

At Dropbox, AI-powered tools and features are quickly transforming the way our customers find, organize, and understand their data. Dropbox Dash brings AI-powered universal search to all your apps, browser tabs, and cloud docs, while Dropbox AI can summarize and answer questions about the content of your files. To meet the bandwidth requirements of new and future AI workloads—and stay committed to our sustainability goals—the Dropbox networking team recently designed and launched our first data center architecture using highly efficient, cutting edge 400 gigabit per second (400G) ethernet technology.
400G uses a combination of advanced technologies—such as digital signal processing chips capable of pulse-amplitude modulation and forward error correction—to achieve four times the data rate of its predecessor, 100G, through a single link. Because a single 400G port along with optics is more cost efficient and consumes less power than four individual 100G ports, adopting 400G has enabled us to effectively quadruple the bandwidth in our newest data center while significantly reducing our power usage and cabling footprint. Our new design also streamlines the way our data centers connect to the network backbone, allowing us to realize further cost and energy savings by consolidating what was previously three separate data center interconnect device roles into one.
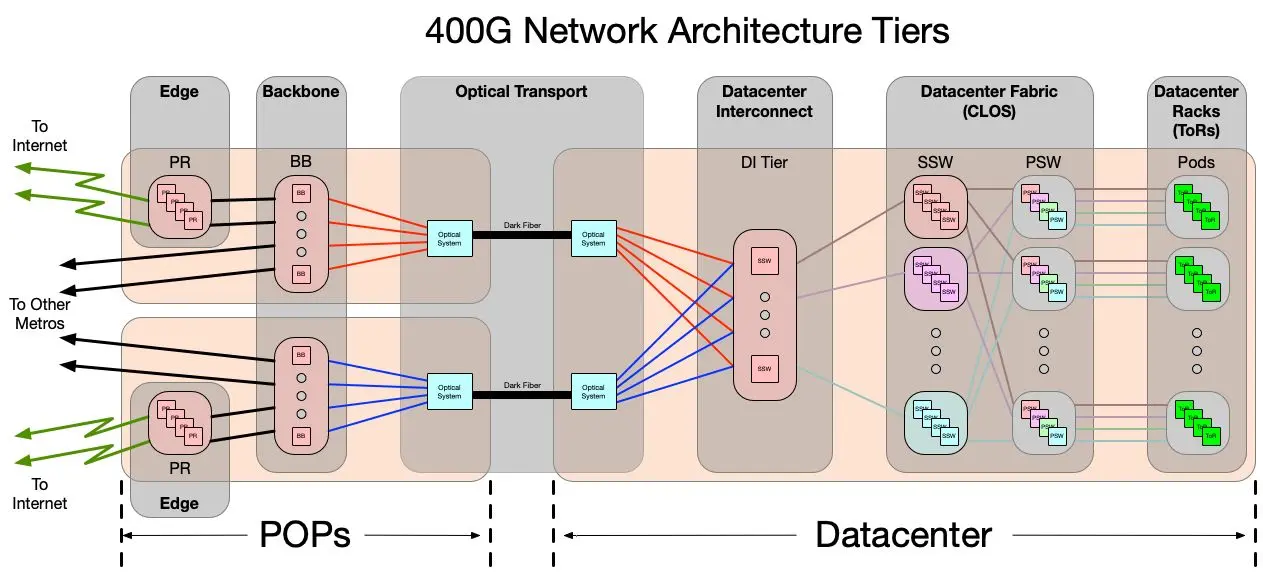
A high-level overview of our 400G network architecture
400G is a relatively new technology, and has not been as widely adopted by the industry as 100G—though that’s beginning to change. In this story, we’ll discuss why we chose to embark on our 400G journey ahead of the pack, review the design requirements and architectural details of our first 400G datacenter, and touch on some of the challenges faced as early adopters and lessons learned. We’ll conclude with our future plans for continuing to build with this exciting new technology.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
The case for 400G
Dropbox has come a long way since launching as a simple file storage company in 2008. We are now a global cloud content platform at scale, providing an AI-powered, multi-product portfolio to our more than 700 million registered users, while also securely storing more than 800 billion pieces of content.
