

More than a billion files are saved to Dropbox every day, and we need to run many asynchronous jobs in response to these events to power various Dropbox features. Examples of these asynchronous jobs include indexing a file to enable search over its contents, generating previews of files to be displayed when the files are viewed on the Dropbox website, and delivering notifications of file changes to third-party apps using the Dropbox developer API. This is where Cape comes in — it’s a framework that enables real-time asynchronous processing of billions of events a day, powering many Dropbox features.
We launched Cape towards the end of 2016 to replace Livefill, which we last talked about in 2014. In this post, we’ll give an overview of Cape and its key features, high-level architecture, and varied use cases at Dropbox.
Requirements
Cape is designed to be a generic framework that enables processing of event streams from varied sources, and allows developers to execute custom business logic in response to these events. There were many requirements we had to satisfy with it:
Low latency
Cape needs to enable processing within sub-second latencies to power content-based collaboration and sharing that increasingly happens in real-time and on-the-go through mobile devices. For example, we’d like a user to be able to search over or view a file that was just added to Dropbox and shared with them.
Multiple event types
Unlike its predecessor Livefill, Cape should generalize to processing different types of events in addition to Dropbox file events. This will enable the Dropbox product to react in real time to events that change non-file metadata, such as sharing a file, changing the permissions on a shared folder, or commenting on a file. Such capabilities have gained increased importance as Dropbox increasingly transforms from a pure file sync solution to a collaboration platform.
Scale
Cape must support the high throughput of tens of thousands of file and non-file events per second. In addition, many different workloads may result from the same event further amplifying the scale that needs to be supported.
Variable workloads
Workloads may vary in duration: from milliseconds, to tens of seconds, to minutes in some cases, based on the type of workload and the event being processed.
Isolation
Cape must provide reasonable isolation between different Cape users’ event processing code, so that an issue with one user’s processing doesn’t have a big adverse impact on all other users of the framework.
At-least-once guarantee
Cape must guarantee that each event is processed at-least-once since this is critical to many use cases for ensuring a correct and consistent product experience.
Data Model
Each event stream in Cape is called a Domain and consists of a particular type of events. Each Cape event has a Subject and a Sequence ID. The Subject is the entity on which an event occurs, the corresponding Subject ID serving as a key to identify the Subject. The Sequence ID is a monotonically increasing ID that provides a strict ordering of events within the scope of a Subject .
There are two specific event sources supported in the first version of Cape that account for many of the important user events at Dropbox — we’ll take a quick detour to understand these sources before moving on.
The first source is SFJ (Server File Journal), which is the metadata database for files in Dropbox. Every change to a file in a user’s Dropbox is associated with a Namespace ID (NSID) and a Journal ID (JID), which together uniquely identify each event in SFJ. The second supported source is Edgestore, which is a metadata store for non-file metadata powering many Dropbox services and products. All changes to a particular Edgestore Entity or Association type can be uniquely identified by a combination of a GID (global id) and a Revision ID.
The following table describes how SFJ and Edgestore events fit into Cape’s event abstraction:
| Source | Domain | Subject ID | Sequence ID |
|---|---|---|---|
| SFJ | SFJ (all SFJ events) | Namespace ID | Journal ID |
| Edgestore | Entity or Association type | GID | Revision ID |
In the future, Cape can support processing custom event streams in addition to SFJ and Edgestore events. For example, events flowing into a Kafka cluster could fit into Cape’s event stream abstraction as follows:
| Source | Domain | Subject ID | Sequence ID |
|---|---|---|---|
| Kafka | A Kafka cluster | {Topic, Partition} | Offset |
Architecture
Shown below is an overview of what Cape looks like:
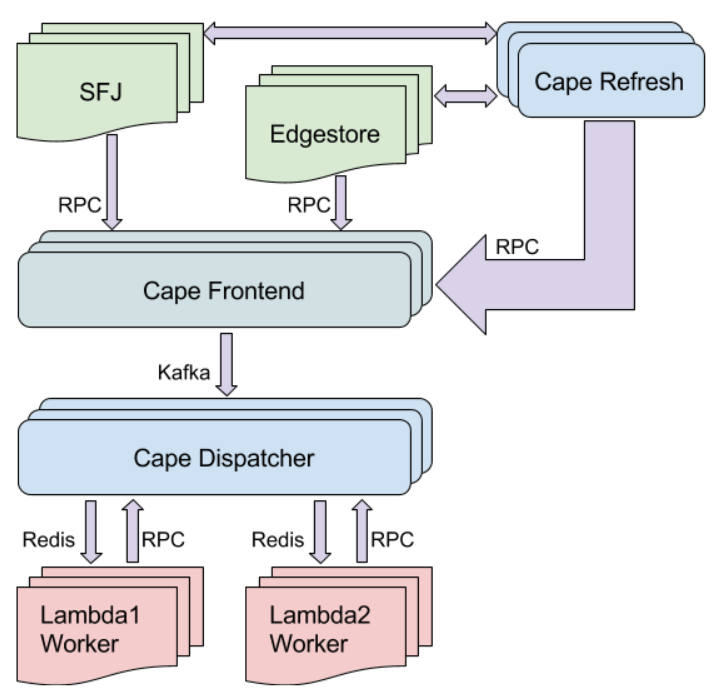
SFJ and Edgestore services send pings to a Cape Frontend via RPCs containing metadata from relevant events as they happen. These pings are not in the critical path for SFJ and Edgestore, and so are sent asynchronously instead. This setup minimizes the availability impact on critical Dropbox services as a whole (when Cape or a service it depends on is experiencing an issue) while enabling real-time processing of events in the normal case. The Cape Frontend publishes these pings to Kafka queues where they are persisted until they are picked up for processing.
