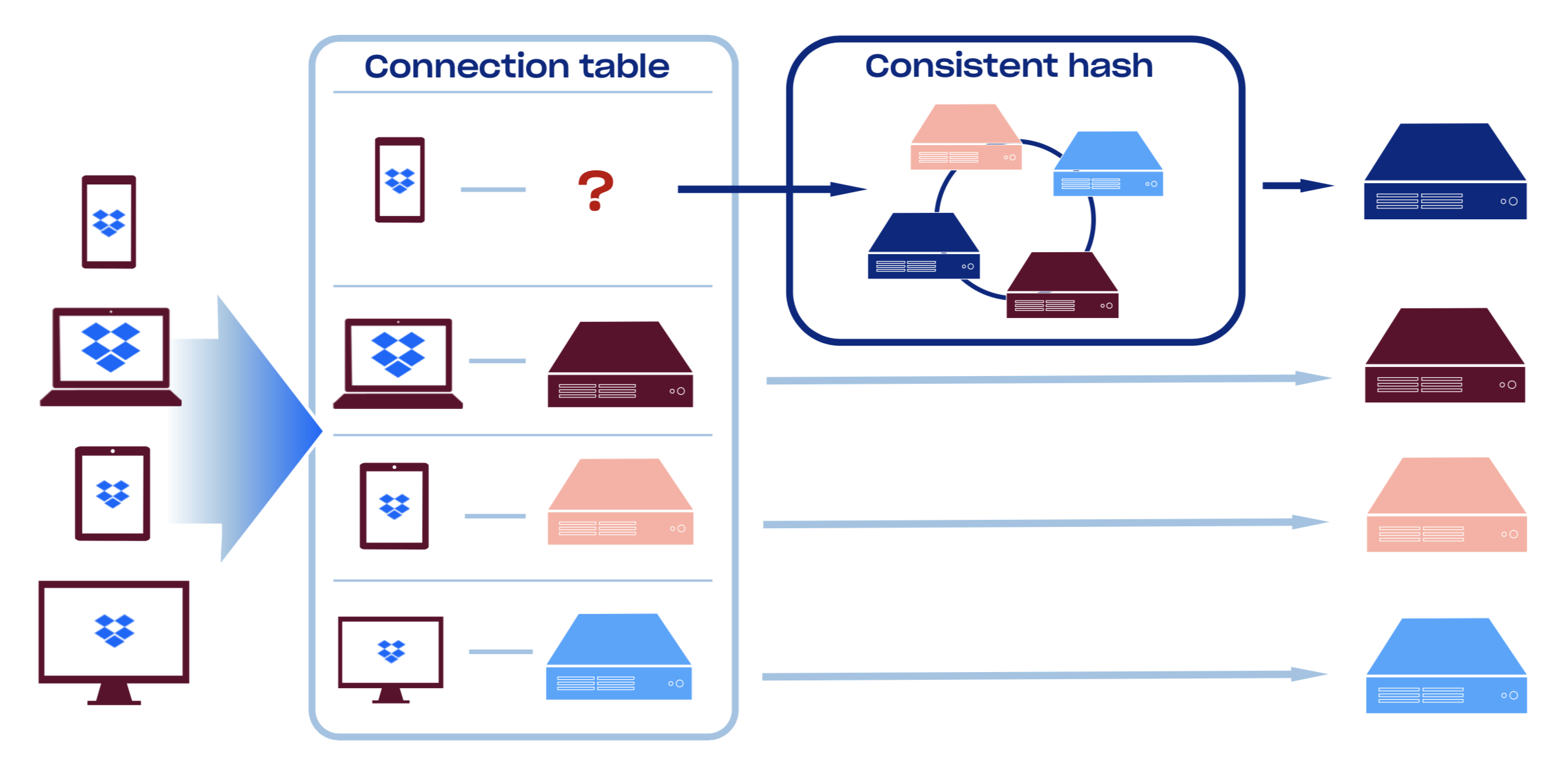
We currently use our homebrew version of consistent hashing module, but starting from linux-4.18 there is a Maglev Hash implementation: [ip_vs_mh](https://github.com/torvalds/linux/blob/master/net/netfilter/ipvs/ip_vs_mh.c). Compared to Ketama, Maglev Hash trades off some of the hash resiliency for more equal load distribution across backends and lookup speed.
