

Dropbox offers several AI-assisted features to help users with tedious organizational tasks. In a recent story we discussed naming conventions. Here, we’ll discuss another feature, smart move, that grew from a need to help users—particularly administrators—more quickly and easily organize large numbers of files.
Released in November 2021, smart move uses machine learning to analyze a user’s existing subfolder structure and suggest folders where they might want to move their files. For example, you can drop a bunch of unorganized files into your home directory with existing folders, and smart move will try to place the files you added in the correct subfolders. A user can quickly scan these suggestions, starting with the highest priority changes, and decide what they want to move and where. Smart move can move multiple files at a time, all with one click, reducing tedious work about work.
Because most users consider file organization a very personal and custom task, we focused on assisting rather than replacing manual organization patterns. We leveraged a human-in-the-loop workflow, prioritizing likely useful moves front-and-center, while still allowing the user full control to reject, change, or accept ML suggestions. This setup was also good for experimentation; we could test a potential ML solution to an organization problem and quickly see how users responded.
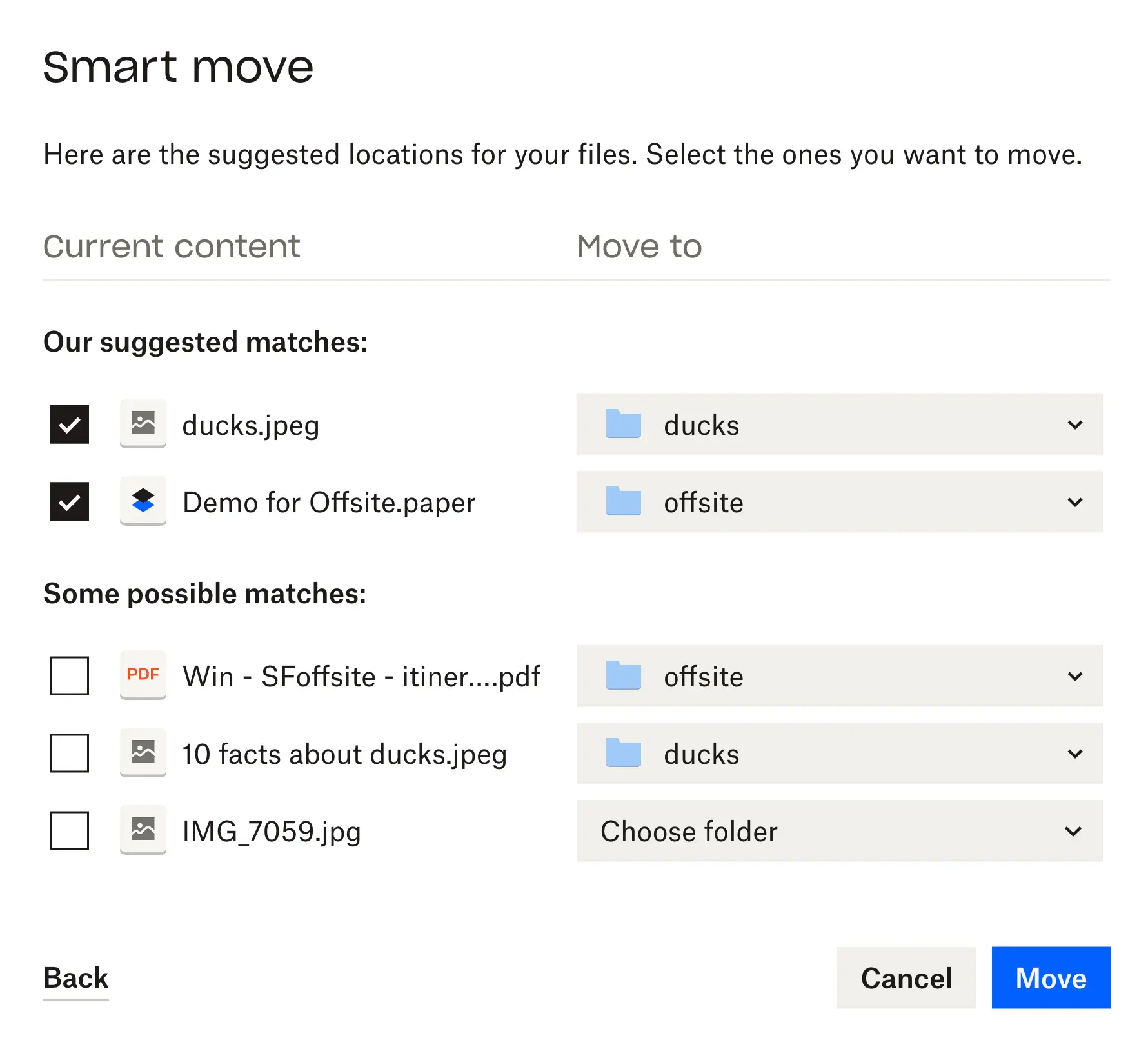
Smart move’s human-in-the-loop modal
To limit complexity, our initial experiment focused only on files in a chosen folder that could be moved to a subfolder. While this limited the potential scope of the feature, it provided a constrained use case that fit the “tidying up” persona we wanted to help.
