

The AI features in Dropbox bring together company knowledge from documents, messages, meetings, and other sources. Users can then ask questions in one place and get answers from the Dash chat agent. Agent quality—how well our chat agent helps users accomplish their goals—is evaluated using a suite of large language model-as-judge evaluations. These evaluations provide a way to measure how well an agent is performing and identify opportunities to improve. Rather than judging only a final response, they inspect the full trajectory an agent takes to satisfy a user’s goal: how it interprets intent, gathers context, uses tools, handles ambiguity, grounds its answer, and completes the task.
We built agent evaluations as the foundation for improving the chat agent. These evaluations are the powerhouses behind the judges that measure the chat outcomes, given the context available to the agent, including relevance, reasoning quality, evidence use, robustness, task completion, and alignment with user asks. Once we had that foundation, we used DSPy to turn evaluation into improvement. DSPy is an open-source framework for optimizing AI systems using evaluation feedback.
We applied DSPy and its optimization algorithms in two stages. First, we used it to improve the judges themselves, calibrating them against a small set of human-labeled examples so their scores better matched human judgment. Then, we used those improved judges to optimize the chat agent’s system prompt. This created a feedback loop: human labels improved the judges, the judges produced scalable evaluation signals, and those signals improved the agent. As a result, users saw significantly fewer incomplete answers and we were able to reduce our token usage too, without compromising answer quality.
In this story, we’ll explain how we set up the evaluation layer, calibrated judges against human labels, applied DSPy—along with its optimization algorithms such as GEPA and MIPROv2 to improve judge performance—and then used those judges to optimize the chat agent itself.
Agent evaluation is significantly more complex than traditional search relevance evaluation because the object being judged is no longer a single, isolated output. Instead, it is the result of a multi-step process. The agent must interpret user intent, gather context, and decide when and how to use tools. It also needs to synthesize information across sources before determining whether to answer directly, search for more information, summarize its findings, or ask for clarification.
This makes evaluation much broader. A good agent response might depend on multiple knowledge sources, including documents, prior messages, meeting notes, or tool calls such as search and read documents. The quality of the final answer depends not only on what information was found, but also on how the agent approached the task.
Agent interactions can also unfold across multiple turns. The system may need to clarify an ambiguous request, incorporate user feedback, revise its answer, or continue searching as the task evolves. As a result, evaluation cannot focus only on the final response. It must also assess the decisions that led there.
Because an agent is made up of multiple interacting components, each part of that process needs its own evaluation. We have to assess not just answer quality, but also intent understanding, tool use, context selection, synthesis, grounding, turn-by-turn adaptation, and overall task completion. Evaluating these dimensions separately helps us identify where failures occur and improve the underlying components more effectively.
This raised an important challenge: before we could use evaluations to improve the chat experience, we first needed to ensure the judges themselves were reliable.
Calibrating judges with human labels
To evaluate chat responses, we needed an LLM judge that could assess an answer in the context of the user’s intent. But before we could trust those judges, we needed to know whether their evaluations aligned with human judgment. That meant starting with a small set of human-labeled examples and an evaluation rubric that engineers could apply consistently.
We sampled a set of internal chats, including the final responses and trace logs showing how the agent arrived at them, then asked human evaluators to review each example across five dimensions: user intent following, semantic relevance (how well the answer addressed the user's request), tool calling, instruction following, and context selection. Together, these dimensions capture what makes a chat agent valuable. They measure whether the agent understands the user's goal, gathers the right context, uses its tools effectively, follows instructions, and ultimately produces a grounded, useful response.
To keep assessments consistent, evaluators followed a structured review process. They first determined whether the agent understood the user’s intent and selected the right context. They then reviewed the searches, retrievals, and other tool actions used to gather that information before checking whether the claims in the final response were supported by the selected evidence. Finally, they scored the response for relevance, grounding, completeness, and instruction following.
Several metrics were scored on a 1–5 scale. Evaluators also recorded reasoning notes explaining their scores and assigned failure codes for issues such as stale evidence, missing context, unsupported claims, incomplete coverage, or failure to personalize. The reasoning notes captured why a response succeeded or failed, while the failure codes provided a structured way to categorize recurring problems.
This richer supervision proved especially valuable. A score provides a useful summary, but the reasoning notes and failure codes reveal what went wrong and where. They can show whether the agent misunderstood the user’s intent, selected the wrong context, made a poor tool decision, missed an instruction, or produced an answer that was only partially relevant. That gave us signal not just on response quality, but on the underlying causes of failure.
These annotations were useful to optimize the judge’s prompts to minimize disagreements between the LLM judge and the human labelers, but they were also useful beyond judge training. Annotations also helped with debugging, error analysis, roadmap planning, and prioritizing improvements to the agent system. Most importantly, they gave us a reliable benchmark against which we could measure and improve the judges themselves.
