

On Thursday, November 18, 2021, Dropbox did not go down. On a normal day this would be a non-event—a sign that everything was operating as usual. However, this day was anything but usual. At 5:00 pm PT, a group of Dropboxers were huddled on a Zoom call when the command was given to physically unplug our San Jose data center from the rest of the Dropbox network.
This was a big deal—the culmination of more than a year’s worth of work for the Disaster Readiness (DR) team, and more than six years of work across Dropbox as a whole.
In a world where natural disasters are more and more prevalent, it’s important that we consider the potential impact of such events on our data centers. A core Dropbox value is being worthy of our customer’s trust. From a disaster readiness perspective, this means ensuring we not only measure risks to our physical locations, but also implement strategies to mitigate such risks.
After we migrated from AWS in 2015, Dropbox was highly centralized in San Jose. While user metadata has been replicated across other regions for many years, the reality was that San Jose was where most of our services originated and matured. Given San Jose's proximity to the the San Andreas Fault, it was critical we ensured an earthquake wouldn't take Dropbox offline.
One way of communicating our preparedness to our customers is through a metric called Recovery Time Objective (RTO). RTO measures the amount of time we promise it will take to recover from a catastrophic event. Over the years, there have been several workstreams aimed at continually reducing our estimated RTO in preparation for all kinds of potential disasters—earthquakes included.
Due to a large cross-functional effort led by the DR team in 2020 and 2021—culminating in the literal unplugging of our San Jose data center—Dropbox was able to reduce its RTO by more than an order of magnitude. This is the story of how we did it.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
In the beginning there was Magic Pocket
In order to better appreciate the challenges associated with achieving a significant reduction in our RTO, it’s important to understand how the architecture of Dropbox was designed.
Dropbox has two core serving stacks: one for block (file) data, and one for metadata. As many avid Dropbox tech blog readers may be aware, Magic Pocket is our solution for block storage, and was designed with a multi-homed approach to reliability. When a service is multi-homed, it means that, by design, the service can be run from more than one data center.
Magic Pocket is also what we call an active-active system. This means, in addition to being multi-homed, it was designed to serve block data from multiple data centers independently at the same time. Its design includes built-in replication and redundancies to ensure a region failure is minimally disruptive to our business. This type of architecture is resilient in disaster scenarios because, from the user’s perspective, it is able to transparently withstand the loss of a data center. After Magic Pocket was implemented, Dropbox embarked on a three-phase plan to make the metadata stack more resilient, with a goal of eventually achieving an active-active architecture here, too.
The first phase of this project was to achieve an active-passive architecture. This meant making the necessary changes to enable us to move metadata from our current active metro—our San Jose data center (SJC)—to another passive metro. This process is called a failover.
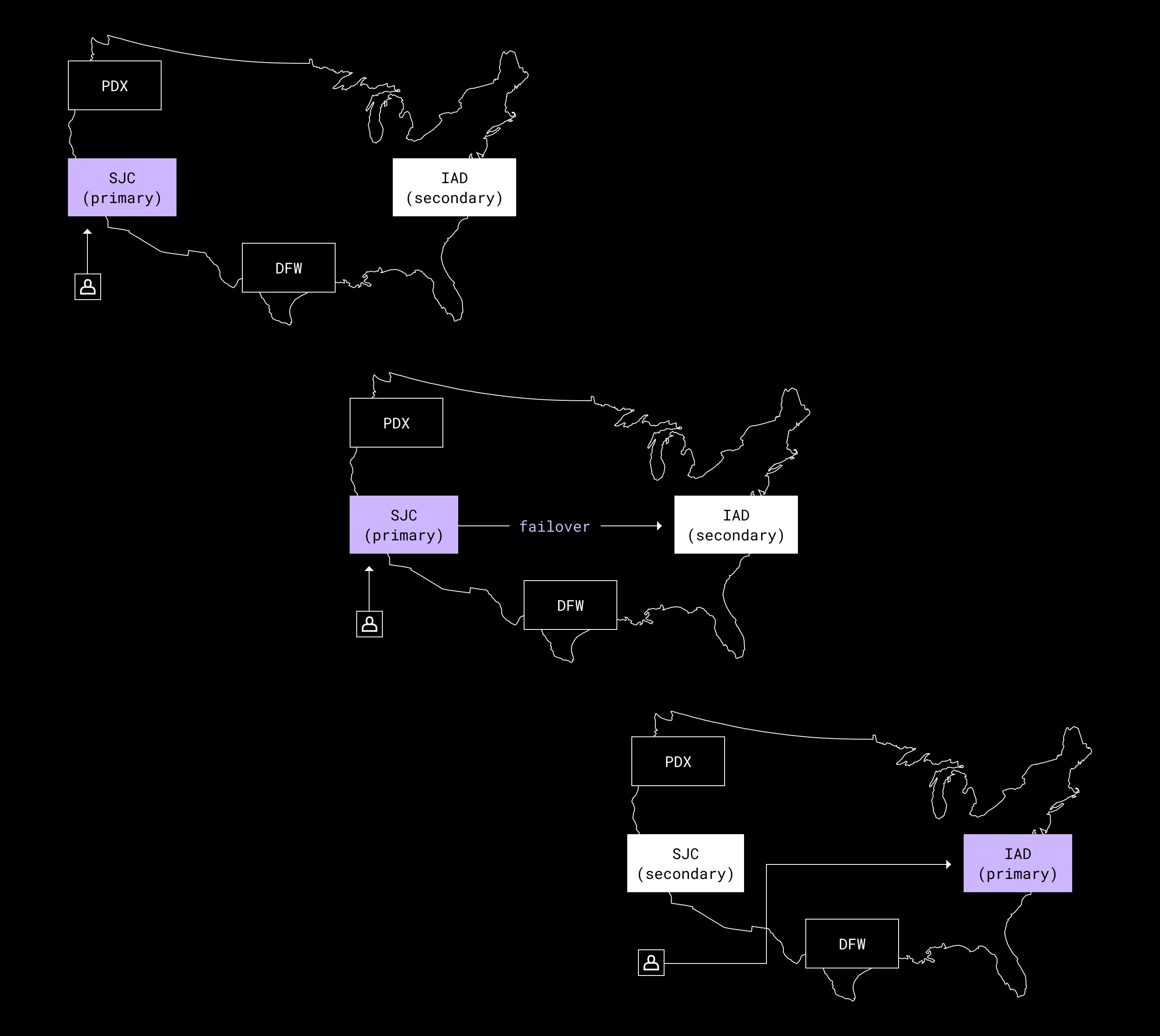
Our first failover was successfully performed in 2015, and was intended as a one-off exercise on the way to our eventual goal. But as we began to work towards an active-active architecture for our metadata stack—enabling us to serve user metadata from multiple data centers independently—we started to realize how difficult achieving this goal would be.
