

Over the past few years, server-side request forgery (SSRF) has received an increasing amount of attention from security researchers. With SSRF, an attacker can retarget a request to internal services and exploit the implicit trust within the network. It often escalates into a critical vulnerability, and in 2021 it was among the top ten web application security risks identified by the Open Web Application Security Project. At Dropbox, it’s the Application Security team’s responsibility to guard against and address SSRF in a scalable manner, so that our engineers can deliver products securely and with as little friction as possible.
On February 19, 2021, HackerOne user Kumar Saurabh reported a critical SSRF vulnerability to us through our bug bounty program. With this vulnerability, an attacker could make an HTTP GET request to internal endpoints within the production environment and read the response. After reproducing the vulnerability, we immediately declared an internal security incident, worked on a quick fix to close the hole, and pushed the fix to production in around eight hours. (We have no reason to believe this vulnerability was ever actively exploited, and no user data was at risk.)
Since most of our internal services speak gRPC, a modern RPC framework with built-in authentication mechanisms, communication over plain GET is not possible. This means an attacker’s access would be limited. Even so, based on our research into the potential impact, we calculated the bounty to be worth $27,000.
In this blog post, we will share how this particular vulnerability worked in practice, and what we did in response to substantially reduce the risk of SSRF attacks going forward.
The bug
Dropbox has a feature called branded sharing. This feature allows Dropbox teams and Pro users to upload a logo and background image that will populate across all their shared links and in-band shared emails.
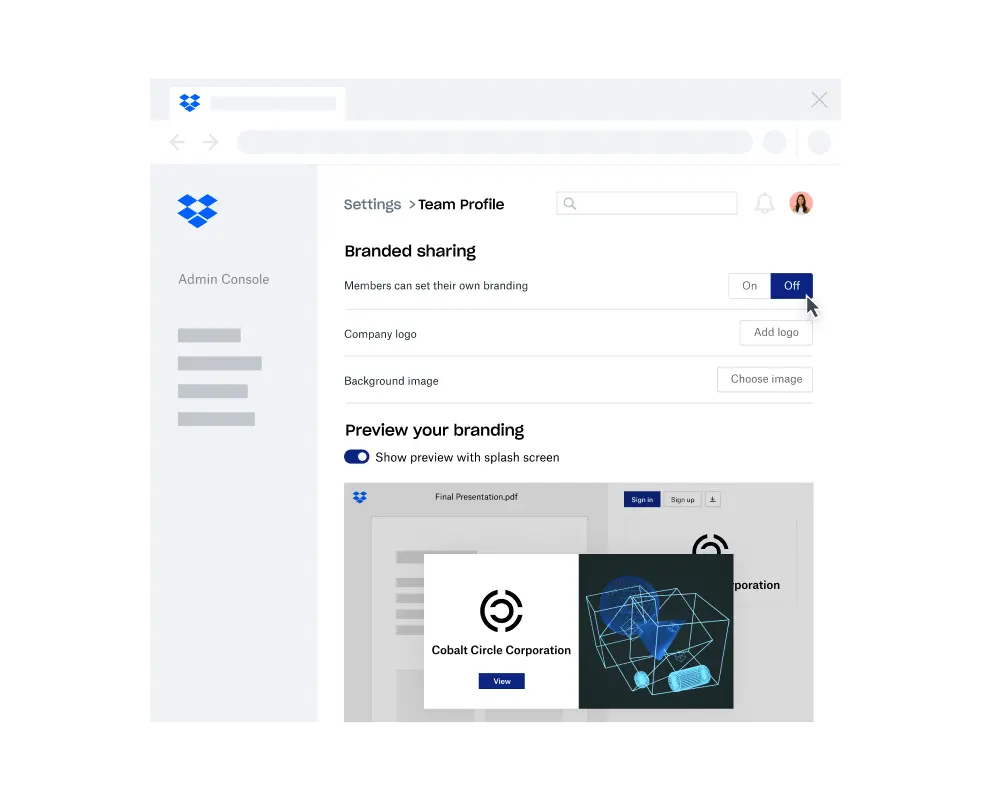
When configuring this feature, the client first makes a request to /team/admin/team_logo/save or /team/admin/team_background/save with an img_url argument. These endpoints then invoke curl to fetch the image data from the given URL. The given img_url is supposed to have dl-web.dropbox.com as the domain—and while we do validate the authority of the URL, differences in URL parsing between the two libraries we use and the lazy validation of our URL API left room for exploitation.
In practice, curl could be tricked into making requests to arbitrary URLs—including the internal network—and made to save the resulting data into a database. Then, the saved data could be read out from https://www.dropbox.com/team/team_logo/[dbtid] or https://www.dropbox.com/team/team_background/[dbtid].
Here is an illustration of the vulnerable code:
parsed_url = URI.parse(img_url)
if BLOCK_CLUSTER != parsed_url.authority:
raise HttpStatusBadRequestException()
conn, url = CurlConnection.build_connection_url(img_url)
response = conn.perform("GET", url)URI is a library we built to handle URI parsing, modification, construction, serialization, and some additional validation. It uses a regex to parse the URI according to RFC 3986 Appendix B with a slight modification to maintain compatibility with browsers. CurlConnection is another helper library we built for making requests with pycurl. Inside the build_connection_url, a standard Python library, urllib.parse, is used to parse the URL.
