

Metadata is crucial for serving user requests. It also takes up a lot of space—and as we’ve grown, so has the amount of metadata we’ve had to store. This isn’t a bad problem to have, but we knew it was only a matter of time before our metadata stack would need an overhaul.
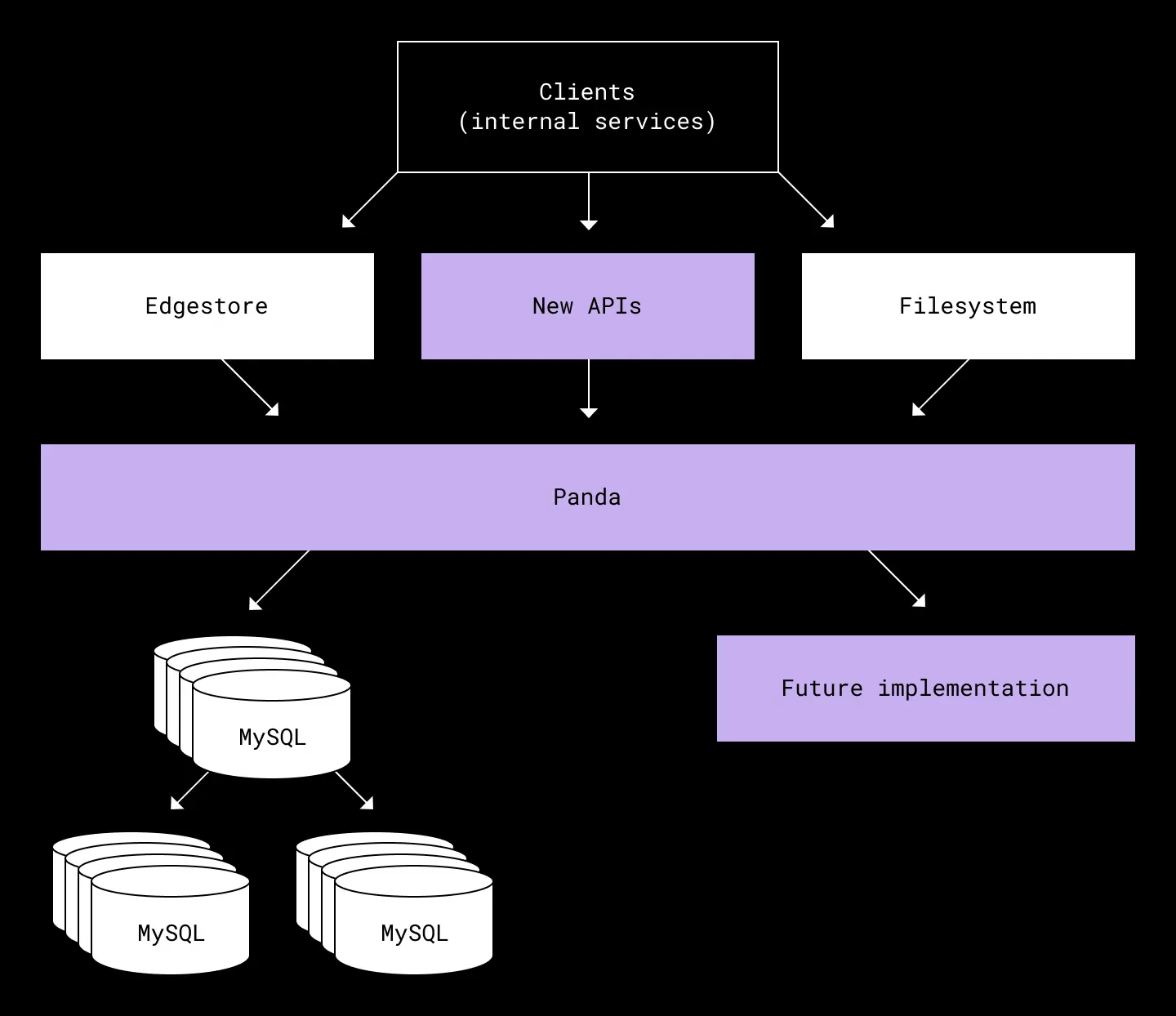
Dropbox operates two large-scale metadata storage systems powered by sharded MySQL. One is the Filesystem which contains metadata related to files and folders. The other is Edgestore, which powers all other internal and external Dropbox services. Both operate at a massive scale. They run on thousands of servers, store petabytes of data on SSDs, and serve tens of millions of queries per second with single-digit millisecond latency.
