

Efficiently storing and retrieving metadata has long been a core focus for metadata teams at Dropbox, and in recent years we've made significant improvements to our foundational layer. By building our own incrementally scalable key-value storage, we’ve been able to avoid necessary doubling of our hardware fleet. As we scale, our evolution continues—but there are still challenges we cannot ignore.
At our current rate of growth, we knew there would come a time when the volume of read queries per second (QPS) could not be sustainably served by our existing underlying storage machines. Caching was the obvious solution—but not necessarily an easy one.
Internal clients of Dropbox metadata have long relied on the assumption that data retrieved would provide a read-after-write guarantee (i.e., if I successfully write to a key, and then immediately subsequently read that key, absent other writes, I should see what I just wrote and not some stale value). If we were to weaken this guarantee, it would be impractical for the metadata team to audit and change every client team’s code. In addition, doing so could require significant client side code complication and/or re-design, reducing development velocity for product teams.
 Dropbox Dash: AI that understands your work
Dropbox Dash: AI that understands your work
If we wanted to solve our high-volume read QPS problem while upholding our clients’ expectation of read consistency, traditional caching solutions would not work. We needed to find a scalable, consistent caching solution to solve both problems at once.
Our answer is Chrono, a scalable, consistent caching system built on top of our key-value storage system, Panda. It can sustainably serve high-volume read QPS, and also allows us to make use of Panda followers to serve linearizable reads (ie. reads that are guaranteed to see the effect of all linearized prior writes). Relieving existing Panda load is important on its own, but this capability is also key to enabling new high-volume metadata workflows involving search and AI.

Illustration by Chia-Ni Wu; licensed under CC BY 4.0
Why is consistent caching so hard?
Naive use of transparent caching at the database layer does not provide a read-after-write guarantee. For example, writing to the underlying storage system and then writing to the cache can leave stale data in the cache if the server orchestrating the writes crashes in between the two steps.
Even simple pre-invalidation of the cache has issues. Imagine the following sequence where key K is initially mapped to value v1 in storage and v1 in the cache:
- Writer tries to write K=v2. It initially invalidates the cache for key K
- Reader 1 looks in the cache, gets a miss, and reads from storage, getting value v1 for K
- Writer then issues and completes the write to storage
- Reader 2 looks in the cache, gets a miss, and reads from storage, getting value v2 for K. Reader 2 then populates the cache with K=v2
- Reader 1 then populates the cache with K=v1. The cache is now stale with respect to the underlying storage
Solving consistent caching at scale
Chrono is built on top of Panda, our multi-version concurrency control (MVCC) key-value storage system. Panda provides a commit timestamp for every successful write, and every record (key/value pair) in Panda is associated with the commit timestamp of the write that created the record. The commit timestamp for a given key increases strictly monotonically with successive writes. Users can also issue reads using a specific snapshot timestamp in the commit timestamp timeline.
There are a few Panda APIs that make Chrono possible.
Write API
Write(keys, values, maxPermittedCommitTimestamp) -> commitTimestamp
In the Write API, the client tells Panda what keys and corresponding values it wants to write. In addition, if the commit timestamp chosen by Panda for the write transaction is higher than the optionally provided maxPermittedCommitTimestamp, Panda fails the write.
Snapshot read API
Get(key(s), readTimestamp) -> record(s)
The client specifies the read timestamp, and can read out the record value from that point in time. If the readTimestamp is sufficiently old, Panda will attempt to use followers to serve the Get request.
GetLatest API
GetLatest(key(s)) -> (record(s), readTimestamp)
GetLatest takes in key(s) the client wants to read, then returns the latest records for those keys. The records contain the value of the key and the commit timestamp of the key. GetLatest reads the keys at a transactionally consistent point in time, and that read timestamp is returned to the caller. The readTimestamp is always higher than or equal to the commit timestamps of the returned records. Panda also guarantees that any write to any of the provided keys linearized after this GetLatest call will have a commit timestamp strictly greater than the returned readTimestamp.
Panda’s GetLatest implementation strives to return the highest readTimestamp that is still guaranteed to be correct. Generally, the value of readTimestamp returned is fairly close to the current real time. This means that when we read the same key using GetLatest a few minutes apart—without any write to the key in between—we will receive same record and commit timestamp, but with a fresher readTimestamp in the more recent read.
