

The Lifetime of a file
The access characteristics of a file at Dropbox varies heavily over time. Files are accessed very frequently within the first few hours of being uploaded but significantly less frequently afterwards. Here is the cumulative distribution function of file accesses for files uploaded in the last year.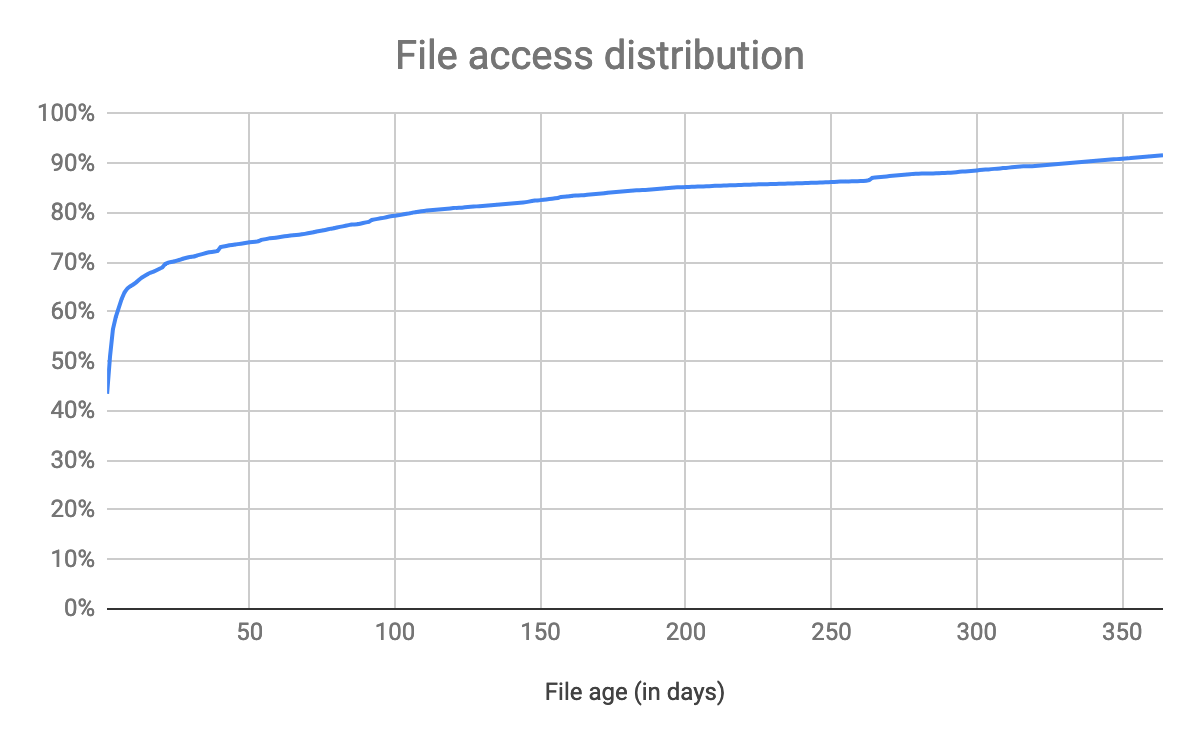
Over 40% of all file retrievals in Dropbox are for data uploaded in the last day, over 70% for data uploaded in the last month, and over 90% for data uploaded in the last year. This pattern is unsurprising. A new upload triggers a number of internal systems that fetch the file in order to augment the user experience, such as perform OCR, parse content to extract search tokens, or generate web previews for Office documents. Users also tend to share new documents, so a file is also likely to be synced to other devices soon after upload. In general, people are much more likely to access files they have recently uploaded rather than files they uploaded years ago.
We refer to data that’s accessed frequently as “warm” and infrequently accessed data as “cold.” The differences in access characteristics between warm and cold data open up opportunities for cost optimization by tailoring the system to each class of data.
Magic Pocket
Magic Pocket is our system for storing files. Dropbox splits files into chunks, called blocks, up to 4MB in size. The blocks are immutable—all metadata operations and related complexities around mutations and revision history are handled by the metadata layers on top. Magic Pocket’s job is to durably store and serve those large blocks.