Prior to smart move, users of Dropbox on the web had to move files one at a time, perhaps opening and scanning many potential folders the file could be moved to. With all these manual steps, tidying up a folder could seem daunting. By integrating ML and a new UX flow into the move experience, we hoped to make organization easier.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
What does an organized folder mean?
The biggest challenges with prototyping smart move were not actually related to ML model development at all! The greatest lessons learned were in product design and understanding user needs. Only then could we translate user needs into an ML problem with a potential feature solution.
Organization is very personal. In our research, multiple users said they were wary of allowing other people—even people they work with—to organize their Dropbox contents or move their files around. One user was concerned about being unable to find their files if they were wrongly moved or renamed. Any automation would need to keep our users in control, allowing them to approve, edit, or reject any suggestions we made.
A second challenge was the various ways in which different users organize their files. What does an “organized” folder mean? Organization looks different for different people. For example:
| Type of organization | Examples |
|---|---|
| Organization by theme |
|
| Organization by workstream |
|
| Organization by source |
|
There are many ways to organize, and we relied on user research focused on Dropbox on the web—versus Dropbox users on desktop or mobile—to identify cases we wanted to tackle first. We acknowledged early in the project that we were unlikely to have a model that performed well in all these scenarios; a successful automation would require us to narrow our approach.
We had to solve some additional challenges as well:
- Because filenames are sensitive information, Dropbox engineers cannot manually review these records for developing hypotheses about organization. Instead, we got permission from Dropbox employees to use files in our company Dropbox instance. To handle this sensitive data, we had to develop new workflows and data storage solutions to ensure that sensitive data did not mix with other data (for model training, for example) and that only a limited set of team members could review the data shared by Dropbox employees for a pre-defined period of time.
- Identifying appropriate datasets to proxy files and filenames was an initial hurdle to get across. Because there are so many modes of organizing and many, many edge cases, a non-trivial amount of time was spent selecting, filtering, and generating data we wanted to use for training. Multiple rounds of data validation and cleaning were needed as we discovered new cases. For example, many organized folders were auto-generated from desktop applications; these directories were then synced to Dropbox. While prime examples of organization, auto-generated files were not part of the use case we targeted.
- Smart move’s UX flow serves recommendations synchronously, since the user triggers the workflow and must wait for a response. Longer response times degrade user experience, so latency and performance optimization were critical. (We covered some common steps and mitigations we took to improve model latency, in our naming conventions blog post.)
When model reuse doesn’t work
From 2018 to 2019, the Dropbox user research team conducted interviews with power users around issues of organizing files in Dropbox on the web. We relied on this research to form our hypothesis for how recommendations can assist in file organization.