The Dropbox platform runs on a hybrid cloud infrastructure that encompasses our data centers, global backbone, public cloud, and edge points-of-presence (POPs). To efficiently meet our growing resource needs, the Dropbox hardware team is continuously redesigning our high performance server racks using the latest state-of-the-art components. Recently, these designs reached a critical density where the bandwidth requirements of a server rack are expected to exceed the capabilities of 100G ethernet. For example, our upcoming seventh generation storage servers will require 200G network interface cards (NICs) and 1.6Tb/s of uplink bandwidth per rack in order to meet their data replication SLAs!
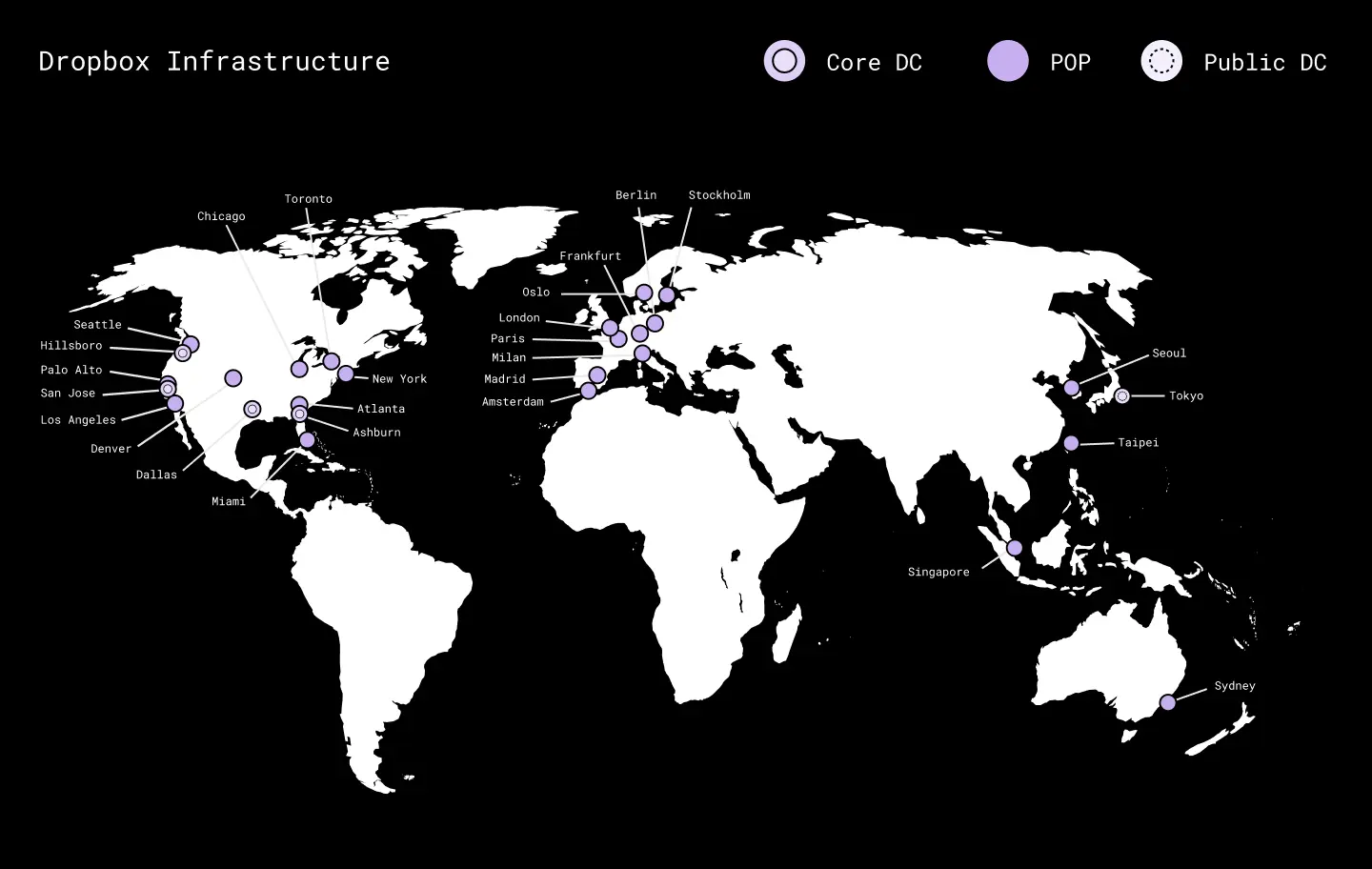
The Dropbox platform’s hybrid cloud infrastructure. Our first 400G data center is located in the US-WEST region
While we considered trying to scale our 100G-based architecture by using bigger devices with a larger numbers of 100G links, we calculated that, for us, this would be wasteful from a power, cabling, and materials standpoint. We anticipated an inevitable need to upgrade to 400G within the next 24 months at most, and deemed it contrary to our sustainability goals to ship a bandaid 100G architecture comprised of hundreds of devices and thousands of optics, only for them to become e-waste within a year or two.