From evaluating agents to improving them
With the rubrics and labeled data in place, we could begin improving the judges themselves. Our goal was to make the judges agree more closely with human evaluators while preserving the structured evaluation process. Doing so required more than a generic scoring prompt. The judge needed to follow a specific workflow (retrospectively, or reviewing traces after the chats ended): infer the user's intent, inspect the conversation, review the trace and supporting evidence, reason about context selection and tool use, and then assign a score along with failure codes and reasoning notes.
To improve judge performance, we used DSPy and optimization algorithms such as GEPA and MIPROv2. Think of DSPy as the toolkit, and GEPA and MIPROv2 as specific algorithms within that toolkit. These algorithms automatically proposed prompt changes and tested them against our human-labeled examples to identify improvements.
We supported several optimization strategies. In some cases, we allowed DSPy to rewrite a judge's instructions from the ground up. In others, we adapted an existing judge to a different underlying model while preserving the same evaluation behavior. We also supported targeted optimization, where the goal was to correct specific failure modes, such as over-scoring outdated information or underweighting missing context, without changing the overall rubric or evaluation process.
Regardless of the optimization strategy, we relied on both scores and textual feedback from human evaluators. The scores told us when a judge disagreed with humans, while the feedback helped explain why. For example, if a judge consistently gave high scores to answers that relied on outdated information, we could update its instructions to better recognize and penalize that failure mode. Once we had judges that reliably reflected human judgment, we could use them as the foundation for improving the agent itself.
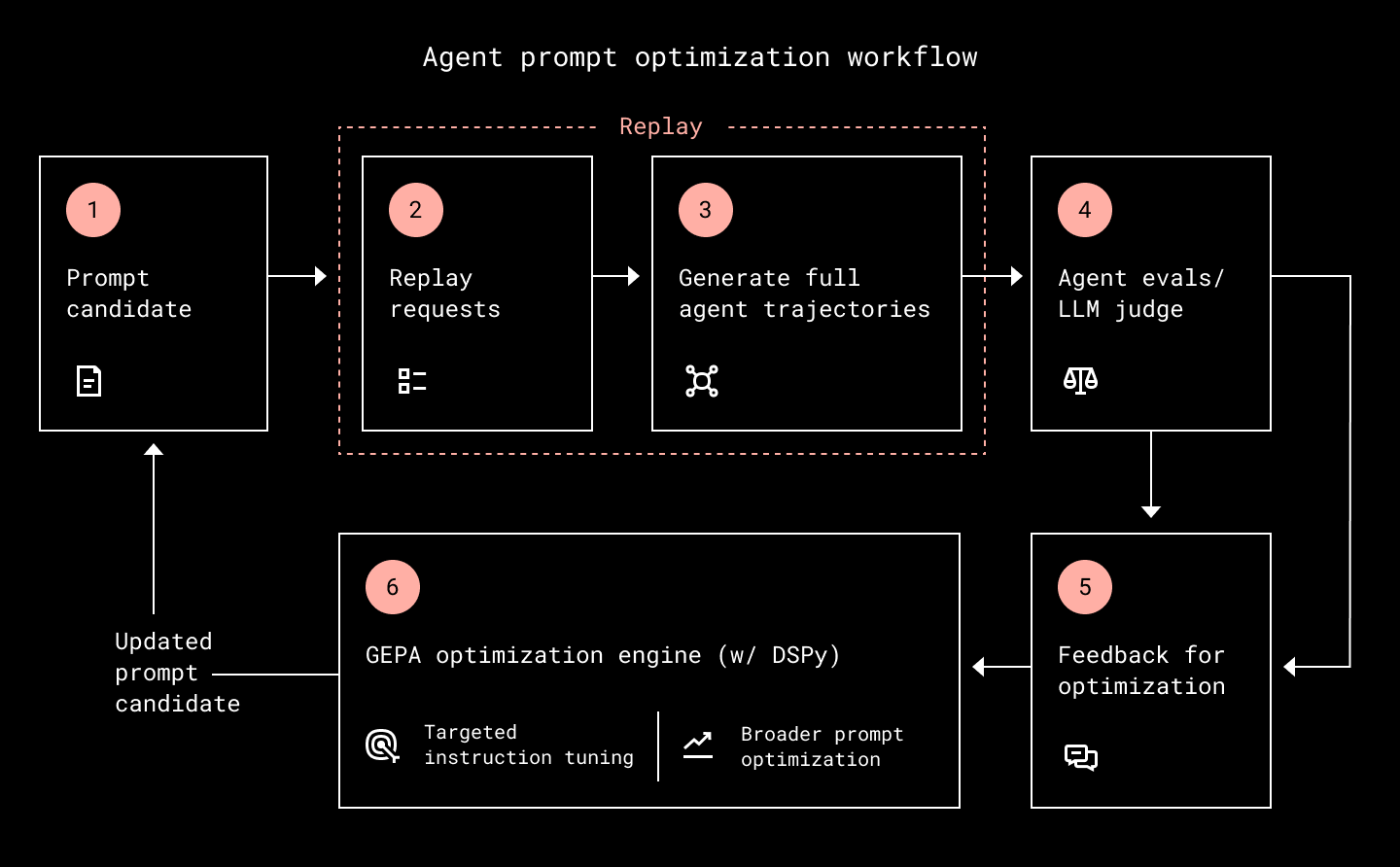
Our chat agent’s prompt optimization used to be a largely manual process. Engineers reviewed failures, proposed prompt edits, tested them, and iterated. While this helped in individual cases, it was difficult to scale and hard to know whether a change would reliably improve production quality. We replaced that workflow with an automated, evaluation-driven loop built on labeled examples, production-aligned scorers, and offline counterfactual replay. For each GEPA round, a candidate prompt is replayed on representative historical Dropbox internal chats, and the resulting agent outputs are scored by the evaluation pipeline. Those scores, along with structured judge reasoning, become the feedback signal GEPA uses to propose the next prompt update.