A few years ago, however, we realized we would soon need a more cost-effective and performant way to keep up with Edgestore’s growth. Edgestore was originally built directly on sharded MySQL, with each of our storage servers holding multiple database shards. Data within Edgestore was evenly distributed, so that most of the disks reached capacity around the same time. When it came time to expand, we split each machine in two, with each holding half of the shards. But by 2019, with another split of Edgestore looming, it was clear this strategy would come with a significant cost. We also faced a looming crisis: that an outlier shard could outgrow the capacity of a single machine, and we would have no way to split that shard.
We decided it was time to rethink the storage layer for our metadata stack. Critically, we wanted a solution that would allow us to expand our storage capacity incrementally, based on our projected growth, instead of simply doubling our fleet of machines. We also wanted the ability to rebalance where data was stored, in case some shards grew faster than others.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Our solution was to introduce a new layer to our metadata stack, a petabyte-scale transactional key-value store we call Panda, which sits between Edgestore and our sharded MySQL. Panda abstracts MySQL shards, supports ACID transactions, enables incremental capacity expansion, and unifies the implementations of complicated features used by multiple backends within Dropbox.
In our new metadata stack, the bottom layer (Panda) is responsible for redundantly storing data, rebalancing data, and enabling distributed transactions. The upper layer provides higher-level features such as indexes, schema, and strongly consistent caching. The well-defined abstraction boundary allows us to separate application and storage concerns. The team working on the application layer—where Edgestore sits—can focus on improving the existing API and providing additional features. Meanwhile, the team responsible for Panda can independently iterate on the storage layer.
Abstraction to the rescue
One advantage of this approach is that we can implement features in Panda independent of the underlying storage engine—such as data rebalancing and two-phase commit, neither of which are inherent to sharded MySQL. This means we can even migrate metadata back and forth between entirely different storage engine implementations if we choose.
Panda also enables us to reduce complexity in the application layer. For a number of historical reasons, Edgestore and the Filesystem have traditionally had separate backends. But with Panda we can eventually unify the two. Finally, a single two-phase commit implementation!
Overall, this new, layered architecture has enabled us to tackle our near-term problems head-on while also future proofing our metadata stack. In this post, we’ll discuss how Panda works, why we built it, the open source solutions we considered first, and some of the interesting design choices we made along the way.
Looking at open source options
Over the last few years, we've had great success replacing our custom infrastructure with industry-standard open source solutions, such as gRPC, Envoy, and Kubernetes. Had the time finally come for us to replace our in-house databases, too? The possibility of adapting an infinitely scalable NoSQL or NewSQL database was compelling, so before making any major investment in our metadata stack we decided to look at the available open source solutions. Any solution would need to scale to multiple petabytes of data, support data rebalancing, include transactions out of the box, and offer a high rate of linearized reads at low latency.
FoundationDB
FoundationDB is an open-source transactional key-value store. It is maintained by Apple, and is an excellent system. But after a thorough investigation, our team concluded that FoundationDB wouldn’t work at the scale we need without significant changes.
A single instance of FoundationDB is tested and tuned to work with up to 500 storage processes. Each process is single-threaded, which means we could only run FoundationDB on up to 500 processor cores. Unfortunately, our Edgestore and Filesystem clusters have more than 10,000 cores each. Scaling the number of storage processes in FoundationDB would be far from trivial.
Another scaling issue lies with FoundationDB’s centralized timestamp oracle, which is responsible for generating timestamps for all transactions and linearizable reads. Like all similar systems, FoundationDB uses batching to scale the timestamp oracle—but only to a point. In practice, we found there was a hard limit on the number of latest read requests FoundationDB could serve, no matter how much hardware we threw at the problem.
We also concluded FoundationDB’s choices around handling machine failures were not suitable for Dropbox's high availability SLA. One or more machine failures should result in a transient proportional availability hit. However, In FoundationDB, a failure of any node in the transactional system will result in 0% availability until reconfiguration—a serious issue we’d be certain to encounter, given how inherently difficult failure detection can be.
Vitess
Vitess is a database clustering system for horizontal scaling of MySQL. It was initially developed at YouTube and later open sourced by Google, before it was replaced by Spanner. Unlike other databases we looked at, it has been proven to work at a massive scale. Vitess is an excellent option if your app is written using SQL, and can tolerate stale results. Neither of these apply to Dropbox, however, as both Edgestore and the Filesystem do not expose SQL, and require the most current data.
Vitess does not support ACID cross-shard transactions. It has only implemented two-phase commit as an experimental feature. Its documentation states it is not production-ready. In addition, the implementation does not guarantee isolation (in the ACID sense) and makes a strong claim that it can’t be done efficiently. Providing ACID isolation requires either the use of read-locks or storing multiple versions. Using read-locks is indeed contentious and costly, which is why most systems that provide ACID transactions use multi-version concurrency control. Vitess does not consider the multi-version option since this is hard to implement in their architecture.