If we reuse that readTimestamp by issuing a snapshot read, we will observe exactly the same records for those keys as what GetLatest returned.
What Chrono does
In one sentence: Chrono is a service that tells you latest write attempt timestamp of every key in the storage system.
Chrono provides the following APIs:
- Attempt(key, attempt_ts) — Before writing a key to Panda, the client needs to first notify Chrono of the write attempt. The attempt_ts (which is used as the maxPermittedCommitTimestamp when calling Write) should be far enough in the future that the write to Panda does not fail, but not so far in the future that it prevents effective caching of that key for too long. A sensible balance is achieved with something similar to Attempt(key, Now() + 5s). This depends on loosely synchronized clocks for liveness but safety is always maintained, even with arbitrary clock skew.
- LatestAttemptTimestamp(key) -> ts — For every key queried, return an upper bound for the highest observed attempt timestamp.
To provide non-decreasing return values for LatestAttemptTimestamp for any given key, even with crashes/restarts, Chrono stores and periodically advances a separate upper bound timestamp in persistent storage (e.g. Panda). If an Attempt() call provides an attempt_ts that is greater than the persisted upper bound, Chrono fails the request. On startup, a Chrono process reads the upper bound from storage and that is the minimum timestamp it returns for LatestAttemptTimestamp calls; this ensures that the timestamps returned by LatestAttemptTimestamp never go backwards for any given key.
Chrono does not store the data values corresponding to the keys. That responsibility is relegated to a key value (KV) cache system like Memcache or Redis. This KV cache can be lossy and/or serve stale data. Nevertheless we will see below that with these Panda and Chrono APIs, we can achieve consistent caching and not serve stale data to our users.
The full picture looks like this:
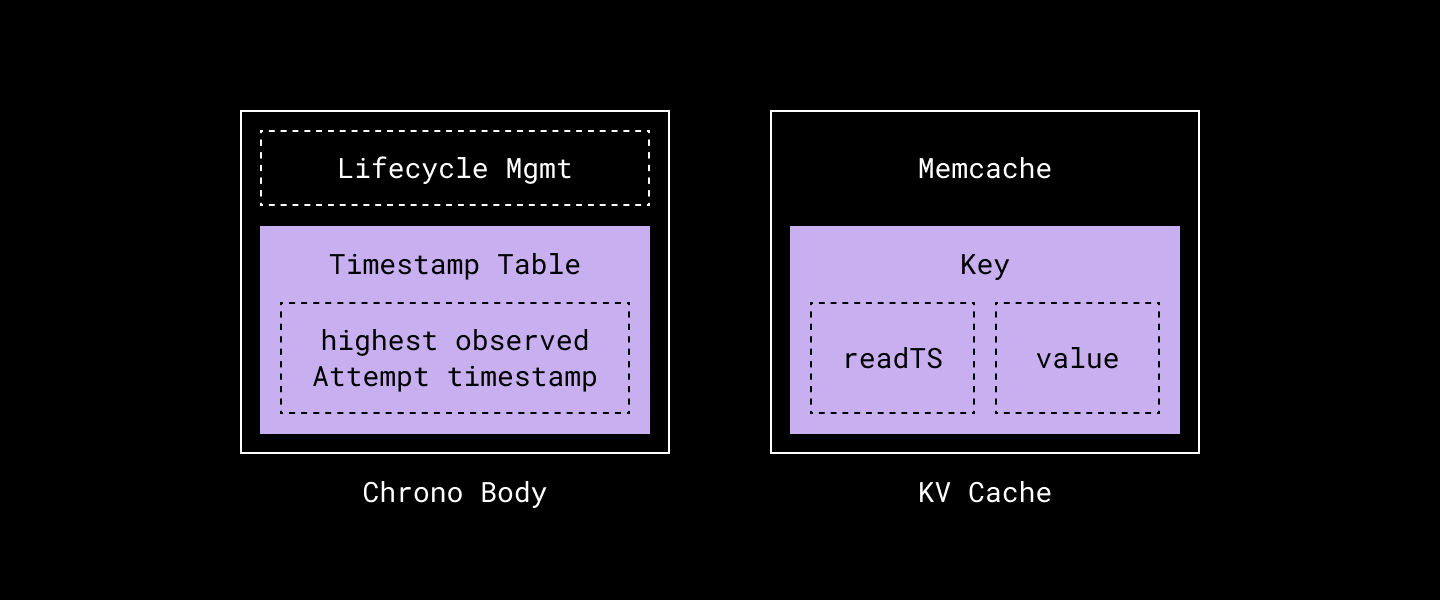
We have two main components:
- Chrono Server, which provides the two APIs we mentioned above.