This system is already designed for a fairly cold workload. It uses spinning disks, which have the advantage of being cheap, durable, and relatively high-bandwidth. We save the solid-state drives (SSDs) for our databases and caches. Magic Pocket also uses different data encodings as files age. When we first upload a file to Magic Pocket we use n-way replication across a relatively large number of storage nodes, but then later encode older data in a more efficient erasure coded format in the background.
Within a given geographic region Magic Pocket is already a highly efficient storage system. Replicating data across geographical regions makes Magic Pocket resilient to large scale natural disasters but also significantly less efficient in aggregate.
Cross-region Replication
To understand our cold storage developments we first need a high level understanding of how Magic Pocket works.
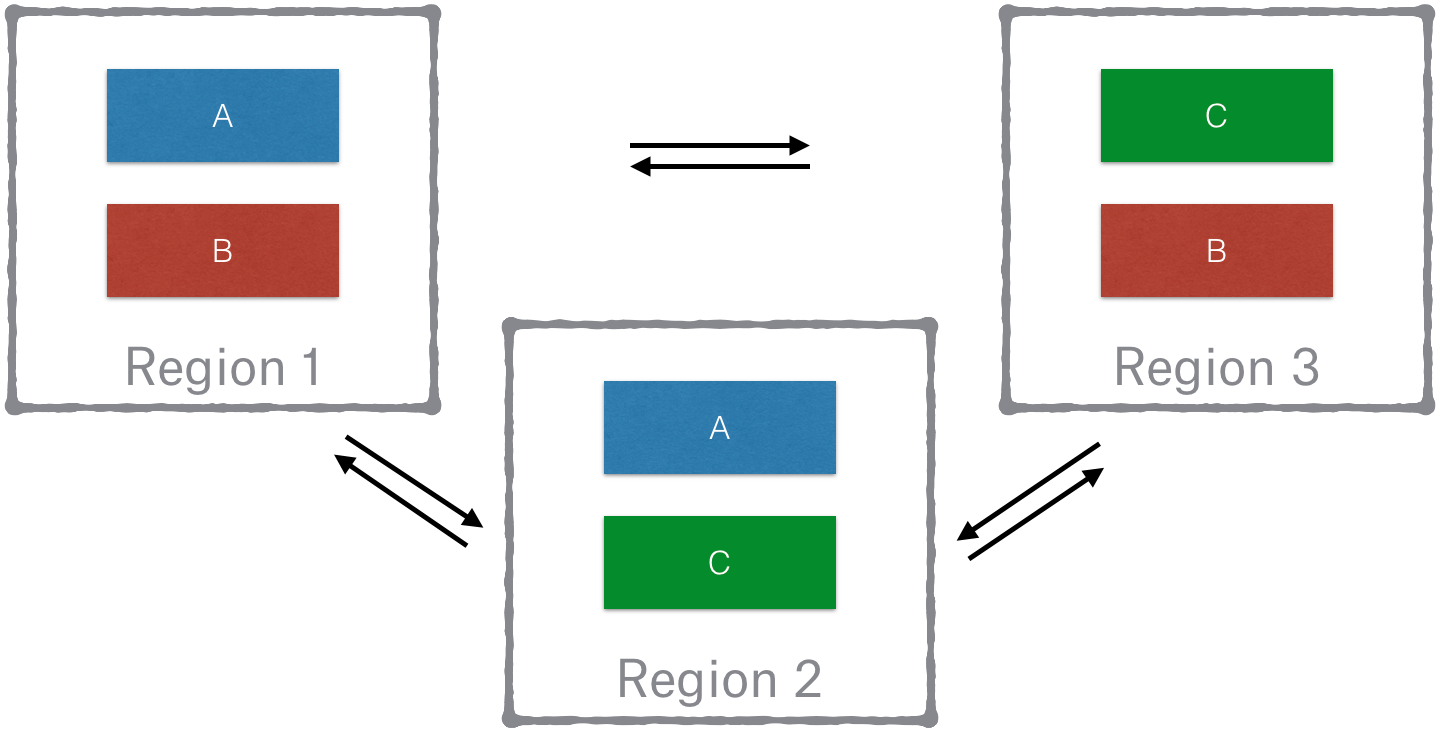
Magic Pocket stores blocks in a highly reliable manner within a storage region but it also stores this data independently in at least two separate regions. Within a region things can get quite complicated, but the interface between regions is quite simple. It’s basically a glorified version of Put, Get, and Delete.