Of the different types of organizers who responded to our call for user research, one persona that stood out was the organizer for teams. This is a Dropbox user, such as a team manager or company administrator, who is responsible for organizing their own and others’ files. Typically, this person spends a large amount of time renaming or moving files the team creates to clean up content and make sure it is better stored or findable by the team. Based on the detailed user research and some iteration on mockups, we settled on a design similar to the finalized feature.
To quickly validate our hypothesis internally, we built a prototype of smart move by repurposing a model from a prior experiment, suggested destinations. This model leveraged a user’s recent activity and filenames to provide a single suggested folder destination for one file at a time. But when we gave the prototype to select Dropbox employees who offered to be our helpful testers, we discovered several reasons to use a new heuristic or model for our experiment rather than repurposing an old one:
- Testers expected suggestions to be the same or similar for the same set of files. The suggested destinations model did not guarantee deterministic results, as suggestions were based off the user’s most recent activity. If a user requested a suggestion within a folder, then navigated to some other folders before returning to the original folder to request a suggestion again, the results could be drastically different in non-obvious ways based on their recent navigation.
- Internal testers desired clarity around how smart move suggestions are made. The model did not produce results that met user expectations based on file and folder name relationship. Testers indicated that if they were asked to organize a folder, they rely on filenames, and only occasionally would they look at file contents.
- Given the sheer number of files in some folders, dividing suggestions for each file into high and medium confidence helped focus testers on the changes that were most likely to improve their organization.
Sometimes, being able to play with a prototype as if it were already an in-production feature highlights specific and unexpected needs. We highly recommend ML practitioners create low-overhead prototypes for testing, as our testers gave a large amount of feedback in using the feature that we did not uncover through user research interviews. With this feedback, we turned to developing a new model that better met needs, since model reuse did not provide a good solution in this case.
