

Magic Pocket, the exabyte scale custom infrastructure we built to drive efficiency and performance for all Dropbox products, is an ongoing platform for innovation. We continually look for opportunities to increase storage density, reduce latency, improve reliability, and lower costs. The next step in this evolution is our new deployment of specially configured servers filled to capacity with high-density SMR (Shingled Magnetic Recording) drives.
Dropbox is the first major tech company to adopt SMR technology, and we’re currently adding hundreds of petabytes of new capacity with these high-density servers at a significant cost savings over conventional PMR (Perpendicular Magnetic Recording) drives. Off the shelf, SMR drives have the reputation of being slower to write to than conventional drives. So the challenge has been to benefit from the cost savings of the denser drives without sacrificing performance. After all, our new products support active collaboration between small teams all the way up to the largest enterprise customers. That’s a lot of data to write, and the experience has to be fast.
As with our initial Magic Pocket launch, we attacked the problem through inventive software and server architecture to ensure that this solution matched our standards for annual data durability of over 99.9999999999%, and availability of over 99.99%. Our ambition here is to use our expertise in software for large distributed systems to enable us to take advantage of the ongoing developments in drive technology before our competitors. We believe that future storage innovations, including solid-state-drives (SSDs), will benefit from the same architectural approaches we’re developing for SMRs, so that our investment now will pay off in multiples.
In this post, we’ll describe our adoption of SMR HDD technology in the Dropbox Storage platform, Magic Pocket. We discuss why we’ve chosen to use SMR, hardware tradeoffs and considerations, and some of the challenges we encountered along the way.
What is SMR and why are we using it?
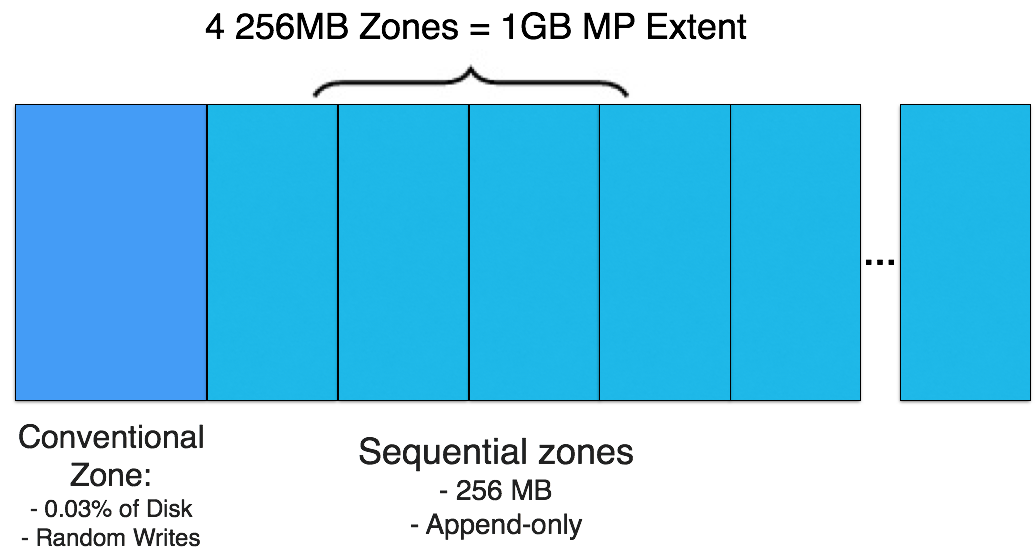
Conventional Perpendicular Magnetic Recording (PMR) HDDs allow random writes across the entire disk. Shingled Magnetic Recording (SMR) HDDs offer increased density by sacrificing random writes for forced sequential writes. Squeezing the tracks on SMR disks together causes the head to erase the next track. A small, conventional area at the outside diameter allows for caching random writes as well as using SSD.
SMR HDDs offer greater bit density and better cost structure ($/GB), decreasing the total cost of ownership on denser hardware. Our goal is to build the highest density Storage servers, and SMR currently provides the highest capacity, ahead of the traditional storage alternative, PMR.