Many companies only replicate data across multiple data centers located within tens or a few hundred miles from each other. At Dropbox we set the bar for durability and availability during region outage much higher and replicate data across data centers located thousands of miles apart. We effectively store double the amount of data we would otherwise to better survive large-scale disasters.
This overhead has long been an inefficiency that we wanted to rectify. Ever since we built Magic Pocket, we kept asking ourselves, can we maintain the same high bar for safety but in a more efficient way?
Requirements
In order to better tailor the system for the different workloads, we decided to operate two storage tiers. We built a new cold storage tier, and renamed the original Magic Pocket system the warm tier. We asynchronously migrate data in the background as it becomes cold. Everything that’s not cold is considered warm.
The high level requirements for a cold storage system are simple. We can’t sacrifice durability. Period. No matter how rarely any file is used, Dropbox users trust us with their most important stuff. We need to still be able to tolerate a full region outage and multiple rack failures in the surviving regions simultaneously. Availability-wise, we can’t sacrifice read availability but interestingly we don’t actually care about the write availability. Since user-facing writes get written to the warm storage tier we can pause writes into the cold storage tier at any time without affecting users.
We can tolerate a slight increase in latency for cold data, since Magic Pocket is already very fast compared to the time it takes to send files over the internet. However, we still need reliably fast access: you probably don’t need your 2007 tax records too often, but when you do, you want them immediately, not in few minutes.