The inconsistent URL parsing left us open to the kind of SSRF vulnerability described in this Black Hat talk from 2017. An example payload is https://dl-web.dropbox.com\@<host>:<port>. Parsing it with the URI library will return the part before \@ as the authority and pass the check:
In [1]: URI.parse('https://dl-web.dropbox.com\@127.0.0.1:8080').authority
Out[1]: 'dl-web.dropbox.com'However, parsing it with urlsplit would treat the part after \@ as the hostname and direct the request to an attacker-specified address:
In [1]: urlsplit("https://dl-web.dropbox.com\@127.0.0.1:8080").hostname
Out[1]: '127.0.0.1'
The fix
The main goal of the URI class is normalization. Thus, if we apply str to the parsed_url, we can actually block the malicious payload because URI will conduct validation during the serialization and reject some uncommon patterns. The most straightforward fix would be:
parsed_url = URI.parse(img_url)
+try:
+ safe_url = str(parsed_url)
+except Exception as e:
+ raise HttpStatusBadRequestException()
if BLOCK_CLUSTER != parsed_url.authority:
raise HttpStatusBadRequestException()
-conn, url = CurlConnection.build_connection_url(img_url)
+conn, url = CurlConnection.build_connection_url(safe_url)But a slightly better solution is to construct the URL with the intended domain instead of verifying that the user input has a valid one. This way, we’re not making requests to a raw user-provided URL. This solution looks like:
try:
safe_uri = str(
URI(
scheme="https",
authority=BLOCK_CLUSTER,
path=args.path,
query=args.query,
)
)
conn, url = CurlConnection.build_connection_url(safe_url)
except Exception as e:
raise HttpStatusBadRequestException()Secure by default
After fixing the immediate vulnerability, a few teams came together in a postmortem meeting and discussed how we could reduce the risk of SSRF vulnerabilities across Dropbox even further. We decided to build a framework for making web requests that’s secure by default.
Our ultimate goal is to prevent outgoing HTTP requests from accidentally hitting internal private addresses. Theoretically, we can resolve a URL and check whether it belongs to the private address space, but there are some caveats:
- Inconsistent URL parsing. If the validation and the actual request library adopt different URL parsers, they might interpret a URL differently due to the ambiguity of the spec. An attacker can craft a polyglot URL to bypass validation.
- HTTP redirection. If we only validate the initial request, an attacker can redirect it to an internal address and bypass validation of subsequent requests.
- DNS rebinding. Suppose the validation and the actual request library each resolve a URL to an IP on their own. In this case, an attacker can return a safe IP in the first DNS lookup and a private IP in the second lookup to bypass validation.
To address these issues, we must ensure there is a central place to consistently parse URLs, validate IP addresses, and make the actual request—a place that can’t be bypassed.
Some libraries, such as Advocate, implement this in the application layer. At Dropbox, we deploy the mitigation in a lower network/proxy layer for the following reasons:
- We can have a central configuration. At Dropbox, we accomplish this with Envoy and an HTTP RBAC filter.
- We don't have to figure out a solution for every language we support.
- It covers third-party libraries or binaries, which we have no control over.
- We don't need to worry about discrepancies between a programming language’s URL parser and a request library’s URL parser.
- It is easier to configure customized, finer-grained ACLs for different purposes. For example, we have a proxy with a short list of allowed targets for requests to our corporate network, and we block some additional Dropbox assets from receiving webhook requests.
- We can enforce the usage of our proxy by blocking direct outgoing requests.
One final caveat is special protocols. If validation only happens for HTTP requests, an attacker can leverage URL schemes such as file://, gopher://, etc. to carry out the exploitation. (Note that some older libraries would follow the HTTP redirection to these special protocols, so only validating the initial request might again be insufficient.)
One solution would be to disable all protocols other than HTTP/HTTPS. Dropbox uses curl-based libraries, and we could do so by configuring the options such as CURLOPT_PROTOCOLS or CURLOPT_REDIR_PROTOCOLS. Instead we chose to recompile libcurl to get rid of other protocol supports because it is more bulletproof and easier to integrate with our system.
We had already adopted these defenses for our webhook requests. After this incident, we extended it to every outgoing request and migrated all incompatible use cases. Now, SSRF attacks can't target sensitive internal networks by default.
Further hardening
The above protection against SSRF is effective in isolating our internal network as a whole, but we wanted to take things a step further and reduce the attack surface in our production network, too. Most of our production services speak gRPC and have a default-deny access control policy, making them difficult to be exploited by SSRF attacks. However, to provide a safety net for anything that might fall through the cracks—such as an errant HTTP listener with sensitive capabilities—we aimed for a holistic solution that would meet our secure by default framework.
The project we came up with is called Auth Everywhere, which mandates that all connections in production should be authenticated, authorized, and auditable. To achieve this, we deployed a sidecar proxy along with an HTTP service to only accept mTLS connections from clients within the ACL. Auth Everywhere takes a defense-in-depth approach to handling SSRF vulnerabilities; it hardens our production infrastructure with the least privilege principle, and limits the impact of a production host being compromised in general.
Conclusion
SSRF has been one of our top concerns after we saw some novel techniques in recent talks. Thanks to the help of security researchers from our bug bounty program, we were able to fix the critical vulnerability detailed here before it could be exploited by bad actors. And in the process of fixing this particular case of SSRF, we used the opportunity to harden our systems more generally, substantially reducing the risk of SSRF going forward.
If being rewarded for finding vulnerabilities excites you, be sure to check out our bug bounty program. And if you want to build innovative products, experiences, and infrastructure, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