Metadata complicates things
The metadata stack is built on top of two large, sharded MySQL deployments. One is for general metadata using our in-house database Edgestore, and the other for filesystem metadata. Each shard in a cluster is allocated to six physical machines: one primary and two replicas in each of our core regions.
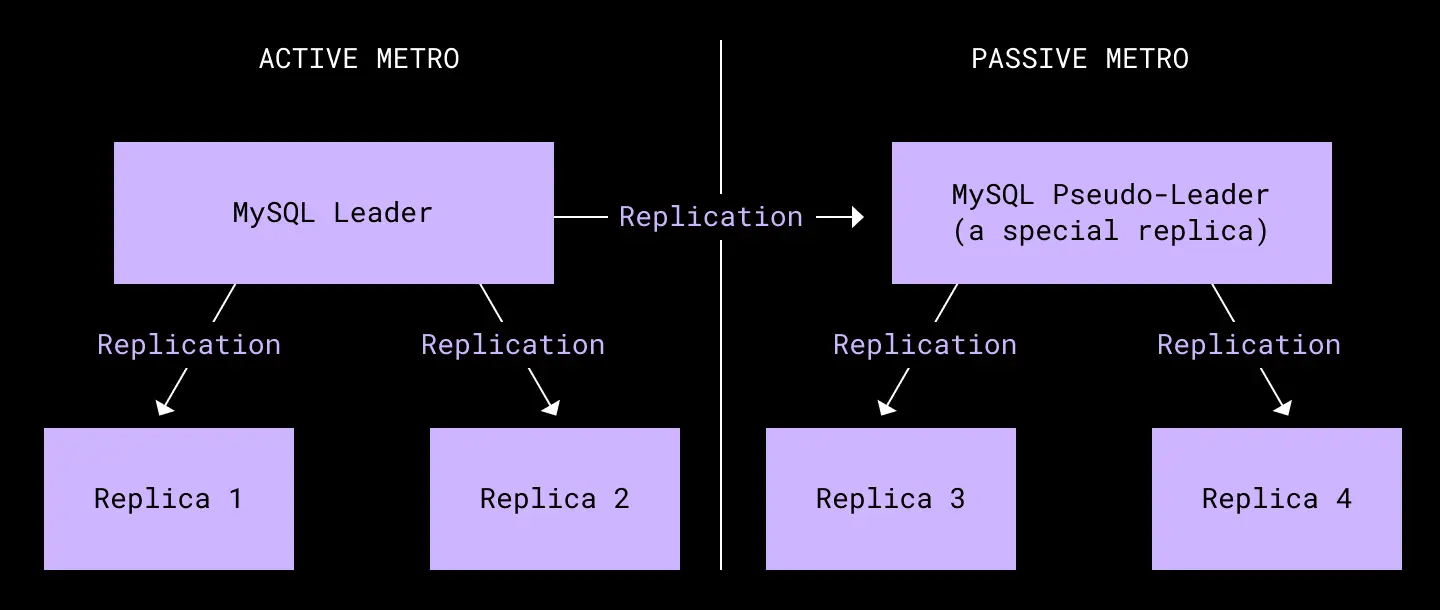
There are two core trade-offs at the MySQL layer—and complexities with how we model data in Edgestore—that forced a rethink of our disaster readiness plans.
The first MySQL trade-off is with how we handle replication. We use semisynchronous replication to balance data integrity and write latency. However, because of that choice, replication between regions is asynchronous—meaning the remote replicas are always some number of transactions behind the primary region. This replication lag makes it very hard to handle a sudden and complete failure of the primary region. Given this context, we structured our RTO—and more broadly, our disaster readiness plans—around imminent failures where our primary region is still up, but may not be for long. We felt comfortable with this trade-off because our data centers have many redundant power and networking systems that are frequently tested.