Our decision to adopt 400G stemmed from hardware advancements made by our server design team, increasing levels of video and images uploaded to Dropbox, and the growing adoption of our latest product experiences, Dash, Capture, and Replay. Our hardware and storage teams are in the process of finalizing the manufacture of servers that will require network interface speeds of up to 200G per host, and throughput requirements that greatly exceed the 3.2Tb/s switching rate of our current-generation top-of-rack switch.
Our final design produced efficiency improvements at four sections of our network: the fabric core, the connections to the top-of-rack switches, the data center interconnect routers, and the optical transport shelves.
Fabric core: Zero-optic, energy efficient
At the heart of our 400G data center design, we retained our production-proven quad-plane fabric topology, updated to use 12.8T 32x400G switches in the place of 3.2T 32x100G devices. Sticking with a fabric architecture allowed us to retain the desirable features of our existing 100G design—non-blocking oversubscription rates, small failure domains, and scale-on-demand modularity—while increasing its speed by a factor of four.
Crucially, we were able to do this without expanding our power requirements. We accomplished this by leveraging 400G direct attach copper (DAC) cabling for the dense spine-leaf interconnection links. 400G-DAC is an electrically passive cable that requires virtually no additional power or cooling, so by choosing it we were able to fully offset the increased energy requirements of the faster chips powering the 400G switches themselves.
Comparing power usage metrics from our new 400G fabric core with our legacy 100G data center confirms that the 400G fabric is 3x more energy efficient per Gigabit.
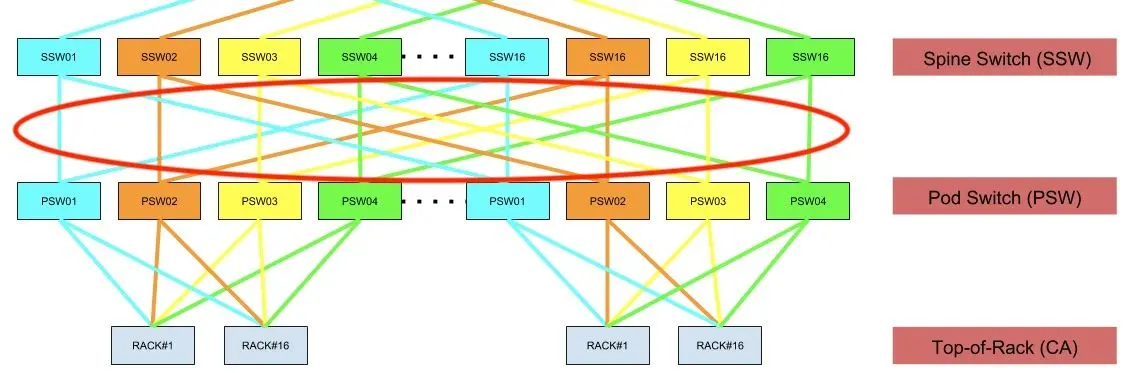
We based the core of our 400G fabric on the same quad-plane fabric architecture we’ve successfully deployed in various iterations for our past five 100G data center builds, but updated it to use 32x400G devices and extremely energy-efficient 400G-DAC cabling
The drawbacks of 400G-DAC were its short three meter range and wider cable thickness. We solved for these constraints by meticulously planning (and mocking up in our lab) different permutations of device placement, port assignments, and cable management strategies until we reached an optimal configuration. This culminated in what we call our “odd-even split” main distribution frame (MDF) design, pictured below.