One of the fundamental design choices in Vitess is that it embraces relaxed consistency. Stale reads make a lot of sense if you are building YouTube, but not if you are building a file system. The vast majority of reads in Edgetore expect to be strongly consistent, or linearizable—meaning a read expects to see the result of all writes that have completed before the read has begun. There are several features of Vitess that result in stale results, such as the resharding process, which switches reads before writes.
While Vitess is a great option, it has different trade-offs compared to what we have already provided to Dropbox engineers. Walking back those guarantees was not viable.
CockroachDB
CockroachDB is the most mature of the NewSQL databases. While it is currently focused on smaller deployments compared to Dropbox, its architecture is quite promising. Unfortunately, there were several soft and hard blockers that prevented us from adopting CockroachDB at the time.
One hard blocker was that CockroachDB does not support Dropbox's current replication model. Dropbox uses MySQL semi-sync replication to replicate between two regions located thousands of miles (or 80ms) apart. The asynchronous model allows us to serve reads and writes with single digit millisecond latency while being resilient to natural disasters that could wipe out a whole region. The downside is that in the case of an abrupt region outage, we will lose the writes that didn’t replicate to the other region. CockroachDB, on the other hand, uses a quorum replication model which can survive region outages without data loss—but with an inter-region latency cost of 80ms for all writes. Dropbox may eventually adopt this model, but it would still take years to build out new data centers and change our operating model if such a decision were ever made.
Another issue was that Dropbox operates at a scale more than an order of magnitude larger than the the scale at which CockroachDB operated at the time, to the best of our knowledge. CockroachDB has solid architecture, and everything is designed to scale, so we didn’t anticipate as many architectural issues as with FoundationDB. However, we couldn’t commit to a system unless we knew it was tested and run at our desired scale on a regular basis, since subtle implementation bottlenecks can often appear with a significant increase in the scale of operation.
Memory was one potential constraint. When we first played with CockroachDB, its default table range size was 64 MB. For a 2 PB data set, this is more than 30 million ranges to manage, or roughly 60 GB needed to keep all ranges in memory. While the default range size is configurable, there were still a number of concerns that made using larger values impractical. In more recent versions of CockroachDB, the default value increased to 512 MB, so they are definitely trending in the right direction.
