

Dropbox Dash brings your files, messages, and team’s knowledge together in one place, so you can ask questions and get useful answers that are actually grounded in your company’s context. Under the hood, that experience relies heavily on one deceptively simple capability: reliably judging which results are relevant to a query at scale. Relevance judges are used across multiple pipelines like ranking, training data generation, and offline evaluation. Without systematic optimization, they can become a primary source of regressions, cost blowups, and loss of trust as models change.
Making a relevance judge work in production is harder than it looks. A prototype might lean on a state-of-the-art model, but real systems have latency and cost budgets, which usually means migrating to smaller or cheaper models. The catch is that prompts often don’t transfer cleanly across models. We ran into this while scaling our LLM-as-a-judge work: manual prompt tuning got us to a functioning judge, but quality plateaued early and every model swap—or even a small prompt edit—risked regressions in unexpected cases.
To address prompt brittleness and scale up relevance label generation for the long tail of candidates, we brought in DSPy. DSPy is an open-source framework for systematically optimizing prompts against a measurable objective, turning a manual, fragile process into a repeatable optimization loop. In this article, we’ll show how we defined that objective, used DSPy to adapt our judge across models, and made the judge both cheaper and more reliable in production.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
How to measure agreement with humans
Before we can improve a relevance judge, we need a clear definition of what “good” means. At its core, the judge’s job is straightforward: given a query and a document, it assigns a relevance score from 1 to 5, where 5 indicates a perfect match and 1 indicates no meaningful connection to the query and user intent. To evaluate how well the judge performs, we compare its scores to those assigned by human annotators performing the same task.
In our evaluation dataset, humans are shown a query and a candidate document and asked to rate its relevance on that same 1–5 scale. They also provide a short explanation describing why they chose that score. These human judgments serve as our reference point. For more details on the annotation process, see our LLM-as-a-judge blog. (Dropbox conducts these reviews with limited, non-sensitive internal datasets; no customer data is reviewed by humans as part of this process.)
We then measure how far the model’s ratings deviate from the human ratings using normalized mean squared error (NMSE), a metric that summarizes the model’s average disagreement with humans as a single number. If a human assigns a 5 and the model assigns a 4, that’s a small disagreement; if the human assigns a 5 and the model assigns a 1, that’s a much larger one. NMSE captures those differences across the entire dataset by computing the average squared gap between the model’s score and the human score, scaled to a 0–100 range. An NMSE of 0 indicates perfect agreement, while higher values indicate worse alignment.
We also account for structural reliability. The judge’s output is formatted as JSON; if the model returns broken JSON or fails to follow the expected structure, that output cannot be parsed and therefore cannot be used. In those cases, we treat the response as fully incorrect. These formatting failures aren’t cosmetic: if the output cannot be read, examples may be dropped, batches can fail, and evaluation metrics become unreliable.
Taken together, this framework gives us a clear and measurable objective: minimize disagreement with human relevance judgments while ensuring that outputs remain consistently usable in production systems. That’s the objective DSPy optimizes against.
Adapting our relevance judge for large-scale use
Our best-performing relevance judge was built on the most powerful proprietary model at the time (OpenAI’s o3). It produced high-quality scores and aligned closely with human ratings, but it was expensive to run at scale. As Dash grew, we needed to score orders of magnitude more query–document pairs. Running the most expensive model for every judgment wasn’t sustainable. We wanted to move to a lower-cost, open-weight model that we could run at scale.
We chose gpt-oss-120b, an open model that offered a strong balance between cost and performance. In simple terms, it was much cheaper to run, but still capable of following complex instructions. The problem was that our carefully tuned prompt for o3 did not transfer cleanly. When we applied it to the cheaper model, quality dropped under our evaluation metric. Manual prompt rewriting could eventually recover performance, but it would require weeks of iteration and regression chasing. Instead of starting over by hand, we used DSPy to systematically adapt the judge to the new model.
How DSPy helped us adapt the judge
We already had everything needed to define the problem clearly. The task was fixed: given a query and a document, assign a relevance score from 1 to 5. The dataset was fixed: human-annotated examples with ratings and explanations. And the metric was fixed: NMSE, which measures how far the model’s ratings deviate from human ratings.
