

In our previous post, we provided an overview of the global edge network that we deployed to improve performance for our users around the world. We built this edge network over the last two years as part of a strategy to deliver the benefits of Magic Pocket.
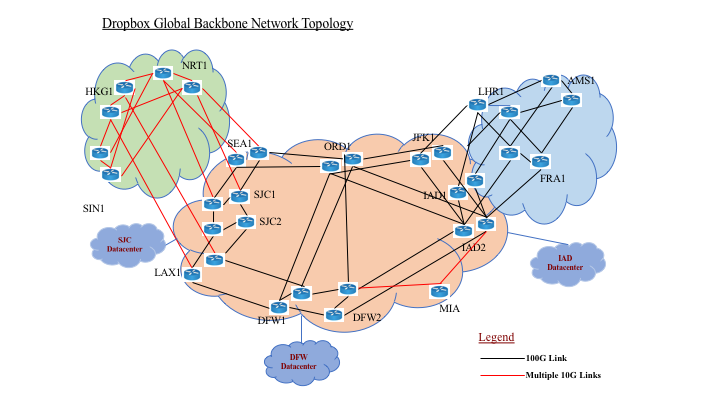
Alongside our edge network, we launched a global backbone network that connects our data centers in North America not only to each other, but also to the edge nodes around the world. In this blog, we’ll first review how we went about building out this backbone network and then discuss the benefits that it’s delivering for us and for our users.
Dropbox backbone network
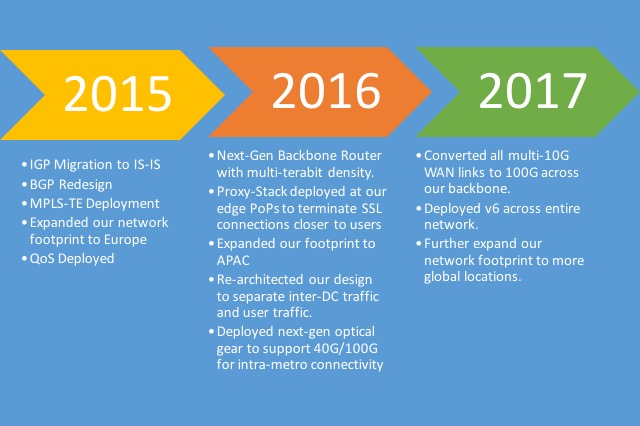
2015: Year of planning and implementing new technologies
In early 2015, we began our network expansion initiative to accommodate for 10X scale, provide high (99.999%) reliability, and improve performance for our users. Our internal forecasts pointed to exponential growth in our network traffic as user adoption continued to grow. As we were planning to scale our network, we began to look at deploying technologies like Quality Of Service (QoS), Multi-Protocol Label Switch (MPLS), IPv6, and overhauling our routing architecture to support future growth.
Routing Architecture:
At that time, our routing architecture was primarily Open Shortest Path First (OSPF) as our Interior Gateway Protocol (IGP), and we had route reflectors (RR) for our Interior Border Gateway Protocol (iBGP) design. As we were planning for 10X scale and deploying new technologies, we were re-evaluating our routing architecture for both IGP and BGP design.
IGP Migration:
One of the biggest sticking points to continuing with OSPF was the complexity in rolling out IPv6. We were originally using OSPFv2, which only supports IPv4. IPv6—which we were upgrading to—requires OSPFv3. Multiple address families in OSPFv3 were not fully supported by all vendors nor widely deployed at that time. This meant we had to run two versions of OSPF to support v4 and v6, which was operationally more complex.
We started to look at replacing OSPF with IS-IS, a protocol-agnostic architecture that runs at OSI layer-2, and can easily support all address types including v4 and v6. In addition, IS-IS uses Type Length Value (TLV) to carry information in Link State Packets. The TLVs make IS-IS easily extensible to carry different kind of information and support newer protocols in future. In Q2 2015 we successfully migrated from OSPF to IS-IS across the entire backbone.
iBGP Design:
Our initial iBGP design was based on a single hierarchy route-reflector (RR) model. But iBGP RRs have their own limitations, including the fact that they offer limited path diversity. After learning routes from clients, RRs advertise a single best path to their peers. This results in RR peers having visibility into only one path for every prefix, which potentially causes all traffic for that prefix to be sent only to one next-hop, instead of being distributed across several equal-cost next-hops.