CockroachDB has a promising company trajectory and solid architecture. It is a solution that we could potentially adopt 5-10 years down the line as they keep scaling up the size of their deployments and remove some of the hard blockers that currently prevent us from using it. But it was clear that CockroachDB wasn’t ready for us yet.
Introducing Panda

Taking destiny into our own hands. “Panda & Theseus” (2022) by Chia-Ni Wu is licensed under CC BY 4.0
With the next database splits looming, we needed to solve our problems fast. At the same time, we wanted to future-proof our metadata stack. Panda was the result.
Panda is a distributed, ordered key-value store. It transparently splits the key space into ranges and distributes ranges among storage nodes. It uses a two-phase commit and hybrid-logical clocks—or monotonic versions that relate to real time—to provide global ACID transactions. In addition to storing key-value pairs, Panda keeps a history of timestamped versions for each key, allowing consistent snapshots at a given point in time. You can think of Panda as a hierarchy of sorted maps organized into databases and tables like a traditional relational database: database :: table :: (key, timestamp) -> value
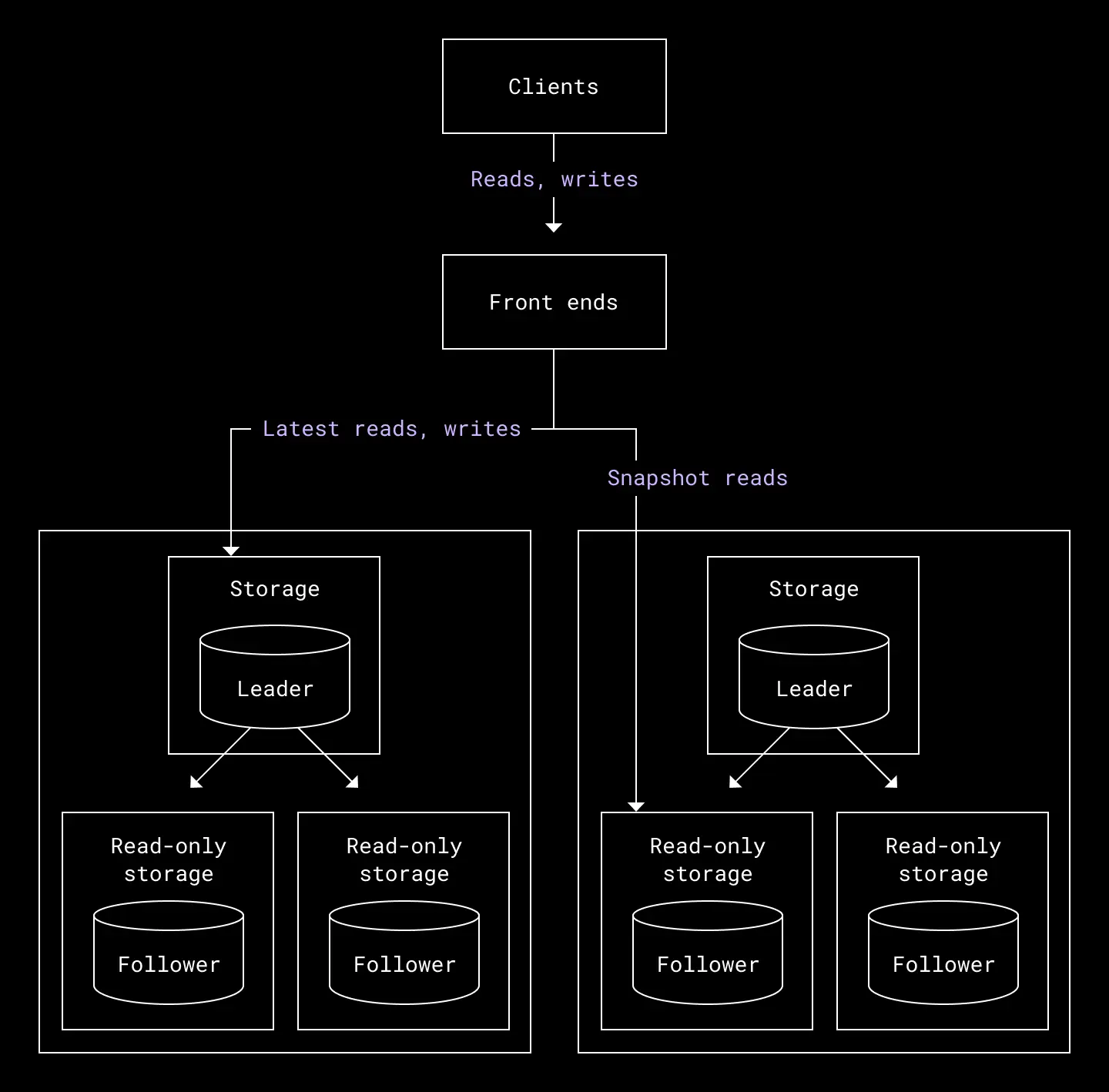
Panda’s data plane serves read and write requests, and has two types of nodes:
- Front end nodes are the entry point to the system. They are responsible for routing requests to the appropriate storage nodes and act as the coordinator for two-phase commits, which is the protocol we use to ensure writes to multiple storage nodes are ACID compliant. Panda exposes a minimal, yet powerful API which can be used to build abstractions like Edgestore and the Filesystem.
- Storage nodes expose a lower level API, including methods for implementing two-phase commit. They are responsible for interfacing with the storage engine—in our case, MySQL—to actually serve reads and writes. Read-only storage nodes are used to serve reads once a snapshot is chosen. Storage nodes also implement multi-version concurrency control (MVCC) over the storage engine in order to serve non-blocking reads and point-in-time queries. Storage nodes do not talk to each other on the data path and instead bubble up any observed pending writes to the front ends to resolve. This makes it easier to find the root cause of latency issues due to slow or overloaded storage nodes by using standard observability tooling.
