

In our previous blog posts, we talked about how we updated the Dropbox search engine to add intelligence into our users’ workflow, and how we built our optical character recognition (OCR) pipeline. One of the most impactful benefits that users will see from these changes is that users on Dropbox Professional and Dropbox Business Advanced and Enterprise plans can search for English text within images and PDFs using a system we’re describing as automatic image text recognition.
The potential benefit of automatically recognizing text in images (including PDFs containing images) is tremendous. People have stored more than 20 billion image and PDF files in Dropbox. Of those files, 10-20% are photos of documents—like receipts and whiteboard images—as opposed to documents themselves. These are now candidates for automatic image text recognition. Similarly, 25% of these PDFs are scans of documents that are also candidates for automatic text recognition.
From a computer vision perspective, although a document and an image of a document might appear very similar to a person, there’s a big difference in the way computers see these files: a document can be indexed for search, allowing users to find it by entering some words from the file; an image is opaque to search indexing systems, since it appears as only a collection of pixels. Image formats (like JPEG, PNG, or GIF) are generally not indexable because they have no text content, while text-based document formats (like TXT, DOCX, or HTML) are generally indexable. PDF files fall in-between because they can contain a mixture of text and image content. Automatic image text recognition is able to intelligently distinguish between all of these documents to categorize data contained within.
Assessing the challenge
First, we set out to gauge the size of the task, specifically trying to understand the amount of data we would have to process. This would not only inform the cost estimate, but also confirm its usefulness. More specifically, we wanted to answer the following questions:
- What types of files should we process?
- Which of those files are likely to have “OCR-able” content?
- For multi-page document types like PDFs, how many pages do we need to process to make this useful?
The types of files we want to process are those that currently don’t have indexable text content. This includes image formats and PDF files without text data. However, not all images or PDFs contain text; in fact, most are just photos or illustrations without any text. So a key building block was a machine learning model that could determine if a given piece of content was OCR-able, in other words, whether it has text that has a good chance of being recognizable by our OCR system. This includes, for example, scans or photos of documents, but excludes things like images with a random street sign. The model we trained was a convolutional neural network which takes an input image before converting its output into a binary decision about whether it is likely to have text content.
For images, the most common image type is JPEG, and we found that roughly 9% of JPEGs are likely to contain text. For PDFs, the situation is a bit more complicated, as a PDF can contain multiple pages, and each page can exist in one of three categories:
- Page has text that is already embedded and indexable
- Page has text, but only in the form of an image, and thus not currently indexable
- Page does not have substantial text content
We would like to skip pages in categories 1 and 3 and focus only on category 2, since this is where we can provide a benefit. It turns out that the distribution of pages in each of the 3 buckets is 69%, 28%, and 3%, respectively. Overall, our target users have roughly twice as many JPEGs as PDFs, but each PDF has 8.8 pages on average, and PDFs have a much higher likelihood to contain text images, so in terms of overall load on our system, PDFs would contribute over 10x as much as JPEGs! However, it turns out that we could reduce this number significantly through a simple analysis, described next.
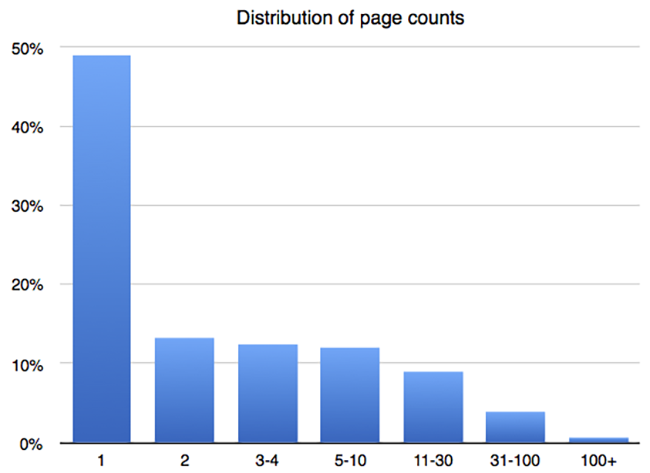
Total number of pages
Once we decided on the file types and developed an estimate of how much OCR-able content lived on each page, we wanted to be strategic about the way we approached each file. Some PDF documents have a lot of pages, and processing those files is thus more costly. Fortunately, for long documents, we can take advantage of the fact that even indexing a few pages is likely to make the document much more accessible from searches. So we looked at the distribution of page counts across a sampling of PDFs to figure out how many pages we would index at most per file. It turns out that half of the PDFs only have 1 page, and roughly 90% have 10 pages or less. So we went with a cap of 10 pages—the first 10 in every document. This means that we index almost 90% of documents completely, and we index enough pages of the remaining documents to make them searchable.