The Cape Dispatcher subscribes to the aforementioned Kafka queues to receive event pings and kick off the necessary processing. The Dispatcher contains all the intelligent business logic in Cape and dispatches particular events to the appropriate lambda workers based on how users have configured Cape. In addition, it’s responsible for ensuring other guarantees that Cape provides, notably around ordering between events and dependencies between lambdas.
The Lambda Workers receive events from the Dispatcher via Redis, carry out the users’ business logic, and respond to the Cape Dispatcher with the status of this processing — if the processing is successful, this is the end of the processing for that particular event.
As mentioned earlier, pings from SFJ and Edgestore are sent asynchronously and outside the critical path to the Cape Frontend, which of course means they are not guaranteed to be sent for every event. You may have realized that this makes it seemingly impossible for Cape to provide the guarantee that every event is processed at least once, e.g. it would be possible for a file to be synced to Dropbox but for us to miss all the asynchronous processing that should happen as a result. This is where Cape Refresh comes in — these workers continually scan the SFJ and Edgestore databases for recent events that may have been missed and send the necessary pings to the Cape Frontend to ensure they are processed. Additionally, this serves as a mechanism to detect permanent failures in users’ application code on any of the billions of Subjects processed by Cape.
Using Cape
To integrate with Cape, these are the steps a developer needs to follow:
- Lambda: Write the code that should execute in response to events by implementing a well-defined interface (currently in Python or Go) — this is referred to as a lambda
- Deploy: Deploy Cape workers to accept events and run the newly created lambda using Dropbox’s standard deployment and monitoring tools
- Config: Include in Cape’s config the set of events that should be processed by specifying the Domain, and the Lambda that should run in response to them
After the above steps are followed, the newly deployed Cape workers will receive events related to the relevant lambda, can process these events appropriately, and respond back to the Cape Dispatcher with the status of this processing. Users also have access to automatically generated monitoring dashboards with basic metrics around the event processing being performed by this lambda.
Wrap-up
Cape already processes several billion events a day with 95th-percentile latencies of less than 100 milliseconds and less than 400 milliseconds, respectively, for both SFJ and Edgestore. These latencies are measured from the point when the Cape Frontend receives the event to when event processing starts at the lambda workers. For SFJ, end-to-end latencies (i.e., from when the change is committed to SFJ to when processing starts at the lambda workers) are higher: ~500 milliseconds & 1 second, respectively, due to batching within the SFJ service itself.
Here are just a few examples of how Cape is used at Dropbox today:
- Audit Logs: Cape enables real-time indexing of Dropbox events relevant to audit logs, enabling Dropbox Business admins to search over these logs
- Search: Cape is used for real-time indexing when a file in Dropbox changes, enabling search over a file’s contents
- Developer API: Cape is used to deliver real-time notifications of file changes to third party apps using the Dropbox developer API
- Sharing permissions: Cape is used to perform expensive operations asynchronously, e.g. propagating permissions changes across a large or deep hierarchy of shared folders
Given how generic the framework is and its support for the majority of Dropbox’s important events, we expect Cape to underpin many of Dropbox’s features in the future.
The architecture overview we’ve included in this post obviously leaves out discussion of many details and design decisions. In future posts, we’ll dive deeper into further technical details of Cape and specific aspects of its architecture, design, and implementation.
Thanks to the folks that helped build Cape: Bashar Al-Rawi, Daisy Zhou, Iulia Tamas, Jacob Reiff, Peng Kang, Rajiv Desai, and Sarah Tappon.


