

The Dropbox desktop client is relied on by millions of users across the world to save their most important files and keep them in sync across their devices. Weighing in at over 1 million lines of Python logic, we had a massive surface area for potential issues in our migration from Python 2 to Python 3. In this process, we knew that we had to be worthy of the trust that users place in Dropbox and keep their information safe.
Over the last few months, we’ve explored why and how we rolled out our Python 3 migration, and how we ensured that the resulting application was reliable. In this piece, we’ll take a brief walk through the history of Python 3 in our desktop client, and then dive into the details of how we pulled off a gradual migration while allowing ongoing development.
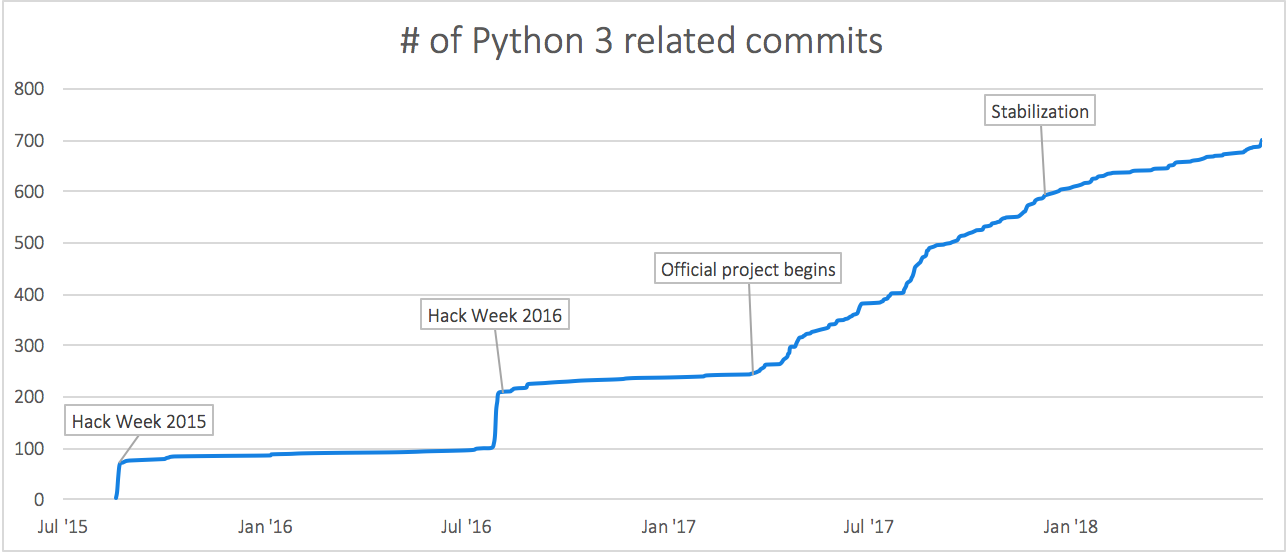
The Pioneers
Like many other great ideas at Dropbox, the effort to migrate the desktop client to Python 3 began during one of our annual Hack Weeks. The phrase thrown around internally to describe this week-long event is “getting back to our roots”—five days where everyone at Dropbox puts aside their daily responsibilities to work in small, fast-moving teams to tackle exciting or interesting problems.
Hack Week 2015
This was the start of it all—an intrepid team of Dropboxers decided to see how far they could take Python 3 in the desktop client. In the spirit of Hack Week, they managed to hack together a version of the desktop client that could sign in and sync some files while running Python 3.
Problem solved? Not quite. Unfortunately, it was clear that many features were completely broken by the upgrade. Some changes that were compatible with both Python 2 and Python 3 were merged, however, much of the work was eventually thrown away.
Hack Week 2016
A new team formed during this Hack Week with the goal of making more permanent steps towards Python 3. Armed with Mypy, a static type-checking tool that we had adopted in the interim year, they made substantial strides towards enabling the Python 3 migration:
- Ported our custom fork of Python to version 3.5
- Upgraded some Python dependencies to Python 3-compatible versions, and forked some others (e.g.
babel) - Modified some Dropbox client code to be Python 3 compatible
- Set up automated jobs in our continuous integration (CI) to run the existing unit tests with the Python 3 interpreter, and Mypy type-checking in Python 3 mode
Crucially, the automated tests meant that we could be certain that the limited Python 3 compatibility that existed would not have regressed when the project was picked up again.
Python 3rd time’s the charm
By early 2017, it had become clear that upgrading Python versions was in the critical path for several toolchain upgrades, and the multi-month-long project to migrate to Python 3 was officially staffed.
Prerequisites
Before we could begin working on migrating any of our application logic, we had to ensure that we could load the Python 3 interpreter and run until the entry point of the application. In the past, we had used “freezer” scripts to do this for us. However, none of these had support for Python 3 around this time, so in late 2016, we built a custom, more native solution which we internally referred to as “Anti-freeze” (more on that in the initial Python 3 migration blog post).