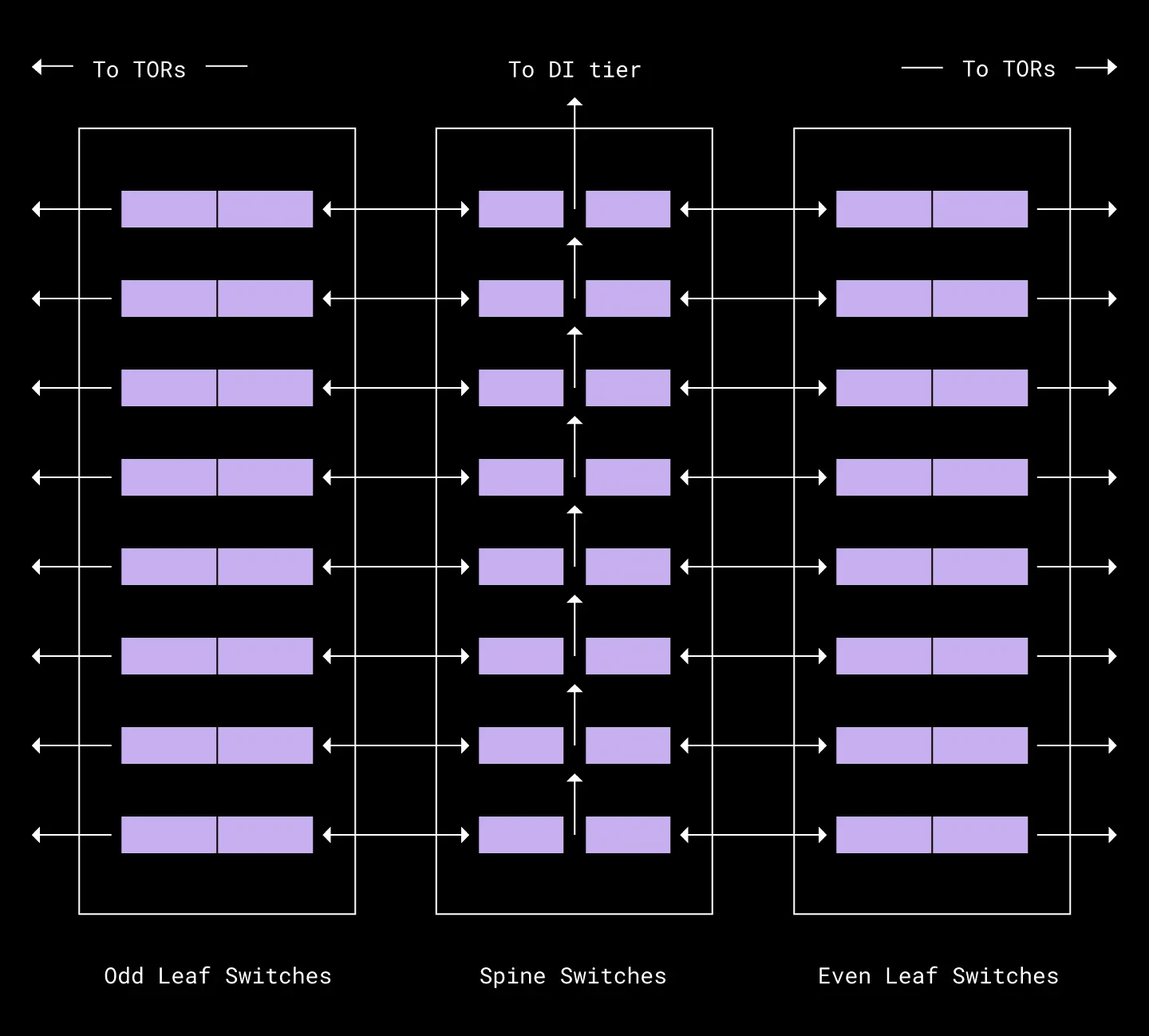
A simplified version of our 400G data center MDF racks using 400G-DAC interconnects. Spine switches are stacked in the center rack, connected to leaf switches that are striped evenly between the adjacent racks. Only DAC cables to the first leaf switch in each of the odd (left) and even (right) racks are pictured. This design was repeated four times for each of the data center’s four parallel fabric planes
Top-of-rack interconnect: Backwards compatibility
Another key architectural component we needed to consider was the optical fiber plant which connects the top-of-rack switches in the data hall to the 400G fabric core. We designed these links based on three requirements:
- The need to support connectivity to both our existing 100G as well as next generation 400G top-of-rack switches
- The ability to extend these runs up to 500 meters to accommodate multi-megawatt-scale deployments
- The desire to provide the most reliable infrastructure while optimizing power usage and materials cost
After testing various 400G transceivers in this role, we selected the 400G-DR4 optic, which provided the best fit for the three requirements mentioned above:
