

At Dropbox, we store data about how people use our products and services in a Hadoop-based data lake. Various teams rely on the information in this data lake for all kinds of business purposes—for example, analytics, billing, and developing new features—and our job is to make sure that only good quality data reaches the lake.
Our data lake is over 55 petabytes in size, and quality is always a big concern when working with data at this scale. The features we build, the decisions we make, and the financial results we report all hinge on our data being accurate and correct. But with so much data to sift through, quality problems can be incredibly hard to find—if we even know they exist in the first place. It's the data engineering equivalent of looking for a black cat in a dark room.
In the past, different teams at Dropbox had different approaches to validating data, with different standards and different pipelines. Inevitably, when we found errors in our data, we knew there were likely more we that weren’t being caught. This is why, in 2018, Dropbox created a dedicated data engineering team to oversee the validation of data in our data lake and to try and catch these problems before they occurred.
All organizations operating at our scale have to think about data validation issues like these. The reality is, data validation isn't a straightforward problem to solve. Some systems have no data quality checks, while other systems attempt to check everything before data can be used. Both have their problems.
If we make our checks too permissive, data will be available more quickly for Dropboxers to use, but the quality may be poor. On the other hand, if we make our checks too restrictive, the quality of the data will be better but take more time and resources to process—and by the time the data is ready, it may be too stale to be useful anymore.
At Dropbox, our data validation framework falls somewhere in the middle. This story will detail how we implemented a new quality check system in our big data pipelines that achieves the right balance of simplicity and coverage—providing good quality data, without being needlessly difficult or expensive to maintain.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
Coverage, code, and configuration decisions
Data quality problems can take many forms. Is a query returning duplicate data? Is there data missing in mandatory fields? Are negative dollar amounts expected? What if the timestamp on a piece of data is too far in the future or the past? We knew we wanted a system that would not only be easy to configure, but be able to perform a wide range of quality checks such as these when needed.
We looked at open source projects on GitHub, and considered commercial products, too. Great Expectations and dbt were two options we considered. Both support simple checks like NOT NULL, upper/lower bound, and UNIQUE, and store these checks in YAML files. But for more complex checks, such as percentages or complex business logic, we would still need to write SQL. Great Expectations and dbt are also standalone services rather than libraries, which makes them hard to integrate with our orchestration system Airflow. For example, while we can call dbt from within Airflow, get the result, and return it to Airflow, any failures require us to use dbt’s interface to investigate.
We also looked at the widely used library Evidently, but felt it was too complex for what we wanted to deliver and would require a lot of Python. When we couldn’t find anything that quite met our needs, we decided to build a solution from scratch.
The first decision we had to make was around coverage. In other words, what kinds of problems were we going to cover with our tests? On the one hand, we wanted our system to be able to validate data of any complexity. On the other hand, we knew we couldn’t cover everything. So we decided to take an 80/20 approach. This principle dictates that 80% of all outputs in a given scenario come from just 20% of inputs, and we reasoned that we could cover the most common data quality problems with only a handful of tests. Problems not covered by our approach might never appear, and those that did could be dealt with on a case-by-case basis.
Next, we had to decide which programming language to use to write our validation framework. Our data engineers had experience in SQL, Java, Scala, SchemaPLT, Python, and C, among others, and each had pros and cons. But after much discussion, we chose SQL. Why choose such a primitive language? Well, everyone knows SQL! It’s flexible enough to handle both simple and complex validations, and relative to other languages, it’s easy for engineers of any level to develop with and maintain.
Finally, we needed to decide where to store the rules defining our data validation checks. Here we didn’t have a lot of options. Databases are widely used for this purpose, and have the advantage of being easy to access and configure. But storing our rules as code would make it easier to review changes and see the history of our revisions. In the end we chose to store all validations as code in Git—because only data engineers know how many problems a database can cause. 🙂
Simple enough? Yes. Effective enough? Yes!
Executing our validation SQL
We use an Airflow orchestration system to land new data in the lake. To implement our framework, we added a validation operator to Airflow that executes our validation SQL after new data has been ingested. For performance reasons, we use one query for all validations. The result from this query has only one row and a lot of columns, and each column represents one data validation operation. If a column contains zero, it means the validation passed. Any other value means the validation failed.