The second MySQL trade-off is at a consistency level. We run MySQL in read committed isolation mode. This strong consistency makes it easy for our developers to work with data, but it also limits the ways we can scale our databases. A common way to scale is to introduce caches that alter the overall consistency guarantees, but increase read throughput. In our case, while we’ve built out a cache layer, it was still designed to be strongly consistent with the database. This decision complicated the design, and put restrictions on how far away from the databases caches can be.
Finally, because Edgestore is a large multi-tenant graph database used for many different purposes, data ownership isn't always straightforward. This complex ownership model made it hard to move just a subset of user data to another region.
These trade-offs are critical to why we struggled to build an active-active system. Our developers have come to rely on the write performance enabled by our first MySQL trade-off, and the strong consistency of the second. Combined, these choices severely limited our architectural choices when designing an active-active system, and made the resulting system much more complex. By 2017, work towards this effort had stalled—but there was still pressure within the company to develop a more robust solution to potential datacenter failures. To ensure business continuity in the event of disaster, we switched gears and prioritized an active-passive failure model instead.
Introducing the Disaster Readiness team
Once we made the decision to focus on active-passive, we began to build the tools needed to make failovers more frequent. In 2019 we ran our first formalized failover, and from that point on we ran failovers quarterly, further improving the process each time. 2020 marked a turning point—not only for the world, but for the state of disaster readiness at Dropbox.
In May 2020, a critical failure in our failover tooling caused a major outage, costing us 47 minutes of downtime. The script that drove the failover had errored out halfway through the process, leaving us stuck in a half-failed state. This failure highlighted several critical problems in our disaster readiness strategy:
- The system driving our failovers did not fail safely.
- Individual service teams all owned their own failover process and tooling in isolation from each other.
- We were not running failovers often enough, which gave us fewer opportunities to practice our approach.