This results in an unequal load-balance of traffic across the network. We tried to mitigate that issue by using Add-Path, which provides the capability to announce multiple paths. Since Add-Path was still a new feature being developed by routing vendors at that time, we ran into multiple bugs when we tested it. At that point, we decided to come up with a new iBGP design and move away from route reflectors. We debated a couple of design choices, including:
- Full mesh iBGP design across all routers. In this scenario, all routers will have full mesh iBGP with each other. This design solves the lack of path diversity encountered with RRs, as with full mesh iBGP all routers will learn all routes from each other. This works well in a smaller network with fewer routers, but we knew that as our network grew, the number of routers and routes learned would grow significantly. Millions of routes in the control plane can cause memory issues; coupled with any route churn, this can impact CPU and/or RIB/FIB memory, causing significant operational impact.
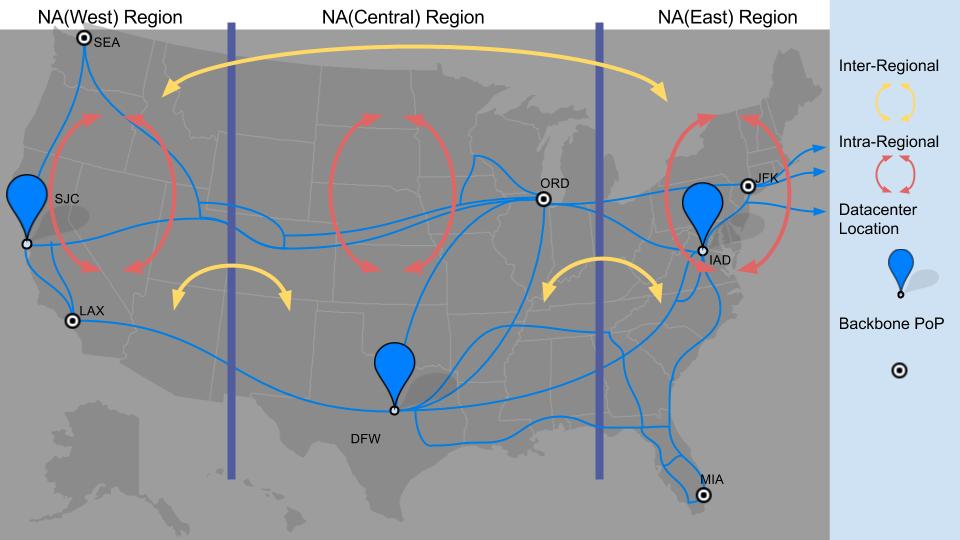
- Full mesh iBGP within a region, with route reflectors across regions. The second approach was to break our backbone network into smaller regions and have full mesh iBGP between routers within a region, while having RRs announce routes between regions. This would solve the route scaling issue as the number of routers in full iBGP mesh would be much lower. But as discussed above, limitations of RRs would still continue to exist even with this design.
We ultimately decided on a hybrid approach of the two: full mesh iBGP that announces selective routes across regions. We now have full mesh iBGP across all routers, but also regionalize our backbone network into smaller groups that have different routing policies. Because transit-provider-routes constitute the bulk of our traffic, we confined routes from transit providers to the region where they originated. All other peering routes and internal traffic is announced across regions. This approach eliminated the limitations of RRs and also solves the route scaling issues due to full-mesh iBGP.
