


There is nothing more important to Dropbox than the safety of our user data. When we set out to build Magic Pocket, our in-house multi-exabyte storage system, durability was the requirement that underscored all aspects of the design and implementation. In this post we’ll discuss the mechanisms we use to ensure that Magic Pocket constantly maintains its extremely high level of durability.
This post is the second in a multi-part series on the design and implementation of Magic Pocket. If you haven’t already read the Magic Pocket design overview go do so now; it’s a little long but provides an overview of the architectural features we’ll reference within this post. If you don’t have time for that then keep on reading, we’ll make this post as accessible as possible to those who are new to the system.
Table-stakes: Replication
When most good engineers hear “durability” they think “replication”. Hardware can fail, so you need to store multiple copies of your data on physically isolated hardware. Replication can be tricky from a mathematical or distributed-systems perspective, but from an operational perspective is the easiest to get right.
In the case of Magic Pocket (MP) we use a variant on Reed-Solomon erasure coding that is similar to Local Reconstruction Codes, which allows us to encode and replicate our data for high durability with low storage overhead and network demands. If we use a Markov model to compute our durability given the expected worst-case disk failure rates and repair times, we end up with an astonishingly-high 27 nines of durability. That means that according to this model, a given block in Magic Pocket is safe with 99.9999999999999999999999999% probability!
Does that mean we should trust this model and call it a day? Of course not. Replication is a necessary ingredient for durability, but by no means is it sufficient. There are a lot more challenging failure modes to contend with than just random disk failures: stuff like natural disasters, software bugs, operator error, or bad configuration changes. True real-world durability requires investing heavily in preventing these less-frequent but wider-reaching events from impacting data safety.
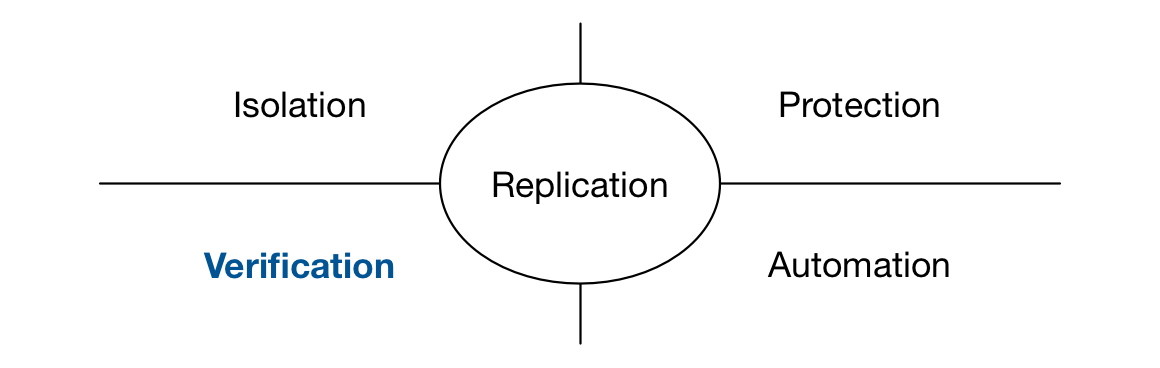
We recently presented a talk on Durability Theater, highlighting the challenges in building a system for real-world durability. Take a look at the video to find out more about about the breadth of defenses we employ against data loss, which we categorize across four dimensions: Isolation, Protection, Verification and Automation. Each of these would be a great topic for future blog posts but today we want to focus on one of our favorite areas of investment: Verification.
How correct is correct?
The most important question we ask ourselves every day is “is this system correct?” This is an easy question to ask, but a surprisingly difficult question to answer authoritatively. Many systems are “basically correct”, but the word “basically” can contain a lot of assumptions. Is there a hidden bug that hasn’t been detected yet? Is there a disk corruption that the system hasn’t stumbled across? Is there bad data in there from years and years ago that is used as a scapegoat whenever the system exhibits unexpected behavior? A durability-centric engineering culture requires rooting out any potential issues like this and establishing an obsessive focus on correctness.
A large fraction of the Magic Pocket codebase is devoted purely to verification mechanisms that confirm that the system continually maintains our high level of correctness and durability. This is a significant investment from the perspective of engineering time, but it’s also a huge hardware and resource-utilization investment: more than 50% of the workload on our disks and databases is actually our own internal verification traffic.