- The lifecycle management component is mainly in charge of whether a Chrono process has been properly bootstrapped and is ready to serve requests.
- The timestamp table is where we conceptually store the mapping for key → highest observed Attempt timestamp. The implementation hashes the key and stores a single value for all keys that fall into the same hashed slot. This does introduce aliasing across keys that fall into the same hash equivalence class, but strictly bounds memory usage.
- Memcache, which holds the key → <readTS, value> mapping.
By decoupling of the data caching component and write attempt tracking component, we have the ability to scale just that component without interfering with other components. For example, if the cache hit rate is low due to insufficient memory allocated for the Memcache cluster, we are able to vertically or horizontally scale our Memcache fleet without touching the Chrono server. Although we show only one box each for Memcache and Chrono in the diagram above, both are sharded, horizontally-scalable systems in practice.
How the Chrono protocol works
Below we will describe how a user of Chrono (for example Edgestore) would interact with Chrono, Memcache, and the underlying storage system in order to achieve consistent caching. At a high level, we are using the timestamps stored in Chrono to detect when Memcache entries are stale and avoid serving them.
Write path
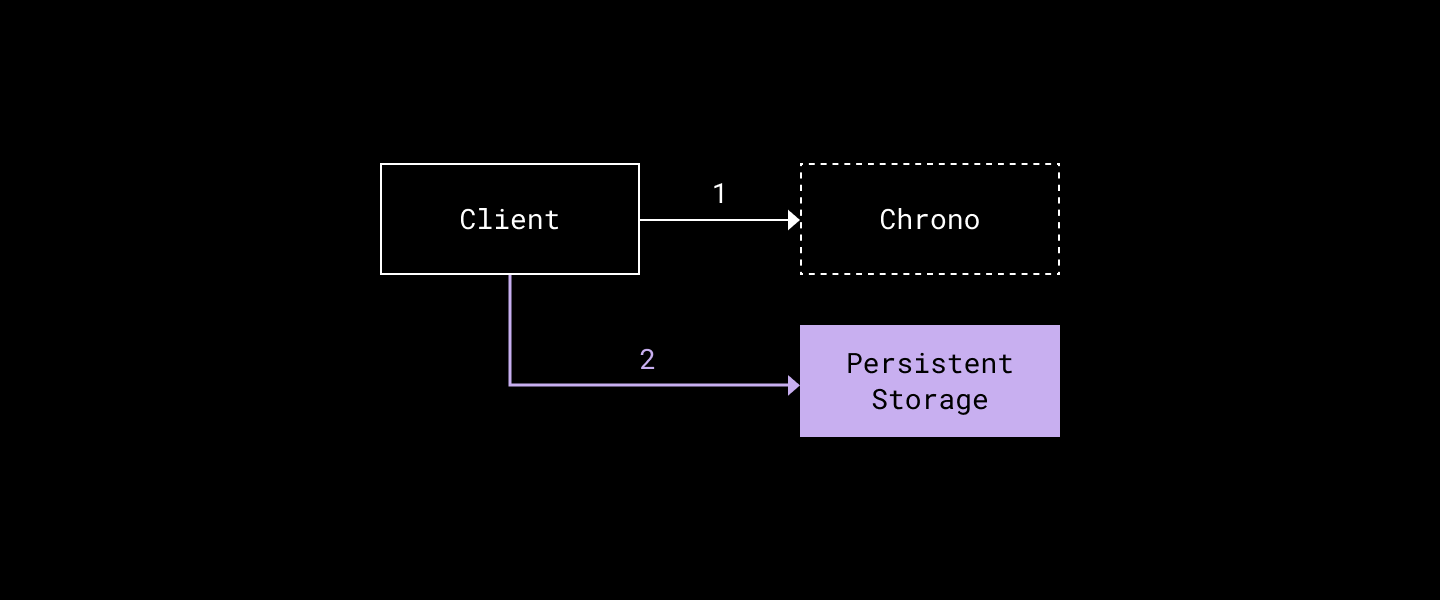
- The client chooses a reasonable attempt_ts—slightly higher than time.Now() to account for clock skew and network round trip latencies—and calls Attempt(key, attempt_ts) to Chrono. Step one must succeed before proceeding to step two, or the flow is aborted.