Developing a new model
Developing a new model for smart move posed an interesting question: How would we generate a credible dataset for something that hasn’t happened yet? In other words, how could we predict how a user would most likely organize a folder full of files before that user has organized the files themselves?
Answer: Find existing folders that look like they are already organized, and treat them as the labelled end state of a (theoretical) successful smart move action.
## Existing folder structure (desired end state)
root
|
+---- folder_A/
| |
| +---- file_1.pdf
|
+---- folder_B/
| |
| +---- file_2.pdf
|
+---- folder_C/
|
+---- file_3.jpg
+---- folder_D/
+---- folder_E/
|
+---- file_4.pdfThis file structure can be broken down into a hypothetical pre-move case, which can be used as training data. Using this method, we gleaned several million suitable training examples from our internal data alone (Dropbox employees use Dropbox for work… a lot).
## (file to move, candidate folder name, correct/incorrect label)
(file_1.pdf, folder_A, 1)
(file_1.pdf, folder_B, 0)
(file_1.pdf, folder_C, 0)
(file_2.pdf, folder_A, 0)
(file_2.pdf, folder_B, 1)
(file_2.pdf, folder_C, 0)
(file_3.pdf, folder_A, 0)
(file_3.pdf, folder_B, 0)
(file_3.pdf, folder_C, 1)
(file_4.pdf, folder_D, 0)
(file_4.pdf, folder_E, 1)We iterated on what signals the model used, trying to settle on the smallest set that could be quickly retrieved on-the-fly, yet still give reasonable performance, such as:
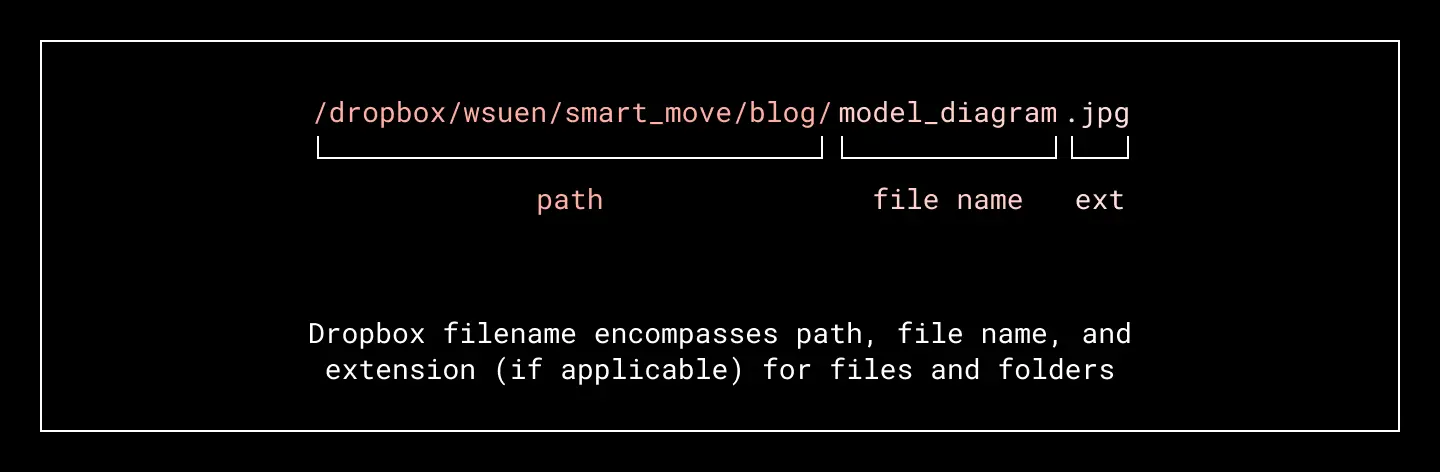
- The name of the file being tidied (including file extension).
- The name of each candidate folder.
- The names of files/folders within each candidate folder. These are potential siblings of the file we’re making a smart move suggestion for (they share the same parent/candidate folder as the file being tidied). Often the files within a folder (say, w-2.pdf, taxreturn_2020.pdf, charitable.img, 2019taxes.pdf) give more insight into the correct organizational intent than the folder name (which could be something like finance).