To tackle the first problem, we started an emergency audit of our existing failover tooling and processes. We made the necessary changes to ensure our tooling now failed safely, and built a new checklist to ensure appropriate rigor when running a failover exercise.
The second and third problems were addressed by creating a dedicated team for failover, the Disaster Readiness (DR) team. Having a dedicated team with no competing priorities meant we could run failovers monthly instead of quarterly. More failover experience would not only help build confidence in our approach, but empower us to respond to and recover from disasters far more quickly than before.
With a clear mandate and a team of seven, we set ourselves the ambitious goal of significantly reducing our RTO by the end of 2021.
The year of failover improvements
A major concern highlighted by the May 2020 outage was that we relied on a single monolithic Go binary to handle the failover from one metro to another. This tool did the job for the first few failovers, but became harder to manage as our failover ambitions grew.
As a result, we decided to rewrite the tool from the ground up to be more modular and configurable. We took inspiration from Facebook’s Maelstrom paper, which details a system for dealing with data center disaster scenarios by smartly draining traffic. However, we would need to adapt the fundamental idea to our own Dropbox systems, starting with an MVP.
We borrowed Maelstrom’s concept of a runbook, which contains one or more tasks, each of which carries out a particular operation. Together, the tasks form a directed acyclic graph, which enables us to describe not only the current steps needed to perform a failover exercise, but any generic disaster recovery test. We can then describe the runbook needed to perform a failover in a configuration language that is easy to parse and edit—making changes or updates to the failover process as simple as editing configuration files.
Not only is this a much more lightweight process than editing the Go binary directly, but it allows us to reuse tasks with other runbooks, making it easier to test a task one at a time on a more regular basis.
The diagrams below show the state machines for a runbook and a task within.
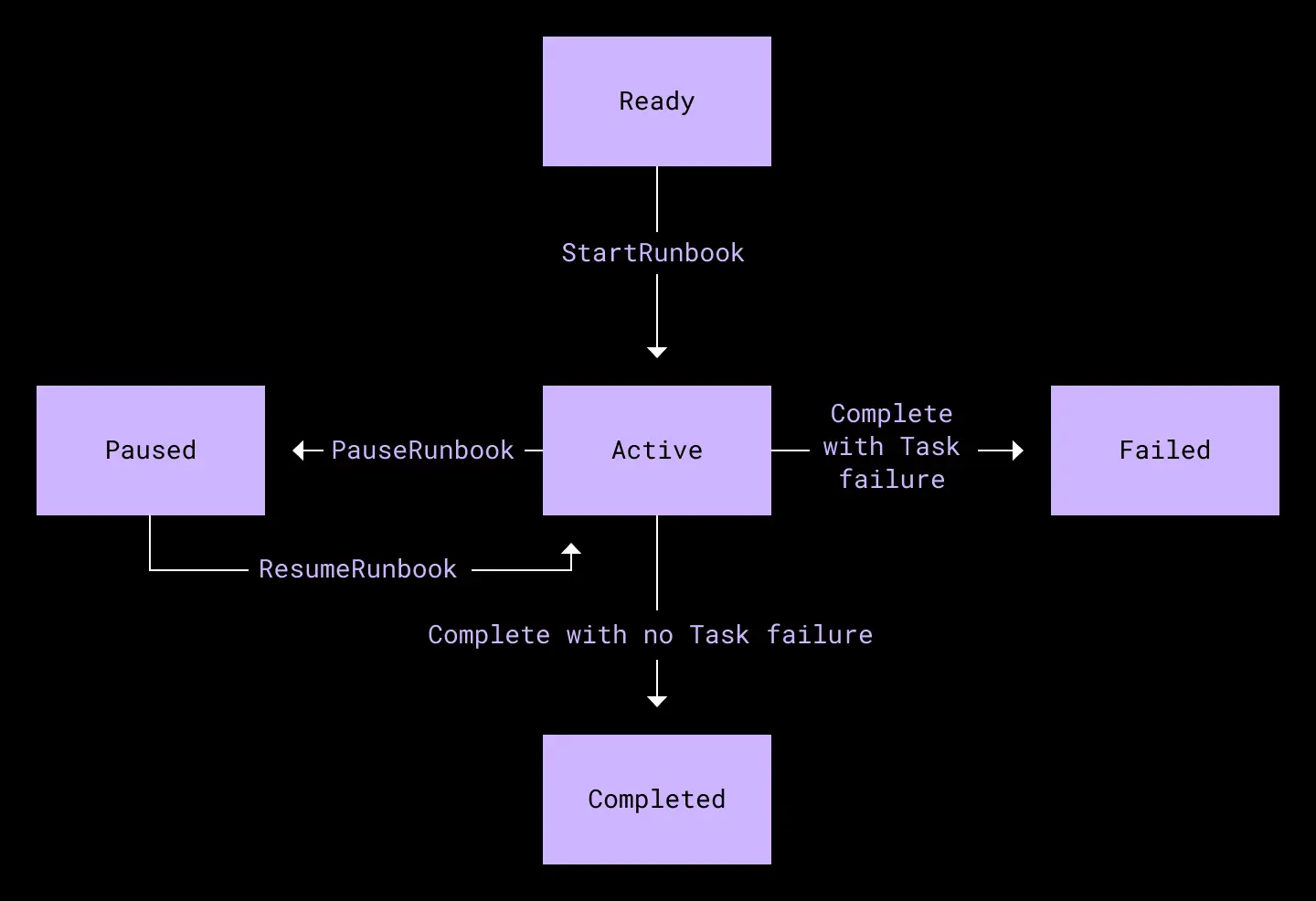
Runbook state machine. A runbook consists of multiple Tasks.
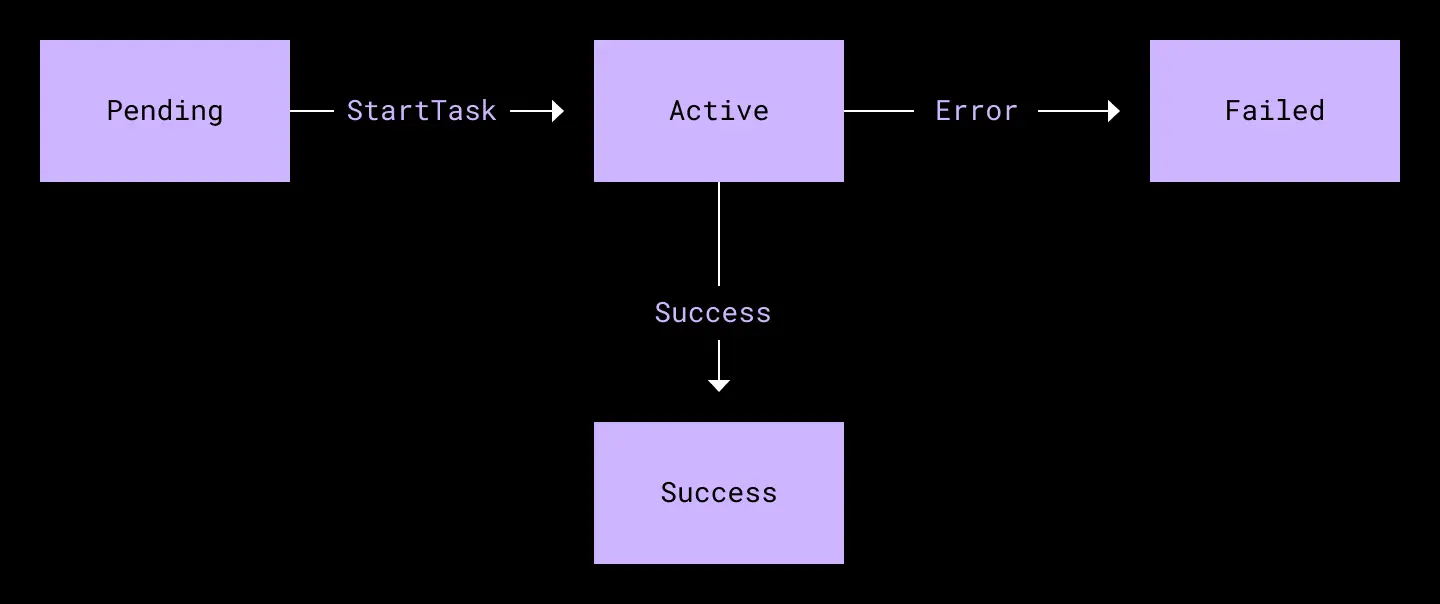
Task state machine. A task performs a specific operation, such as failing over a database cluster, changing traffic weights, or sending a Slack message.