Automatic image text recognition system components
Rendering
Once we started the process of extracting text with OCR on all the OCR-able files, we realized that we had two options for rendering the image data embedded in PDF files: We could extract all raster (i.e. pixel) image objects embedded in the file stream separately, or we could render entire pages of the PDF to raster image data. After experimenting with both, we opted for the latter, because we already had a robust large-scale PDF rendering infrastructure for our file previews feature. Some benefits of using this system include:
- It can be naturally extended to other rendered or image-embedding file formats like PowerPoint, PostScript, and many other formats supported by our preview infrastructure
- Actual rendering naturally preserves the order of text tokens and the position of text in the layout, taking the document structure into consideration, which isn’t guaranteed when extracting separate images from a multi-image layout
The server-side rendering used in our preview infrastructure is based on PDFium, the PDF renderer in the Chromium project, an open-source project started by Google that’s the basis of the Chrome browser. The same software is also used for body text detection and to decide whether the document is “image-only,” which helps decide whether we want to apply OCR processing.
Once we start rendering, the pages of each document are processed in parallel for lower latency, capped at the first 10 pages based on our analysis above. We render each page with a resolution that fills a 2048-by-2048-pixel rectangle, preserving the aspect ratio.
Document image classification
Our OCR-able machine learning model was originally built for the Dropbox document scanner feature, in order to figure out if users took (normal) photos recently that we could suggest they “turn into a scan.” This classifier was built using a linear classifier on top of image features from a pre-trained ImageNet model ( GoogLeNet/Inception). It was trained on several thousand images gathered from several different sources, including public images, user-donated images, and some Dropbox-employee donated images. The original development version was built using Caffe, and the model was later converted to TensorFlow to align with our other deployments.
When fine-tuning this component’s performance, we learned an important lesson: In the beginning, the classifier would occasionally produce false positives (images it thought contained text, but actually didn’t) such as pictures of blank walls, skylines, or open water. Though they appear quite different to human eyes, the classifier saw something quite similar in all of these images: they all had smooth backgrounds and horizontal lines. By iteratively labeling and adding such so-called “hard negatives” to the training set, we significantly improved the precision of the classification, effectively teaching the classifier that even though these images had many of the characteristics of text documents, they did not contain actual text.
Corner detection
Locating the corners of the document in the image and defining its (approximately) quadrangular shape is another key step before character recognition. Given the coordinates of the corners, the document in an image can be rectified (made into a right-angled rectangle) with a simple geometric transformation. The document corner detector component was built using another ImageNet deep convolutional network ( Densenet-121), with its top layer replaced by a regressor that produces quad corner coordinates.
The test data for training this model used only several hundred images. The labels, in the form of four or more 2-D points that define a closed document boundary polygon, were also drawn by Mechanical Turk workers using a custom-made UI, augmented by annotations from members of the Machine Learning team. Often, one or more of the corners of the document contained in the training images lie outside of the image bounds, necessitating some human intuition to fill in the missing data.
Since the deep convolutional network is fed scaled-down images, the raw predicted location of the quadrangle is at a lower resolution than the original image. To improve precision, we apply a two-step process:
- Get the initial quad
- Run another regression on a higher-resolution patch around each corner
From the coordinates of the quad, it is then easy to rectify the image into an aligned version.
Token extraction
The actual o ptical c haracter r ecognition system, which extracts text tokens (roughly corresponding to words), is described in our previous blog post. It takes rectified images from the corner detection step as input and generates token detections, which include bounding boxes for the tokens and the text of each token. These are arranged into a roughly sequential list of tokens and added to the search index. If there are multiple pages, the lists of tokens on each page are concatenated together to make one big list.