We launched internally with two options: a filename similarity heuristic, and a trained model. Our heuristic baseline was a simple similarity heuristic based on name similarities. We also tested a simple neural network model. From the raw signals, we tested a variety of engineered signals (including optional features we ended up discarding) and model iterations (label smoothing, changing architecture, weighting, etc). What follows is the final model architecture that worked well enough for testing.
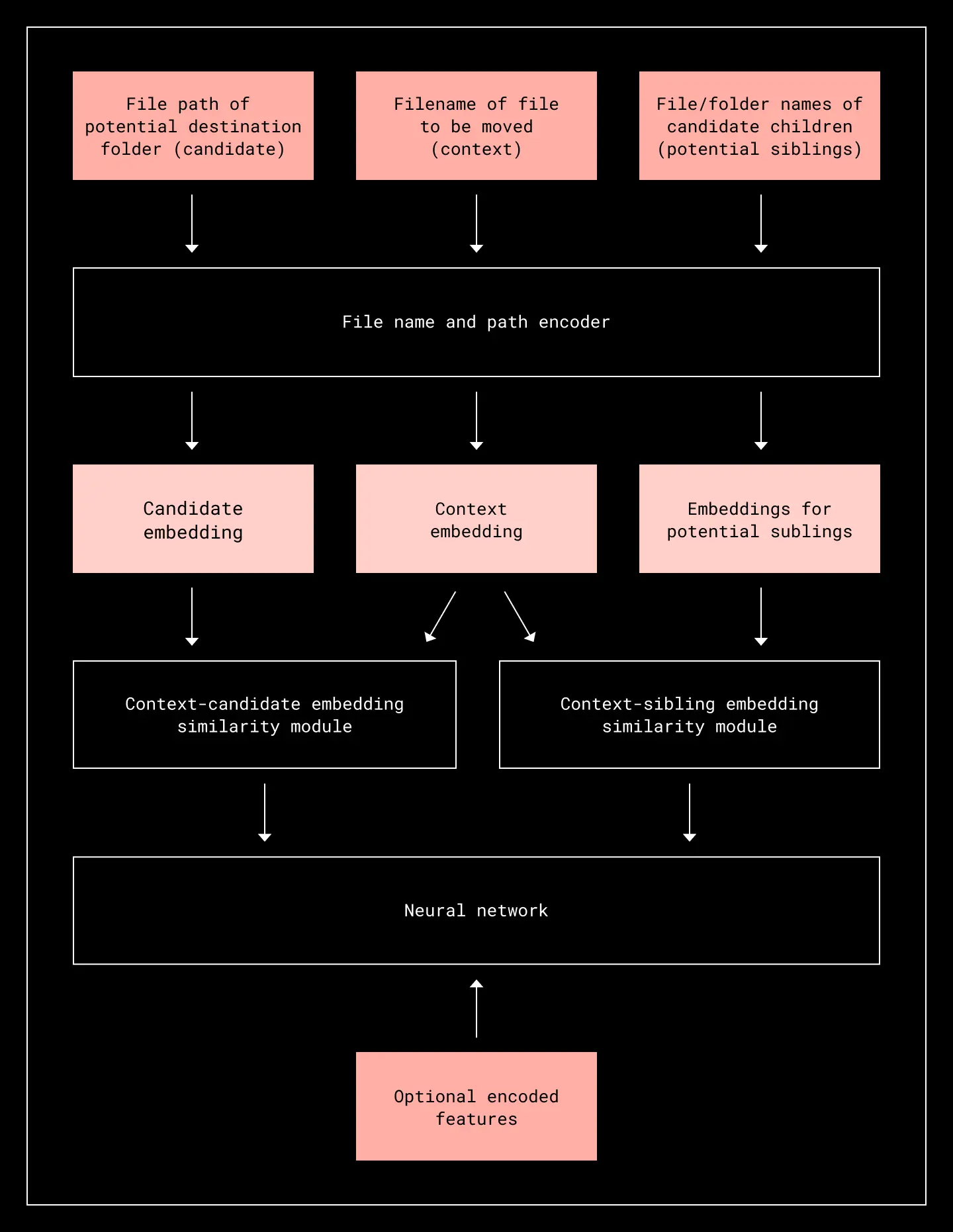
Architecture of the base model
First, we tokenized the name of the file being moved (we also call this the context), candidate folder names, and names of potential sibling files and folders. The tokenized names were then passed to an in-house encoder we developed which used character-level and GloVE word-level embeddings. The encoder encodes file/folder names into an embedding space that lets us determine similarity based on various tokens in the file, semantic similarity, and file types (for example, understanding that png, jpg, and img are all image types, or that pdf can be an image or document type). The embeddings also let us leverage similarities between classes of documents, like financial reports (which may contain tokens like tax, w-2, receipt) versus marketing assets (press release, marketing copy).
Using the embeddings for the context file, candidate folder, and potential siblings, we computed similarity matrices for context-to-candidate and context-to-siblings. We did some basic feature engineering on the similarity features, as well as some optional encoded features from other sources (such as selective weighting for certain types of files and folders we wanted to penalize more heavily) before passing all the features into a deep neural network. We tested a variety of different architectures, but the one we landed on used <20 hidden layers with dropout.
The model produced a score for each file to move/candidate folder pair. We ranked each candidate destination for a file based on this score, and the top ranked candidate was considered the suggested sub-folder recommendation for that file. The score was also used to identify high and medium-confidence recommendations—using a simple cutoff at first, so only the top 20% of recommendations by score distribution were considered high-confidence and displayed to the user most prominently. Medium-confidence suggestions were less front-and-center, but still presented for users to select in the human-in-the-loop review screen before any file moves are made. The entire bottom tranche of recommendations were considered low-confidence and not shown at all.
