

Our users love Dropbox for many reasons, sync performance being chief among them. We’re going to look at a recent performance improvement called Streaming Sync which can improve sync latency by up to 2x.
Prior to Streaming Sync, file synchronization was partitioned into two phases: upload and download. The entire file must be uploaded to our servers and committed to our databases before any other clients could learn of its existence. Streaming sync allows file contents to “stream” through our servers between your clients.
The Dropbox File System
First we’ll discuss the way Dropbox stores and syncs files. On your local machines, Dropbox attempts to conform to the host file system on your system. However, especially considering that Dropbox supports shared folders, the server side Dropbox file system has a different abstraction. Unlike a traditional file system, a relative path is insufficient.
We define a namespace to be an abstraction for the root directory of a more traditional file system directory tree. Each user owns a root namespace. In addition, every shared folder is a namespace which can be mounted within one or many root namespaces. Note that users own namespaces and not vice versa. With this abstraction, every file and directory on the Dropbox servers can be uniquely identified by two values: a namespace and a relative path.
Dropbox File Format
Every file in Dropbox is partitioned into 4MB blocks, with the final block potentially being smaller. These blocks are hashed with SHA-256 and stored. A file’s contents can be uniquely identified by this list of SHA-256 hashes, which we refer to as a ‘blocklist’.
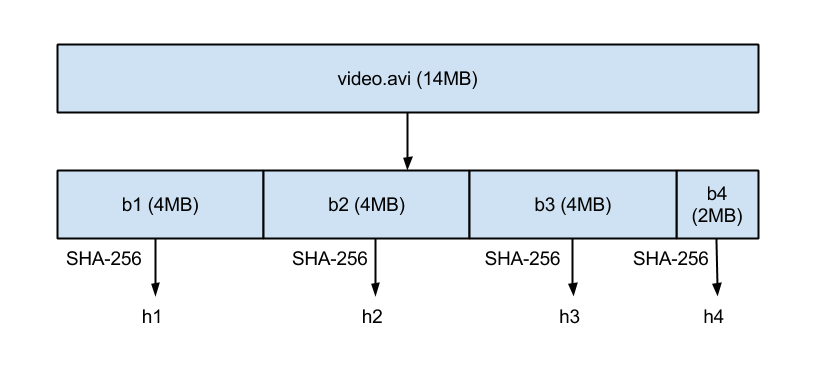
Here, the blocklist for video.avi is ‘h1,h2,h3,h4’, where h1, h2, h3, and h4 represent hashes of the blocks b1, b2, b3, and b4.
The Server File Journal (SFJ)
This is our big metadata database which represents our file system! Note that it doesn’t contain file contents, just blocklists. It is an append-only record where each row represents a particular version of a file. The key columns in the schema are:
- Namespace Id (NSID)
- Namespace Relative Path
- Blocklist
- Journal ID (JID): Monotonically increasing within a namespace
Dropbox server types
There are two types of servers relevant to this discussion:
- Block data server: Maintains a key-value store of hash to encrypted contents. No knowledge of users/files/how those blocks fit together.
- Metadata server: Maintains database of users, namespaces, and of course SFJ
The servers communicate via internal RPCs when necessary.
Dropbox Desktop Client Protocol
First, we will discuss the protocol prior to streaming sync, to motivate this work.
Each desktop client keeps a cursor (a JID) of its location in SFJ for each of its namespaces, which allows it to communicate how ‘up-to-date’ it is with the server.
First, let’s discuss what happens on an uploading client when a file appears! The client first attempts to ‘commit’ the blocklist to the server under the (namespace, path). The metaserver checks to see if a) Those hashes are known. b) This user/namespace has access. If not, the commit call returns “need blocks” indicating which blocks are missing. For brand new files, this is often all of them.
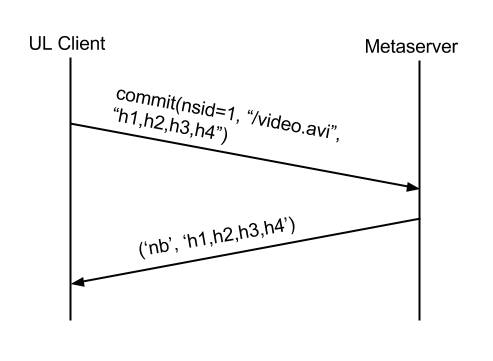
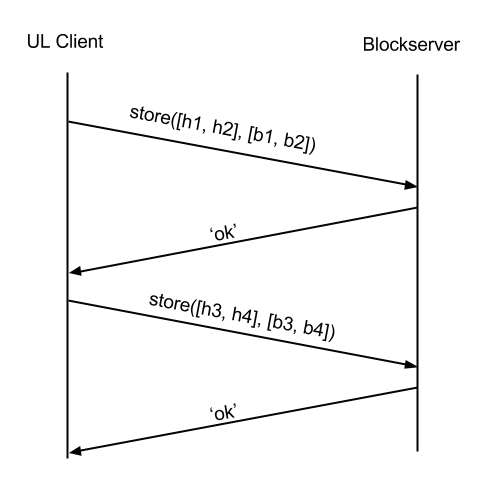
* In this diagram, there is a limit of 8MB, but we’ve experimented with other values as well.
Finally, the client attempts the commit again. This time, it should definitely work. The metaserver will update SFJ with a new row. Congratulations, the file officially exists in Dropbox!
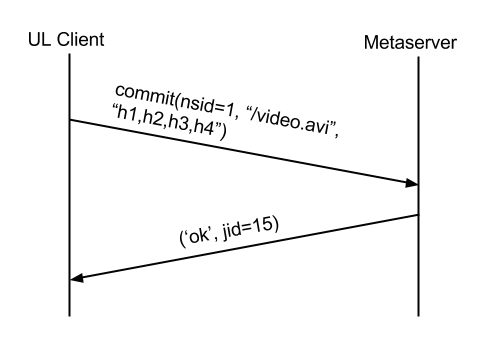