- The client then tries to commit the transaction to Panda using Write(key, value, maxPermittedCommitTimestamp=attempt_ts).
Read path
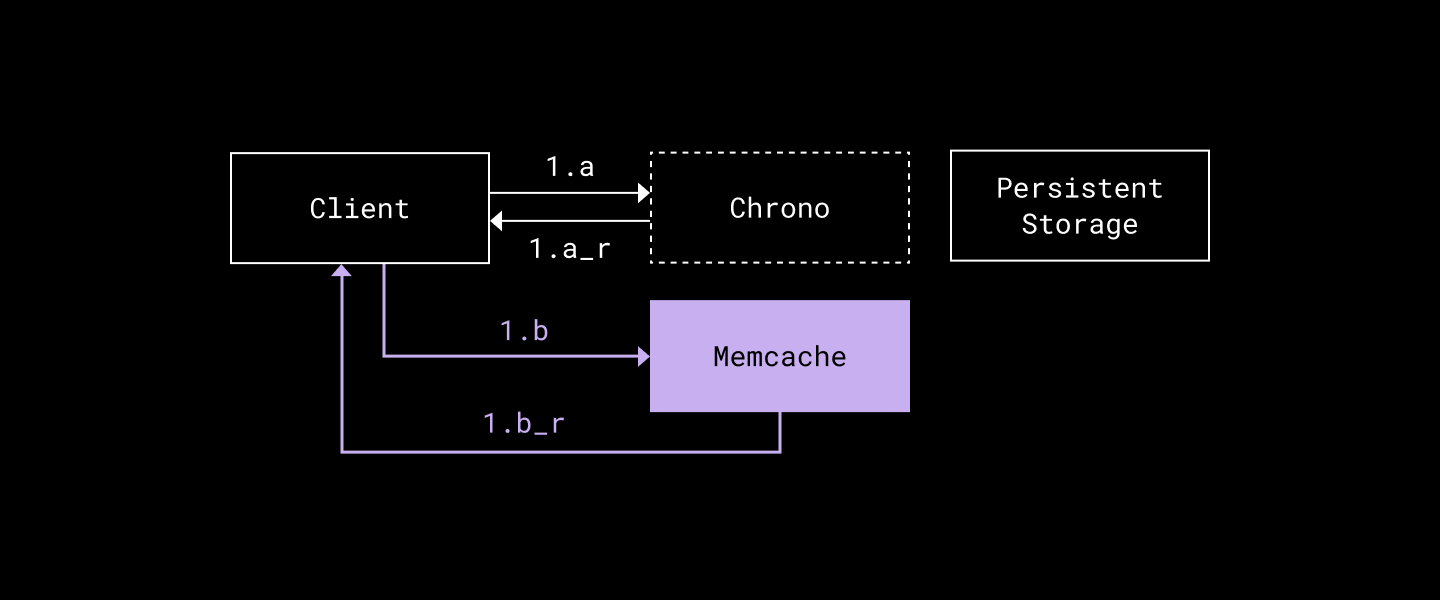
- In parallel…
a. The client calls LatestAttemptTimestamp(key) and gets LatestAttemptTS.
b. The client calls Memcache.Get(key) and gets val, memcacheReadTS (or cache miss).
- Next, we validate cache freshness if we hit Memcache…
if LatestAttemptTS > memcacheReadTS {
// cache stale; need to read from storage.