Airflow also lets us combine multiple source tables into a single table, validate the result, and then combine that result with other tables for further validation. This logic lets us begin to gather more details about validation failures—for example, the percentage of problematic rows—without any additional steps. Our framework gathers all non-zero values, marks the Airflow task as failed, and throws an exception through Airflow. We then send a PagerDuty alert to whoever is on call.
For example, if we get an unexpected number of NULLs for another_column and suspiciously low data, we will get the following exception:
Failed validations:
suspiciously_low_data: 999999,
high_null_perc_another_column: 0.07Based on the exception message, a data engineer can understand the reason for the failure and what data should be checked. With small changes to this framework, we could even return strings if necessary—for example, unexpected enum values or email domains.
Here are some examples of what these checks look like in practice.
Upstream data issues
Check if we have any data in the "user” table:
SELECT CASE WHEN COUNT(*)=0 THEN 1 ELSE 0 END AS is_no_data
FROM "user"Check that we don’t have NULLs in a mandatory column:
SELECT SUM(CASE WHEN email IS NULL THEN 1 ELSE 0 END) AS email_nulls
FROM "user"Check duplicate IDs:
SELECT SUM(CASE WHEN rows_per_user_id > 1 THEN 1 ELSE 0 END) AS duplicated_user_id
FROM
(
SELECT *
, COUNT(*) OVER (PARTITION BY user_id) AS rows_per_user_id
FROM "user"
) uProfiling alerts
Check that remaining NULLs are below an acceptable threshold:
SELECT CASE WHEN locale_null_perc > 0.05 THEN locale_null_perc ELSE 0 END AS high_null_perc_locale
FROM
(
SELECT SUM(CASE WHEN locale IS NULL THEN 1 ELSE 0 END)/COUNT(*) AS locale_null_perc
FROM "user"
) tBusiness logic checks
Check if a user has a negative account balance:
SELECT SUM(CASE WHEN u.balance <=0 AND COALESCE(p.ttl_amount, 0) < COALESCE(i.ttl_amount, 0) THEN 1 ELSE 0 END) AS users_with_incorrect_non_pos_balance
FROM "user" u
LEFT OUTER JOIN
(
SELECT user_id, SUM(amount) AS ttl_amount FROM payment GROUP BY user_id
) p ON p.user_id = u.user_id
LEFT OUTER JOIN
(
SELECT user_id, SUM(amount)AS ttl_amount FROM invoice GROUP BY user_id
) i ON i.user_id = u.user_idPrepare the final validation result for “user” table:
SELECT is_no_data
, duplicated_user_id
, suspiciously_low_data
, email_nulls
, CASE WHEN locale_null_perc > 0.05 THEN locale_null_perc ELSE 0 END AS high_null_perc_locate
FROM
(
SELECT CASE WHEN COUNT(*)=0 THEN 1 ELSE 0 END AS is_no_data
, SUM(CASE WHEN rows_per_user_id > 1 THEN 1 ELSE 0 END) AS duplicated_user_id
, CASE WHEN COUNT(*)<1000000 THEN COUNT(*) ELSE 0 END AS suspiciously_low_data
, SUM(CASE WHEN email IS NULL THEN 1 ELSE 0 END) AS email_nulls
, SUM(CASE WHEN locale IS NULL THEN 1 ELSE 0 END)/COUNT(*) AS locale_null_perc
FROM
(
SELECT *
, COUNT(*) OVER (PARTITION BY user_id) AS rows_per_user_id
FROM "user"
) u
) tOnly the good stuff
Our approach has one big downside: once data hits the data lake, anyone can technically use it. Because our checks can take hours to complete—especially if there’s a lot of data to validate, or a lot of validations to run—it means that, during this time, users will have the ability to access unvalidated data.
We could have made our downstream pipelines wait for our validation tasks to complete, but this is hard to maintain with scale. So how do we let someone know what data has and hasn’t been validated? Our solution was to merge our data validation framework with the existing SQL execution operators in Airflow that add new data to our data lake.