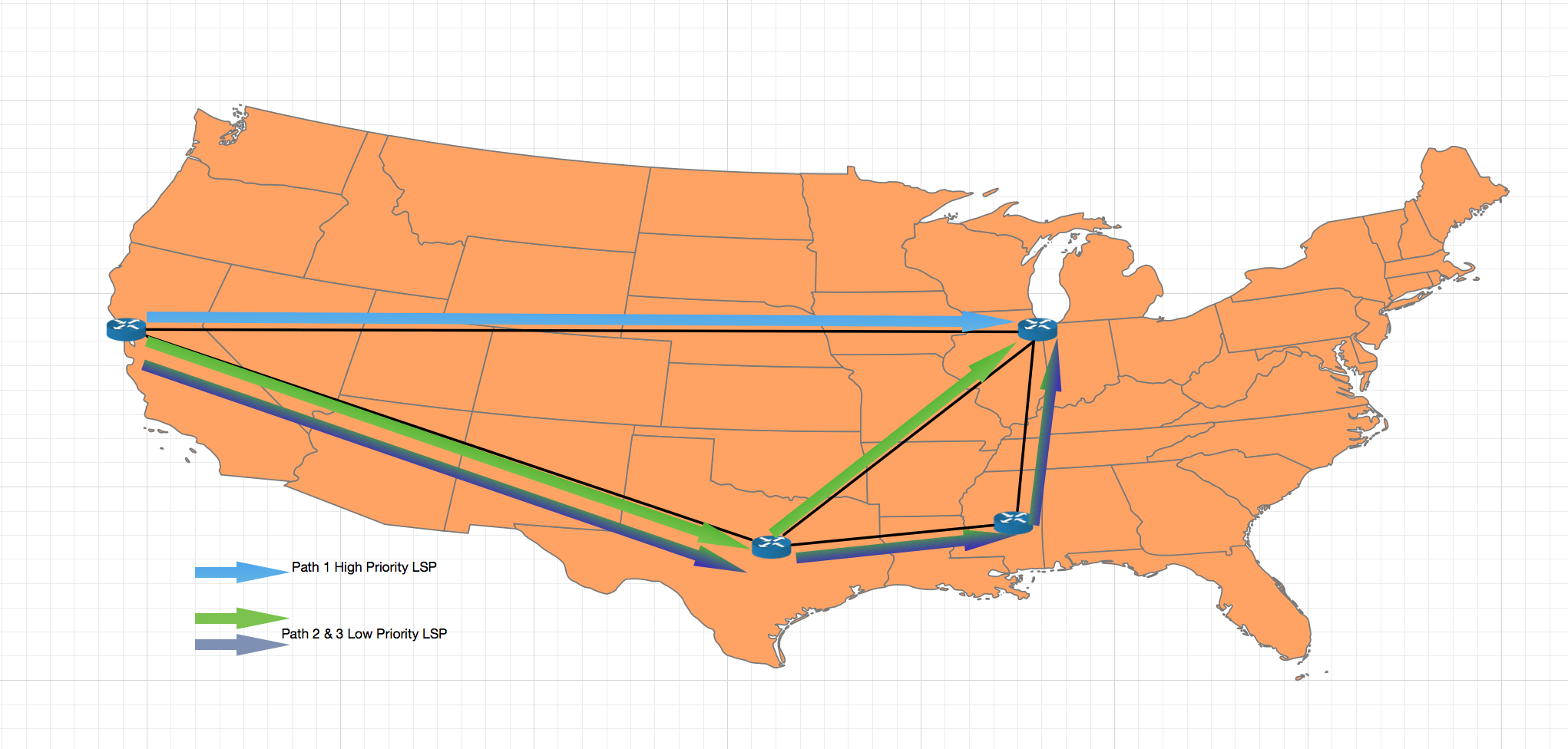
MPLS-TE
In early 2015, we started rolling out MPLS-TE. To meet and exceed customer expectations, our network must handle failures and rapidly respond to demand spikes. To address the challenge of adapting to dynamic changes in bandwidth capacity and demand, we implemented MPLS with RSVP.
MPLS RSVP-TE has a mechanism to react to and adjust for sudden spikes in traffic without manual intervention. When there is sufficient bandwidth available, MPLS ensures traffic will follow the shortest path on the network between its source and destination by establishing a Label Switch Path (LSP) between those points. We deployed multiple LSPs with different priorities: user traffic always takes high-priority LSPs, whereas internal traffic takes low-priority LSPs.
As traffic demand goes up (or network capacity goes down because of an outage) RSVP-TE will move LSPs to alternate higher metric paths which have sufficient bandwidth to handle that demand. Because we deploy multiple LSPs with different priorities, RSVP-TE can leave our user traffic on the shortest route and start by moving less critical internal traffic to the longer paths first as shown in the figure below. This allows the network to have redundancy as well as efficient utilization of our network resources to ensure the required level of service and avoid over-provisioning.
Quality of Service
Quality of service (QoS) is an industry-wide set of standards and mechanisms for ensuring high-quality performance for critical applications. Dropbox’s network carries a mix of latency-sensitive user traffic, and high-volume batch traffic—this includes traffic from data migrations and server provisioning. In 2015, we launched a Quality of Service (QoS) program to identify different traffic types and treat them accordingly, end-to-end. QoS gives us techniques necessary to manage network bandwidth, latency, jitter and packet loss, which helps us guarantee network resources to critical applications during congestion events.