The architecture of Panda’s data plane
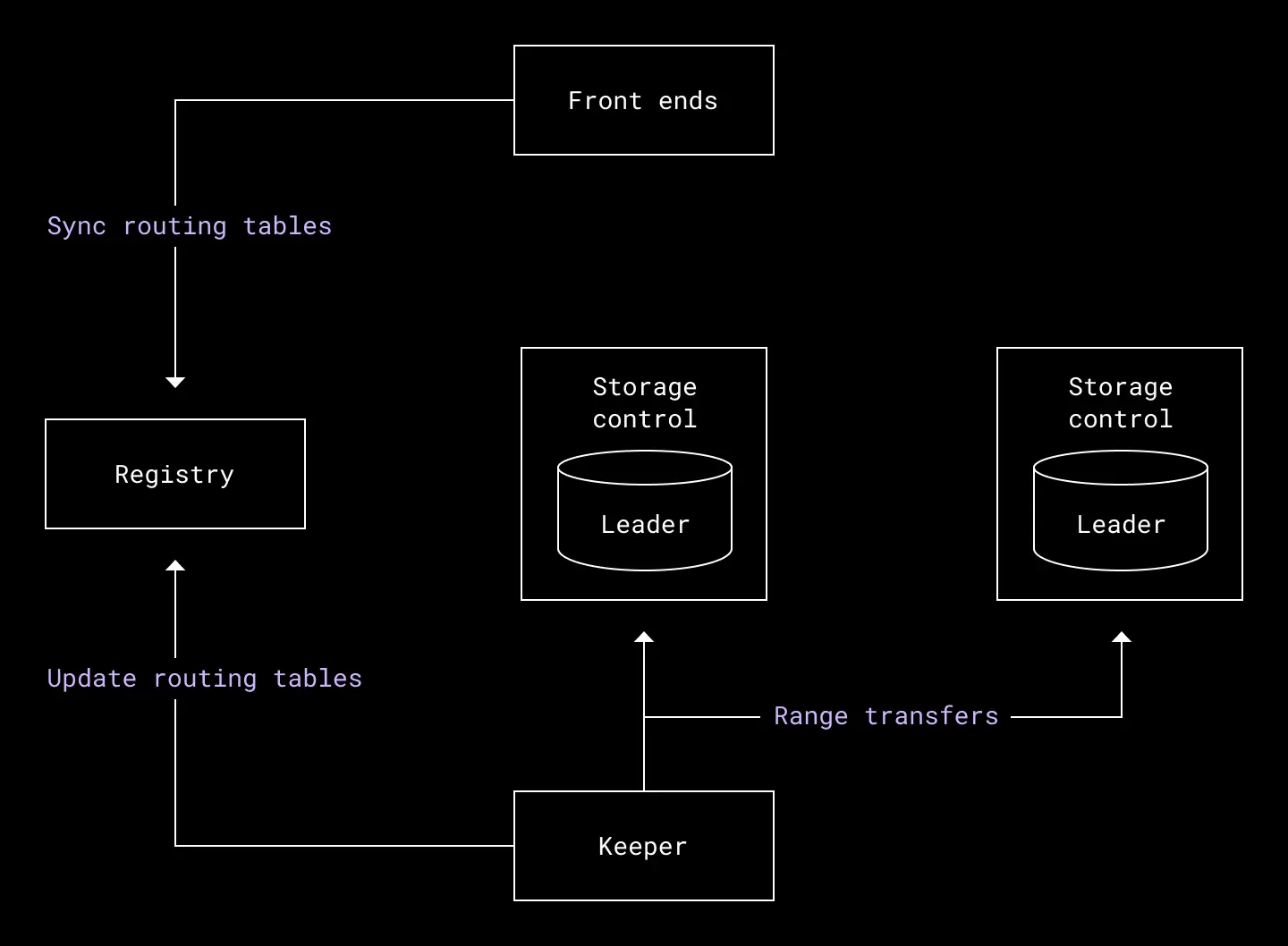
The control plane, meanwhile, manages Panda’s internal system processes, and is made up of the following subsystems:
- Storage control. This subsystem is colocated with each storage node. It exposes low level methods for implementing range transfers, where multiple storage nodes exchange ownership of a range of data.
- Registry. This subsystem is the source of truth for range metadata in the system. The registry keeps track of which ranges belong to a given storage node. The registry also ensures that data is never lost during a range transfer by ensuring that each range state transition maintains invariants—including mutual exclusion for writes—and that the entire key space is covered by existing ranges. Front end nodes consult the registry to get the latest range/storage mapping in order to route requests.
- Keeper. This subsystem is the janitor of the system. It keeps everything running smoothly by performing important maintenance tasks. Its primary function is to coordinate and run range transfers to rebalance data, but it also validates system metadata properties such as range placement on storage nodes.
The architecture of Panda’s control plane
Next we'll describe how Dropboxers can use Panda to build their products, the decision to use multi-version concurrency control, what we can do with range transfers, and our approach to testing and verification.
Designing the API
Panda was created so that Dropbox engineers can build feature-rich, scalable metadata storage systems. To achieve the scale and performance we need, Panda’s API is intentionally minimalistic. We provide a reliable and predictable building block which can be used to create the higher level abstractions needed to build Dropbox products. At a very high-level, Panda supports the following operations:
type Panda interface {
// If all Preconditions hold, atomically commits all KeyValue pairs at
// the returned timestamp.
Write([]KeyValue, []Precondition) (Timestamp, error)
// Establishing latest (linearizable) snapshot.
LatestTimestamp(Key) (Timestamp, error)
LatestTimestampForRange(KeyRange) (Timestamp, error)
// Snapshot read operations.