You can read more about Maglev Hash in the Maglev paper or the morning paper, or go over a quick summary of consistent hash techniques from Damian Gryski.
We hash incoming packets based on 5-tuple (proto, sip, dip, sport, dport) which improves load distribution even further. This sadly means that any server-side caching becomes ineffective since different connections from the same client will likely end up on different backends. If our Edge did rely on local caching, we could use 3-tuple hashing mode where we would only hash on (protocol, sip, dip).
Another interesting fact is that L4LB will need to do some special handling of ICMP’s Packet Too Big replies, since they will originate from a different host and therefore can’t use plain outer header hashing, but instead must be hashed based on the tcp/ip headers in the ICMP packet payload. Cloudflare uses another approach for solving this problem with its [pmtud](https://github.com/cloudflare/pmtud): broadcast incoming ICMP packets to all the boxes in the PoP. This can be useful if you do not have a separate routing layer and are ECMP’ing packets straight to your L7 proxies.
Control plane for L4LBs is currently written in Go and closely integrated with our infrastructure and responsible for online reconfiguration, BGP connectivity, and health-checking of backends.
Health checks on any encapsulating DSR-based L4LB is very tricky. Special care must be taken to run health checks through the same packet encapsulation process as data itself is going, otherwise it is easy to start sending traffic to the box that does not have a properly set up tunnel yet.
Key properties of the L4LBs:
- They are resilient and horizontally scalable. Since L4LB does not terminate TCP connection and relies on the consistent hashing for connection scheduling, we can safely add/remove L4LBs because all of them will consistently route packets to the right destination
- Graceful removal/addition of L7 proxies. Since L4LBs also have a connection tracking table even if the set of backends changes, they will continue routing existing connections to them, which is the key distinguishing feature from plain ECMP
- Allows for horizontal scaling of L7 proxies. L4LB is fast enough to be network bounded, which means that we can scale L7 proxies until we have sufficient bandwidth
- Supports any IP-based protocol
- Supports any hashing algorithm. Maglev? Rendezvous? We can quickly experiment with any of them
- Supports any hashing policy. 3-tuple? 5-tuple? QUIC Connection ID? Easy!
Not to mention that now we can convert basically any server in production into a high performance loadbalancer just by running a binary on it.
As for the future work, we have a number of things we want to try. First, replace the routing dataplane with either a DPDK or XDP/eBPF solution, or possibly just integrating an open-source project like Katran. Second, we currently use IP-in-IP for packet encapsulation and it’s about time we switch it to something more modern like GUE which is way more NIC-friendly in terms of steering and offload support.
L7 proxies (nginx)
Having PoPs close to our users decreases the time needed for both TCP and TLS handshakes, which essentially leads to a faster TTFB. But owning this infrastructure instead of renting it from a CDN provider allows us to easily experiment and iterate on emerging technologies that optimize latency and throughput sensitive workloads even further. Let’s discuss some of them.