Initial Designs
We needed to somehow remove the full cross-region replication, but still be able to tolerate geographic outages. If we were to replicate data across regions instead of keeping a full internally-replicated copy in each region, we could reduce storage cost, but this would come with an increased wide-area network cost when we need to reconstruct a file during a region outage. This potential higher network cost is in fact a good tradeoff against lower storage overhead for cold data however, since this data isn’t fetched very frequently.
Unfortunately, we did not get this right from the first attempt. We spent a significant amount of time developing solutions that we ended up unhappy with. To better understand our ultimate “good” solution, let’s first look at couple of seemingly-good ideas that didn’t pan out.
Single erasure code spanning multiple regions
The obvious approach was to remove the strict boundaries between regions, where each one replicates independently, and instead have single software instance that does erasure coding across all regions. The erasure code should have enough internal redundancy to tolerate a large scale regional disaster.
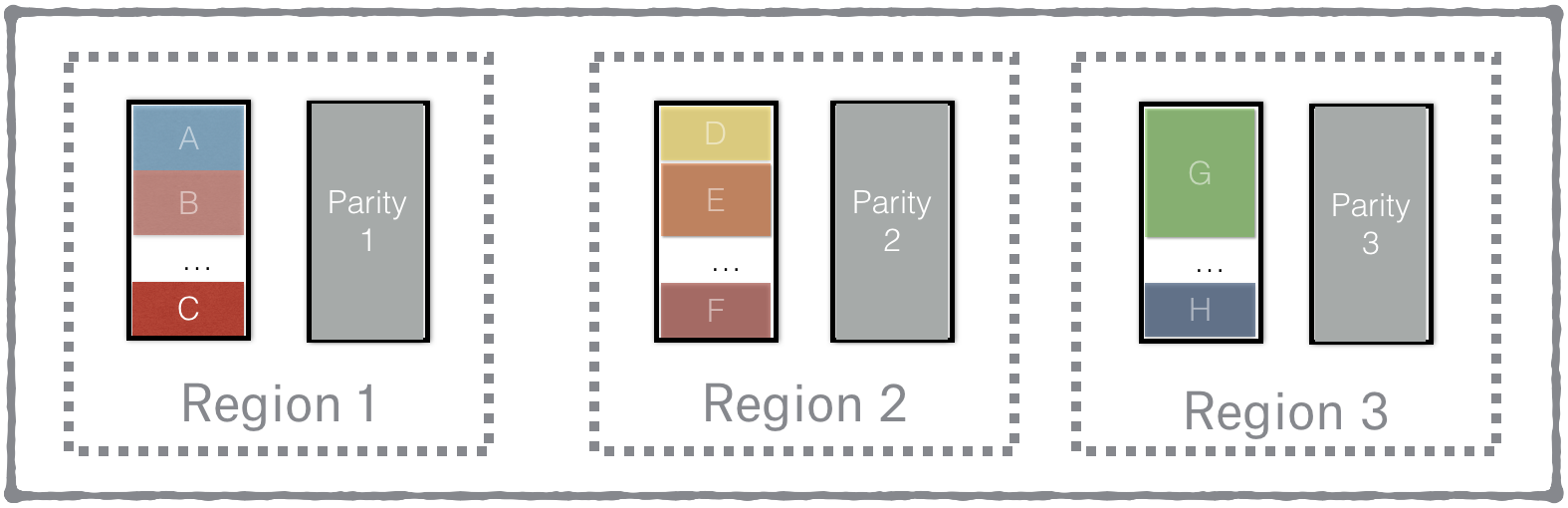
We actually went quite far with this approach. We got the prototype of the new system up and running in our stage environment relatively quickly but then started finding more issues and hidden costs. The additional complexity in the design also made all our other storage initiatives more involved and as a result slowed down development.