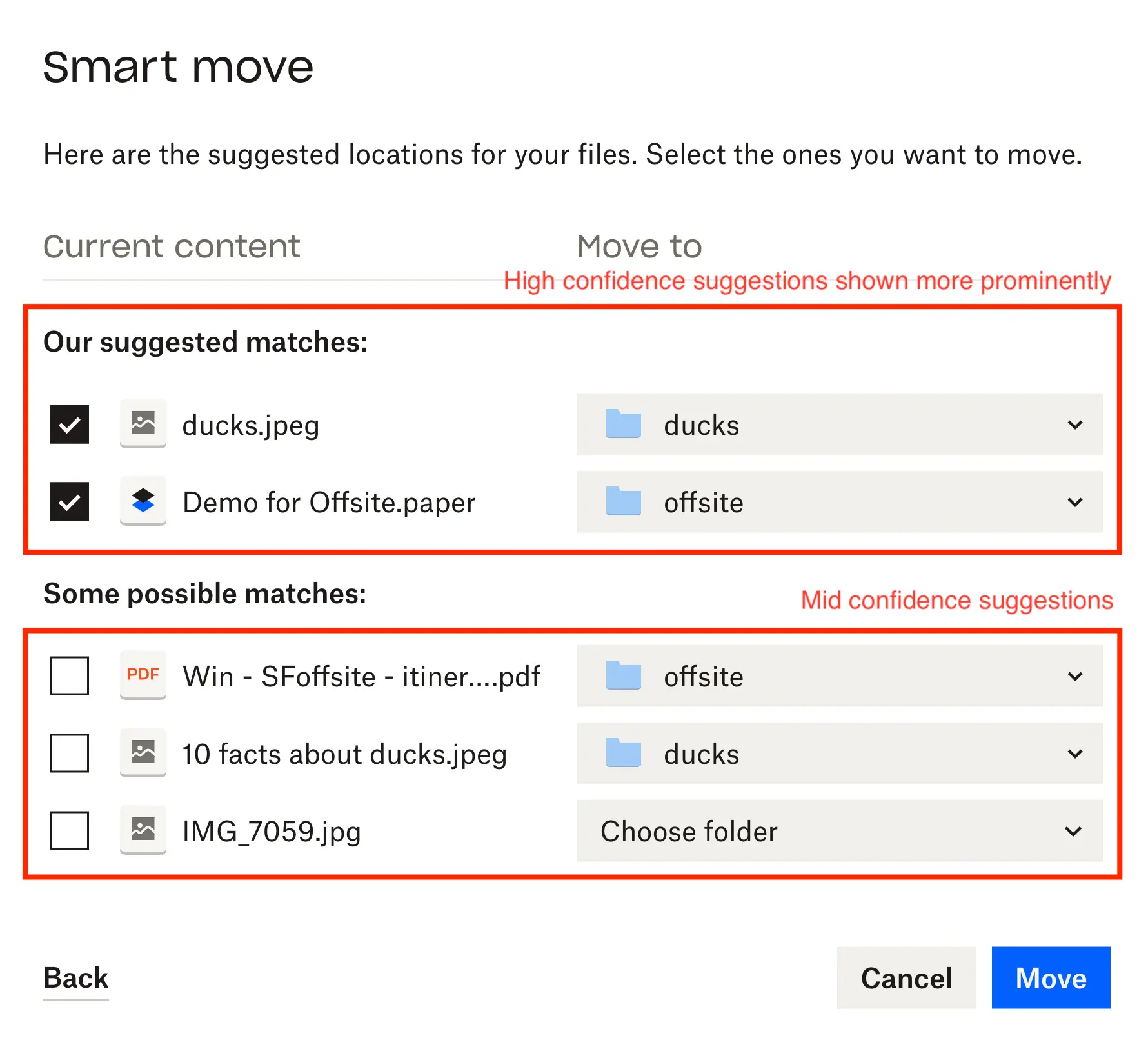
We relied on usage patterns from Dropbox employees interacting with our internal Dropbox instance. Because our dataset for internal testing only contained files from approved folders within Dropbox’s own enterprise account, we did small-scale manual review, and applied some data cleaning and filtration. This step was critical because even small scale review captured many undocumented assumptions about what smart move should do that were trip-ups for the proof of concept.
How did we do?