Let’s take a look at the stack of verifiers that we run continually in production…
One quick definition before we get started: an extent is the physical manifestation of a data volume on a given storage node. Each storage node stores thousands of 1GB extents which are full of blocks of user data.
Verification Systems
Cross-zone Verifier |
Application-level walker that verifies all data is in the storage system and in the appropriate storage regions. |
|
Storage Watcher |
Sampled black-box check that retrieves blocks after a minute, hour, day, week, etc. |
|
Metadata Scanner |
Verifies all data in the Block Index is on the correct storage nodes. |
|
Extent Referee |
Verifies that all deleted extents were justified according to system logs. |
|
Trash Inspector |
Verifies all deleted extents contain only blocks that are deleted or have been moved to other storage nodes. |
|
Disk
|
Verifies data on disk is readable and conforms to checksums. |
There are a lot of scanners in here so we’ll go through them one-by-one. Let’s start with the lowest level of the storage stack: the Disk Scrubber.
Disk Scrubber
This will be no surprise to those working in large-scale storage: your disks are lying to you. Hard drives are an amazing and reliable technology, but when you have over half a million disks in production they’re going to fail in all manner of weird and wonderful ways: bad sectors, silent disk corruption and bit-flips, fsyncs that don’t fsync . Many of these errors also slip through S.M.A.R.T. monitoring on the disks and lie there dormant, waiting to be discovered… or worse, not discovered at all.
When we talked about our durability model we mentioned how it depends on the time taken to repair a disk failure. When we detect a bad disk in MP we quickly re-replicate the data to ensure the volumes aren’t vulnerable to a subsequent disk failures, usually in less than an hour. If a failure were to go undetected however, the window of vulnerability would expand from hours to potentially months, exposing the system to data loss.
The disk scrubber runs continually on our storage nodes, reading back every bit on disk and validating it against checksums. If the scrubber detects bad data on disk then it automatically schedules that data to be re-replicated and for the disk to enter our disk remediation workflow, which we’ll discuss in a future post.
We perform a full sweep of each disk approximately every 1–2 weeks. This requires reading terabytes of data off the disk, but these are sequential scans which minimizes disk seeks. We also scan the recently-modified areas of the disk more frequently to catch any fresh issues.
Trash Inspector
If Magic Pocket needs to move a volume between storage nodes, or rewrite a volume after garbage collecting it, then it writes the volume to a new set of storage nodes before deleting it from the old nodes. This is an obviously-dangerous transition: what if a software bug caused us to erroneously delete an extent that hadn’t yet been written stably to a new location?
We adopt a protection in MP called trash. When the Master in a cell instructs a storage node to delete an extent the node actually just moves the extent to a temporary storage location on the disk. This “trash” data sits there until we can be sure this data was deleted correctly.
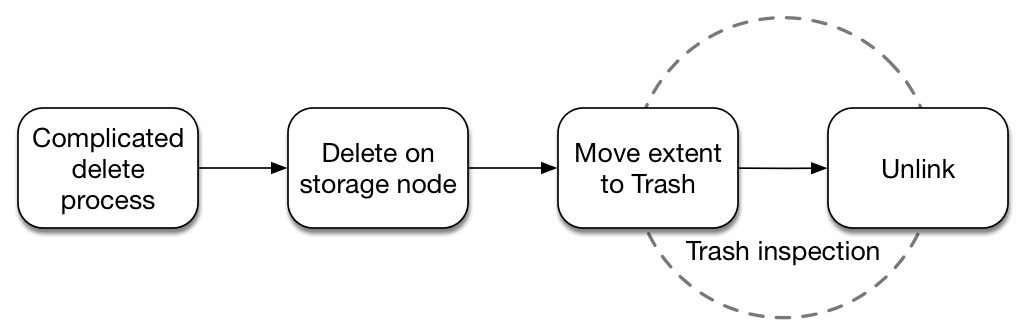
The Trash Inspector iterates over all the blocks in trash extents and checks the Block Index to determine that either:
- the block has been safely moved to a new set of storage nodes, or
- the block itself was also marked to be deleted.
Once a trash extent passes inspection it is kept on-disk for an additional day (to protect against potential bugs in the trash inspector) before being unlinked from the filesystem.
Extent Referee
The Trash Inspector does a good job of ensuring that we only delete data as intended, but what if a bad script or rogue process attempts to delete an extent before it has passed inspection? This is where the Extent Referee comes in. This process watches each filesystem transition and ensures that any move or unlink event corresponds to a successful trash inspection pass and corresponding instruction from the Master to remove the extent. The Extent Referee will alert on any transition that doesn’t conform to these requirements.