Get(Timestamp, Key) (Record, error)
Scan(Timestamp, KeyRange) ([]Record, error)
}This is a simplified version for the sake of clarity. The actual API has slightly more clutter, including batching, and the ability to perform a linearized read in a single request
One infrastructure principle at Dropbox is that if a developer writes a bad query that takes down the database, this is the database's fault, not the developer's fault. We have found this to be the only sustainable way to operate metadata storage systems with a large variety of workloads at Dropbox scale. Living up to this principle requires a carefully curated API designed with multi-tenancy in mind. Some of Panda’s most important tradeoffs and design choices are:
- Predictability. Panda doesn’t have any higher level read operations like joins or chained reads. While this pushes some complexity to Dropbox developers, it means that Panda can easily model the cost of an operation and gracefully reject traffic it knows won’t succeed. The system performance doesn’t degrade sharply after some load inflection point. Batch jobs are throttled to give priority to serving live site traffic. No single use case is allowed to exhaust all system resources. Writing reliable systems is much easier when you can predict the behavior of your dependencies.
- Partial results. All read APIs in Panda can return fewer results than the request specified. This enables Panda to always make incremental progress instead of timing out or running out of memory while trying to serve a giant request. This solves a very real problem at Dropbox where hot regions of data can lead to requests that consistently time out and a whole process can grind to a halt.
- Optimistic concurrency control. Panda does not expose key locks. Instead, developers must leverage preconditions to ensure no conflicting writes happened after their transaction started. This approach has disadvantages, including being less ergonomic, but it means that a Panda user can’t hold resources indefinitely and gum up transaction processing for other users. The result is a more reliable API with predictable performance which is critical in a multi-tenant system.
- Data distribution. The only way developers can influence data distribution in Panda is by carefully designing their keys. Developers are encouraged to structure their keys so that objects that are queried or transacted together are closer in the key space. The placement increases the probability of queries only touching a single storage node, which reduces write overhead, lowers tail read latencies and improves availability. There is no behavior changes regarding whether keys are placed on the same node or not. Developers can still read and write the keys atomically. This gives developers enough flexibility to build systems over Panda with high performance and availability while allowing Panda to fully manage the placement of data.
Multi-version concurrency control
Multi-version concurrency control (MVCC) was an essential design choice for Panda. MVCC has enabled a couple of features that will allow easier operation for internal developers—and ultimately better reliability for end users, too.
The first is implementing ACID transactions without read-locks. Reads account for more than 95% of Edgestore and Filesystem workloads, so optimizing for non-blocking reads considerably improves our ability to scale.
The second is enabling snapshot reads at older timestamps. This allows us to serve reads on all nodes in the system—not just the ones accepting writes. A standard replication topology includes one leader accepting writes and the latest reads, and two or more followers replicating the data. Utilizing this follower capacity is crucial for increasing system throughput and fully utilizing available hardware. In practice, many Dropbox routes will follow a pattern of establishing a timestamp using the latest read and then doing many subsequent reads at that timestamp (Panda will try to give an older timestamp if there were no recent writes). In most cases, those subsequent reads can leverage the followers.
There are two downsides to using MVCC. The first is write amplification. All operations, including deletes, become row inserts. However, this overhead is acceptable for Edgestore and Filesystem due to the high read/write ratio.
The second downside is the cost of garbage collection. Obviously, we can’t keep all versions of all keys in perpetuity, or we’ll run out of space quite quickly. Depending on the key structure, a more subtle issue with having older versions is scan performance. If the data has a long retention period or the cleanup is not quick enough, hot keys can turn into dense key ranges that can be expensive to churn through in scans—an issue we experienced firsthand. We optimized our garbage collection by keeping a queue of keys and timestamps eligible to be vacuumed and processing it in strict order.