Types of SMR
There are three types of SMR HDDs to consider: Drive/Device Managed, Host Aware, and Host Managed SMR disks. While we originally evaluated both Host Aware and Host Managed SMR disks, we finally settled on Host Managed disks for our fleet.
Drive or Device Managed SMR disks allow the host to treat them like conventional drives. Non-sequential writes are buffered in the small conventional area on each disk, and then later on transcribed to the sequential zones. This involves reading the data from the sequential zone and writing the original data merged with the new data back to the sequential zone.
Host Aware drives allow a host that understands SMR disks to control the writing of the sequential zones. Hosts can open and close zones, monitor write pointers, partially write sequential zones and avoid conventional area caching and performance bottlenecks caused by rewriting zones. Host Aware drives offer more control than Drive Managed SMR, which is our defining priority.
Host Managed SMR drives require the host to manage the sequential zones on its own. The drive does no copying of new data to sequential zones and no caching of data in the conventional area. Hosts must explicitly open, fill and close sequential zones. Host Managed SMR offer the most control over the way data is stored on the drive and is consistent with how we have built things before.
Dropbox Storage Architecture

Hardware Trade-offs
While implementing SMR disks, there were a number of hardware trade-offs we had to consider. We worked to optimize performance and data transfer speeds, but also needed to consider hardware reliability and total cost of ownership. This required us to look at just about every element of our hardware stack.
Chassis density
Our latest design fits approximately 100 LFF (Large Form Factor) disks in a single chassis, which makes them the densest storage system in production. The 100 LFF disk per chassis had design constraints of a physical limit of 4U in rack space in a 19” standard datacenter rack and a requirement to stay at a 42” depth limit. This keeps us from needing to design custom datacenter racks. We keep each rack limited to housing 8 fully configured chassis to avoid deviating from standard datacenter flooring specifications.
Memory and CPU
One thing that came out of our testing was the decision to increase the memory to 96GBs per host. We did this because we keep an in-memory index of blocks and their offsets/length on the disk. With 14TB SMR drives we significantly increased the capacity of an individual chassis; each machine will store 2.29 times more blocks than a chassis in our previous architecture. This means that our block index will need a proportional increase in memory resulting in 96GB per machine.
We also had to slightly upgrade our CPUs by moving from 16 to 20 cores, 40 threads, per chassis. The additional processing power was necessary to keep the total chassis I/O performance above 40Gbps and 45Gbps for writes and reads.
SAS Controller
In order to further improve reliability and reduce complexity, we moved from a RAID controller to a Host Bus Adapter (HBA). The initial benefit to using RAID was to leverage the cache to reduce write latency. This proved a costly endeavor with a lot of overhead: we were creating individual RAID 0 and managing associated firmware and bugs in the raid controller only to expose a single block device. We also worked to enable Direct I/O to reduce CPU usage from double-buffering.
An added benefit of removing the overhead of creating so many RAID 0 devices was cutting the overall provisioning time for this storage system from up to 2 hours total down to a quick 30 minutes. This allows us to focus more on realizing the technology and less time setting it up.
Adding the HBA simplified our architecture at the expense of our initial cache device. We understood that any emerging technology is an exploration into the unknown. In order for us to reduce the amount of exposure we focused on removing complexity as a success criteria.
Cache
With the removal of the RAID controller, we discovered that we needed to compensate for the loss of write cache. Our solution to this was to add our own caching layer to maintain the performance requirements. An SSD drive could compensate for the decision to remove the RAID controller.
In previous generations of storage systems, data from network had been directly written to the drives. Writing to large SMR drives is time-consuming so we needed to ensure the network doesn’t get stalled when the drives are busy. To make this process asynchronous and non-blocking, we added an SSD to cache the data which is then lazily flushed to the SMR disks in the background.
While this design works for us now, we are seeing that as the density increases we are saturating the SATA bus and have a need to use another transfer protocol. We’ve discovered that we are pushing the limits of the SATA bus and it has become a bottleneck we can see from our SSDs. Future generations will likely have an NVMe design for caching.
Network
Magic Pocket started with lower density chassis (around 240TB). We moved up in density over time as network speeds increased and we didn’t have to compromise recovery time for density, which is a lever to lower TCO.