- 400G-DR4 can support our existing 100G top-of-rack switches by fanning out to 4x100G-DR links. Its built-in digital signal processor chip is able to convert between 400G and 100G signals without imposing any additional computational costs on the switches themselves.
- The 400G-DR4 optic has a max range of 500 meters, which meets the distance requirements of even our largest data center facilities.
- At 8 watts of max power draw per optic, 400G-DR4 is more energy efficient than 4x100G-SR4 optics at 2.5 watts (2.5 * 4 = 10W). 400G-DR4 also runs over single mode fiber, which requires 30% less energy and materials to manufacture than the multi-mode fiber we’ve used in our previous generation 100G architectures.
Data center interconnect: Enhanced efficiency, scalability
The data center interconnect (DI) layer has been completely revamped to reflect updates in both bandwidth density and a more powerful, feature-filled networking tier. Today, DI traffic patterns consist of:
- Cross-datacenter traffic between data centers
- External traffic between data centers and POPs, such as Dropbox customers, cloud storage providers, or corporate networks
Previously, the network used distinct tiers to manage these traffic types—one tier for cross-datacenter traffic and another tier for external traffic between data centers and POPs. This involved three separate networking devices, pictured below.
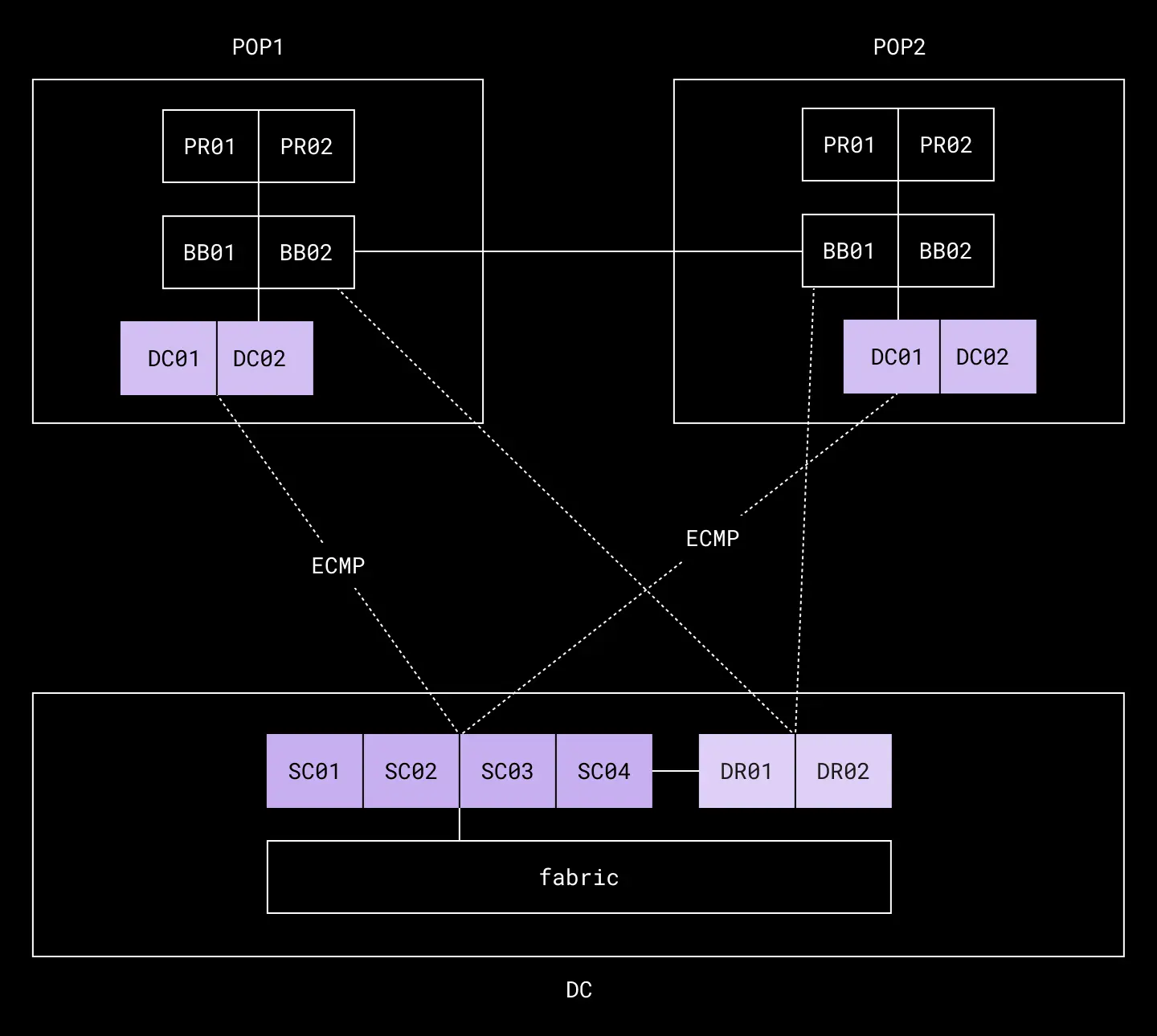
Our old data center interconnect design
400G technology enabled us to combine these three devices into a single data center interconnect. At the same time, features such as class-based forwarding—which wasn’t available during the initial tiered design—made it possible to use quality-of-service markings to logically separate traffic over different label-switched paths with the appropriate priorities.
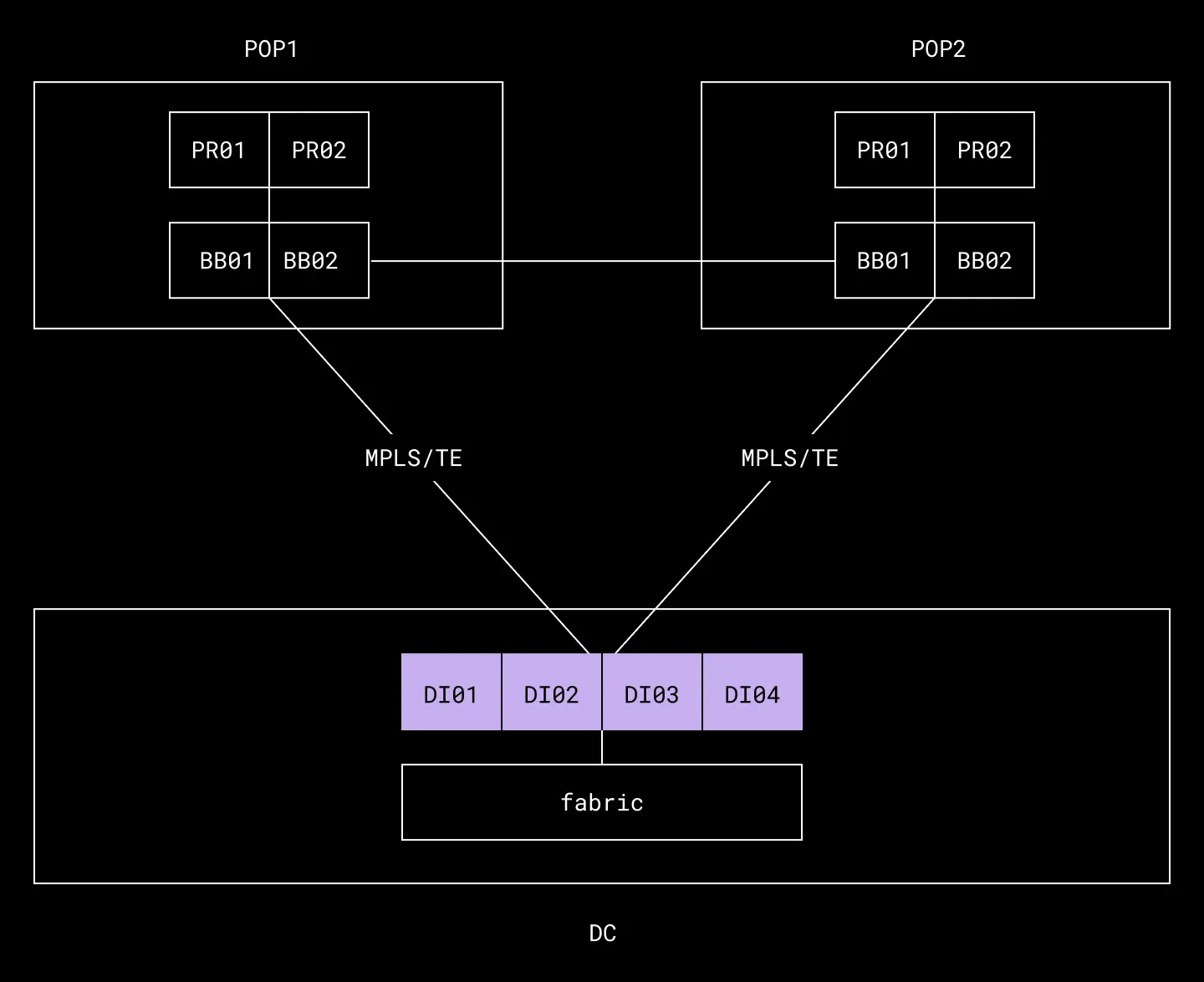
Our new data center interconnect design
The optimized DI tier offers multiple advantages:
- There is a 60% reduction in the number of devices employed at the tier, resulting in notable improvements in space utilization, energy efficiency, and device cost savings, thereby enhancing the network's environmental and economic sustainability.
- The new architecture leverages MPLS RSVP TE to replace ECMP, making the data center edge bandwidth-aware, thereby boosting resiliency and efficiency.
- New architecture allows us to streamline routing by incorporating route aggregation, community tags, and advertising only the default route down to the fabric.
- The new DI tier seamlessly maintains backward compatibility with 100G-based hardware and technology, enabling us to upgrade specific parts of the network while still leveraging the value of our existing 100G hardware investments.
Furthermore, the adoption of 400G hardware unlocks the potential for the DI to scale up to eight times its current maximum capacity, paving the way for future expansion and adaptability. This comprehensive reimagining of the DI marks a significant stride towards an optimized architecture that prioritizes efficiency, scalability, and reliability.
Optical transport: Backbone connectivity
The optical transport tier is a dense wavelength division multiplexing system (DWDM) that is responsible for all data plane connectivity between the data center and the backbone. Utilizing two strands of fiber optics between the data center and each backbone POP in the metro, the new architecture provides two 6.4 Tb/s tranches of completely diverse network capacity to the data center, for a total of 12.8 Tb/s of available capacity. The system can scale up to 76.8 Tb/s (38.4 Tb/s diverse) before additional dark fiber is required.
In comparison, the largest capacity a pair of fiber can carry without this DWDM system is 400 Gb/s.