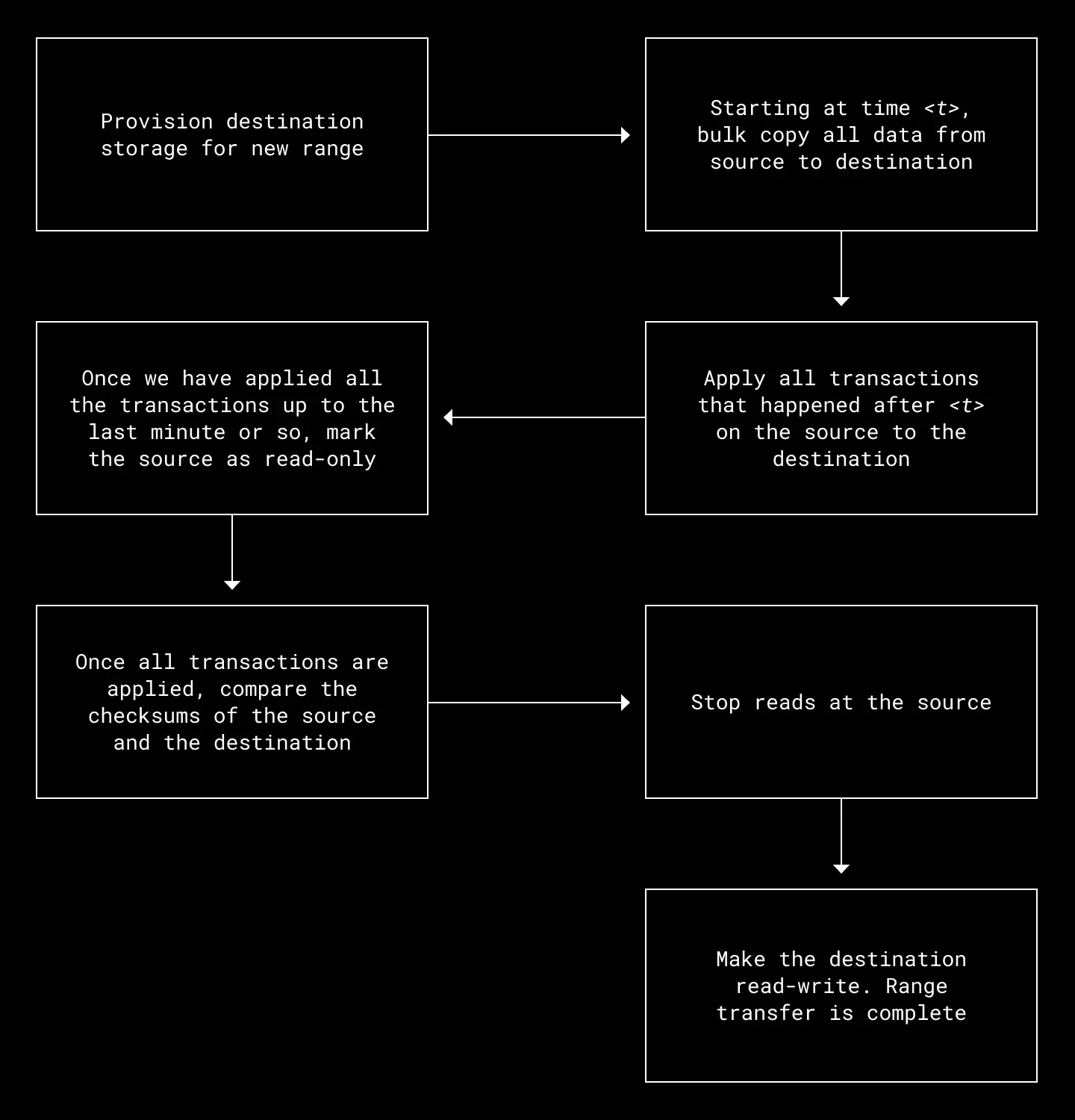
Range transfers
Panda splits the key space into ranges and places them onto storage nodes. Ranges for Edgestore and Filesystem are about 100 GB, which gives us the right balance between avoiding unnecessary multi-storage operations while still being able to rearrange quickly enough when needed.
Panda’s range transfer protocol
The steps here are carefully designed to keep the critical section of a transfer, where the range is unavailable or read-only, to a minimum. In practice, we have used these transfers for ranges with hundreds of gigabytes of data with only seconds of unavailability. The same protocol can be used to implement range merges and range splits which gives us full control over the data distribution in the system.
Range transfers are a powerful feature. They allow Panda to effectively federate key-value storages. Some applications of this feature include:
- Data rebalancing and incremental capacity expansion. No more splits! If the amount of data stored grows by 5%, we need 5% more hardware. We can also easily consolidate the data and shrink the fleet.
- Migrating back and forth between different versions. That capability is essential since, starting in MySQL 8, version upgrades are one way only. That change makes version upgrades significantly riskier. Dropbox operates one of the largest fleets of MySQL with a very high standard for correctness, so we are often among the first ones to hit MySQL correctness bugs or performance issues in production. We sometimes hit such issues after days or weeks when we have rolled out half the fleet. Having no ability to rollback is scary. Thankfully, range transfers always allow us to go back, no matter what upgrade policy MySQL adopts.
- Storage can also be a completely different implementation leveraging different storage engines or replication. We have a pilot storage implementation that uses RocksDB for the storage engine and /etcd/raft for replication. We leverage range transfers to go back and forth between MySQL and RocksDB. That is one potential evolution of Panda, in case there is still no well-established open-source alternative that can satisfy the Panda API and work at Dropbox scale.
Randomized testing and verification
Dropbox stores users’ most important data, so it’s critical that our metadata layer has strong guarantees around durability and consistency. To that end, we have made heavy investments into testing Panda.