We also wrote an in-house scheduler implementation which can accept a runbook definition and send out tasks to be executed by a worker process. For the MVP, both scheduler and worker are co-located in the same process and communicate over Go channels, but the flexible architecture means we could turn them into separate services as usage increases in the future.
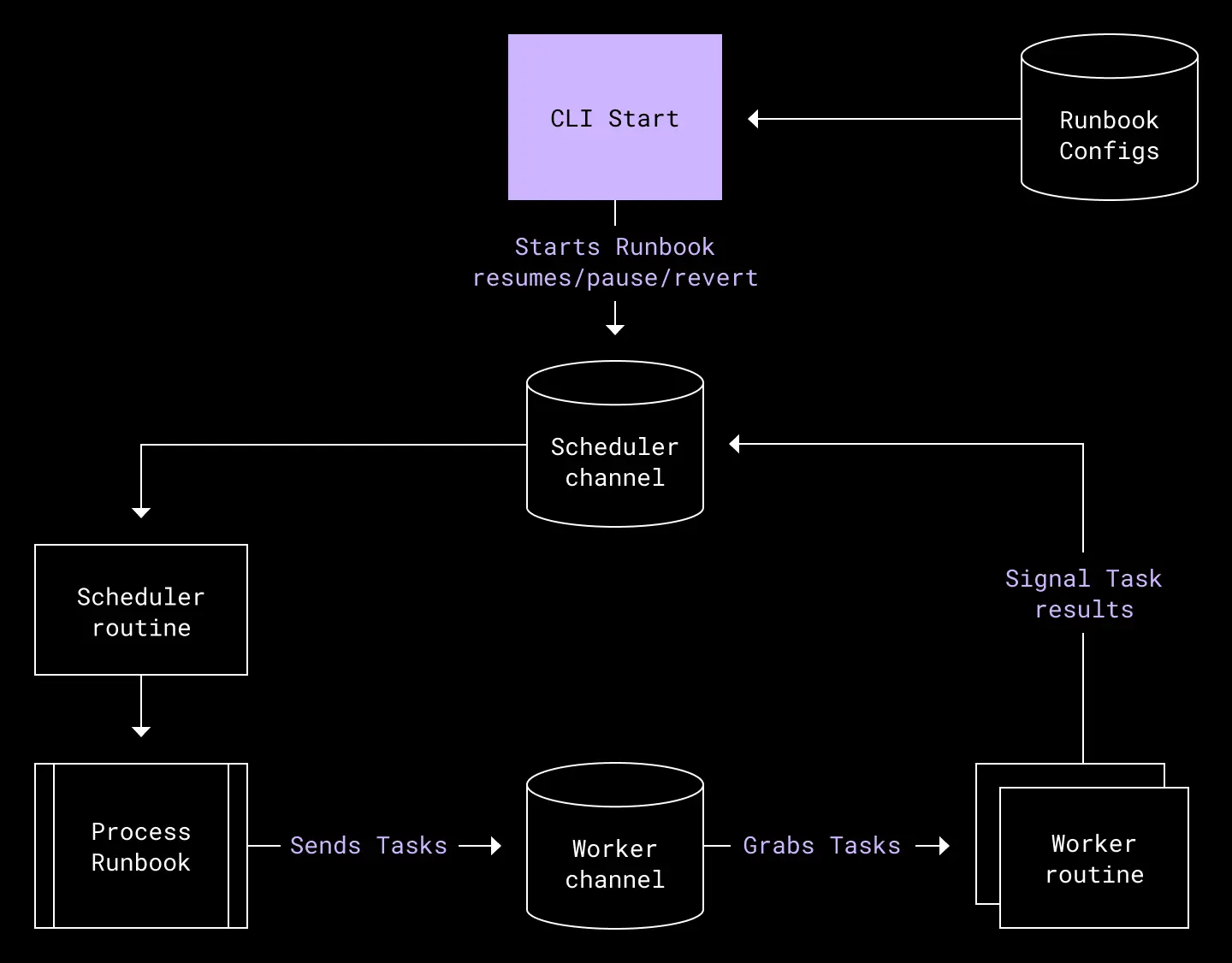
The updated failover tool, which consists of a scheduler goroutine and multiple worker goroutines, communicating via channels to assign and execute tasks belonging to a runbook in the correct order.
With this new architecture, it was easy to gain visibility into the execution status of our failover runbook. At a glance, we could now tell which tasks had failed or succeeded. The explicit graph structure also allows for greedy task execution in the face of failure, while guarding important actions from being executed should any of their predecessors fail. And the operator gains other operational flexibilities, such as the ability to easily rerun a runbook, skipping over completed tasks or tasks we do not want. As our runbooks grow in complexity, these reliability gains are essential for our procedure to remain manageable.
Fundamental improvements in our tooling aside, we also implemented other changes to help us reduce risk and place our customers first:
- Routine testing of key failover procedures. With our refactored tooling, we could now run regular, automated tests of failover tasks on a much smaller scale. For example, we might only run a failover of a single database cluster, or only one percent of traffic to another metro and back. These small tests gave us the confidence to make changes without worrying we might miss any regressions—and helped ensure the same issues that plagued our unsuccessful failover would not reoccur.