TCP
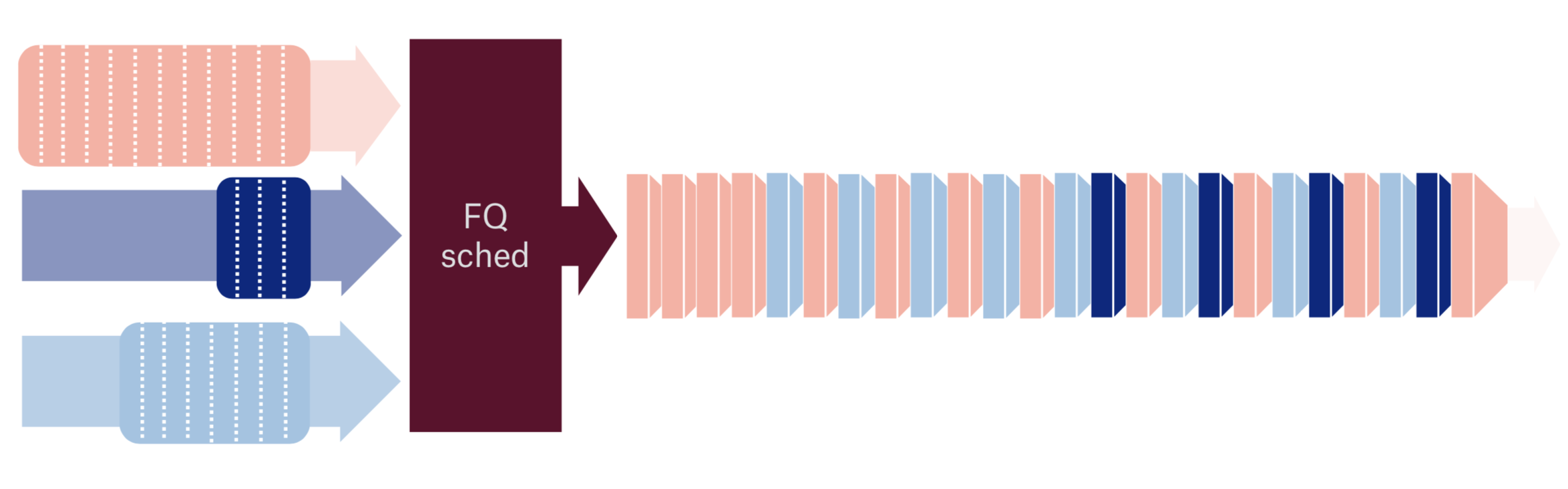
Starting from the lowest layers of the stack here is a Fair Queueing packet scheduler example: not only because it introduces fairness between flows, but also adds “pacing” to the upper level protocol. Let’s look at some specific examples.
Without fair queueing, packets will be dumped to the network as they arrive from the TCP stack, which will lead to the huge Head-of-Line blocking further down network stack.
With FQ packets of different flows are interleaved and one flow no longer blocks another.
Without pacing, if you want to send multiple megabytes of data to the user, and current TCP congestion window allows that, then you’ll just dump thousands of packets onto the underlying network stack.
With pacing, TCP will hint packet scheduler a desired sending rate (based on the congestion window and rtt) and then scheduler is responsible for submitting packets to the network stack every once in a while to maintain that steady sending rate:
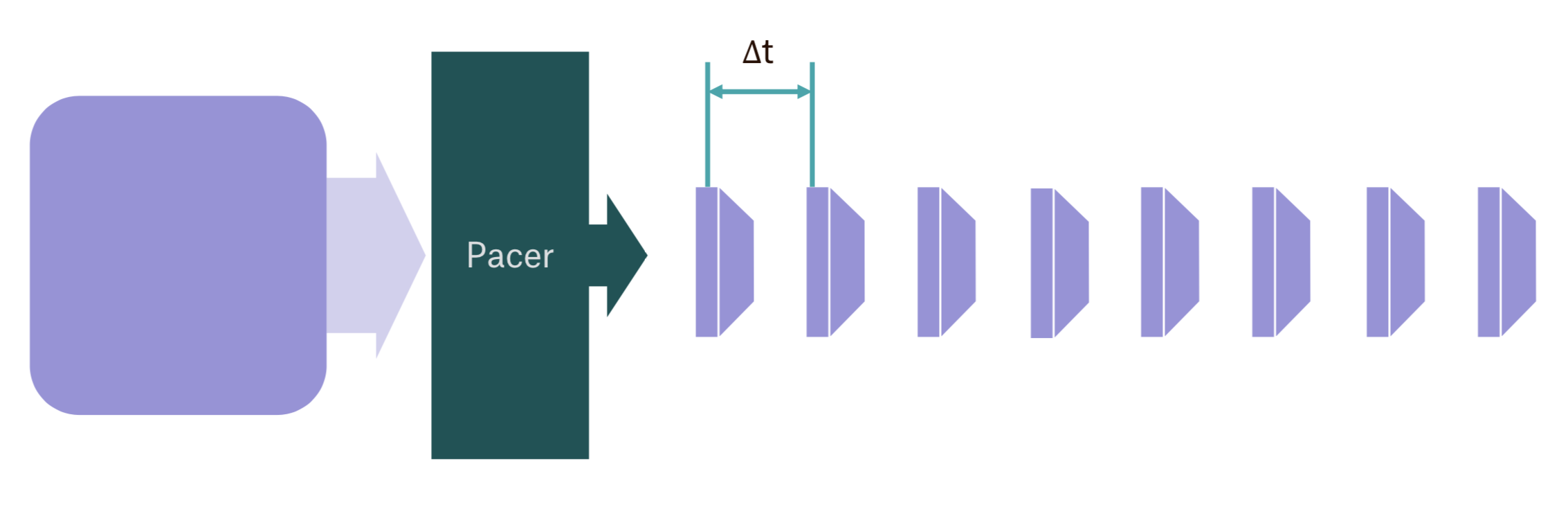
FQ comes at a relatively low CPU cost of around 5%, but it essentially makes routers and shapers along the path way happier, which leads to lower packet loss and less bufferbloat.