Using 14TB SMR disks put the new chassis at 1.4PB per host. This level of storage density required another increase in network bandwidth to assist with system recovery. We are comfortable with an acceptable increase of the failure domain as long as the recovery time meets our SLA. We decided we needed to design the SMR based chassis with a 50Gbps NIC card per chassis and a non-blocking clos fabric network with 100Gbps uplinks. The benefit we gained is the ability to quickly add data to the chassis upon deployment and the ability to quickly drain the chassis in times of repair, ensuring Magic Pocket meets its SLA.
Software Redesign
Per the Magic Pocket design, Object Storage Devices (OSD) is a daemon the behaves very similar to key value store optimized for large-sized values. We run one daemon per disk per machine and only that daemon has access to the disk. OSD treats disks as a block device and directly manages data layout on the drive. By not using a filesystem on SMR, we are able to optimize head movements and prioritize disk IO operation based on the type fully within the software stack. To communicate with the SMR disk, we use Libzbc as the basis for disk IO.
SMR stores metadata indexes on sequential zones. We got lucky with two factors. First, the capacity sizes evenly divide across 4 zones of logical space (256MB x 4 = 1GB). Had this not been divisible by 4, any excess space would have been lost or required more invasive changes to reclaim that space. Second, the ratio of metadata to block data is 0.03% which fits well with ratio of conventional area and sequential area.
We discovered large writes are much better for SMR (averaging 4-5 MB). To optimize here, writes are buffered in certain stages. Originally, we tried flushing from SSD to SMR as soon as possible with multiple small writes, but this was not efficient, so we moved to model of buffering and less writes of larger size.
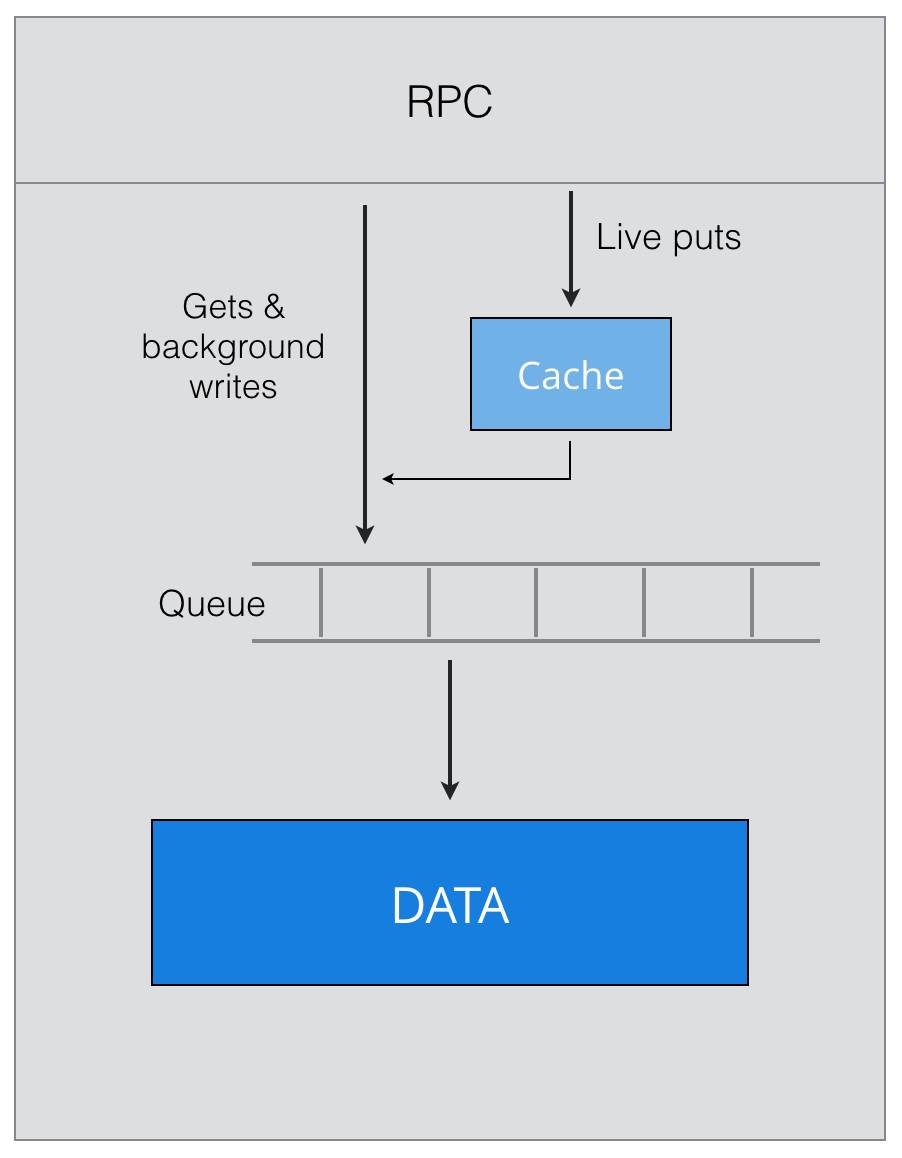
Our highest priority was managing live traffic. The live traffic is made up of incoming new blocks and writes to support that user data. One of the biggest challenges here is latency!