- Improved operational procedures. The DR team was inspired by practices used in past NASA space launches. For example, we instituted a formalized go/no-go decision point, and various checks leading up to a countdown. We also introduced clearly defined roles—such as “button pusher” and “incident manager”—and automated as many steps as possible, allowing us to reduce the number of participants needed for each failover exercise from 30 to fewer than five. This reduction helped us balance the cost of running exercises more frequently.
- Clearly defined abort criteria and procedures. Part of the operational improvements included planning for a worst case scenario by defining clear abort criteria and procedures. Having these in place ensured we not only knew when to make a call to abort, but how—allowing us to recover as quickly as possible and minimize the impact on our users’ experience.
- More frequent and longer failover exercises. Armed with better tooling, procedures, and visibility into our failover exercises, we were able to increase the frequency of failovers from once a quarter to once a month—and increase the duration of each failover exercise over time. This enabled us to catch code deployments, configuration changes, or new services that would cause a problem during failover sooner, reducing the number of such issues we had to address at a time. After multiple successful one-hour failovers, we increased our stay in the passive metro to four hours, then 24 hours, and so on—until we were able to run from the passive metro for over one month at a time. We also challenged the team with an “unplanned” failover, where the date of the failover was a surprise to the team and the company, leaving everyone just an hour to prepare.
Looking back at the improvements made since the May 2020, our successful streak of failovers demonstrated that we were on the right path towards our goal. Operationally, we demonstrated muscle memory for performing and consistently improving failovers. The failover service introduced a layer of automation that significantly reduce pre-failover steps for the DR team—drastically reducing the amount of manual prep work needed to perform failover as a result. These tooling improvements also reduced our monthly downtime from 8-9 minutes per failover at the beginning of 2021 to 4-5 minutes in the latter half of the year. The next frontier was getting to a place where we could prove we were no longer dependent on SJC.

A history of our incremental progress on failover exercises with longer duration of stay.
The year of the blackhole
As our failover efforts continued to improve from 2020 into 2021, a small group within the DR team began work on the second critical milestone: achieving true active-passive architecture.
While our ability to failover proved we could migrate the metadata serving stack to the passive metro, there were several other critical services still serving from the active metro—in this case, SJC. We realized the best way to ensure we did not have any dependency on the active metro was to perform a disaster recovery test where we physically unplugged SJC from the rest of the Dropbox network. If unplugging SJC proved to have minimal impact on our operations, this would prove that in the event of a disaster affecting SJC, Dropbox could be operating normally within a matter of hours. We called this project the SJC blackhole.
Multi-homing
Even though the metadata and block stacks that serve live user traffic would not be affected by the SJC blackhole, we knew we could still face major troubles if internal services were degraded or nonfunctional while Dropbox was being served out of another metro. That would prevent us from being able to correct production issues that might arise during the blackhole. As a result, we needed to ensure that all critical services still running in SJC were multi-homed—or, at the very least, could temporarily run single-homed from a metro other than SJC.
Several prior technological investments helped facilitate the multihoming process and made detection of single-homed services easier. We leveraged the Traffic team and our traffic load balancer Envoy to control traffic flowing from our POPs to our data centers for all critical web routes. The Courier migration allowed us to build common failover RPC clients, which could direct a service’s client requests to a deployment in another metro. Additionally, Courier standard telemetry provided inter-service traffic data, which helped us identify single-homed services. At the network layer, we leveraged Kentik netflow data with custom dimension tagging to validate the dependency findings from our Courier service and catch any lingering non-Courier traffic. Finally, almost all services are under Bazel configuration, which allowed us to build and promote multi-metro deployment practices and provided another data source to validate service-metro affinity. Once at-risk services were identified, the DR team provided advice and resources to empower service owners to make changes to their service architecture that would reduce dependency on SJC.
In some cases, we were able to work directly with teams to integrate their service into our monthly failover. By reducing the number of services which were single-homed in SJC and involving them in regular testing, we increased our confidence in those services being able to serve out of another metro. Some of the major services that were added to the failover roster were CAPE and ATF, two asynchronous task execution frameworks. For certain teams, we parachuted in to directly assist their multi-homing efforts for their SJC-only components. In the end, we were able to help multi-home all major services in SJC before our planned blackhole date, allowing us to minimize the potential impact of SJC going dark.
Preparing for the blackhole
Once we were confident that critical services were, at the very least, no longer single-homed in SJC, we prepared to unplug SJC for the first time.
About two months prior to the SJC blackhole, in collaboration with the networking engineering team, we decided to take an incremental approach to preparing for the big event. In our collaboration, there were three main goals:
- To decide on a procedure that would simulate a complete loss of SJC (and would be easily reversible).
- Test this procedure in a lower risk, less impactful metro.
- Based on the outcome of these tests, prepare the company for the SJC blackhole.
The procedure
Initially, we planned to isolate SJC from the network by draining the metro’s network routers. While this would have gotten the job done, we ultimately landed on a physical approach that we felt better simulated a true disaster scenario: unplugging the network fiber! After deciding on this approach, we set out to outline a detailed Method of Procedure (MOP) that would dictate the sequence of actions to be performed on the big day. At a high level, this is what our MOP looked like:
- Install traffic drains to direct all lingering traffic to other metros.
- Disable all alerting and auto-remediation.
- Pull the plug!
- Perform validations (pings to machines, monitor key metrics, etc.).
- Start a 30 minute timer and wait.
- Reconnect fiber.
- Perform validations.