Putting the pieces together
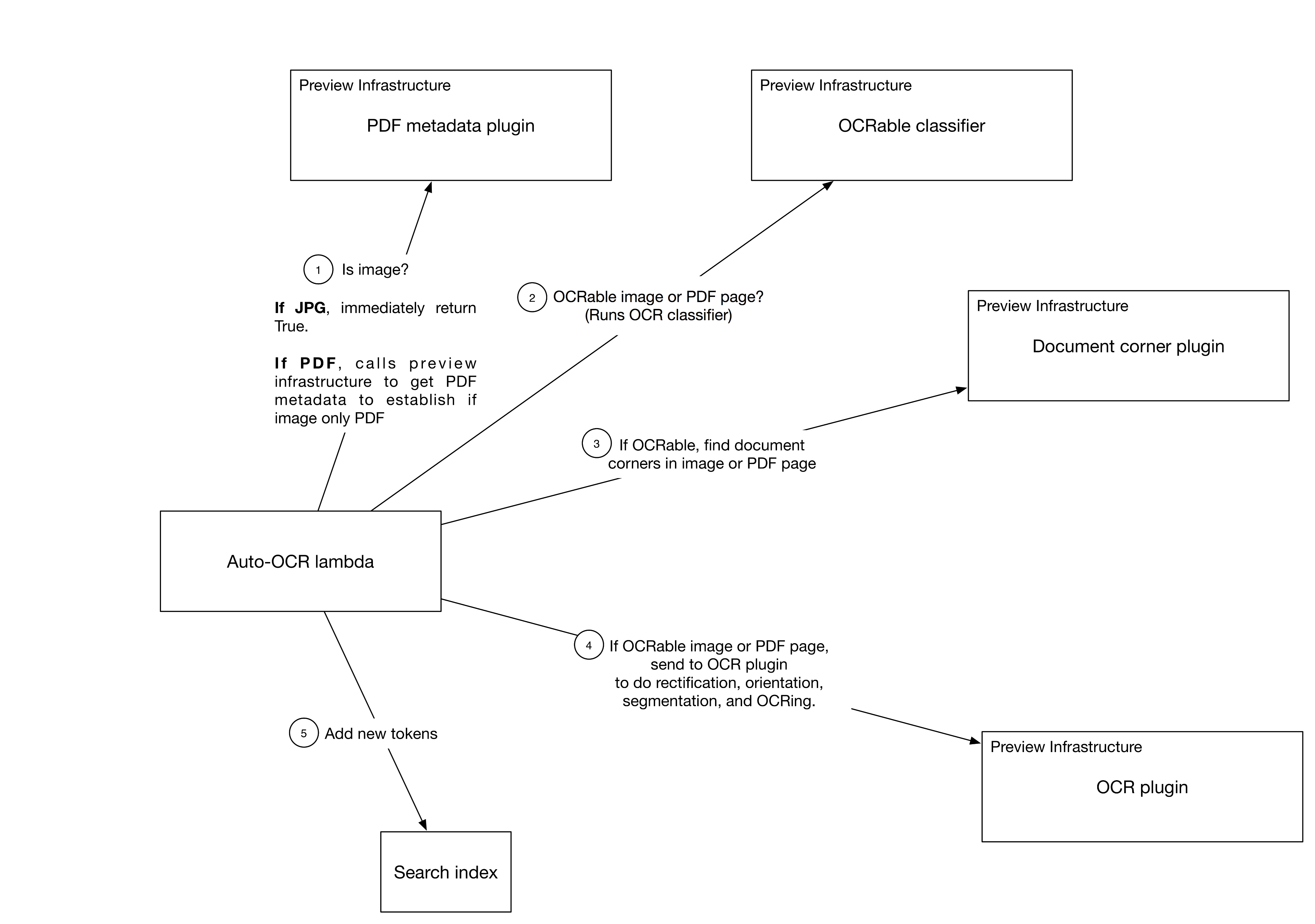
To run automatic image text recognition on all potentially indexable files for all eligible users, we need a system that can ingest incoming file events (e.g., adds or edits) and kick off the relevant processing. This turns out to be a natural use case for Cape, the flexible, large-scale, low-latency framework for asynchronous event-stream processing that powers many Dropbox features. We added a new Cape micro-service worker (called a “lambda”) for OCR processing, as part of the general search indexing framework.