DSPy allows you to define that setup—task, data, and metric—and then systematically search for prompt variants that improve performance on that metric. We used DSPy’s GEPA optimizer (a method that iteratively improves prompts by analyzing where the model disagrees with humans and generating feedback) to adapt and optimize the relevance-judging program for a specific target model—in this case, gpt-oss-120b.
Rather than treating evaluation as a single score, GEPA generates structured feedback for each example where the model disagrees with a human annotator. In our case, we combined the size and direction of the gap with the human explanation and the model’s reasoning, producing concrete signals about what went wrong and why.
This feedback powers the DSPy reflection loop. The prompt is evaluated, its failure modes are surfaced in plain language, the prompt is revised, and the cycle repeats—all while directly optimizing against the human-alignment metric defined earlier. Instead of trying to infer improvements from a single number, the system can respond to specific patterns, such as underweighting recency relative to the human explanation or overvaluing keyword matches. To make this more concrete, here is a simplified version of how we construct that textual feedback:
diff = predicted_rating - expected_rating
direction = "higher" if diff > 0 else "lower"
feedback_parts = [
f"Predicted rating {int(predicted_rating)} but expected {int(expected_rating)}.",
f"Model rated {abs(diff):.0f} point(s) {direction} than the expected human rating.",
]
# Include human explanation if available
if gold.explanation:
feedback_parts.append(f"Human rationale: {gold.explanation}")
# Include model's explanation for comparison
if pred.explanation:
feedback_parts.append(f"Model's reasoning: {pred.explanation}")
feedback_parts.append(
"Remember: when adapting the prompt, avoid overfitting to specific
example(s). Do not include exact examples or keywords from them in the prompt.
Also ensure you do not change the basic parameters of the task (e.g. changing the
rating range to be anything but 1-5). Try to add a general rule to an execution
plan to rate similar documents in the future."
)
feedback = "\n".join(feedback_parts)There were important caveats. In early experiments, we observed that the optimizer could overfit by copying specific keywords, usernames, or verbatim document phrases directly into prompts. That behavior improved performance on the training examples but did not generalize. To address this, we added explicit guardrails to forbid direct inclusion of example-specific content. We also found that candidate prompts sometimes modified key task parameters, such as changing the rating scale from 1–5 to 1–3 or 1–4. Additional constraints ensured that the task definition remained stable throughout optimization.
With this setup in place, we could move beyond intuition and measure the impact directly. Because the task, dataset, and metric were fixed, we could compare the optimized prompt to our original manually tuned prompt under identical conditions. That gave us a clear view of what changed and by how much.