- Re-enable alerting and auto-remediation.
- Un-drain traffic.
With the overall procedure decided, we set out to prepare for two test runs in our Dallas Forth Worth (DFW) metro. We chose this metro because it fit the requirement of being lower risk; it had few critical services, all of which were multi-homed by design, and was therefore very resilient.
The DFW metro consists of two data center facilities: DFW4 and DFW5. We decided to start with one data center for the first test, and test both facilities second.
To prepare, the networking and data center teams took photos documenting our optical gear wiring in its ideal state. They also ordered backup hardware to have on hand, just in case something broke. Meanwhile, the DR team defined our abort criteria, and coordinated with teams to either drain their service or disable alerting and/or auto-remediation.
DFW test no.1
The day finally came to conduct our first DFW test. More than 20 of us were gathered over Zoom, our MOP was on the screen, and everyone understood their role and was ready to go. We proceeded as planned through the MOP, and unplugged the fiber for DFW4.
As we began to do validations, we noticed very quickly that our external availability number was dropping—something we did not expect. After waiting about four minutes, we made the call to abort and began to reconnect the network fiber. We deemed the first test a failure as we did not reach 30 minutes of network isolation.
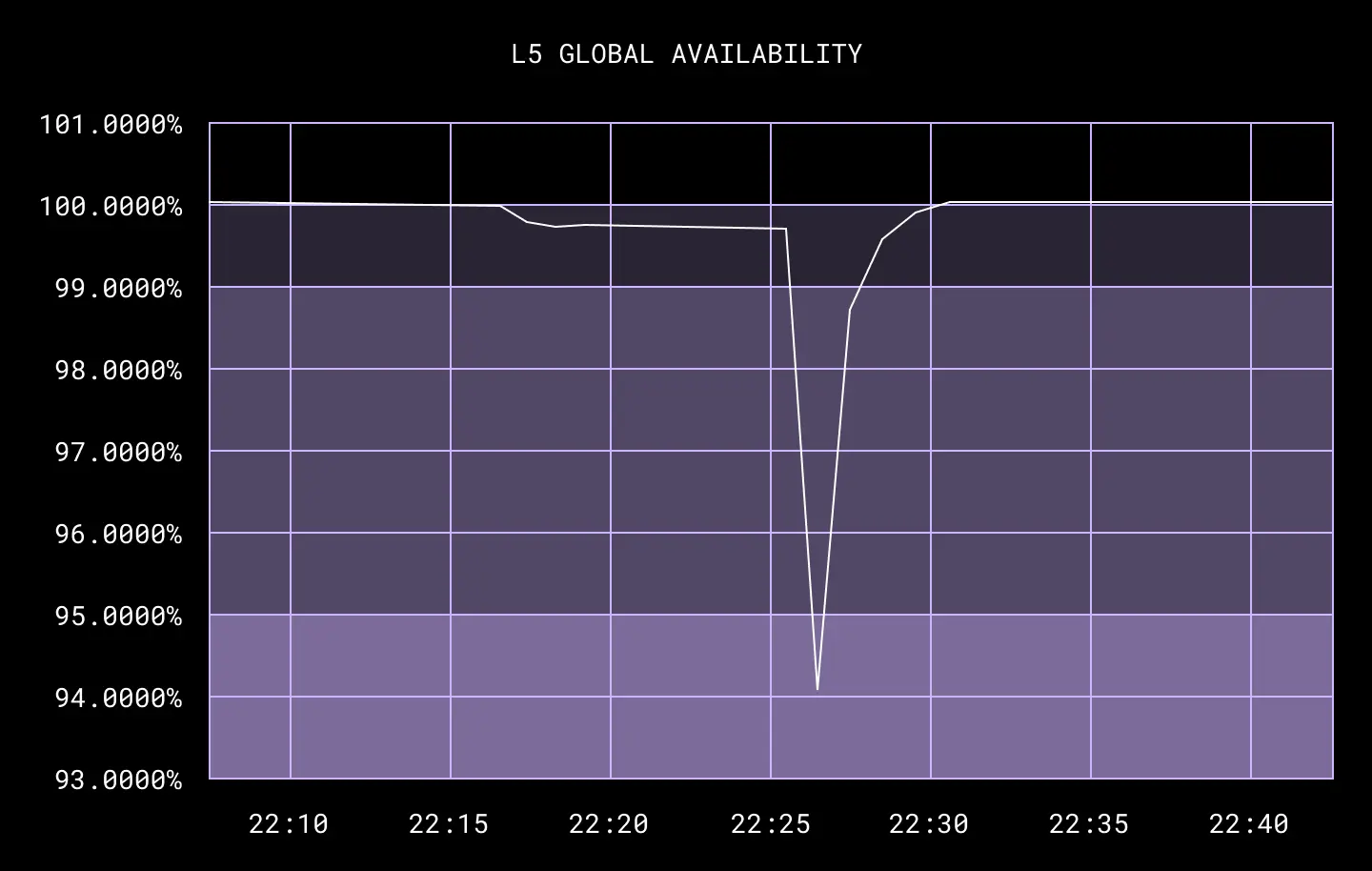
The root cause was that the unplugged DFW data center, DFW4, was home to our S3 proxies. When the services still running in DFW5 tried—and failed—to talk to the local S3 proxies, those services suffered, ultimately impacting global availability.