In an offline evaluation, the trained model edged ahead of the similarity heuristic in terms of accuracy of (file, candidate folder) pairs classified, which is not entirely surprising. We expected better performance if we could model more complex relationship between file and folder names (semantic relationships such as “a file with health insurance in the name may be related to a folder called Medical Docs”) as well as folder contents and extensions (“Vacation 2022 already contains many image types, so it’s a more likely destination for beach.png and summer_trip.jpg”). For both heuristic and model, including features from children (files and folders sharing the same candidate folder) boosted performance as we had hoped.
| Trained model | Similarity heuristic | |
|---|---|---|
| Evaluation dataset size | 57,921 files | 57,921 files |
| Trained model accuracy | 73% | 64% |
We then released smart move to internal users to determine how the feature performed and to get feedback. Unsurprisingly, the Dropbox employee results were fairly in-line with our offline evaluation on internal data, with our model once again outperforming the heuristic.
However, we still wanted to test the end-to-end flow of presenting suggestions in the UX before releasing to a limited external alpha. In our online alpha testing, the heuristic actually slightly outperformed the model. 61% of suggestions were accepted without changes, compared to 59% for the model. Looking only at the high confidence suggestions we show prominently to the user, over 94% of those suggestions from the heuristic were accepted! This is compared to 90% for the model.
| Similarity heuristic | Trained model | |
|---|---|---|
| Overall accuracy (high and medium confidence) | 61% | 59% |
| Accuracy of high confidence suggestions only | 94% | 90% |
These results are not entirely surprising as we may have overfit on the internal Dropbox organization use cases, which did not necessarily match what users prioritized for organization. However, it wasn’t all wasted effort as we were able to reuse the same model for other feature prototypes—and in these other scenarios it outperformed the heuristic.
What we also learned was that accuracy wasn’t the only measure of the quality of our predictions. User perception matters too. In some cases, a recommendation might be technically a good fit for a folder, but still look wrong to the user. Or, even when a set of recommendations might look correct, another less seemingly correct folder was ultimately the better choice, based on where the user eventually moved their files.
As we continue to improve our smart move model, we are working on how to quantitatively measure ease of use and interpretability in a way that captures all the qualitative feedback we’ve received on suggestions.
In conclusion…
Each experiment we conduct furthers our knowledge of how ML can be used to improve the Dropbox user experience, especially for tedious and repetitive tasks like file organization. Smart move yielded many lessons in prototyping features for organization recommendations. We took the work we did for smart move and pivoted to making it a reusable capability for quick prototyping, and kicked off research into consolidating the best features of smart move into legacy models like suggested destinations.
After smart move, we reused the model for rapid prototyping of other Dropbox experiments, such as destination suggestions on file ingest for the Save-to-Dropbox browser extension, or on bulk upload in Dropbox on the web. Both these cases were new problems, as we had to provide folder destinations for files that were not in Dropbox yet! While we ultimately chose not to continue with this work, we learned that providing suggestions quickly, and using minimal data from the files being uploaded, was very important. Curiously enough, in those cases, the smart move model actually outperformed the smart move heuristic—a case where model reuse happened to work! This was likely because the model made better user of sparse information for files not yet uploaded to Dropbox, while the heuristic floundered when many fields were missing.
Going forward, there are two areas in particular we’re especially keen to explore:
- Alternative UX and workflow tools for organization. ML-assisted organization seems like a very promising field, especially for reducing toil for other personas outside the initial scope of team admin/organizer. At the same time, we need to be careful not to add too many extraneous processes or clutter to the user experience.
- Fine-tuning an LLM to compare performance. When work on the smart move model began in 2021, there were not as many frameworks to quickly leverage an LLM for this solution. We’re curious to see how the performance of an LLM would compare to our model, which has only been trained on internal Dropbox data—especially for non-English languages.
Acknowledgements: Thanks to Morgan Zerby and Tristan Inghelbrecht for product management support, as well as Theo Champlin, Mike Lyons, and Jiayi Zeng for their work on the human-in-the-loop content organization experience.
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