We also employ extensive unix access controls along with TOMOYO mandatory access control to guard against operators or unintended processes interacting with data on storage nodes. More on these in future posts.
Metadata Scanner
One advantage of storing our Block Index in a database like MySQL is that it’s really easy to run a table scan to validate that this data is correct. The Metadata Scanner does exactly this, iterating over the Magic Pocket Block Index at around a million blocks per second (seriously!), determining which storage nodes should hold each block, and then querying these storage nodes to make sure the blocks are actually there.
A million checks per second sounds like a lot of activity, and it is, but we have many hundreds of billions of blocks to check. Our goal is to perform a full scan over our metadata approximately once per week to give us confidence that data is entirely correct in one storage zone before we advance our code release process and deploy new code in the next zone.
The storage nodes keep enough metadata in-memory to be able to answer queries from the Metadata Scanner without performing a disk seek. The Metadata Scanner and Disk Scrubber thus work together to ensure both that the data on the storage nodes matches the data in the Block Index, and also that the data on the disks themselves is actually correct.
Storage Watcher
The most insidious bugs in a large distributed system are logic errors on the boundaries between modules: an engineer misunderstanding an API, or the semantics of an RPC call, or the meaning of a field in a database. These are hard to catch in unit testing, and typically require comprehensive integration testing or verification mechanisms to detect. But what if the engineer writing the code is the same person writing the tests or the verifier? It’s very likely that the same broken assumptions will make their way into the verification mechanism itself.
The Watcher was designed to avoid any such “broken verifiers” and was written as an end-to-end black box checker, implemented by someone who wasn’t involved in building the storage system. We sample 1% of all blocks written to Magic Pocket and record their corresponding storage keys (hashes) in queues in Kafka. The Watcher then iterates over these queues and makes sure it can correctly fetch these blocks from Magic Pocket after one minute, one hour, one day, one week and one month. This allows us to verify that MP is indeed still serving blocks correctly from an end-to-end perspective, and that there are no errors introduced over time that may prevent a block from being accessed.
Cross-zone Verifier
This is the last one so we’ll make it quick. MP contains multiple storage zones that store data for different users and we need to maintain some careful invariants when moving users between these zones. We also need to make sure that if a zone goes down for maintenance or because of an outage that we recover quickly and transfer all data that may have been missed during this downtime.
The Cross-zone Verifier lives outside of MP and scans through the Dropbox filesystem maintained in a separate system called File Journal. This verifier walks this filesystem and checks that all files in Dropbox are correctly stored in all zones corresponding to the given user. While the other verifiers confirm that MP is correctly storing the blocks that we know we should have, the Cross-zone Verifier ensures that there’s agreement between what MP is storing and what our clients (the rest of Dropbox) think we should be storing.
Verification as testing
If it felt like a lot of work reading that long list of verifiers, rest assured that it was a lot more work to actually build them. Building these verifiers was a really valuable investment for us however, and greatly improved our execution speed. This is because a comprehensive verification stack doesn’t just ensure that the system is correct in production, it also provides a highly-valuable testing mechanism for new code.
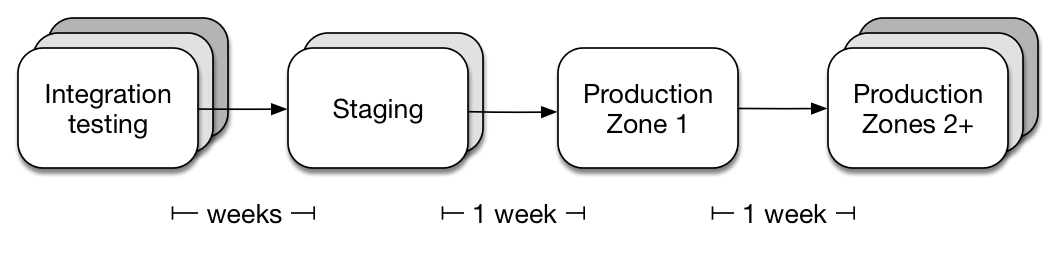
Unit tests are great but there’s no substitute for comprehensive integration testing. We run a broad suite of integration tests on simulated workloads, including failure injection and multiple simultaneous code versions, but the final gateway to production is always our Staging cluster. This cluster is tens of petabytes in size and stores a geographically-distributed mirror of a subset of production data. We actually serve live traffic out of Staging and fall back to production MP if there’s a problem. We run these verifiers for at least a week on Staging before team members can sign off to release a code version from stage into production. The verification mechanisms provide us a very comprehensive view into the correctness of the system and ensure that any bugs are caught before they make it to an actual production cluster.