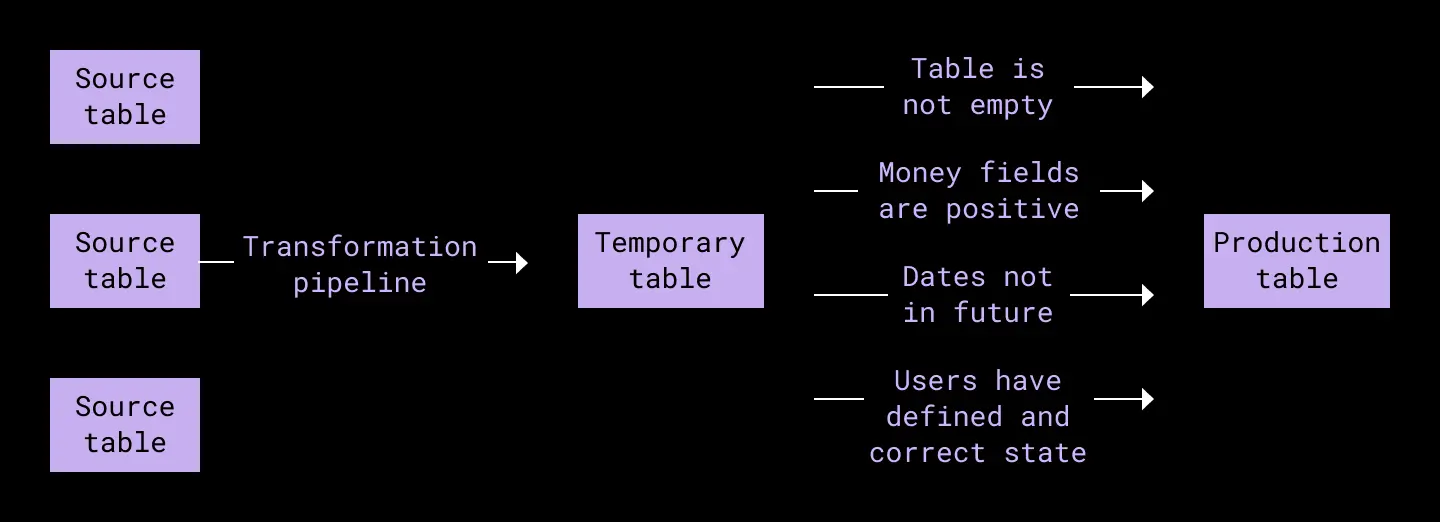
Now the operator that fills a specific table performs two queries: fill and validation. First, the operator creates a temporary table, fills that table with a fill query, and then calls a validation query against the temporary table. Then, if the data passes, the operator moves the validated data to the production table.
This process can be optional or mandatory, depending on the data, which gives us added flexibility when needed. Having access to unvalidated data can be useful for non-critical checks, while mandatory validations block any downstream usage of business critical data. This way we guarantee that only correct data is available for usage.
Simple system, big results
The biggest risk of a system like this is that we can’t get immediate results. By design, this system prevents usage of incorrect data—and because it takes months to gather statistics about downstream data quality issues, the only way to know if our framework was working was to wait and see.
More than a year after release, we can finally say our validation framework was a huge success. We saw 95% fewer data quality incidents, which we call SEVs (as in SEVerity), compared to the previous year. Given our 80/20 approach, these are extremely good results for such a simple system. Thanks to our framework, we were able to catch quality issues such as…
- An email campaign that was accidentally sending the same message multiple times
- A group of still-active accounts that were mistakenly marked as churned, and thus wouldn’t count towards revenue
- A new subscription bundle for Dropbox and Dropbox Sign that was incorrectly counted as a standard Dropbox subscription
- 24 cases of duplicate data over a six month period that we might have otherwise missed
The simplicity of the system not only makes it easy to maintain, but also easy to modify and extend its capabilities. Next on our roadmap, we plan to add validation to both legacy pipelines and pipelines that don’t have as stringent validation requirements but would benefit from our quality checks all the same. We also plan to further build out our analytics capabilities, which will let us analyze existing pipelines and recommend possible validations, and monitor changes in our validation coverage as we add more data to the data lake.
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


