

Problem
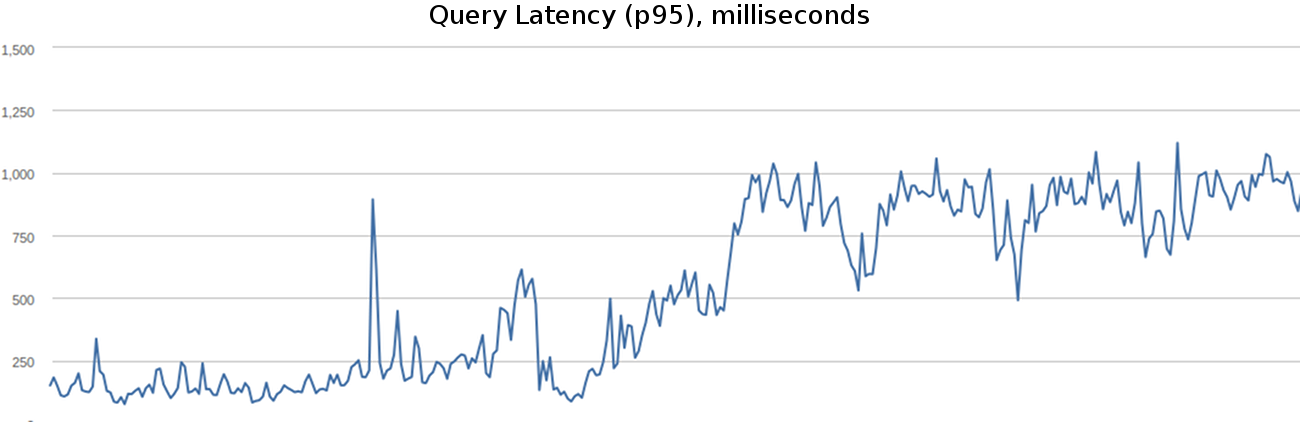
In order to create a good user experience for Firefly, we strive to keep our query latency under 250 ms (at 95th percentile). We noticed that our latency had deteriorated quite a bit since we started adding users to the system.
One aspect of Firefly that allows us to support search over a very large corpus (hundreds of billions of documents) with a relatively small machine footprint is that we don’t load the search index in RAM — we serve it from solid-state drives (SSDs). In our investigation, we found that the deterioration in latency was caused by an increase in I/O operations per sec (IOPS) on the index servers. This increase caused the index servers to be I/O bound.
Approach
Search index encoding
Conceptually, a search index contains the mapping:
token => List(Tuple(DocumentID, attributes))Examples of attributes are: whether the token appeared in the text of the document, if it was part of the filename, or if the token was an extension.
For compactness, we encode the list of document IDs separately from the list of attributes. These are then laid out one after another:
token => Header, Encoded(List(DocumentID)), Encoded(List(attributes))
The header contains meta information like the byte length of each encoded part and the version of the encoding scheme used. This ended up being very helpful for this project, as it allowed us to introduce new ways of encoding this list without breaking backwards compatibility for old index entries.
For example, if the token “JPG” is an extension for documents 10001, 10002 and 10005, and it appears in the text of document 10007, then the mapping for “JPG” would look like the following:
JPG => [10001, 10002, 10005, 10007], [Extension, Extension, Extension, FullText]
JPG => [10001, 1, 3, 2], [Extension, Extension, Extension, FullText]
We're using Varint encoding for the document IDs, so smaller values translate into fewer bytes in encoded form.
When we use run-length encoding of attributes, we get an even more compact representation:
JPG => [10001, 1, 3, 2], [Extension x 3, FullText]
Results
These encoding changes reduced the total size of the encoded search index by 33%.