Watching the watchers
One last remark before we go: how do we verify the verifiers themselves?
Here’s a screenshot of the primary metric generated by the Metadata Scanner. Take a look and see if you notice anything interesting:
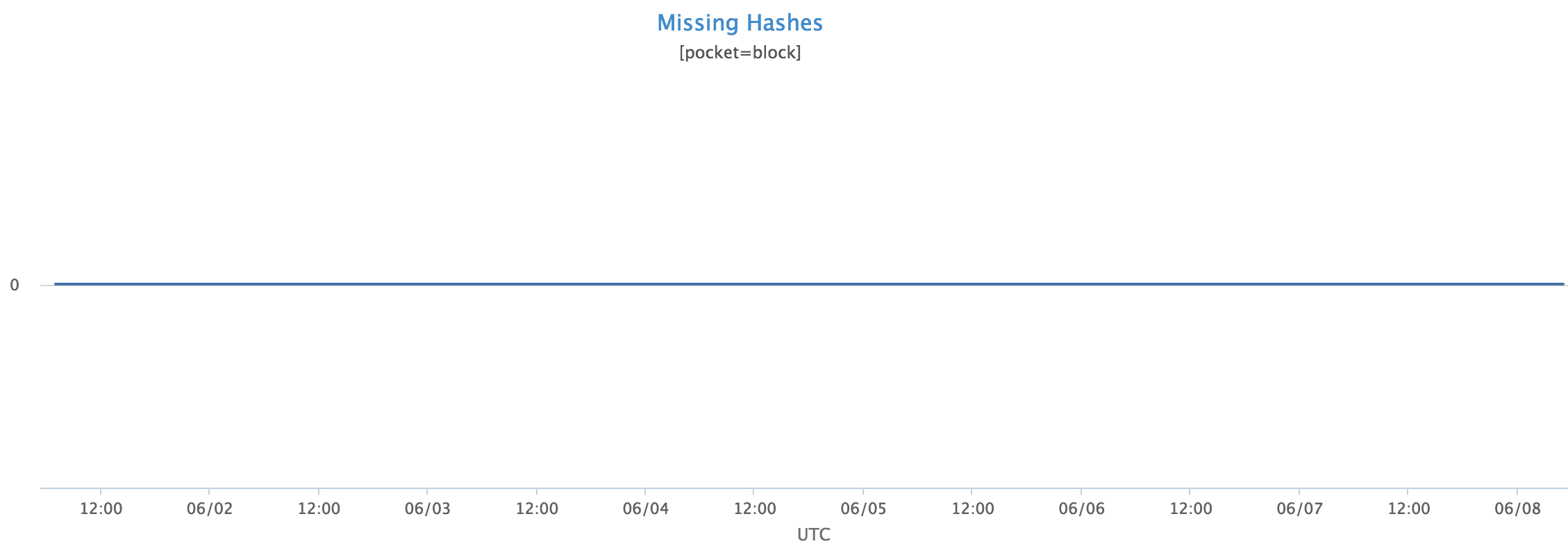
That’s right, it’s the most boring graph in the world!
MP is designed for extremely high levels of durability so the graph of missing hashes is just a zero line. Apart from the Disk Scrubber which finds regular disk errors, and occasional timeouts from our other verifiers, all our verification graphs look like this. How do we know that the scanners are actually doing something useful rather than just spitting out zeros all day? What we really need to do is create some problems and make sure they get detected.
This dovetails into a larger discussion about DRTs (Disaster Recovery Training events) that we’ll cover another time. These are induced failures to test that a system is able to recover from disaster, and that the team is trained to respond to an incident. The other important and sometimes-overlooked aspect to a DRT however is ensuring that all the verification systems are actually doing their job.
For us this means constructing failure tests that trigger our verification mechanisms without potential for actually impacting user data. Typically this means running tests in our staging cluster, which is safely backed up in our production clusters.