To build out this program, we worked with various application owners within Dropbox to mark their services on host machines based on the priority of their service. We classified all Dropbox traffic into four categories and assigned them into respective queues as shown below:
Network_Control: All routing protocol hellos or keepalive messages are put in this queue. These messages get the highest priority as loss of these packets jeopardizes proper network operation.Premium: All traffic that serves end users. Packets in the premium queue are considered critical to Dropbox users and treated with high priority.Default: Traffic that is not user-impacting but still important for internal services to communicate with each other.Best_Effort: Non-critical Traffic. These packets are usually the first to be dropped under congested network conditions, and can be re-sent at a later point in time.
We make sure we have enough bandwidth to support all traffic types at all times of the day, but we want to protect critical services against unplanned and unexpected network failure events. QoS helps us do that by allowing us to prioritize Premium (user) traffic over other lower-priority traffic.
2016: Year of execution to support 10X scale
2016 was the year we re-architected the network and deployed new hardware to support future scalability.
Types of routers
The Dropbox backbone network consists of routers with three distinct roles:
- Data center routers (DR), with a primary function of connecting the data center to the backbone network
- Backbone routers (BB), which act as a termination point for long-haul circuits and also as an aggregation devices for DRs in regions where we have data centers
- Peering Routers (PR), with a primary function of connecting Dropbox to external BGP peers to provide connectivity to the Internet.
The Dropbox network has two types of traffic: “user traffic,” which flows between Dropbox and the open Internet, and “data center traffic,” which flows between Dropbox data centers. In the old architecture, there was a single network layer, and both traffic types were using the same architecture, passing through the same set of devices.
Old Architecture:
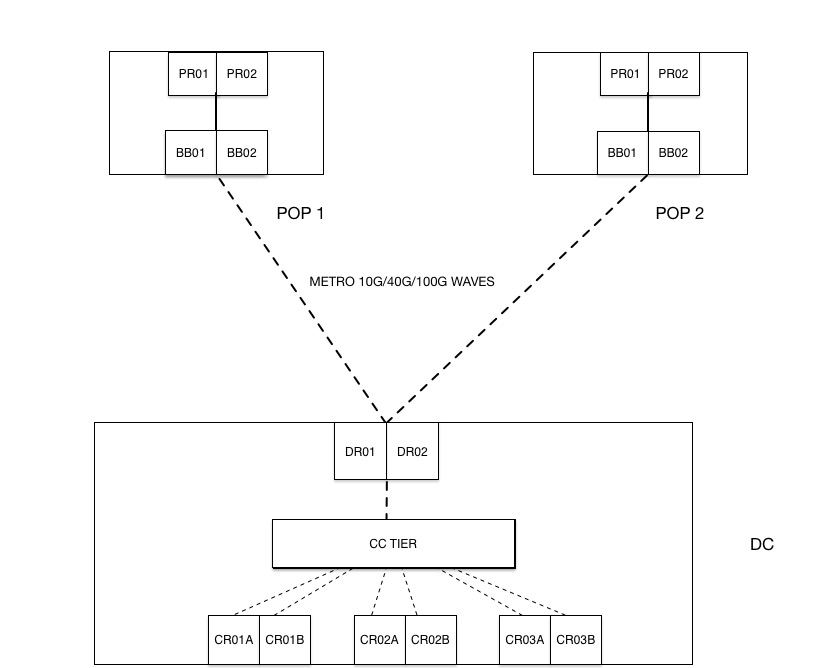
At first, we used the same hardware device for all three roles. But as we began to scale significantly, our existing designs and the platform that we were using reached their limits. We could have continued down the same path by growing horizontally, but that would have been expensive and operationally complex. We instead decided to re-think our architecture, which led to the evolution of our new, two-tier architecture.