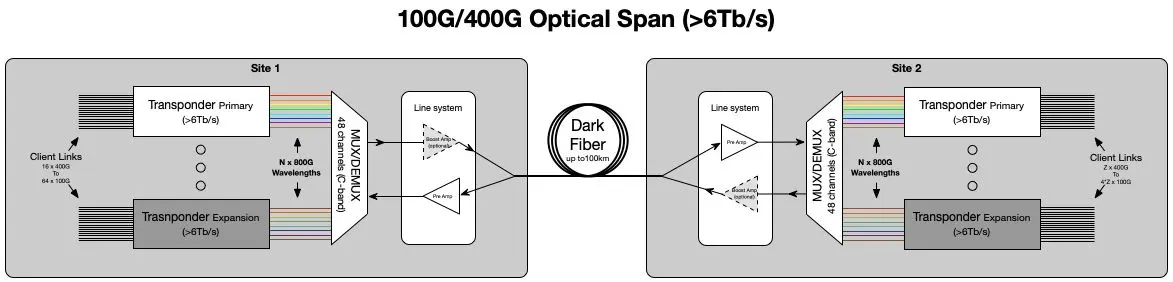
One of the two 6.4 Tb/s diverse data center uplinks spans
New to the optical tier in this generation is the use of 800 Gb/s tuned waves (versus 250 Gb/s in the previous generation) which allows for greatly increased density and significantly lower cost-per-gigabit compared to previous deployments. Additionally, this tier was engineered to afford significant flexibility in the deployment of 100G/400G client links. The multi-faceted nature of this architecture enabled Dropbox to adapt to unexpected delays in equipment deliveries due to commodity shortages, ensuring on-time turn-up of our 400G data center.
What we learned
Since its launch in December 2022, our first 400G data center has been serving Dropbox customers at blazingly fast speeds, with additional facilities slated to come online before the end of 2023. But as with any new technological development, adopting 400G forced us to overcome new obstacles and chart new paths along the way.
Here are some lessons learned from our multi-year journey to this point:
- Meticulously test all components. Since every 400G router, switch, cable, and optic in our design was one of the first of its kind to be manufactured, our team recognized the need to evaluate each product’s ability to perform and interoperate in a multi-vendor architecture. To this end, we designed a purpose-built 400G test lab equipped with a packet generator capable of emulating future-scale workloads, and physically and logically stress-tested each component.
- Ensure backwards compatibility at the 400G-100G boundary. We discovered in testing that a 100G top-of-rack switch we deploy extensively in our production environment was missing support for the 100G-DR optic we’d selected to connect our existing 100G top-of-rack switches to the new 400G fabric. Fortunately, we were able to surface the issue early enough to request a patch from the vendor to add support for this optic.
- Have contingency plans for supply chain headwinds. During our design and build cycle for 400G, unpredictability in the global supply chain was an unfortunate reality. We mitigated these risks by qualifying multiple sources for each component in our design. When the vendor supplying our 400G DI devices backed out one month before launch due to a chip shortage, the team rapidly developed a contingency plan. Because 400G QSFP-DD ports are backwards compatible with 100G QSFP28 optics, we devised a temporary interconnect strategy using 100G devices in the DI role until their permanent 400G replacements could be swapped in.
What’s next
The successful launch of our first 400G data center has given us the confidence needed to continue rolling out 400G technology to other areas of the Dropbox production network. 400G data centers based on this same design are slated to launch in US-CENTRAL and US-EAST by the end of 2023. Test racks of our 7th generation servers with 400G top-of-rack switches are already running in US-WEST and will be deployed at scale in early 2024. We also plan on extending 400G to the Dropbox backbone throughout 2024 and 2025.
Finally, an emerging long-haul optical technology called 400G-ZR+ promises to deliver even greater efficiency gains. With 400G-ZR+, we can replace our existing 12-foot-high optical transport shelves with a pluggable transceiver the size of a stick of gum!

Daniel King, one of our data center operations technicians, holds a pluggable transceiver in front of the equipment it will eventually replace.
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