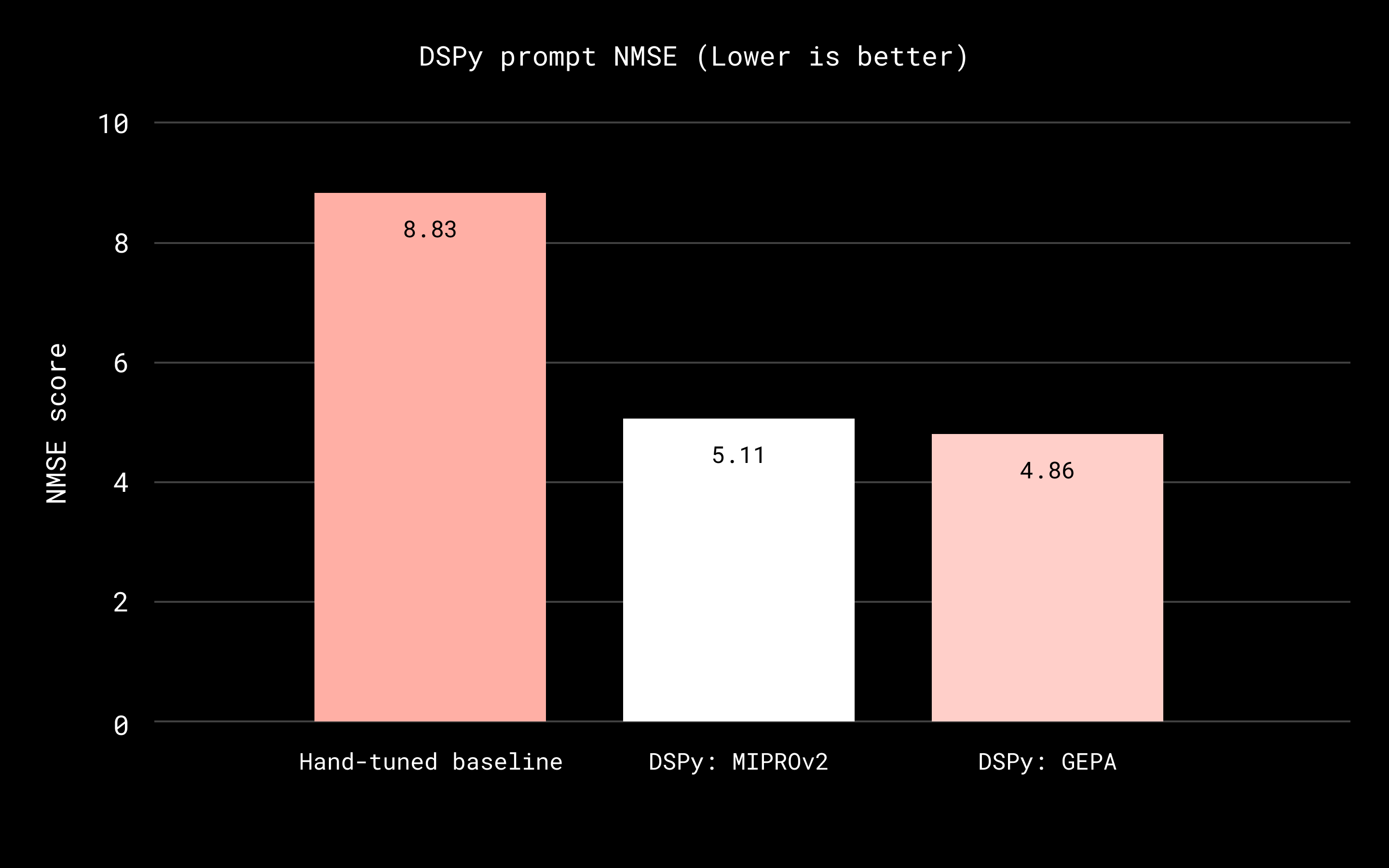
Comparing the best-performing DSPy-optimized prompt to the original manually written prompt, we reduced NMSE by 45 percent (from 8.83 to 4.86). That means the judge’s scores tracked human ratings much more closely, increasing our confidence in using it for evaluation and training signals. Model adaptation time dropped from one to two weeks of manual iteration to one to two days. That allowed us to swap in newly released models with less regression risk and keep the judge aligned with evolving product needs.
Because the optimized judge could run on a much cheaper model than our production o3 judge, we were also able to label 10–100 times more data at the same cost. That increased coverage and statistical power, enabled larger experiments, and reduced the risk of downstream models overfitting to a small evaluation set. Those results showed that DSPy could preserve quality while dramatically reducing cost.
However, optimizing for cost and human alignment still leaves an important question: can the judge behave reliably when its outputs are consumed programmatically in automated pipelines? In Dash, the relevance judge doesn’t run in isolation. It sits inside systems that score large candidate sets, generate training data, and run offline simulations. That means its outputs aren’t just read by people; they’re parsed and acted on by other components. This introduces a second requirement: operational reliability.
Improving operational reliability
When we talk about judge quality, it’s easy to focus only on how closely the model’s scores match human ratings. But in practice, the judge also has to consistently produce JSON outputs that downstream systems can read and use.
To stress test this dimension of reliability, we introduced gemma-3-12b, a much smaller and cheaper model. Smaller models reduce cost and enable broader scaling, but they are more brittle about formatting and instruction-following. By adapting our judge to a significantly smaller model, we could measure and directly optimize what was effectively the system’s weakest link: whether a low-cost judge could produce valid, machine-readable outputs consistently enough to be usable in Dash’s pipelines.
In the baseline configuration, more than 40 percent of gemma-3-12b’s responses were malformed JSON. Under our evaluation rules, those responses were treated as fully incorrect. This meant that even before considering alignment with human ratings, the judge was unreliable from an operational standpoint. After DSPy optimization, malformed outputs dropped by more than 97 percent, and NMSE improved substantially:
| Version | NMSE | Valid Response Format | Invalid Response Format |
|---|---|---|---|
| Original Prompt (Baseline) | 46.88 | 498 | 358 |
| DSPy prompt (MIPROv2) | 17.26 | 847 | 9 |
This result showed that DSPy was not only improving alignment with human judgments, but also strengthening structural reliability. Even a smaller, weaker model could become operationally dependable when optimized against the right objective.