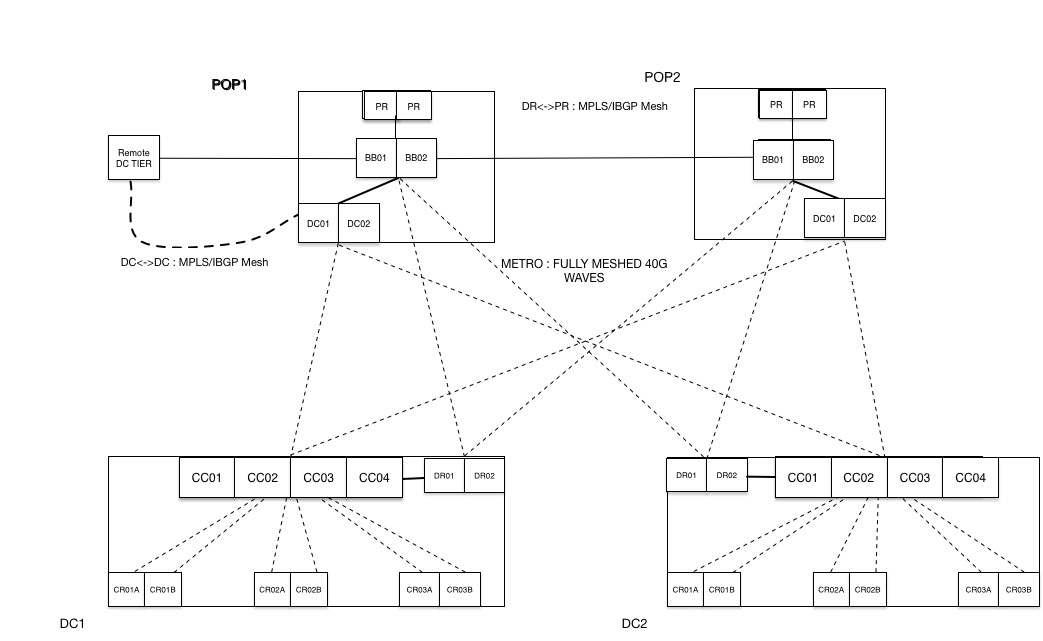
Two-Tier Architecture:
In the new architecture, we created two network domains to handle each type of traffic independently. We also introduced a new set of routers called DCs to connect data centers. The new data center (DC) tier has full mesh MPLS (RSVP) LSPs between them, and is built on a new set of highly dense backbone routers that can easily scale to multi-terabit capacity. The new DC-tier carries the data center traffic, whereas the old DR-tier is used to transport user traffic, primarily from Dropbox to the Internet. Each tier has its own BGP and MPLS LSP mesh, but they connect to the same set of backbone (BB) routers, sharing the same physical transport network.
We have about twice as much data center traffic as user traffic, and both traffic profiles have different characteristics. Data center traffic consists of internal services talking to each other, or copying data from one data center to another. User traffic is always transporting from DRs to a point of presence, and is treated as premium traffic. Peeling off Dropbox internal traffic to its own tier has enabled a clear separation between the two types of traffic, which helps in building traffic profiles and network topologies that are unique to each traffic type.
Optical:
To support the tremendous growth and maintain consistent service level agreements, we invested in dark fiber connecting our data centers to our PoPs. Leasing dark fiber and running our own optical systems gives us the flexibility to add capacity at a much faster pace, compared to purchasing bandwidth or leased line capacity from optical transport vendors. To build on this, we deployed the latest bleeding edge optical gear available, which gives us the ability to scale quickly and easily.
2017: Preparing for future growth
Moving to 100G:
In 2016, we started to qualify a next-generation backbone (BB) router with cutting-edge technology that has the scale and density to support tens of terabits of throughput capacity. We spent about eight months qualifying products from different vendors, and ultimately decided to utilize the latest technology product which could support our requirements. Dropbox was one of the first to qualify and deploy this platform in production infrastructure.
Our initial deployment in the backbone was with 10G circuits. As the traffic on our network increased, we continued to add more 10G links to increase capacity, ultimately combining those 10G links into a single link aggregation bundle (LAG). By early 2016, we had multiple LAG bundles that each had more than ten 10G links each, which added complexity when it came to provisioning, managing and troubleshooting circuits. We decided to simplify our architecture by replacing multiple 10G circuits with 100G.
With the roll-out of new BB routers across our network, we were able to migrate WAN links from multiple 10G LAG bundles to 100G. By June 2017 we migrated all our US and EU WAN links, including our transatlantic links, to 100G. This increased our cumulative WAN capacity by ~300%.
IPv6
In Q4 2016 we started rolling out IPv6 across our entire network. One of our design goals was to have parity between IPv4 and IPv6 for both routing as well as forwarding. As part of this roll-out, and to have consistent routing for both v4 and v6, we chose IS-IS single-topology over multi-topology. For forwarding v6 traffic, we intend to use the same set of MPLS-TE LSPs as we used to tunnel v4 traffic. We could do that by using IGP short-cuts as defined in rfc3906. With the implementation of IGP-shortcuts, both v6 and v4 traffic were using the same MPLS-LSPs across the backbone. By end of Q1 2017 we completed v6 roll-out across our data centers, backbone and edge.