With that taken care of, we were ready to get started on the application itself.
1. Incrementally enabling unit tests and type-checking
As a starting point, our first goal was to enable all unit tests and Mypy type-checking under Python 3 to validate that we had some measure of compatibility with Python 3.
All unit tests were initially disabled under Python 3 with module-level pytest.skip function calls. We then went through each test file one-by-one, ran it under Python 3, fixed any issues in either the application logic itself or the test, and then removed the skip.
Similarly, we had an explicit blacklist of files that did not pass under Python 3 Mypy that we worked through file-by-file. By enabling Python 3 Mypy across the codebase, we were able to take advantage of the company-wide push to add more Mypy typing (from 35% coverage to 63% coverage when this project ended!) and enforce types compatible with both Python 2 and Python 3 to prevent the hybrid syntax from regressing.
Specifically, Mypy was able to catch and warn about some type issues that would otherwise silently produce the incorrect result on Python 3, such as our most common issue: the behavioral difference between str, bytes, and unicode in the two Python versions.
Strings: str and bytes and unicode , oh my!
A brief summary: in Python 2, str is an alias for bytes, and unicode is the type for Unicode strings; in Python 3, str is the type for Unicode strings, bytes is for byte-strings, and unicode doesn’t exist.
Besides the differently named types, there are also significant semantic differences in how Python treats each of these types across versions (enough that presentations have been given on just this topic!). For brevity, we’ll omit a discussion here, but a thorough understanding of the differences is highly recommended for anyone working on migrating a project from Python 2 to Python 3.
The primary issue we ran into involved the various locations that we serialize our in-memory representation of various data. Because the interfaces typically accepted ‘string-like’ objects, we would happily call str on a byte-string, which would result in "b'string contents'" in Python 3. Our discovery of these issues were mostly driven by a combination of stronger Mypy typing (to be explicit about when types were bytes vs. Text), and failures from the unit test suite.
A special note about from __future__ import unicode_literals
On the surface, this seems convenient, as it implements the Python 3 string literal behavior in Python 2. However, we found that this was confusing to use in just parts of the codebase, and not possible to add to every file overnight.
It wasn’t possible for us to directly add this import across the codebase because it can change the runtime behavior in breaking ways, especially since many Python standard library functions require a str to be passed on both Python 2 and Python 3.
Including this import in just some files resulted in confusion for developers, as it’s disorienting to follow some logic across files and have the string literal type change because of an import at the top of the file.
2. ‘Straddling’ Python 2 and Python 3
After we had unit tests passing and Mypy type-checking, we could begin trying out the application end-to-end.
We first did this within our team, fixing any obvious issues with the basic functionality, and then organized “bug bashes” with the teams that owned each part of the Dropbox client to test their features in more detail and uncover any more subtle regressions.
Then, it came time to dogfood the Python 3 version of the application with our internal users. To allow us to safely and quickly move our users back to Python 2 if we discovered a critical issue, we built Hydra, which allowed us to choose to run either the Python 2 or Python 3 interpreter when the desktop client started up. During this time, we had to ensure that all of the application logic was written with a hybrid Python 2/3 syntax (‘straddling’ both Python 2 and Python 3) to allow us to continue shipping Python 2 builds to the majority of our users while we were testing Python 3 internally.
3. Letting it bake
To ensure that we met our high quality bar, we kept the desktop client in this hybrid state for an extended stabilization period—first for just our internal build, and then eventually our Beta population as well.
During this period, we relied on reports from our revamped aggregate crash reporting pipeline to alert us of any issues that occurred. This eventually led to the discovery of some fun issues, such as this one in Python itself.
After about 7 months in this period, we were confident that the Python 3 version of the application met our quality bar, and expanded the scope of the rollout to include our Stable channel and removed Python 2 from our application binary. This marked the end of our Python version migration!
Learnings (tl;dr)
- Unit tests and typing are invaluable. We were able to discover the majority of the compatibility issues early on through our unit tests and static Mypy type-checking, and they allowed us to create a clear and concurrently actionable list of issues to fix.
- String encoding in Python is hard. Python 3 is significantly more sane in this respect, and if your Python logic handles Unicode strings, this is in and of itself a good reason to switch from Python 2 to Python 3. However, the drastic changes made in Python 3 to fix string behavior means that most issues you’ll find during the migration will be related to the difference in how strings are handled between the versions.
- Incrementally migrate to Python 3 for great profit. Because we preserved Python 2 compatibility throughout this project, we could continue to allow feature development and ship Python 2 versions of the application, while gradually increasing our Python 3 compatibility until we were comfortable enough to switch over.
Acknowledgements
Stay tuned…
If you’re interested in hearing some of our greatest war stories from this process in more detail, there’s one more post in this series coming soon to a Dropbox tech blog near you!
Interested?
If the kind of problems we’re tackling are interesting to you, and you want to take on the challenges of desktop Python development at scale, consider joining us!