At the same time, this experiment reinforced another benefit of the approach: iteration speed. Although gemma-3-12b was ultimately too weak for our highest-quality production judge paths, DSPy allowed us to reach that conclusion quickly and with measurable evidence. Instead of prolonged debate or manual trial and error, we could test the model directly against our evaluation framework and make a confident decision.
Incrementally improving our o3 model
One finding emerged across our explorations: DSPy let us control the scope of changes, from small prompt edits to broader adjustments. When adapting to a new, cheaper model (like gpt-oss-120b or gemma-3-12b), we were comfortable with full prompt rewrites, prioritizing broad exploration and end-to-end optimization. But when the target was our production o3 judge—already strong and widely depended on—the constraint flipped. Our goal was to make targeted improvements without destabilizing behavior relied on across multiple pipelines.
When it came to optimizing the o3-based judge, we weren’t starting from scratch. We already had a high-performing baseline. Large prompt rewrites were too risky; even small wording changes could shift behavior in corner cases, and the blast radius was high. So instead of rewriting the prompt end-to-end, we limited changes to a small, predefined set of safe edits.
We introduced an instruction library layer to make prompt improvement more targeted and easier to control. When we found cases where the judge’s score differed substantially from the human rating, humans wrote short explanations describing what the judge misunderstood and what it should have paid attention to instead. We then distilled those explanations into single-line instruction bullets, or small, reusable “rules of thumb” the model can follow. In this setup, the optimization module is responsible only for selecting the best bullet-instructions. DSPy can’t rewrite the entire prompt from scratch; instead, its job is to choose which instruction bullets to include (e.g. select common themes of errors), and how to combine them, so the prompt grows by assembling the most helpful additional guidance rather than be constantly rewritten.
This turned optimization into something closer to “small PRs with tests” than a large-scale refactor: improvements were incremental, regressions were easier to diagnose, and we could keep the baseline behavior stable while still pushing agreement upward.
For example, if a disagreement was explained as “the document is older than a year, so it’s less relevant for this query,” we translated that into a bullet like: “Documents older than a year should be rated at least one point lower unless they are clearly evergreen.” DSPy could then learn whether including that bullet improved alignment on the eval set without unintended side effects.