The biggest problem with this approach is that we can’t truly mitigate the durability risk. We promised that the system would not sacrifice durability. In purely-theoretical terms we still provided as many “nines of durability” as the original system, but in practice we could not deliver on that promise. Given that we only had a single large-scale region running a single version of software, a single software bug could wipe out everything no matter how many copies we store. Magic Pocket’s independent region model is extremely resilient to human error—whether it is human writing a software bug or an operator error executing a wrong command. Eliminating the strong logical separation between two storage regions takes away a last line of defense and significantly elevates the possibility of us losing data in the long run.
We killed the project after more than nine months of active work. As an engineer, it is not easy to give up something you have been trying to make work for so long. Some of the early conversations were controversial but ultimately everyone agreed killing the project was the right decision for Dropbox and our users.
Facebook’s Warm BLOB Storage System
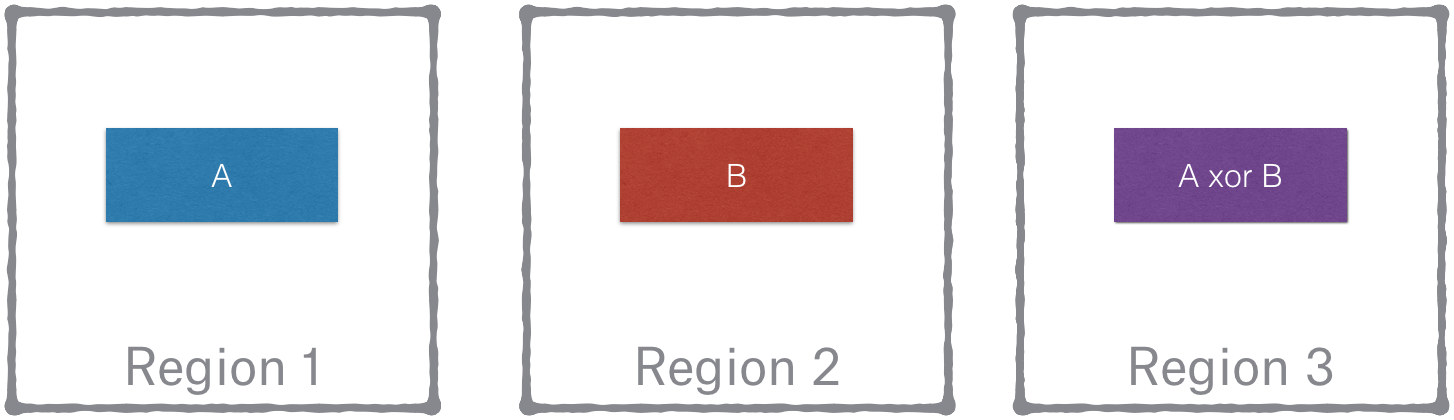
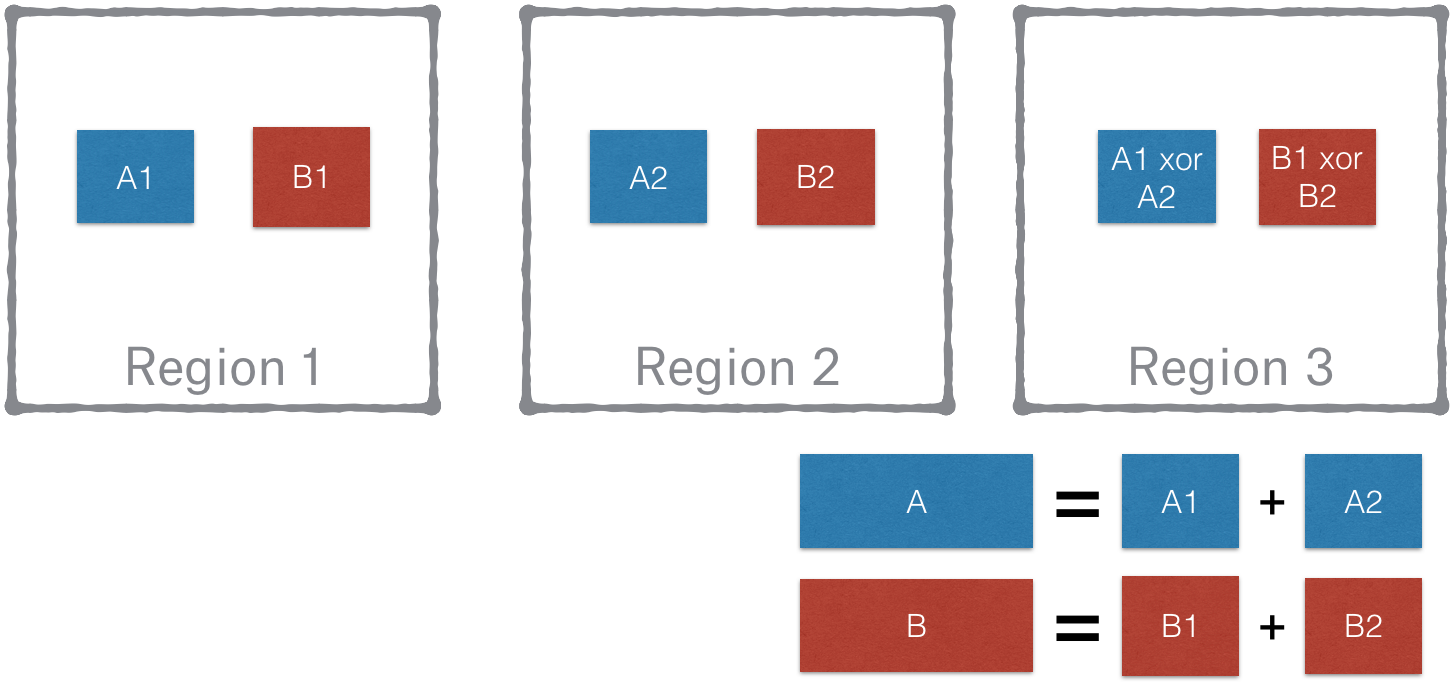
The idea is to pair each volume/stripe/block with a buddy volume/stripe/block in a different geographic region, and then store an XOR of the buddies in a third region. In the above example, block A can be fetched from Region 1. If Region 1 is not available, then block A can be reconstructed from fetching block B and A xor B from Region 2 and Region 3 respectively and performing an XOR. That is a neat idea. We didn’t need to change anything in Magic Pocket region’s internals, and just replicate differently on top of them.