This grounds prompt optimization in realistic agent behavior rather than abstract examples or ad hoc judgments. The same replay infrastructure used to diagnose production failures is now part of the optimization loop itself, so each candidate is evaluated against representative interactions before being considered for launch. Optimization focused on concrete failure modes, including wrong context selection, incomplete answers, missed ambiguity, incorrect search-tool use, and loss of multi-turn context.
The result was a tighter feedback loop. We replayed representative examples, scored them with production-aligned evaluators, used those scores to guide the next GEPA proposal, and repeated the process until the data supported a launch candidate.
Faster iteration and better quality
To measure the impact of this prompt optimization work, we focused on failure modes tied to semantic relevance and answer quality. (As mentioned earlier, semantic relevance measures whether the agent understood the user's request and addressed the right parts of it.) Answer quality measures whether the response was complete, useful, grounded, and well-formed. In practice, this meant tracking issues like incomplete answers and missed key aspects of a user's request.
For each new prompt, we compared its performance against the existing production prompt using the same set of examples. This gave us a cleaner apples-to-apples comparison and made it easier to determine whether a prompt change actually improved performance. We also tested whether the gains were statistically meaningful.
We used statistical tests to check whether the observed improvements were likely to reflect a real change, rather than random variation in the evaluation results. The optimization loop increased experimentation velocity. In the first two weeks, we generated six prompt candidates automatically, compared with five manual prompt changes in the prior month, nearly doubling the pace of exploration.
The launch results were measurable: a 26% reduction in incomplete answers and a 13% reduction in missed key aspects, with improvements appearing within the first 24 hours. The optimized agent also became more efficient. Total token usage dropped by 5.4%, while average completion length decreased by 9.8%. Importantly, these efficiency gains did not come at the expense of answer quality.
Together, these results show how agent evaluations and DSPy can create a practical feedback loop for improving agent behavior: identifying failure modes, generating candidate prompts, validating quality gains, and reducing serving costs.
What’s next
One of the biggest lessons from this work is that automated prompt optimization needs strong guardrails. We intentionally constrained most agent prompt edits to small, targeted instruction updates and added automated review checks for prompt structure, completeness, caching behavior, and size limits. These safeguards helped ensure that candidate prompts remained maintainable and production-safe as the optimization process became more automated.
More broadly, this experiment showed that prompt optimization brings traditional machine learning discipline to prompt engineering. By combining human-labeled evals, representative replay data, and GEPA-based optimization in DSPy, we treated prompts as measurable, optimizable artifacts rather than static instructions. This framework gave us a systematic way to search over the instructions, constraints, examples, and policies that shape model behavior, helping us move beyond intuition and manual iteration to identify failure modes, compare improvements, and validate impact before launch.
Longer term, agent optimization may look less like manual prompt iteration and more like a continuous machine learning workflow: replay representative data, run optimization jobs, compare candidates against evaluation datasets, review evidence, and ship validated improvements. As with traditional ML systems, weak evaluation signals can lead to brittle improvements, while strong evaluations, representative data, and expert review help changes generalize and keep regressions under control.
The broader takeaway is that agent optimization works best when automation is paired with rigorous evaluation. Reliable judges, representative replay data, and clear success metrics create the feedback loop needed to improve agent behavior while keeping quality measurable and regressions under control.
Acknowledgments: Jongmin Baek, Josh Wilson, Akshay Bapat, Gonzalo Garcia, April Liu, Eric Wang, Hans Sayyadi, Prasang Upadhyaya, and Emeka Okafor Jr. We’re also grateful to the DSPy community for their engagement and support. Our DSPy collaborators offered guidance, discussions, and responsiveness as we applied DSPy to real production systems at Dropbox.
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit jobs.dropbox.com to see our open roles.