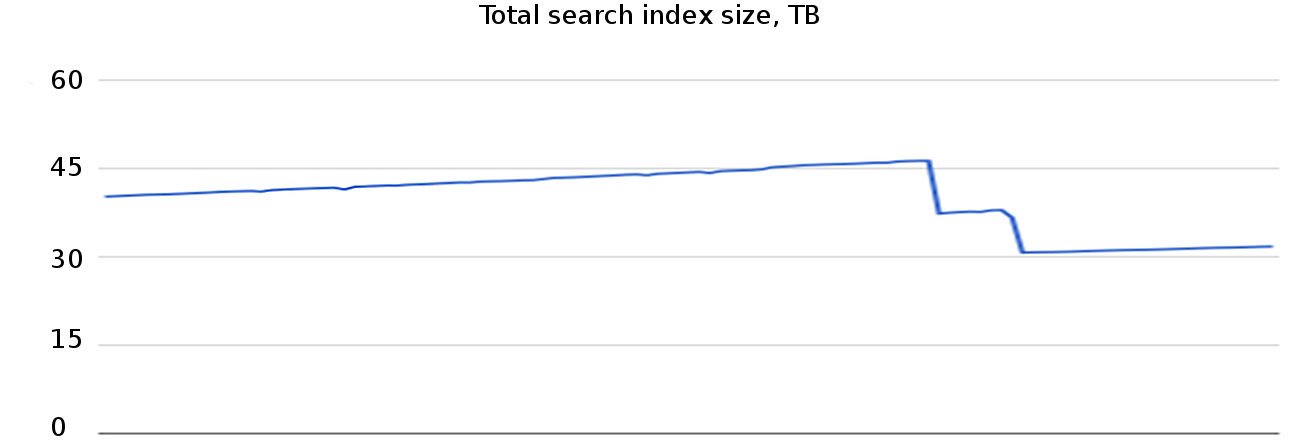
The above graph shows two large reductions in index size. The first one was a result of deploying delta encoding, and the second one was a result of deploying run-length encoding.
Both of these greatly reduced the I/O we do on the index servers. This is illustrated by the following graph:
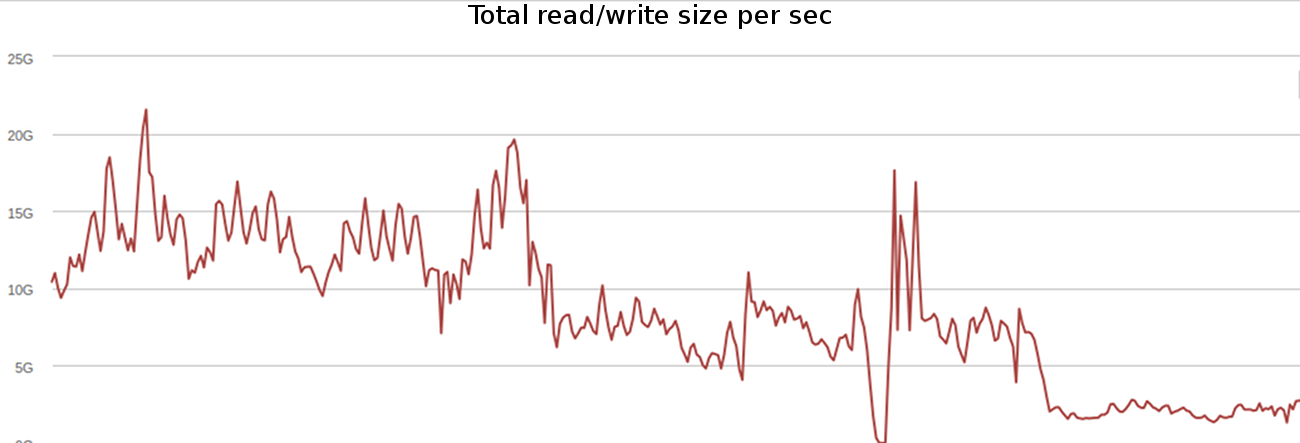
Interestingly, the run-length encoding resulted in a larger improvement than the delta length encoding. We had expected this to only reduce the posting-lists for certain filename tokens (e.g., “jpeg” was usually an extension) — these frequently had the same attributes associated with them. To our surprise, this also gave us a large reduction in the posting-list size for full-text tokens. Our theory is that some users may have the same word a single time in a large number of documents, so all of these hits share the same attributes.
These changes resulted in a significant improvements in the 95th percentile latency of our system, as shown by the following graph—we're back at 250 milliseconds!

Lessons learned
It is important to track the vital stats of the system as it’s scaled up, and follow up on any degradation. Sometimes it may reveal unexpected behavior. Also, having extensible structures is pretty helpful — it would have been very hard to introduce alternative encodings without the use of the header in the mapping.
As a result of these changes, our index servers were no longer I/O bound, leading to a better experience for our users.