} else {
// cache hit; serve val we got from Memcache
}…and upon cache miss/stale cache:
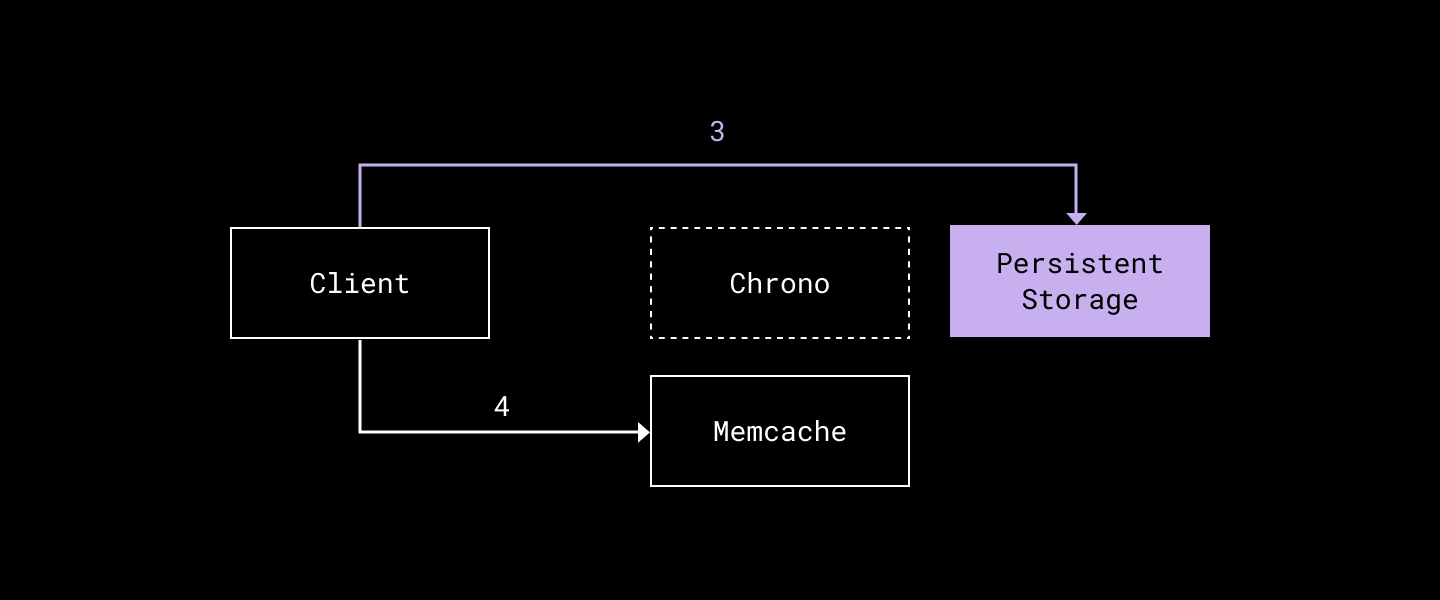
- Send the GetLatest(key) request to storage and get a more recent (val, readTS) pair.
- The client then populates (key, readTS, val) to Memcache.
A concrete example
- The client wants to write key K with value val. It informs Chrono it is attempting to write key K, expecting the commit timestamp won’t be higher than 10.
- After successfully calling chrono.Attempt(K, attempt_ts=10), the client proceeds to write to storage with Write(K, val, maxPermittedCommitTimestamp=10).
- The storage commits the write and responds with 9 as the commit timestamp.
- The client now issues a read for key K. It asks Chrono, and Chrono returns LatestAttemptTimestamp(K)=10. The client also asks Memcache about key K but misses in the cache.
- The client issues storage.GetLatest(K), gets back K, val, readTS=11. The client then stores K → val, readTS=11 in Memcache.
- The next time the client reads again, it can compare Memcache readTS=11 with Chrono's answer of LatestAttemptTimestamp(K)=10, and then use the value in Memcache as it’s fresher than the latest Attempt.
Even in a situation where Memcache did not hold an entry for our target key, we can still take advantage of a snapshot read by doing a Get with a read timestamp value at least as high as the timestamp returned by Chrono’s LatestAttemptTimestamp. This is guaranteed to observe all linearized prior writes and in practice offloads significant traffic from the Panda leaders onto the followers because most reads are not to recently written keys.
