


Request queuing
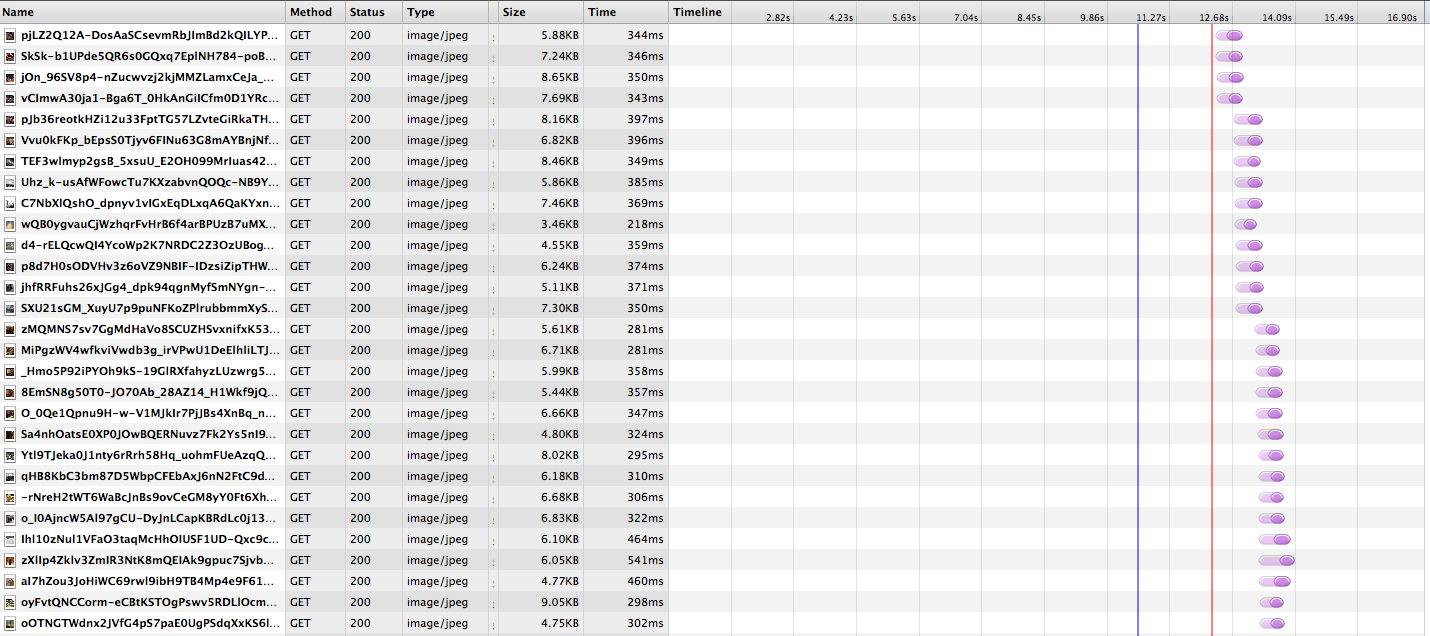
You can see that a limited set of images is loaded in parallel, blocking the next set of thumbnails from being loaded. If the latency of fetching each image is high—e.g. for users far away from our datacenters—loading the images can drastically increase the page load time. This waterfall effect is common for web pages loading lots of subresources, since most browsers have a limit of 6 concurrent connections per host name.
A common workaround for web pages is to use domain sharding, spreading resources over multiple domains (in this case photos1.dropbox.com, photos2.dropbox.com, etc.) and thus increasing the number of concurrent requests. However, domain sharding has its downsides—each new domain requires a DNS resolution, a new TCP connection, and SSL handshake—and is also not practical when loading thousands of images and requiring many domains. We saw similar issues on our mobile apps: both iOS and Android have per-host or global limits on the number of concurrent connections.
To solve the problem, we need to reduce the number of HTTP requests. This way we avoid problems with request queueing, make full use of the available connections, and speed up photo rendering.
Measuring performance
Before embarking on any performance improvement, we need to make sure we have all of the instrumentation and measurements in place. This allows us to quantify any improvements, run A/B experiments to evaluate different approaches, and make sure we’re not introducing performance regressions in the future.