Fun fact: when we first deployed FQ we’ve noticed that all the buffer drops on our Top-of-the-Rack (ToR) switches had gone away. Even though they were very beefy boxes capable of handling terabits of traffic it seems like they had shallow buffers and were susceptible to packet drop during microbursts.
This is only one of the features that new Linux kernels provide, including but not limited to: Tail Loss Probe, TCP Small Queues, [TCP_NOTSENT_LOWAT], RACK, etc. We work on network- and transport-level optimizations from time to time—and when we do, it’s super fun and usually involves some amount of Wiresharking and packetdril ling. For example, one upcoming project for the Traffic team is to evaluate BBR v2 (once it is ready for public testing). TLS All connections to Dropbox are protected by TLS that encrypts and authenticates data in transit over the public internet. We also re-encrypt data and send it over an encrypted and mutually authenticated channel over our backbone network.
Since we use the same TLS stack internally for gRPC, we are very invested in its performance, especially around the TLS handshake part, where we make sure our libraries are using the most efficient hardware instructions possible, and for large file transfers, where we try to minimize the number of memory copies that they perform.
Our TLS setup is relatively simple: BoringSSL, TLS tickets with frequently rotated ephemeral keys, preferring AEAD ciphersuites with ChaCha20/Poly1305 for older hardware (we are very close the Cloudflare’s TLS config.) We are also in the process of rolling out the RFC version of the TLS 1.3 across our Edge network.
As for the future plans: as our boxes get closer to 100Gbit we are starting to look towards [TCP_ULP] and how we can add support for it to our software stack.
HTTP