How does this provide consistent caching?
If everything is implemented correctly, we have the following facts:
- Before any successful write to a given key K resulting in commit timestamp T_commit in Panda, we must have issued to Chrono a successful Attempt(K, T_attempt) call. It is the case then that T_commit <= T_attempt due to our use of maxPermittedCommitTimestamp.
- If LatestAttemptTimestamp(K) follows some successful Attempt(K, T_attempt), then the timestamp returned by LatestAttemptTimestamp(K) is greater than or equal to T_attempt.
Suppose a key K exists in Memcache and is associated with its value (possibly a tombstone indicating deletion) and a read timestamp T_read. We claim that if a client issues a read for K and we see T_read >= LatestAttemptTimestamp(K) (which would allow us to use the cached value), then the value in Memcache is a valid value to return to the user (guaranteed to include the latest linearized prior write).
We prove this by contradiction. If we returned a stale answer, there must be a newer Write for K in storage whose commit was linearized prior to the client-issued read with commit timestamp T_commit_newer > T_read (due to the guarantees provided by GetLatest mentioned earlier) when we returned the value corresponding to T_read from the cache.
However for the Write with commit timestamp T_commit_newer to have succeeded, we must have first successfully called Chrono with an Attempt(K, T_attempt_newer) and T_commit_newer <= T_attempt_newer. Then, the LatestAttemptTimestamp(K) call for the read that happens subsequently (and which returned a stale value from the cache) would have returned a value that is at least as high as T_attempt_newer. But this means that we would not have used the value from the cache because LatestAttemptTimestamp(K) >= T_attempt_newer >= T_commit_newer > T_read. This is a contradiction, so there can be no such Write.
Validation
We used a number of tools and techniques to help us verify the correctness of the caching protocol. The main one is TLA+, a formal specification language developed to design, model, document, and verify concurrent systems. It’s worth noting that expressing your system and invariants correctly in TLA+ does not necessarily mean you will implement the system correctly. We also wrote various self-checking workloads and verifiers to continually test in stage and production that we uphold internal invariants and provide externally visible read-after-write behavior when reads are served from the cache.
Lessons learned
- Strong semantics (read-after-write) have a cost. Educate your clients from day one. Somewhat stale data is not necessarily a bad thing, and it is possible with upfront design to tolerate it in many scenarios. There is, however, a tradeoff between ease of development and platform sustainability. If you, as the system maintainer, have the choice, choose not to spoil the clients with strong guarantees.
- TLA+ is awesome. We used TLA+ in the design phase of Chrono to prove correctness—but it does not solve every problem for you. There are still a lot of things you need to consider before you can even express them in TLA+. Making incorrect assumptions about the environment or not modeling correctness-critical startup sequences may result in a model that gives false hope. We encountered this with a previous flawed iteration of the caching protocol that had a different but buggy startup sequence. We did not catch this in our initial model that only described steady state behavior; the bug was caught by human inspection and analysis. Subsequently modeling the startup sequence for the prior version of the protocol then quickly revealed an invariant violation.
- Scale matters. The most time-consuming part was not building or debugging Chrono, but dealing with various operational issues common to many sharded systems—for example, how to design a sharding scheme that allows us to efficiently bundle Memcache requests to reduce overall request fanout and latency, how to debug and mitigate hot spotting in Chrono and Memcache pods, etc.
A project of this magnitude doesn’t come together without the help of many incredible Dropboxers. We’d like to thank Metadata team members Jonathan Lee and Zhangfan Dong for their contributions. A special shoutout to alumnus Preslav Le who inspired and kickstarted the effort, and all Metadata alumni for their invaluable contributions to this project!
Finally, we want to recognize our partners in Capacity, Fleet Management, Filesystem, Reliability, and Orchestration whose contributions and support helped us move this project forward.
~ ~ ~
If building innovative products, experiences, and infrastructure excites you, come build the future with us! Visit dropbox.com/jobs to see our open roles, and follow @LifeInsideDropbox on Instagram and Facebook to see what it's like to create a more enlightened way of working.