For our web application, we use the Navigation Timing API to report back performance metrics. The API allows us to collect detailed metrics using JavaScript, for example DNS resolution time, SSL handshake time, page render time, and page load time:
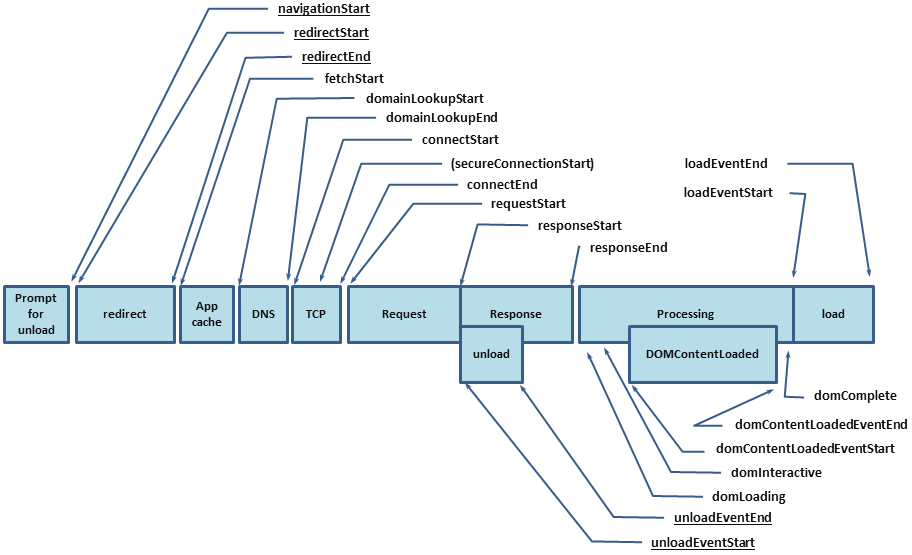
Similarly, we log detailed timing data from the desktop and mobile clients.
All metrics are reported back to our frontends, stored in log files and imported into Apache Hive for analysis. We log every request with metadata (e.g. the originating country of the request), which allows us to break down the metrics. Hive’s percentile() function is useful to look at the page load time distribution – it’s important to track tail latency in addition to mean. More importantly, the data is fed into dashboards that the development teams use to track how we’re doing over time.
We instrumented our clients to measure how long it takes to load thumbnails. This included both page-level metrics (e.g. page render time) and more targeted metrics measured on the client (e.g. time from sending thumbnail requests to rendering all the thumbnails in the current viewport).
Batching requests
- We use nginx on our frontends. At the time, there was no stable nginx version with SPDY support.
- We use Amazon ELB for load balancing, and ELB doesn’t support SPDY.
- For our mobile apps, we didn’t have any SPDY support in the networking stack. While there are open-source SPDY implementations, this would require more work and introduce potentially risky changes to our apps.
GET https://photos.dropbox.com/thumbnails_batch?paths=
/path/to/thumb0.jpg,/path/to/thumb1.jpg,[...],/path/to/thumbN.jpgHTTP/1.1 200 OK
Cache-Control: public
Content-Encoding: gzip
Content-Type: text/plain
Transfer-Encoding: chunked
1:data:image/jpeg;base64,4AAQ4BQY5FBAYmI4B[...]
0:data:image/jpeg;base64,I8FWC3EAj+4K846AF[...]
3:data:image/jpeg;base64,houN3VmI4BA3+BQA3[...]
2:data:image/jpeg;base64,MH3Gw15u56bHP67jF[...]
[...]- Batched: we return all the images in a single plain-text response. Each image is on its own line, as a base-64-encoded data URI. Data URIs are required to make batching work with the web code rendering the photos page, since we can no longer just point an <image> src tag to the response. JavaScript code sends the batch request with AJAX, splits the response and injects the data URIs directly into <image> src tags. Base-64 encoding makes it easier to manipulate the response with JavaScript (e.g. splitting the lines). For mobile apps, we need to base64-decode the images before rendering them.
- Progressive with chunked transfer encoding: on the backend, we fire off thumbnail requests in parallel to read the image data from our storage system. We stream the images back the moment they’re retrieved on the backend, without waiting for the entire response to be ready; this avoids head-of-line blocking, but also means we potentially send the images back out of order. We need to use chunked transfer encoding, since we don’t know the content length of the response ahead of time. We also need to prefix each line with the image index based on the order of request urls, to make sure the client can reorder the responses. On the client side, we can start interpreting the response the moment the first line is received. For web code we use progressive XMLHttpRequest; similarly for mobile apps, we simply read the response as it’s streamed down.
- Compressed: we compress the response with gzip. Base64-encoding generally introduces 33% overhead. However, that overhead goes away after gzip compression. The response is no longer than sending the raw image data.
- Cacheable: we mark the response as cacheable. When clients issue the same request in the future, we can avoid network traffic and serve the response out of cache. This does require us to make sure the batches are consistent however - any change in the request url would bypass the cache and require us to re-issue the network request.
Results
Since the scheme is relatively simple and uses plain HTTPS instead of SPDY, it allowed us to deploy it on all platforms and we saw significant performance improvements: 40% page load time improvement on web.
However, we don’t see this as a long-term strategy - we’re planning on adding SPDY support to all of our clients and take care of pipelining at the protocol level. This will simplify the code, give us similar performance improvements and better cacheability (see note about consistent batches above).
The Dropbox performance team is a small team of engineers focused on instrumentation, metrics and improving performance across Dropbox’s many platforms. If you obsess over making things faster and get excited when graphs point down and to the right, join us!