The main job of the nginx proxies on the Edge is to maintain keep alive connections to the backends in data center over our fat-long-pipe backbone. This essentially means that we have a set of hot connections that are never constrained by CWND on an almost lossless link.
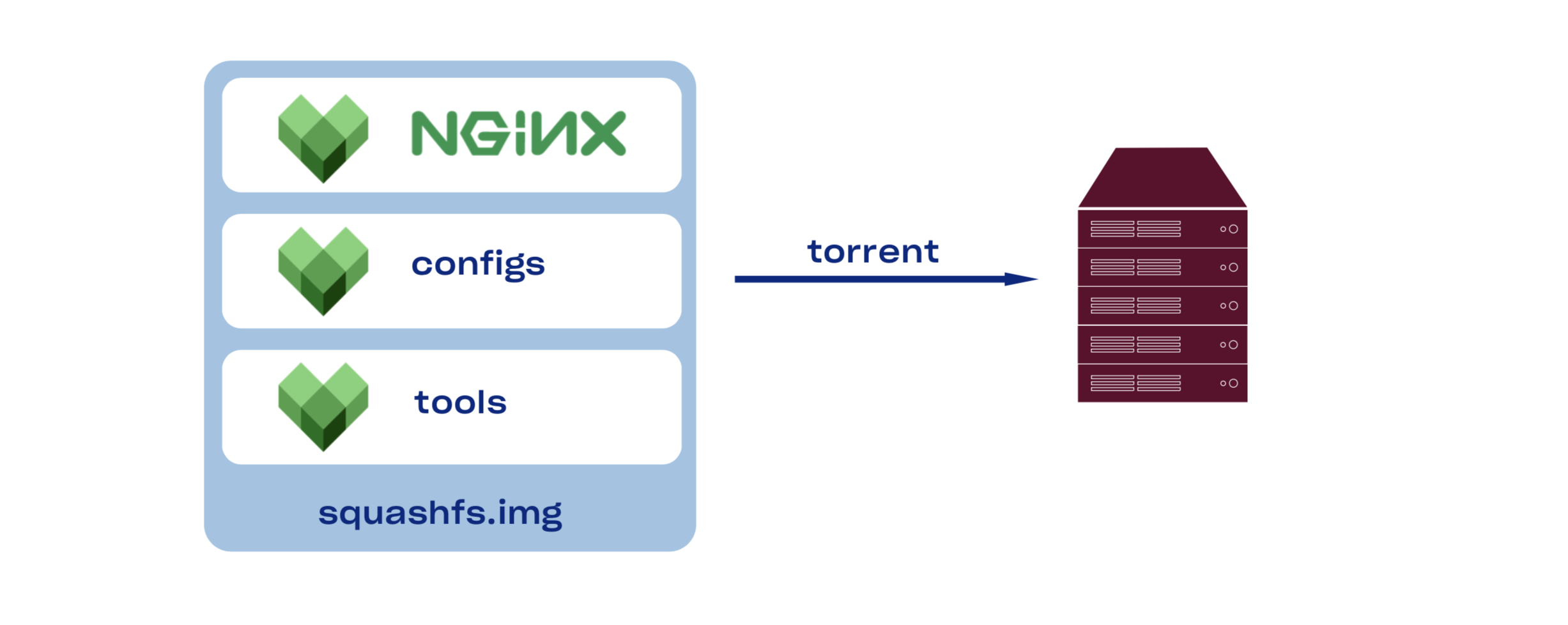
Very quick note about how we build and deploy nginx: like everything else in Dropbox, we use Bazel to reproducibly and hermetically build a static nginx binary, copy over configs, package all of this into a squshfs, use torrent to distribute resulting package to all the servers, mount it (read-only), switch symlink, and finally run nginx upgrade. We probably should write a blog post on it too, since it is very simple and very efficient.
Our nginx configuration is static and bundled with the binary therefore we need a way to dynamically configure some aspects of the configuration without full redeploy. Here is where Upstream Management Service kicks in. UMS is basically a look-aside external loadbalancer for nginx which allows us to reconfigure upstreams on the fly. One can create such system by:
- Regenerating config for nginx and hot reloading it. Sadly, when used extensively this approach negatively impacts connection reuse and increases memory pressure
- Using configuration API from the nginx plus
- Using standalone sidecar proxy on the same box, but that will lead to major increase in CPU/MEM resource usage
- Using Lua APIs or custom C modules
Because we are already relying on the Lua there, we’ve built a data plane for UMS with it by combining a balancer_by_lua_block directive and ngx.timer.every hook that periodically fetches configuration from control plane via https.
A nice side effect of writing the balancer module in Lua: we can now quickly experiment with different loadbalancing algorithms before writing them in C. The downside of Lua is that it is tricky to test, especially in a company where Lua is not one of the primary languages.