The first several steps of processing take advantage of Dropbox’s general previews infrastructure. This is a system that can efficiently take a binary file as input and return a transformation of this file. For example, it might take a PowerPoint file and produce a thumbnail image of that PowerPoint file. The system is extensible via plugins that operate on specific types of files and return particular transformations; thus, adding a new file type or transformation is easy to do. Finally, the system also efficiently caches transformations, so that if we tried to generate a thumbnail image of the same PowerPoint file twice, the expensive thumbnail operation would only run once.
We wrote several preview plugins for this feature, including (numbers correspond to the system diagram above):
- Check whether we should continue processing, based on whether it’s a JPEG, GIF, TIFF, or PDF without embedded text and if the user is eligible for the feature
- Run the OCR-able classifier, which determines whether a given image has text
- Run the document corner detector on each image so we can rectify it
- Extract tokens using the OCR engine
- Add the list of tokens to the user-specific search index
Robustness
To increase robustness of the system in the case of transient/temporary errors during remote calls, we retry the remote calls using exponential backoff with jitter, a best-practice technique in distributed systems. For example, we achieved an 88% reduction in the failure rate for the PDF metadata extraction by retrying a second and third time.
Performance optimization
When we deployed an initial version of the pipeline to a fraction of traffic for testing, we found that the computational overhead of our machine learning models (corner detection, orientation detection, OCRing, etc.) would require an enormous cluster that would make this feature much too expensive to deploy. In addition, we found that the amount of traffic we were seeing flow through was about 2x what we estimated it should be based on historical growth rates.
To address this, we began by improving the throughput of our OCR machine learning models, with the assumption that increasing the throughput offered the greatest leverage on reducing the size of the OCR cluster we would need.
For accurate, controlled benchmarking, we built a dedicated sandboxed environment and command line tools that enabled us to send input data to the several sub-services to measure throughput and latency of each one individually. The stopwatch logs we used for benchmarking were sampled from actual live traffic with no residual data collection.
We chose to approach performance optimization from the outside in, starting with configuration parameters. When dealing with CPU-bound machine learning bottlenecks, large performance increases can sometimes be achieved with simple configuration and library changes; we discuss a few examples below.
A first boost came from picking the right degree of concurrency for code running in jails: For security, we run most code that directly touches user content in a software jail that restricts what operations can be run, isolates content from different users to prevent software bugs from corrupting data, and protects our infrastructure from malicious threat vectors. We typically deploy one jail per core on a machine to allow for maximum concurrency, while allowing each jail to only run single-threaded code (i.e., data parallelism).
However, it turned out that the Tensor F low deep learning framework that we use for predicting characters from pixels is configured with multicore support by default. This meant that each jail was now running multi-threaded code, which resulted in a tremendous amount of context-switching overhead. So by turning off the multicore support in TensorFlow, we were able to improve throughput by about 3x.
After this fix, we found that performance was still too slow—requests were getting bottlenecked even before hitting our machine learning models! Once we tuned the number of pre-allocated jails and RPC server instances for the number of CPU cores we were using, we finally started getting the expected throughput. We got an additional significant boost by enabling vectorized AVX2 instructions in TensorFlow and by pre-compiling the model and the runtime into a C++ library via TensorFlow XLA. Finally, we benchmarked the model to find that 2D convolutions on narrow intermediate layers were hotspots, and sped them up by manually unrolling them in the graph.
Two important components of the document image pipeline are corner detection and orientation prediction, both implemented using deep convolutional neural networks. Compared to the Inception-Resnet-v2 model we had been using before, we found that Densenet-121 was almost twice as fast and only slightly less accurate in predicting the location of the document corners. To make sure we didn’t regress too much in accuracy, we ran an A/B test to assess the practical impact on usability, comparing how frequently users would manually correct the automatically predicted document corners. We concluded that the difference was negligible, and the increase in performance was worth it.
Paving the way for future smart features
Making document images searchable is the first step towards a deeper understanding of the structure and content of documents. With that information, Dropbox can help users organize their files better—a step on the road to a more enlightened way of working.
Automatic image text recognition is a prime example of the type of large scale projects involving computer vision and machine learning that engineers at Dropbox tackle. If you are interested in these kinds of problems, we would love to have you on our team.
Thanks to: Alan Shieh, Brad Neuberg, David Kriegman, Jongmin Baek, Leonard Fink, Peter Belhumeur.