After standard unit and integration tests, our next line of defense is what we call simulation testing. We run a production-like workload for several hours in a test environment. In the background, we introduce faults and run background jobs like range transfers and MVCC garbage collection. Meanwhile, verifiers check that Panda invariants are upheld: snapshots are repeatable, latest reads are linearizable, etc. When all these components come together, we stress the boundary conditions of Panda and have found tens of bugs, including deadlocks, range transfer data corruptions, swallowed errors, MySQL bugs, and more! Once the test wraps up, we double-check that we had a reasonable number of successful requests and range transfers because a silly but common failure mode is a simulation test that does no work and trivially has no bugs.
When a new version of Panda reaches production, we continue to verify the data by validating a random sample of real user traffic, checking the same invariants that we do in the simulation. We’ve found it to be really valuable to continue to verify traffic once in production. Certain bugs only surface with real production workloads or happen so infrequently that they require the scale of production deployments.
We also have other verifiers checking that internal Panda metadata, such as range placement, stays consistent and up-to-date. If a bug ever reaches production, we want to find and fix it before others within Dropbox even notice.
What we learned
Panda was a very large project, and a core part of Dropbox’s multi-year strategy to revamp its metadata stack. This forced us to make technical decisions that will allow us to iterate and deliver incremental value without knowing the end state in advance. Here’s some of what we learned:
- Everything has a trade off. Building a distributed system is a series of design choices. For example, MVCC has many benefits but also comes with a higher write overhead and might not be the optimal choice for all systems. Introducing abstraction lets you decouple the system and improve each layer independently, but the well-defined boundary might sometimes prevent you from implementing specific optimizations. There is no one correct answer. You should understand the trade-offs of each option and make decisions based on their specific requirements.
- Provide the weakest guarantee that works. In couple of instances during the development of Panda, we defined our APIs with stricter constraints on the results than necessary. For example, when designing Panda’s Change Data Capture API, we decided to always deliver all updates for a single key in order, even in the event of range transfers. While we have potential future use cases, none of the initial Panda users relied on that behavior. That strong guarantee made the API harder to build and use, and ultimately slowed us down. Instead, we should have started with a weaker guarantee, delivered Panda, and improved later if needed. This principle also led us to delivering partial results from our read APIs. You can always go from a weaker guarantee to a stronger one, but not the other way around.
- Run a production workload as early as possible. When we first started shadowing production requests to Panda, we found several performance bottlenecks resulting from incorrect assumptions we made about the workload. In retrospect, we should have built an MVP and shadowed Edgestore’s requests earlier in the project. This would have helped reveal unknown unknowns early and saved time in optimizing implementation details that didn’t matter in practice.
- Randomized testing is a game changer. Building a good randomized testing infrastructure requires large up-front investments. But in our experience, it is worth it. It has paid for itself multiple times over, and we don’t believe shipping and sustaining Panda would have been possible without it. If you are building a system where correctness matters, invest in randomized testing.
- You won’t have all the answers up front. We don’t know what the future backend of Panda will be yet, and depending on the answer, we might not have taken the shortest possible path to get there. Large project execution isn’t always a straight-line endeavor. A sound multi-year technical strategy should deliver incremental value and have the flexibility to course correct based on lessons learned and potentially evolving business needs.
With Panda, the ability to expand our storage capacity incrementally is not only more cost effective, but a big improvement in functionality over our sharded MySQL stack. Careful design choices will help us reliably operate Panda as Dropbox continues to grow and develop new, metadata-rich products. And with this abstraction layer in place, the metadata teams can focus on making improvements to the storage layer underneath, resulting in cost wins for the business and performance wins for Dropbox users!
Also: we’re hiring!
Does building innovative products, experiences, and infrastructure like Panda excite you? Come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.
~ ~ ~
A project of this magnitude doesn’t come together without the help of many incredible Dropboxers. A special shoutout to alumnus Braden Walker who was the inspiration and kickstarted the effort. We’d also like to congratulate and thank the following Metadata team members for their contributions: Adam Dorwart, Angela Chan, Bisheng Huang, Chris Lacasse, Ganesh Rapolu, James Cowling, Jose Rodriguez Salinas, Leslie Tu, Lihao He, Matt Rozak, Mehant Baid, Olivier Paugam, Pavan Kulkarni, Preslav Le, Rick Yin, Robert Escriva, Samantha Steele, Shicheng Zhou, Tanay Lathia, William Ehlhardt, Yang Lim, Yu-Wun Wang, Yuyang Guo, Yves Perrenoud, Zhangfan Dong, Zhe Wang.
We also want thank all the Metadata alumni for their invaluable contributions to this project!
Finally, we want to recognize the contributions from our partner teams: Capacity, Supply Chain, Fleet Management, Percona, Filesystem, Hardware Engineering, Reliability, Orchestration, and the Application teams that supported us and helped us move this forward.