All the writes to the disk must be sequential and aligned to the 4k boundary; however, when the live data comes in, it doesn’t always fit into neat 4k chunks. This is where using a staging area comes to our rescue. The background process of flushing these blocks from SSD to disk takes care of alignment and making sure we do large writes.
Managing background repairs, which require a huge amount of reads and writes, is less time-critical, so they can occur more slowly.
The Challenges of Using SMR
The chief challenge of making a workload SMR-compatible is taking a random read/write activity and making it sequential. To accomplish this, we rewrote OSD so that metadata, which is frequently updated, is kept in the conventional area of the SMR disk where read/write writes are supported, while the immutable block data is kept on sequential zones.
We needed to overcome dealing with sequential writes of SMR disks, which we accomplished with a few key workarounds. For example, we use an SSD as a staging area for live writes, while flushing them to the disk in the background. Since the SSD has a limited write endurance, we leverage the memory as a staging area for background operations. Our implementation of the software prioritizes live, user-facing read/writes over background job read/writes. We improved performance by batching writes into larger chunks, which avoids flushing the writes too often. Moving from Go to Rust also allowed us to handle more disks, and larger disks, without increased CPU and Memory costs by being able to directly control memory allocation and garbage collection. Check our presentation on how we used Rust to optimize storage at Dropbox to learn more.
Through ongoing collaboration with our hardware partners, we leveraged cutting edge technology to ensure our entire chain of components were compatible. In our configuration, we used an expander to distribute the HBA Controller, allowing the HBA to evenly spread connection to all the drives. However, the expander was initially incompatible with SMR. In this case, and others like it, we collaborated with vendors and co-developed the firmware needed to create functional harmony within the hardware chain.
One of the mechanical challenges of having an average of 100 drives in a chassis is that we are limited in how many hardware variations we can make when bottlenecks are discovered. Space is our limiter now, so looking at components that fit in the system design will present new challenges in the future.
What’s Next?
This new storage design now gives us the ability to work with future iterations of disk technologies. In the very immediate future we plan to focus on density designs and more efficient ways to handle large traffic volumes. With the total number of drives pushing the physical limit of this form factor our designs have to take into consideration potential failures from having that much data on a system while improving the efficacy of compute on the system.
Conclusion
We’re committed to iterating and improving on Magic Pocket and the Dropbox infrastructure, and this deployment is just one step along the way. This has been an exciting and challenging journey introducing new storage technology in a reliable way. This journey involved not only thinking about the mechanical structure of a system, but also the major software updates that would be required. Without the collaboration between the engineering teams this would not have been possible. Our infrastructure will benefit twofold, thanks to greater density and a better cost structure unleashing our Dropbox user’s creative energy.

Project Contributors: Chris Dudte, Victor Li, Preslav Le, Jennifer Basalone, Alexander Sosa, Rajat Goel, Ashley Clark, James Turner, Vlad Seliverstov, Sujay Jayakar, Rami Aljamal