The details of one interesting test are as follows:
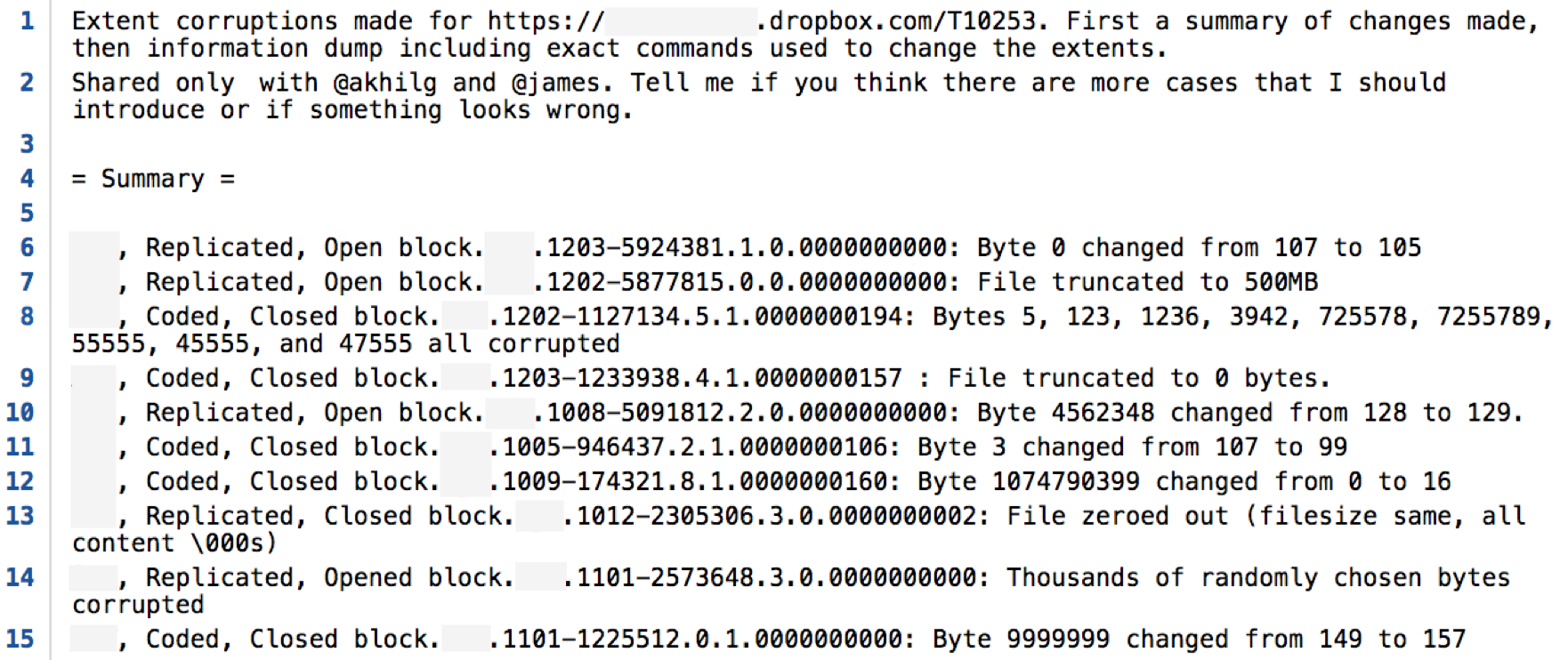
In this test one of our engineers got permission to secretly corrupt data in our staging cluster, flipping bits, truncating extents, and inserting random data. We then waited for the rest of the team to detect the full set of errors. In this particular test all errors were quickly detected, except for two which were automatically repaired by MP before the verifiers got to them. Importantly however, there was no data loss in our staging cluster because of this test; MP contains enough redundancy to automatically detect and recover from all these failures without any operator intervention.
Wrap-up
It was certainly a lot of work to build all the verification systems in MP; there probably aren’t too many large-scale systems in the world subject to more scrutiny. Every project will involve a tradeoff on the spectrum of effort vs correctness, and for Dropbox data-safety is of paramount importance.
Regardless of where you land on this spectrum, the main lesson from this post is that confidence in correctness is a very empowering concept. Being able to reason about the current state of a storage system means that you’re able to move fast on future development, respond to operational issues with confidence, and to build reliable client applications without confusion about the source of errors or inconsistencies. It also lets us sleep a little better every night, which is always a valuable investment.
Stay tuned for more posts about Magic Pocket. Next post will likely cover some of the operational issues involved in running a system at this scale, followed by a post discussing our Diskotech architecture to support append-only SMR storage. We’ll catch you then!