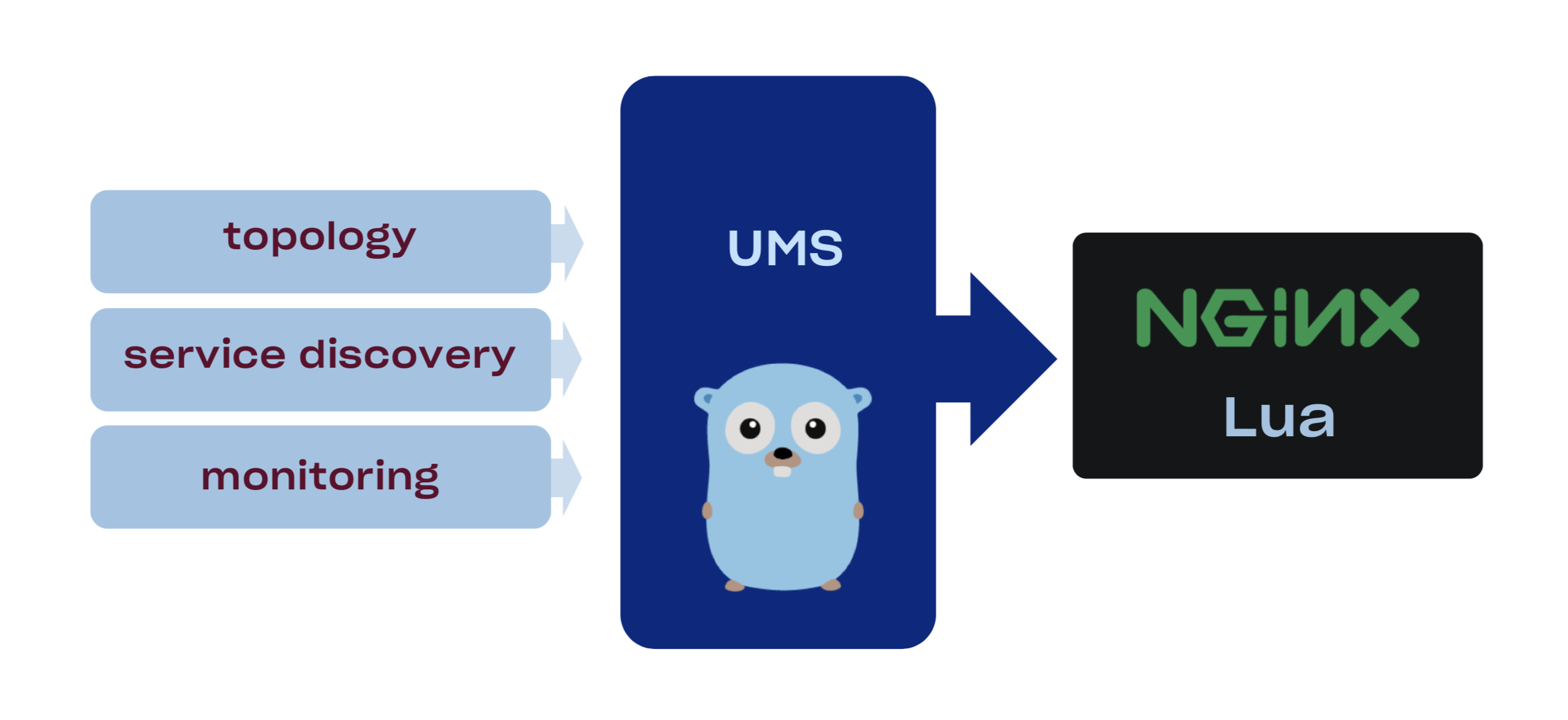
Control plane for UMS is a Golang service that gets information from our service discovery, monitoring system, and manual overrides, then aggregates and exposes it as a REST endpoint that nginx then accesses through a simple httpc:request_uri. gRPC Nginx is terminating HTTP, HTTP/2, and gRPC connections on the Edge. Ability to proxy gRPC through our stack allows us to experiment with our apps talking gRPC directly to the application servers. Being able to do that streamlines development process and unifies the way services communicate externally and internally.
We are looking how we can use gRPC for all APIs. For the APIs that we can’t switch to gRPC, like web, we consider converting all HTTP requests into the gRPC method calls right at the Edge.
Wrap up and future blog posts
All of this pretty much covers the external part of Traffic Infrastructure, but there is another half that is not directly visible to our users: gRPC-based service mesh, scalable and robust service discovery, and a distributed filesystem for config distribution with notification support. All of that is coming soon in the next series of blog posts.
We’re hiring!

The Traffic team is hiring both SWEs and SREs to work on TCP/IP packet processors and loadbalancers, HTTP/2 proxies, and our internal gRPC-based service mesh. Not your thing? Dropbox is also hiring for a wide variety of engineering positions in San Francisco, New York, Seattle, Tel Aviv, and other offices around the world.