We decided to explore this in more detail again… and gave up soon after. Maintaining a globally available data structure with these pairs of blocks came with its own set of challenges. Dropbox has unpredictable delete patterns so we needed some process to reclaim space when one of the blocks gets deleted. All that added up to a lot of complexity that made it less suitable for our use case.
New Replication model
Not all of the previous work was wasted. Spending so much time on trying to make the previous designs work helped us build a better intuition about tradeoffs on the network stack. We ended up challenging one of our very early implicit assumptions. Do we really need a request for a single block to be able to be fully served from within a single region in the best-case scenario when all regions are up? Given that cold data is infrequently accessed, it’s fine to always incur a higher network cost for accessing it. Removing that constraint of serving from a single region led us to the following design.
To illustrate the idea, we are going to use a three region example and XOR for generating a parity block. This method can be generalized and applied to larger set of regions by using something like Reed-Solomon erasure codes to generate parities.
Similar to the previous design, we don’t want to change the internal architecture within a region. However, instead of finding and pairing similar sized blocks, we can split a single block into pieces called fragments, and stripe those fragments across multiple regions.
To put a block, in our three region example, we split it in two pieces called fragments. We put the first fragment in Region 1, the second fragment in Region 2 and compute the XOR of the fragments to form a third parity fragment and put it in Region 3.
Because we are migrating data to the cold tier asynchronously, we can ignore complicated situations where one of the regions isn’t available. If a region is down we can just pause the migration until all three regions are back up.
To get a block, we issue a get request to all three regions, wait for the fastest two responses, and cancel the remaining request. We have absolutely no preference over which two fragments we use to perform the reconstruction. Performing an XOR or an erasure decoding is a negligible operation compared to reading data from disk and transferring it over network.
To delete a block, we just need to delete all fragments when the block is no longer referenced. Another nice property is that we can do this independently in each region. This allows us to use different versions of the deleter software and run these deletions at different times to prevent a software bug from wiping all fragments by mistake.
Latency The most obvious downside of this model is that, even in the best-case, we can’t satisfy a read without fetching fragments from multiple regions. This is not only not as big of a problem as we thought, but also turned out to be a blessing in disguise on many dimensions.
Here are latencies we measured at various percentiles as we were rolling out the new storage tier:
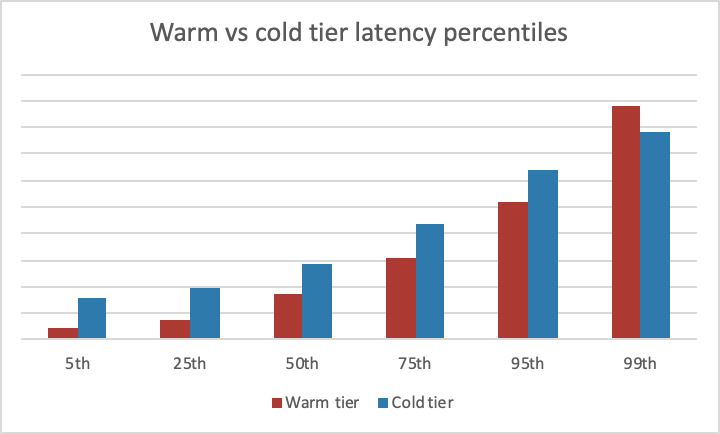
To begin with, the 5th percentile is significantly higher in the cold tier because we need at least one cross-region network round-trip to retrieve data from the cold tier. Looking at 25th, 50th, 75th and 95th percentile, the difference between the warm and cold tiers stays constant at roughly one network round-trip. Dropbox’s network stack is already heavily optimized for transferring large blocks of data over long distances. We have a highly tuned network stack and gRPC-based RPC framework, called Courier, that is multiplexing requests over HTTP/2 transport. This all results in warm TCP connections with a large window size that allows us to transfer a multi-megabyte block of data with a single round-trip.