Going into the test, we incorrectly assumed that the two DFW facilities were roughly equivalent—and thus, we could simply pull the plug on one without affecting the other. However what this test found was that, because we don’t yet treat facilities as independent points of failure—but plan to in the future—many cross-facility dependencies still exist. This leads to a greater impact when we take a single facility offline compared to taking the whole metro offline1.
It’s important to remember that the whole purpose of disaster recovery tests are the lessons we learn—and in this case, not only did the DR team learn a lot, but so did many others. Specifically:
- We needed to conduct blackhole tests on the entire metro, not individual data center facilities.
- We needed a more robust abort criteria specific to these types of tests.
- We needed to work with local service owners to drain their services.
As a result, the MOP for the next tests introduced two new steps:
- Drain any local services (for example, S3 proxies).
- Install traffic drains to direct all lingering traffic to other metros.
- Disable all alerting and auto-remediation.
- Pull the plug!
- Perform validations (pings to machines, monitor key metrics, etc.).
- Start a 30 minute timer and wait.
- Reconnect fiber.
- Perform validations.
- Un-drain local services and validate their health.
- Re-enable alerting and auto-remediation.
- Un-drain traffic.
DFW test no.2
Using what we learned, we tried again a few weeks later—this time, aiming to blackhole the entire DFW metro. Once again, photos were taken, we had backup hardware on hand, and we prepared for our first full metro blackhole.
We started by draining critical local services, and then proceeded with the remaining steps as usual. Two Dropboxers were positioned onsite in each facility and unplugged the fiber on command. Much to our relief, we saw no impact to availability and were able to maintain the blackhole for the full 30 minutes. This was a significant improvement which allowed us to deem the network procedure viable for SJC.
An important outcome of our DFW tests was that they forced owners of non-critical services—for example, deployment systems, commit systems, and internal security tooling—to think critically about how the SJC blackhole would impact them. An impact document was created to ensure we had a single source of truth to communicate which services would have a gap in service during the SJC blackhole. And we encouraged service owners to perform their own pre-blackhole tests to ensure their service’s readiness for the SJC blackhole procedure.
As we reflected on what went well and how we could improve, we realized another huge benefit: these tests had helped train the key teams and their on-calls on the procedure we would use for the SJC blackhole. The fact we could apply these same procedures to SJC gave us the operational confidence we would be successful there, too.
The big day
On Thursday, November 18, 2021, the time had finally come to unplug SJC. We had three Dropboxers ready onsite in each of SJC’s three data center facilities. Again, they took photos and had extra hardware ready in case any optical gear was damaged while un-plugging or re-plugging the delicate network fiber. About 30 people gathered in a Zoom call, and even more in a Slack channel, diligently progressing through a detailed procedure like a space launch mission control.
Finally, at 5:00 pm PT, the time came to pull the plug at each facility, one by one, until all three were offline. Much like our second DFW test, we saw no impact to global availability—and ultimately reached our goal of a 30 minute SJC blackhole!
Yeah, we know, this probably sounds a bit anti-climactic. But that’s exactly the point! Our detail-oriented approach to preparing for this event is why the big day went so smoothly.
While there were some unexpected impacts to internal services that we plan to follow up on, we deemed this test a huge success. In the unlikely event of a disaster, our revamped failover procedures showed that we now had the people and processes in place to offer a significantly reduced RTO—and that Dropbox could run indefinitely from another region without issue. And most importantly, our blackhole exercise proved that, without SJC, Dropbox could still survive.

From left to right, Eddie, Victor, and Jimmy prepare to physically unplug the network fiber at each of SJC’s three data center facilities.
A more resilient, reliable Dropbox
The ability to completely blackhole SJC traffic for 30 minutes was a big step forward for disaster readiness at Dropbox. We proved we now have the tooling, knowledge, and experience necessary to keep the business running in the wake of a disaster bad enough to shutdown an entire metro. These are also the kinds of improvements that enable us to be even more competitive with industry standards for service dependability and resiliency.
This was a multi-year effort involving careful planning and collaboration between multiple teams at Dropbox—and given the complexity of our services and their dependencies, these failovers were not without risk. But a mix of due diligence, frequent testing, and procedural improvements have helped us minimize those risks going forward.
Most importantly, our experience here reinforces a core tenet of disaster readiness: like a muscle, it takes training and practice to get stronger. As we conduct blackhole exercises more frequently—and refine the processes we use—our disaster readiness capabilities will only continue to improve. And if we do our jobs right, our users should never notice when something goes wrong. A resilient, reliable Dropbox is a Dropbox they can trust.
Finally, we’d like to acknowledge the many Dropboxers that made this possible, all of whom should be commended for helping us unlock this new milestone. Reliability at our scale requires everyone to take ownership. We couldn’t reach a milestone like this without hundreds of smaller wins from dozens of teams.
Also: we’re hiring!
Do you want to build resilient systems at scale? Are you energized by the thought of averting disaster? If so, we’d love to have you at Dropbox! Visit out our jobs page to see current openings and apply today.
- - -
1This isn't to say the failure of an individual data center facility would impact customers any more than the failure of an entire metro. In both cases we would maintain service by simply failing over to another metro. In the future we plan to further isolate our failure domains, at which point we'll update our disaster readiness strategy to test individual data center facilities, too.