We can see the cumulative effect of these incremental changes in the evaluation results below:
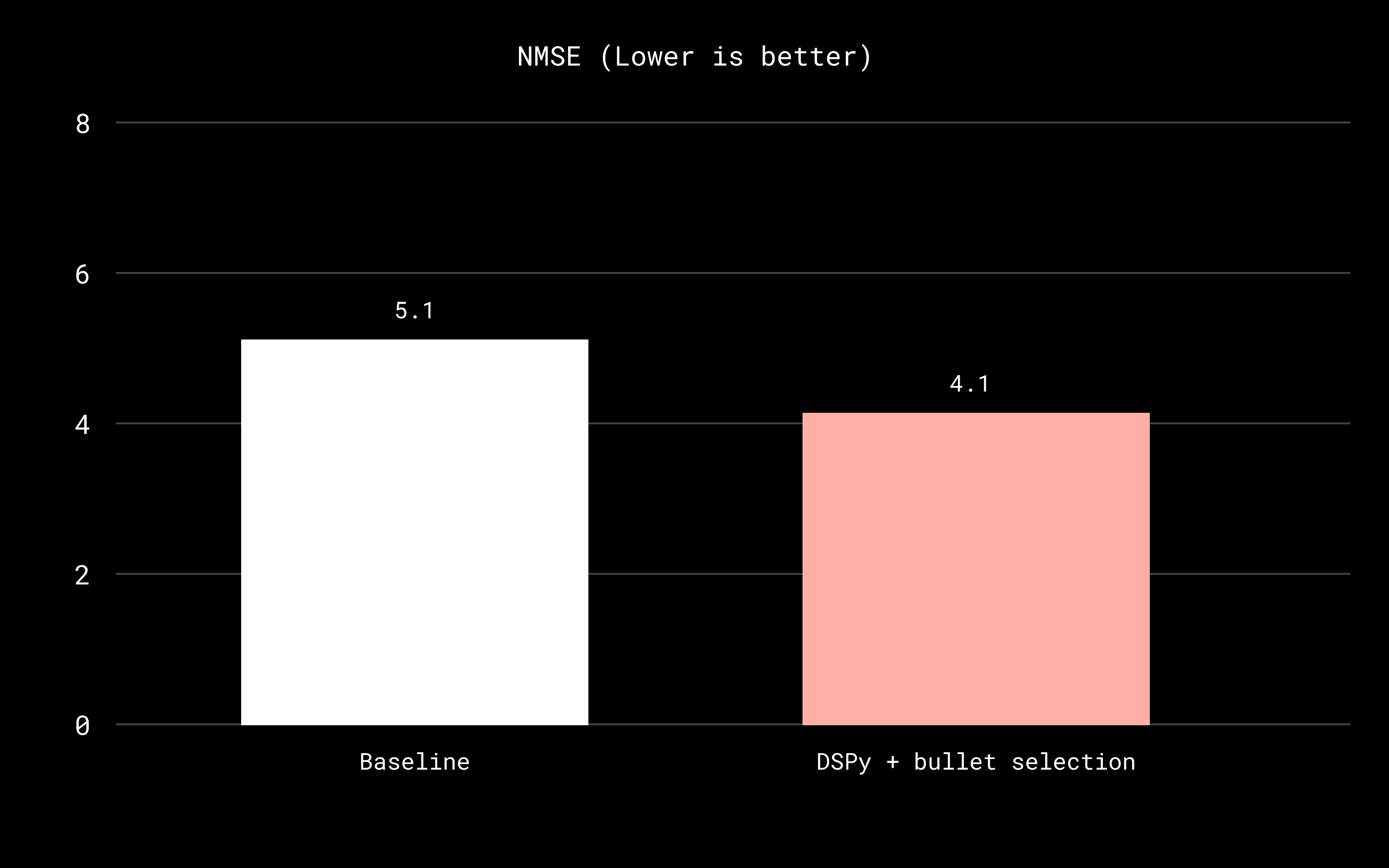
Each step represents a small, testable change, but together they produce a substantial improvement over the initial prompt.
Conclusion
In Dash, relevance scoring is a core capability that shapes ranking, training data generation, and offline simulation. Because it sits at the center of multiple pipelines, even small changes in how we score relevance can ripple outward. If every new model or prompting idea requires manual prompt surgery, progress becomes slow and risky.
With DSPy, we define the objective—alignment with human relevance judgments—and systematically optimize toward it. With the task and dataset held fixed, we can swap in new models and adapt them quickly, with measurable evidence instead of intuition. The workflow becomes less about rewriting prompts and more about improving against a clear metric. Just as importantly, DSPy lets us choose how to improve depending on our risk tolerance. We can run full end-to-end optimization when exploring new, cheaper models, or apply constrained, incremental updates when stability matters for production systems like o3.
In a system like Dash, where relevance scoring touches ranking, training data generation, offline simulation, and cost–latency tradeoffs, prompt optimization can’t be a one-off effort. DSPy turns it into a repeatable loop: define the task, measure against human labels, optimize, and ship changes with confidence as models evolve.
Acknowledgments: This work was made possible by close collaboration across Dropbox. We’d like to thank Eider Moore, Mingming Liu, Stella Xiang, Sean Chang, Prasang Upadhyaya, Hans Sayyadi, and Josh Clemm for their thoughtful reviews, technical feedback, and help shaping both the system and the story.
We’re also grateful to the DSPy community for their engagement and support. In particular, we‘d like to thank Isaac Miller, Drew Breunig, Lakshya A. Agrawal, and Omar Khattab for their guidance, discussions, and responsiveness as we applied DSPy to real production systems at Dropbox.
Dropbox hosted a Bay Area DSPy Meetup at our San Francisco office on Wednesday, March 18, 2026, bringing together developers building real-world, in-production AI systems. Dropbox engineers shared how we’re using LLM judges and DSPy to optimize prompts and improve reliability in production. Head here to view our presentation from the event.
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit jobs.dropbox.com to see our open roles.