We were initially very puzzled by the results at the 99th percentile, however. The cold storage tier had lower tail latency than the warm tier! This was confusing initially but after some investigation it started to make sense. The cold tier was getting the fastest 2 out of 3 requests, while the retry logic in the warm tier was more naive—it was first fetching from the closest region and only issuing a request to the other region if the first attempt fails or times-out. There are always some arbitrary slowdowns in a large scale distributed system. Because the warm tier was getting the majority of the traffic we needed to be slightly smarter and can’t simply issue two requests in parallel. Instead we ended up modifying the warm tier to optimistically issue a retry against the second region if the first request attempt does not arrive by given time budget. This allowed us to also bring down high tail latencies in the warm tier, with a small network overhead. You can learn more about this technique from Jeff Dean’s excellent talk at Velocity.
One beautiful property of the cold storage tier is that it’s always exercising the worst-case scenario. There is no plan A and plan B. Regardless of whether a region is down or not, retrieving data always requires a reconstruction from multiple fragments. Unlike our previous designs or even the warm tier, a region outage does not result in major shifts in traffic or increase of disk I/O in the surviving regions. This made us less worried about hitting unexpected capacity limits during emergency failover at peak hours.
As mentioned in our requirements, we did not have a fixed target for latency, but only directional guidance. Overall, the results we got significantly beat our expectations. Such a small difference would not affect the end user experience, which is dominated by transferring data over the internet. That allowed us to be more aggressive in what data we consider ‘cold’ and eligible for migration.
Durability
The biggest win in terms of durability is keeping the architecture layered and simple. We can operate each region independently as before and run different versions of software allowing us to detect issues that might slip through testing before it affects all copies of the data. Even rare bugs that take a long time to occur or could slip through our release process are extremely unlikely to affect the same data in two or more regions simultaneously. This is invaluable last line of defense against unknown unknowns. Although it’s hard to quantify in a math equation, in practice it allows us to move faster while being assured of our extremely high level of durability.
We’re still vulnerable to bugs in the replication logic that might occur before data is persisted across the independent regions. However, the surface area, amount of data at risk, and number of code paths involved are limited. We can significantly mitigate the risk from bugs by not immediately purging data from the warm tier after cold tier migration. We perform multiple rounds of extensive validations before we purge the data from its original location.
Cost savings
The warm tier replication model is a 1+1 replication scheme, with one data fragment and one parity fragment, plus replication within these regions, of course. The three region cold tier example is a 2+1 replication scheme, with two data fragments and one parity fragment, plus internal region replication. The total replication factor for the warm tier is 2 * region_internal_replication_factor while the cold tier is 1.5 * region_internal_replication_factor. Thus we can reduce disk usage by 25% by using a three region setup.
As mentioned previously, this approach can be generalized for more regions. If we use 4 regions and are willing to tolerate losing any 1 of them, we will have a 3+1 model, which would give us 33% savings. It can also be extended further, to let’s say 4+1 or 5+2, depending on the trade-offs one is willing to make between cost savings and the number of simultaneous region losses tolerated.
Conclusion
While exploring various solutions to building a cold storage tier, we learned that the set of constraints we define have a huge impact on the way we approach a problem. Sometimes adding a new constraint, such as keeping an independent failure domains at all costs, does narrow down the search space and help us focus by ruling out designs early. However, sometimes removing a constraint, such as serving all reads from within a region at steady state, can open a whole new realm of possibilities.
We also learned that although we aim to make data-driven decisions, our intuition is sometimes wrong. We rarely have all data to make a decision and sometimes we don’t even know what data points to look for. The only way to make something work is to try and potentially fail. A bad decision might not be as damaging as long as we’re willing to step back, keep ourselves honest, admit defeat, and course correct when needed.
Of course while we learned something about problem-solving, we also ended up with a cold storage system that’s a great fit for our needs. We also got a significant reduction in storage costs without compromising durability or availability, and without introducing any significant complexity in our architecture.
Interested in solving challenging open-ended engineering problems in large scale distributed systems? We’re hiring!
Acknowledgements
Thanks to all current and past members of the Dropbox storage team who’ve contributed to building the cold storage tier: Preslav Le, Alex Taskov, Rebecca Wang, Rajat Goel, Cristian Ferretti, James Cowling, Facundo Agriel, Alexander Sosa, Lisa Kosiachenko, Omar Jaber, and Sandeep Ummadi.