* Idle clients maintain a longpoll connection to a notification server.
Awesome. There’s a new file. We need to reconstruct the file from the blocks. The downloading client first checks to see if the blocks exist locally (within existing files, or in our deleted file cache). For new files, these checks likely fail, and the client will download directly from the blockserver. The blockserver verifies that the user has access to the blocks and provides them. Similar to store_batch, this may take multiple requests.
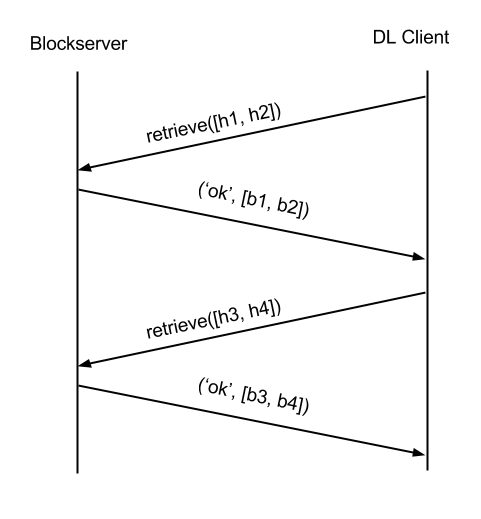
Now that the client has all the blocks, it can reconstruct the file and add it to the local file system. We’re done! We just demonstrated how a single new file is synced across clients. We have separate threads for sniffing the file system, hashing, commit, store_batch, list, retrieve_batch, and reconstruct, allowing us to pipeline parallelize this process across many files. We use compression and rsync to minimize the size of store_batch/retrieve_batch requests.
To sum up the process, here’s the whole thing on one diagram:

Streaming Sync
Typically, for large files, the sync time is dominated by the network time on calls to store and retrieve. The store_batch calls must occur before the SFJ commit. The list call is only meaningful after the SFJ commit. However, retrieve_batch’s dependency on commit is unnecessary. This pointed us toward an optimization which we call Streaming Sync. We want to overlap work on each of the clients. Ideally the downloading client could always be just one blockserver network call behind the uploading client.

High Level Changes
Protocol changes
Metaserver changes
We decided to store the additional state in memcache rather than a persisted table. It is not vital that this data persists, and we chose not to incur the additional cost of writing to a table on a failed commit. The memcache entry looks very similar to an SFJ row, except it is versionless. Thus there is no need for a JID.
Writes to memcache occur on failed calls to commit
Reads from memcache occur on list
Deletes occur on successful calls to commit (or memcache evictions)
Client changes
Great we’re done!
Nope. Not quite. There’s a few more things left to discuss. We’ve only talked about the “normal” case where a file actually completes being uploaded. We need to make sure that even if the file never completes commit, we don’t break the process. Imagine starting an upload and changing your mind midway. We need to make sure that the server side memcache expires entries and does not thrash. Furthermore, we need the DL client’s prefetch cache to be purged periodically and intelligently so it does not grow unbounded.
When accessing blocks, we check validity against the memcache table, but since memcache entry may be mutated, unavailable, expired, or even evicted during the prefetch, we need to arrange fallback behavior on the client when the server cannot verify that a block is eligible for streaming sync. This involved adding special return codes to the store protocol to indicate this condition.
How much does streaming sync help?
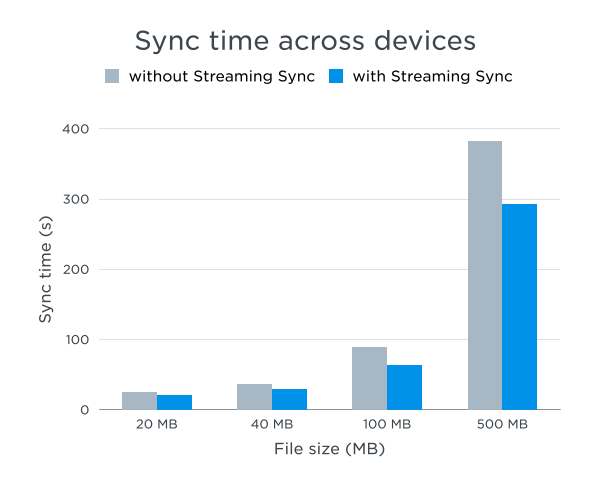
We found that streaming sync only affects files that are large enough to require multiple store/retrieve requests, so we limited the feature to large new files. Streaming sync provides an up-to-2x improvement on multi-client sync time. The improvement approaches 2x as the file’s size increases given equal UL/DL bandwidth, but in practice, the speedup is limited by the slower side of the connection. We did a test across two machines with the same network setup, (~1.2 mb/s UL, ~5 mb/s DL). There is an approximately 25% improvement on sync time.
| File Size (MB) | Sync time (s) with streaming sync | Sync time (s) without streaming sync |
| 20 | 21 | 25 |
| 40 | 30 | 37 |
| 100 | 64 | 89 |
| 500 | 293 | 383 |
As we roll out this feature to the world, we’ll be tracking key metrics like number of prefetched blocks, size of the prefetch cache, and memcache hit/miss rates.
Is it released?
You can find client side support for streaming sync in beta version 2.9 of the desktop client and stable version 2.10. We plan to roll out server side support over the course of the next couple of weeks. If you’re excited about sync performance work like this, we're hiring!


